Adaboost 中文名叫自適應提升算法,是一種boosting算法。
?
boosting算法的基本思想
對于一個復雜任務來說,單個專家的決策過于片面,需要集合多個專家的決策得到最終的決策,通俗講就是三個臭皮匠頂個諸葛亮。
對于給定的數據集,學習到一個較弱的分類器比學習到一個強分類器容易的多,boosting就是從弱學習器出發,反復學習,得到多個弱分類器,最后將這些弱分類器組合成強分類器。
?
boosting算法需要解決兩個問題
每一輪如何改變訓練樣本的權重
如何將弱分類器組合成強分類器
?
adaboost是這樣做的
1. 提高那些被前一輪弱分類器錯誤分類的樣本的權值,而降低那些被正確分類樣本的權值.,這樣下個分類器就能專注于那些不好識別的樣本,針對性的建立分類器。
2. 對于若分類器的組合,adaboost采取加權多數表決的方式,即加大分類錯誤率較小的弱分類器的權值,使其在表決中起較大作用,減小分類錯誤率較高的弱分類器的權值,使其在表決中起較小作用,
這可以理解為有些專家比較權威,他的意見要多采納,有些只是不知名的專家,可以少采納。
?
adaboost其實是一個加法模型,損失函數是指數損失函數,學習算法為前向分步算法的二分類學習方法。(其他學習算法如梯度下降)
加法模型
xgboost中其實也是加法模型,應該說boosting算法都是加法模型,而且還有很多算法也是加法模型,那什么是加法模型?
顧名思義,一個模型是由多個模型相加而得

那最終問題轉化為基于加法模型的損失最小化,即

通常這是一個十分復雜的優化問題,想要一步到位非常困難,如用梯度下降,所以就有了前向分步算法。
?
前向分步算法
前向分步算法是一種優化算法,可以解決上面加法模型的問題。
大致思路是,從前向后,每一步學習一個基分類器,使得整體損失函數更小一點,從而逐步逼近全局最小值。
?
算法流程

?
解釋一點: 新的學習器fm是在上個學習器fm-1的基礎上學習的,也就是說在學習fm時fm-1已經確定,所以求L(y, fm)的極小值就是求b(x;r)的極小值,即單個學習器的最小值。
實際上這和梯度下降的思路十分相似,每次減小一點,逼近一點,而且形式也一樣 fm=fm-1+βb
?
adaboost算法流程

?
?
?
誤差解釋
1. 誤差計算時除以了Σw,因為每輪迭代時,Σw是一個固定值,而且后面會說明其實它等于1,所以不用除這個。
2. 誤差計算時,分類正確為0,其權重被忽略,分類錯誤為1,其權重累加,所以是I(G!=y)
分類器權重解釋

權重更新解釋

組合分類器解釋
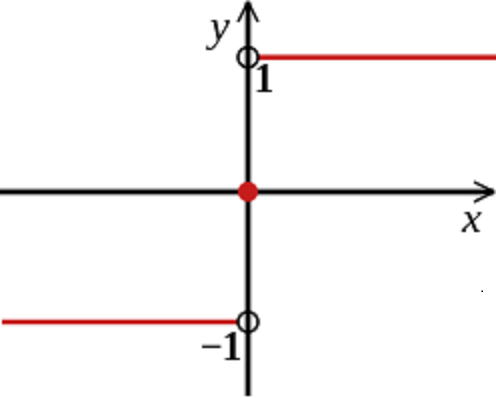
sign函數只能取1和-1,故adaboost為二分類。
當然可以通過修改實現多分類。
?
adaboost有很多種算法,但都大同小異,而且adaboost可以做回歸,思路也是大同小異,具體請百度
?
adaboost進階
正則化
adaboost每個學習器都是弱學習器,為什么還要正則化?其實不是正則化基學習器
fm=fm-1+αb(x,r),這是加法模型,α為基學習器的系數,可以理解為權重,
正則化是對加法模型增加一個學習率v,即fm=fm-1+vαb(x,r),這種方法適合于很多集成學習。
?
基分類器隨機化
像隨機森林一樣,隨機選特征,隨機選樣本
?
總結
理論上來講,adaboost的弱學習器可以是任何模型,但用的最多的是決策樹和神經網絡,決策樹是cart樹
優點:精度高,不容易過擬合
缺點:對異常值敏感,因為異常值可能獲得較大權重,最終影響整個模型
?
?
參考資料:
https://www.cnblogs.com/liuwu265/p/4693113.html?ptvd
https://zhuanlan.zhihu.com/p/59751960
https://zhuanlan.zhihu.com/p/42915999
https://blog.csdn.net/hahaha_2017/article/details/79852363
https://blog.csdn.net/guyuealian/article/details/70995333 原理-實例-代碼(簡明易懂)







![BZOJ1565[NOI2009]植物大戰僵尸——最大權閉合子圖+拓撲排序](http://pic.xiahunao.cn/BZOJ1565[NOI2009]植物大戰僵尸——最大權閉合子圖+拓撲排序)











