在了解別人hive能力水平的時候,不管是別人問我還是我了解別人,有一些都是必然會問的東西。問的問題也大都大同小異。這里總結一下我遇到的那些hive方面面試可能涉及的問題
1、行轉列(列轉行)
當我們建設數據倉庫時,我們對來自OLAP的數據進行加工以便處理成維度模型。在維度模型設計的時候就需要面對這樣的問題(其他時候可能也會用到)
數據準備
建表:create table shj_cnblogs(customer_id string,trans_year string,trans_amount int,product_name string) row format delimited fields terminated by ',';
導入數據:load data local inpath '/home/www/su*****n/sample/data.csv'? into table shj_cnblogs;

行轉列
上表是一個虛擬數據(業務含義:customer_id代表一個客戶,其每年購買的產品和金額),希望將展示客戶不同年份購買了多少以及產品。呈現的數據希望是這樣的。

這里我們的難點就是如何在行聚合時將產品行轉列了,這就說到hive中的函數UDTF(表生成函數)。UDTF函數有:array/explode/collect_set/collect_list等。這里使用了collect_set,腳本為:
select customer_id,trans_year,sum(trans_amount) as total_fund,concat_ws(',',collect_set(product_name)) as all_product from shj_cnblogs group by customer_id,trans_year;
--(當遇到不懂得函數可以用命令查看解釋:show function [extended] fun_name;)
? 上面我們將多行轉為一列,也可以轉為多列。轉多列使用的是collect_set的集合屬性,通過調用集合元素實現多行轉多列。
列轉行
?假如我們虛擬了這樣的數據來描述電影的表,想要將它的列拆分多行,該怎么辦呢?

這里我們使用explode函數,該函數輸入的是一個數組,后將數組中的每個元素都作為一行來輸出。但有一個明顯的限制,不能與其他列共同使用。如果要包含其他列,則需要laterval view來實現。使用lateral view需要指定視圖別名和生成的字段別人。
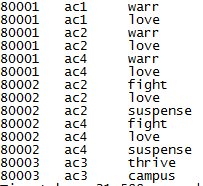
select film_id,actor_id,dd from shj_1 lateral view explode(split(feature_desc,',')) cc as dd ;[這里cc是視圖別名,dd是字段別名]
假如這里需要列分割的不止一列,則使用兩次lateral view來實現。比如說這里的actor_id列是多值分布的,則寫法如下
select film_id,bb,dd from shj_1 lateral view explode(split(actor_id,',')) aa as bb lateral view explode(split(feature_desc,',')) cc as dd ;
執行后結果如圖
?
? 2、窗口函數
在做OLAP分析或報表時,常常使用窗口函數能大幅度提升我們的分析效率。在說窗口函數前,請一定要記住:在SQL處理中,窗口函數都是最后一步執行,而且僅位于Order by字句之前.
窗口函數的關鍵字:over(),它幫助我們在行記錄上實現聚合,我們既可以看到明細數據也可以看到聚合數據(使用中,發現窗口函數可以和聚合函數一起使用的,但注意!窗口函數是僅早于order by步驟。寫sql時應注意兩者之間是否存在沖突,這點容易出錯。)。這里我們從一個樣本數據出發(客戶買東西場景),探索窗口函數的妙用(數據和內容參考博客:http://blog.csdn.net/qq_26937525/article/details/54925827,這篇博客寫的真不錯!)
jack,2015-01-01,10
tony,2015-01-02,15
jack,2015-02-03,23
tony,2015-01-04,29
jack,2015-01-05,46
jack,2015-04-06,42
tony,2015-01-07,50
jack,2015-01-08,55
mart,2015-04-08,62
mart,2015-04-09,68
neil,2015-05-10,12
mart,2015-04-11,75
neil,2015-06-12,80
mart,2015-04-13,94
I、認識窗口函數
我們先看看下面的三個sql語句的差異。第一個是傳統的group by聚合函數,實現以name維度的聚合,展示客戶的購買次數;第二個使用窗口函數,展示明細數據并聚合所有的購買次數(這里沒有指定分區,則針對全表);第三個先分組,對分組數據進行聚合,得出聚合的分組數。該sql可以也可寫成select distinct name,count(*) over() from shj_2;
腳本1> select name,count(*) from shj_2 group by name order by name; jack 5 mart 4 neil 2 tony 3 腳本2> select name,count(*) over() from shj_2 order by name; jack 14 .... jack 14 mart 14 ... tony 14 腳本3> select name,count(*) over() from shj_2 group by name order by name; jack 4 mart 4 neil 4 tony 4
? II、partition by下的序列函數
上面我們說的都是全表的情況,這里我們討論一下分區的使用。在傳統sql中,我們對數據進行除重清洗時會使用到row_number() over(partition by ...order by ...)語句,這其實就是一個窗口函數的應用案例。像row_number()這樣的序列函數還有rank() over(partition by ...order by );dense_rank() over(partiton by ... order by ...)【rank:有空位;dense_rank:沒有空位】;ntile() over(partition by ... order by ...);這些函數的工作機制:先分區(partition by關鍵字后的字段),再排序(order by后的字段),然后在分區中進行序列賦值(row_number從1開始賦值,ntile是根據指定字段進行切片,不均勻時增加前面的分組數)
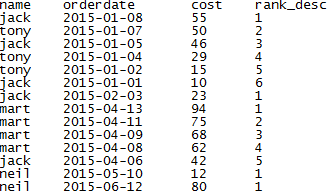
示例:月度的消費排名
select name,orderdate,cost,rank() over(partition by month(orderdate) order by cost desc ) as rank_desc from shj_2;
?? III、聚合函數+over
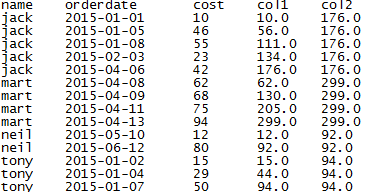
前面提到的partition by可以將數據表以指定的分式進行分區,類似于row_number()等函數,我們也可以使用聚合函數(類似有sum/count/avg/),在使用聚合函數時,指定order by與否將影響整個聚合的效果。不指定時,聚合整個分區,指定order by時,則是以order by順序累加聚合。說明:窗口函數之間是互不影響的。
--查看客戶月度消費和增加,col1是隨著時間增加的累加金額,col2是總金額 select name,orderdate,cost,sum(cost) over(partition by name order by orderdate) as col1,sum(cost) over(partition by name) as col2
from shj_2 order by name, orderdate;
? 
然而,分區函數的粒度還可以更加的細分,這里我們說到window子句,指定聚合的作用范圍(分區中的范圍)。這里我們需要order by來進行排序,否則無序的數據是毫無意義的。指定范圍的關鍵字有:
PRECEDING:前面行
FOLLOWING:后面行
CURRENT ROW:當前行
UMBOUNDED:起點,UNBOUNDED PRECEDING 表示從前面的起點, UNBOUNDED FOLLOWING:表示到后面的終點
? 這里我使用博客中的腳本和結果
select name,orderdate,cost, sum(cost) over() as sample1,--所有行相加 sum(cost) over(partition by name) as sample2,--按name分組,組內數據相加 sum(cost) over(partition by name order by orderdate) as sample3,--按name分組,組內數據累加 sum(cost) over(partition by name order by orderdate rows between UNBOUNDED PRECEDING and current row ) as sample4 ,--和sample3一樣,由起點到當前行的聚合 sum(cost) over(partition by name order by orderdate rows between 1 PRECEDING and current row) as sample5, --當前行和前面一行做聚合 sum(cost) over(partition by name order by orderdate rows between 1 PRECEDING AND 1 FOLLOWING ) as sample6,--當前行和前邊一行及后面一行 sum(cost) over(partition by name order by orderdate rows between current row and UNBOUNDED FOLLOWING ) as sample7 --當前行及后面所有行 from shj_2;

