摘要:隨著互聯網的發展,數據的規模和類型都呈現一個爆炸性的增長,對于這么多類型的數據,如何進行有效的管理和存儲,包括數據的分析,這是大家要面臨的一個問題。在武漢云棲大會上,阿里云高級產品專家吳華劍做了名為“企業數據創新之旅-構建自己的數據湖”的精彩演講。
阿里云存儲產品系列
 ?
?隨著互聯網的發展,整個云存儲數據量的規模呈爆炸性的增長,包括日志型、交易、應用等數據,而且數據類型也越來越豐富。面對這樣的需求,阿里云存儲推出了一系列的云數據庫類型,包括塊存儲、文件存儲、對象存儲、OSS歸檔存儲和表格存儲等。對于傳統企業上云,阿里云也推出了面向混合云的產品,比如混合云存儲陣列、容災備份一體機、備份服務、閃電立方等產品。阿里云有這么全面的產品家族,那是什么支撐著呢?其實是因為阿里云有自研的分布式存儲系統:盤古高性能存儲引擎。目前盤古的存儲不僅支撐阿里云公有云上的存儲產品,也是阿里巴巴集團內部,像天貓、淘寶、螞蟻金服等各類服務存儲的基石。針對于面向金融、人工智能、能源、制造業等各個場景的低延時到高吞吐的存儲需求,阿里云都有相應的產品類型。
?
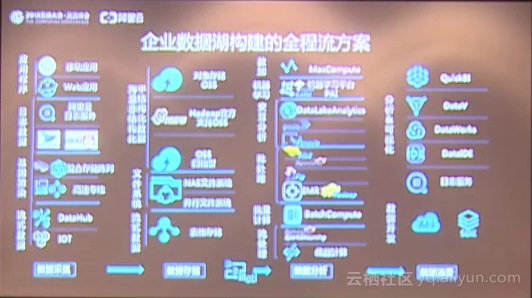
在整個企業數據湖的構建過程當中,從數據的采集到數據存儲再到分析和消費,其實是有分多個階段的,在這多個階段里面,阿里云推出了一系列的解決方案。例如在數據采集方面,阿里云可以支持應用程序數據、日志數據、基因數據、流失的數據等等。另外阿里云推出了阿里云日志存儲服務,OSS也支持像開源日志導入的服務,同時針對IoT的數據也有像IoT、DataHub這樣的數據采集的產品。在存儲方面,阿里云推出了對象存儲,可以支持海量的結構化和非結構化的數據存儲,同時OSS也是Hadoop官方支持的默認存儲類型,這也是中國唯一一家被Hadoop官方支持的存儲產品,用戶的Hadoop應用可以完全不改任何代碼去處理OSS上的數據。同時阿里云的表格存儲,能夠非常好的支持像IoT這樣的流失數據的存儲。在整個數據湖構建的采集、存儲、消費等整個流程,阿里云都提供了相應的解決方案,滿足大家對數據湖的構建要求。
企業應用構建案例
阿里云存儲其實不光是支持互聯網音視頻等普通數據的訪問和讀寫,如今利用阿里云存儲穩定、安全、可靠和高性能等的特點,結合阿里云豐富的機器學習平臺、大數據、批量計算等產品以及阿里云與Hadoop官方的合作,阿里云存儲可以進行離線分析、基因渲染等大規模數據的計算,滿足不同場景的數據處理需求。現在已經應用到新能源、新媒體、包括點播、直播等應用場景。下面是兩個企業應用構建的例子:
1.新媒體內容推薦系統 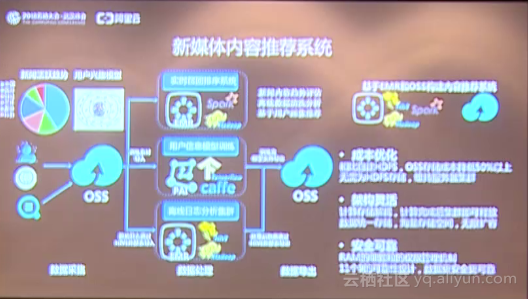 ?
?用戶的訪問日志,包括手機app、應用服務上收集的日志、新聞閱讀的記錄都可以導入到OSS上,滿足海量存儲的需求。同時Hadoop官方也支持OSS存儲的應用,因此用戶可以基于Hadoop生態的應用去搭建像離線分析的系統,并且可以利用機器學習進行用戶興趣的訓練,訓練完的模型數據也可以導入到OSS上面,形成數據處理的閉環,當用戶用完整個架構系統之后,整個數據存儲成本降低了50%以上。
2.批處理(在線視頻日志)
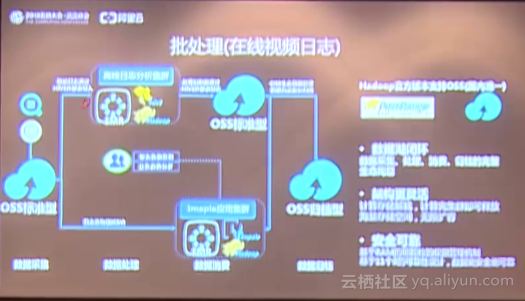 ?
