最早接觸大數據,常縈繞耳邊的一個詞「MapReduce」。它到底是什么,能做什么,原理又是什么?且聽下文講解。
是什么
MapReduce 即是一個編程模型,又是一個計算框架,它充分采用了分治的思想,將數據處理過程拆分成兩步:Map 和 Reduce。用戶只需要編寫 map() 和 reduce() 函數,就能使問題的計算實現分布式,并在Hadoop上執行。
數據處理
MapReduce 操作數據的最小單位是一個鍵值對。map 端的主要輸入是一對<key,value>值,經過 map 計算后輸出一對<key,value>,然后將相同的 key 合并,形成<key,value 集合>,再將這個<key,value 集合>輸入 reduce ,經過計算輸出零個或多個<key,value>對。
兩個重要的進程
JobTracker
JobTracker 在集群中負責任務調度和集群資源監控這兩個功能。TaskTracker 通過周期性的心跳向 JobTracker 匯報當前的健康狀況和狀態,心跳中包括自身計算資源的信息、被占用的計算資源的信息和正在運行中的任務的狀態信息。JobTracker 會根據各個 TaskTracker 周期性發送過來的心跳信息綜合考慮TaskTracker 的資源余量、作業優先級、作業提交時間等因素,為 TaskTracker 分配合適的任務。
JobTracker 提供了一個基于 web 的管理界面,可以通過 JobTracker:50030 端口訪問。
TaskTracker
TaskTracker 主要負責匯報心跳和執行 JobTracker 命令這兩個功能。命令主要包括5種:啟動命令、提交命令、殺死任務、殺死作業和重新初始化。
幾個概念
作業(Job) 和 任務(Task)
MapReduce 作業是用戶提交的最小單位,任務是 MapReduce 計算的最小單位。 簡單講,用戶提交的是一個MapReduce作業,一個 MapReduce 作業可以被拆分成兩種——Map 任務和 Reduce 任務。
