一、time與datetime模塊
在Python中,通常有這幾種方式來表示時間:
時間戳(timestamp):通常來說,時間戳表示的是從1970年1月1日00:00:00開始按秒計算的偏移量。我們運行“type(time.time())”,返回的是float類型。
格式化的時間字符串(Format String)
結構化的時間(struct_time):struct_time元組共有9個元素共九個元素:(年,月,日,時,分,秒,一年中第幾周,一年中第幾天,夏令時)
1import time2 #--------------------------我們先以當前時間為準,讓大家快速認識三種形式的時間3 print(time.time()) # 時間戳:1487130156.419527
4 print(time.strftime("%Y-%m-%d %X")) #格式化的時間字符串:'2017-02-15 11:40:53'
5
6print(time.localtime()) #本地時區的struct_time7 print(time.gmtime()) #UTC時區的struct_time


%a Locale’s abbreviated weekday name.%A Locale’s full weekday name.%b Locale’s abbreviated month name.%B Locale’s full month name.%c Locale’s appropriate date and time representation.%d Day of the month as a decimal number [01,31].%H Hour (24-hour clock) as a decimal number [00,23].%I Hour (12-hour clock) as a decimal number [01,12].%j Day of the year as a decimal number [001,366].%m Month as a decimal number [01,12].%M Minute as a decimal number [00,59].%p Locale’s equivalent of either AM or PM. (1)%S Second as a decimal number [00,61]. (2)%U Week number of the year (Sunday as the first day of the week) as a decimal number [00,53]. All days in a new year preceding the first Sunday are considered to be in week 0. (3)%w Weekday as a decimal number [0(Sunday),6].%W Week number of the year (Monday as the first day of the week) as a decimal number [00,53]. All days in a new year preceding the first Monday are considered to be in week 0. (3)%x Locale’s appropriate date representation.%X Locale’s appropriate time representation.%y Year without century as a decimal number [00,99].%Y Year with century as a decimalnumber.%z Time zone offset indicating a positive or negative time difference from UTC/GMT of the form +HHMM or -HHMM, where H represents decimal hour digits and M represents decimal minute digits [-23:59, +23:59].%Z Time zone name (no characters ifno time zone exists).%% A literal '%' character.
格式化字符串的時間格式
其中計算機認識的時間只能是'時間戳'格式,而程序員可處理的或者說人類能看懂的時間有: '格式化的時間字符串','結構化的時間' ,于是有了下圖的轉換關系
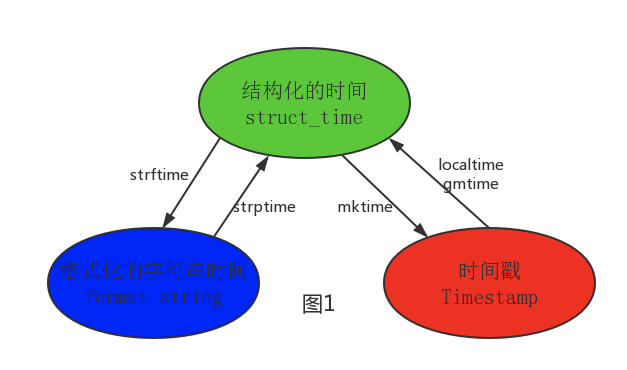
#--------------------------按圖1轉換時間
# localtime([secs])
# 將一個時間戳轉換為當前時區的struct_time。secs參數未提供,則以當前時間為準。
time.localtime()
time.localtime(1473525444.037215)
# gmtime([secs]) 和localtime()方法類似,gmtime()方法是將一個時間戳轉換為UTC時區(0時區)的struct_time。
# mktime(t) : 將一個struct_time轉化為時間戳。
print(time.mktime(time.localtime()))#1473525749.0# strftime(format[, t]) : 把一個代表時間的元組或者struct_time(如由time.localtime()和
# time.gmtime()返回)轉化為格式化的時間字符串。如果t未指定,將傳入time.localtime()。如果元組中任何一個
# 元素越界,ValueError的錯誤將會被拋出。
print(time.strftime("%Y-%m-%d %X", time.localtime()))#2016-09-11 00:49:56# time.strptime(string[, format])