?類似短視頻的在線視頻應用,如何保持競爭力呢?用戶需要對終端用戶訪問的一些視頻,做一些大數據的挖掘和分析,不斷地去改進自己的產品設計。用戶將日志數據上傳到OSS上面之后,可以通過阿里云的Hadoop離線分析系統做分析,同時可以基于Hadoop應用去搭建集群,進行數據交互分析。由于用戶每天產生的海量訪問日志非常大,可能經過一段時間以后這個數據就沒那么熱了,用戶不需要經常去分析和處理它,那用戶可以通過OSS生命周期管理功能對數據進行自動歸檔。整個用戶的數據采集、存儲、消費和自動歸檔等流程都可以在OSS上處理。
云存儲技術引擎 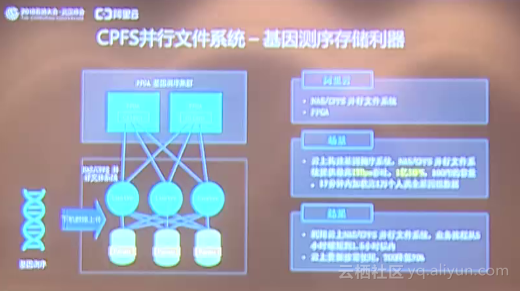 ?
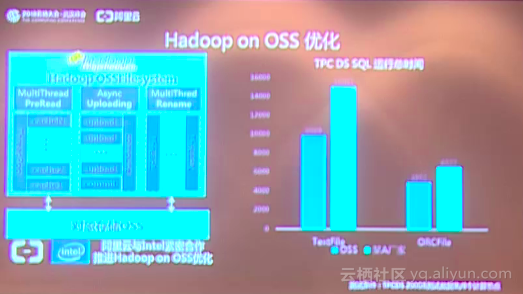
?阿里云存儲針對數據進行計算和分析,在近期又取得了巨大的進展。首先是阿里云對于文件系統家族,推出了CPFS并行文件系統,這個產品阿里云正在公測,而且有些做科研的客戶正在使用這個產品。CPFS并行文件系統有一個非常明顯的特點,它可以極大地提高阿里云單用戶的吞吐。同時阿里云和戰略合作伙伴Intel一起在Hadoop社區里面,針對Hadoop的應用訪問OSS做了大量的優化。Hadoop在訪問OSS的時候,阿里云在Hadoop的客戶端進行了多線程預讀的優化,同時在整個數據寫入到OSS的時候,阿里云也進行了異步的性能提升。另外對于元數據的操作,阿里云也進行了大量的優化。當整個系統優化完之后,阿里云進行了一個TPC DS測試,阿里云測試了200G的數據集并與其他廠商進行對比,阿里云OSS的運行效率提升了15%左右,可以為用戶節省15%的計算資源,不但提升了業務的效率,而且大大降低了成本。
?
同時阿里云OSS在服務端也進行了大量的技術優化,最近阿里云會提供一個服務端預讀的功能,阿里云面向像Hadoop的大數據分析、機器學習等場景會進行優化,會在近期上線,讓大家使用。關于服務端優化,現在也已經有客戶在使用,而且運行效率提升了35%以上,對客戶的業務有很大的幫助。另外OSS select現在也開始公測,原來的數據存儲到OSS之后,當讀取數據的時候需要把整個數據都讀取出來。比如搭一個spark應用的時候,需要把整個數據讀取出來之后再去做一些分析和處理,現在可以使用OSS select功能,只要使用簡單的SQL語句,就可以選取需要的內容,大大地減少運行的時間。阿里云也做了個基于OSS select的測試,整個運行時間從78秒減少到11秒,性能提升了600%。阿里云最近推出的DataLakeAnalytics產品,它可以支持對OSS上的產品做查詢分析,將OSS上存儲的CSV、TEXT、JSON和一些鏈式存儲的數據,可以使用DataLakeAnalytics做查詢分析,這個產品兼容標準SQL,包括JDBC、ODBC的標準,可以幫助大家快速去搭建一個查詢、分析的平臺,可以減少時間,提升研發效率。
以下是OSS select和DataLakeAnalytics的公測鏈接,大家可以掃描二維碼去申請公測。

?


![BZOJ1565[NOI2009]植物大戰僵尸——最大權閉合子圖+拓撲排序](http://pic.xiahunao.cn/BZOJ1565[NOI2009]植物大戰僵尸——最大權閉合子圖+拓撲排序)














計算加減乘除的BUG)