槽(slot)
槽是Hadoop計算資源的表示模型,Hadoop 將各個節點上的多維度資源(CPU、內存等)抽象成一維度的槽。一個TaskTracker 能夠啟動的任務數量是由 TaskTracker 配置的任務槽決定的。
MapReduce 過程
一個MapReduce作業通常經過 input、map、combine、reduce、output 五個階段。combine 階段不一定發生,map輸出的中間結果分發到 reduce 的過程被稱為 shuffle。shuffle 階段還會發生 copy 和 sort。
兩幅重要的流程圖
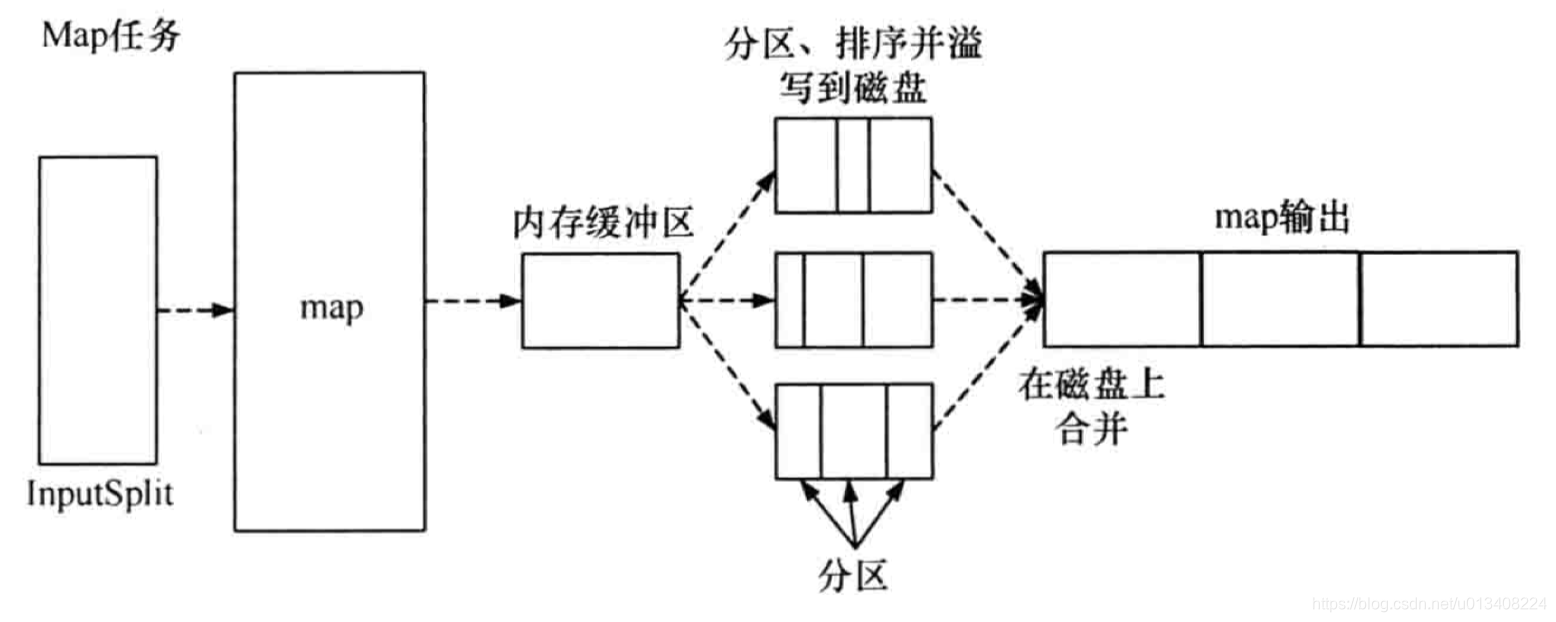
- map任務流程圖
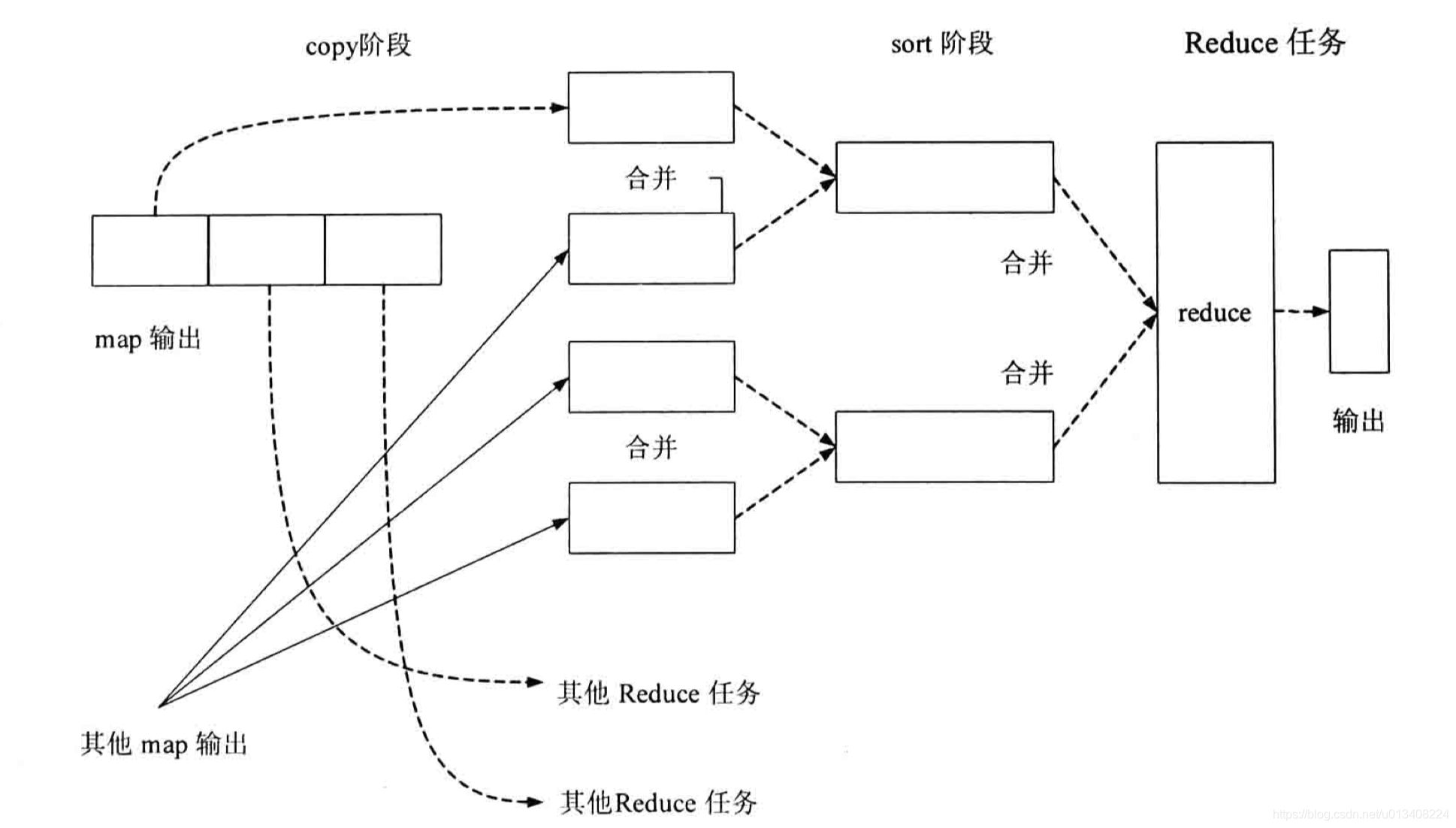
- reduce 任務流程圖
幾個重要的階段說明
map 函數處理后的中間結果會寫到本地磁盤上,在刷寫磁盤的過程中,還做了 partition 和 sort 操作。
map 函數輸出時,并不是簡單地刷寫磁盤,為了保證 I/O 效率,采取了先寫到內存的環形緩沖區,并做一次預排序。請結合map任務流程圖理解。
partition
在分區階段,通過對 key 取模,生成<partition,key,value>三元組,分區階段進行了一次內排序。
MemoryBuffer
內存緩沖區,保存 map 的結果和 partition 處理后的結果,默認大小為100M,溢寫閾值為80M。
spill(溢寫)
內存緩沖區達到閾值時,溢寫線程鎖住這80M的緩沖區,開始將數據寫到本地磁盤中,然后釋放內存。
每次溢寫都會生成一個數據文件,溢出的數據寫到磁盤前會對數據進行 sort 以及合并(combine)。
combine
combine 對map 函數的輸出結果進行早期聚合以減少傳輸的數據量,其作用其實和reduce 函數一樣。combine 的過程發生在 spill(溢寫) 階段。
combine 能夠提升程序性能,但并不是所有常見都適合使用 combine ,例如:求中值。