? IV、常用的窗口函數
lag(var,n[defualt_value]):向后取上第n個數據(lag:有落后的意思)
lead(var,n[defualt_value]):向前取下第n個數據(lead:有領先的意思)
? first_value(var):取分組內排序后,截止到當前行,第一個值
? last_value(var):取分組內排序后,截止到當前行,最后一個值
select name,orderdate,cost, lag(cost,1) over(partition by name order by orderdate) as first_lag_cost, --上一次消費金額 lag(cost,2) over(partition by name order by orderdate) as second_lag_cost, --上上一次消費金額 lead(cost,1) over(partition by name order by orderdate) as first_next_cost, --下一次消費金額 lead(cost,2) over(partition by name order by orderdate) as first_next_cost, --下下一次消費金額 first_value(orderdate) over(partition by name order by orderdate) as month_first_buy, --客戶首次購買的時間 last_value(orderdate) over(partition by name order by orderdate) as month_last_buy --分組后截止當前行客戶最后購買時間 from shj_2;

?
? 3、數據傾斜
傾斜的情況接觸不多,總結一下我的理解和別人的看法。數據傾斜簡單理解就是sql耗時長或在某一個reduce上半天不出結果。我們知道,hive是基于MR任務,如果在MR階段數據分配不均衡,就會導致傾斜。數據處理時,首先會進行map階段,對數據進行拆分并執行map函數,后根據partitioner接口,將數據分配到不同的reduce中進行最后的計算。理想情況下,數據均勻分配不會出現傾斜。但是由于partitioner本身是通過hash對key進行取模的特點存在一定問題,以及數據、腳本等原因,導致傾斜。處理數據傾斜,可以從sql、調整參數進行規避。
? I、SQL優化
a、Map-Join:在兩張表進行關聯時,將小表作為驅動表(左邊),執行MR時左邊的表會被寫入緩存中(小表不會出現內存溢出)提升執行效率。方式1/:查詢中添加/*+ MAPJOIN(SmallTableNmae)*/進行指定;方式2:設置系統參數自動判斷,
set hive.auto.convert.join=true;(自動開戶MAPJOIN優化);set hive.mapjoin.smalltable.filesize=10000000;(設置100M時自動啟用)
?
b、進行不適用distinct count;可以替換成group by
c、處理大表時,進行列裁剪(字段選擇),fiter操作(where條件限定)來減小任務文件
2、參數設置
a、hive.map.aggr=true;允許map端進行combiner操作(相當于reduce)
b、hive.groupby.skewindata=true;負載均衡,在使用group by時常用;
c、set hive.exec.parallel=true;set hive.exec.parallel.thread.number=16;允許并發,及最大并發數
d、還有一些不怎么用,如合并小文件、設置bitmap index
3、數據處理
a、主要對null值進行處理,設置為字符常量加隨機數或在filter操作時限定
b、建表時,合理設置分區以及字段類型
?
原創博客,轉載請注明出處!歡迎郵件溝通:shj8319@sina.com


 數據訪問篇)


)






 開始開發RESTFul接口)



)