sort
MapReduce 計算框架主要用到了兩種排序:快速排序和歸并排序。在 Map 任務和 Reduce 任務的過程中,一共發生了三次排序操作:
- partition 過程中按照鍵值進行的內排序。
- map 任務完成之前,合并溢寫文件產生輸出文件時進行的一次 sort 操作。
- shuffle 過程的 sort 操作。
wordcount 實驗模擬
map 端編程代碼(map_a.py):
import sys
import rep =re.compile(r'\w+')
for line in sys.stdin:world_list =line.strip().split()for word in world_list:if len(word)<2:continuew_list =p.findall(word)if len(w_list)>0:w =w_list[0].lower()print "%s\t%d"%(w,1)
reduce 端編程代碼(red_b.py)
import sys
wt =0
cur_word =None
for line in sys.stdin:word,cnt =line.strip().split('\t')if cur_word ==None:cur_word =wordif cur_word !=word:print "%s\t%d"%(cur_word,wt)wt =0cur_word =wordwt =wt+int(cnt)
print "%s\t%d"%(cur_word,wt)
模擬命令
cat The_man_of_property.txt |python ./project/map_a.py | sort -k 1 |python ./project/red_b.py
輸出顯示




)
![[轉]QDir類及其用法總結](http://pic.xiahunao.cn/[轉]QDir類及其用法總結)



默認特性)