# 把一個格式化時間字符串轉化為struct_time。實際上它和strftime()是逆操作。
print(time.strptime('2011-05-05 16:37:06', '%Y-%m-%d %X'))
#time.struct_time(tm_year=2011, tm_mon=5, tm_mday=5, tm_hour=16, tm_min=37, tm_sec=6,
# tm_wday=3, tm_yday=125, tm_isdst=-1)
#在這個函數中,format默認為:"%a %b %d %H:%M:%S %Y"。
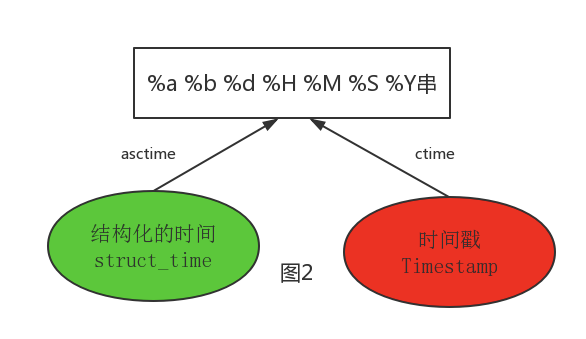
1 #--------------------------按圖2轉換時間2 # asctime([t]) : 把一個表示時間的元組或者struct_time表示為這種形式:'Sun Jun 20 23:21:05 1993'。3# 如果沒有參數,將會將time.localtime()作為參數傳入。4 print(time.asctime())#Sun Sep 11 00:43:43 2016
5
6# ctime([secs]) : 把一個時間戳(按秒計算的浮點數)轉化為time.asctime()的形式。如果參數未給或者為7# None的時候,將會默認time.time()為參數。它的作用相當于time.asctime(time.localtime(secs))。8 print(time.ctime()) # Sun Sep 11 00:46:38 2016
9 print(time.ctime(time.time())) # Sun Sep 11 00:46:38 2016
1 #--------------------------其他用法2# sleep(secs)3 # 線程推遲指定的時間運行,單位為秒。
datetime模塊
#時間加減
import datetime
# print(datetime.datetime.now()) #返回2016-08-19 12:47:03.941925#print(datetime.date.fromtimestamp(time.time()) ) # 時間戳直接轉成日期格式2016-08-19# print(datetime.datetime.now() )
# print(datetime.datetime.now()+ datetime.timedelta(3)) #當前時間+3天
# print(datetime.datetime.now()+ datetime.timedelta(-3)) #當前時間-3天
# print(datetime.datetime.now()+ datetime.timedelta(hours=3)) #當前時間+3小時
# print(datetime.datetime.now()+ datetime.timedelta(minutes=30)) #當前時間+30分
#
# c_time=datetime.datetime.now()
# print(c_time.replace(minute=3,hour=2)) #時間替換
二、random模塊
import random
print(random.random())#(0,1)----float大于0且小于1之間的小數
print(random.randint(1,3)) #[1,3] 大于等于1且小于等于3之間的整數
print(random.randrange(1,3)) #[1,3) 大于等于1且小于3之間的整數
print(random.choice([1,'23',[4,5]]))#1或者23或者[4,5]
print(random.sample([1,'23',[4,5]],2))#列表元素任意2個組合
print(random.uniform(1,3))#大于1小于3的小數,如1.927109612082716item=[1,3,5,7,9]
random.shuffle(item) #打亂item的順序,相當于"洗牌"print(item)
import random
def make_code(n):
res=''
for i inrange(n):
s1=chr(random.randint(65,90))
s2=str(random.randint(0,9))
res+=random.choice([s1,s2])returnres
print(make_code(9))
生成隨機驗證碼
三、os模塊
os模塊是與操作系統交互的一個接口
os.getcwd() 獲取當前工作目錄,即當前python腳本工作的目錄路徑
os.chdir("dirname") 改變當前腳本工作目錄;相當于shell下cd
os.curdir 返回當前目錄: ('.')
os.pardir 獲取當前目錄的父目錄字符串名:('..')
os.makedirs('dirname1/dirname2') 可生成多層遞歸目錄
os.removedirs('dirname1') 若目錄為空,則刪除,并遞歸到上一級目錄,如若也為空,則刪除,依此類推
os.mkdir('dirname') 生成單級目錄;相當于shell中mkdir dirname
os.rmdir('dirname') 刪除單級空目錄,若目錄不為空則無法刪除,報錯;相當于shell中rmdir dirname
os.listdir('dirname') 列出指定目錄下的所有文件和子目錄,包括隱藏文件,并以列表方式打印
os.remove() 刪除一個文件
os.rename("oldname","newname") 重命名文件/目錄
os.stat('path/filename') 獲取文件/目錄信息
os.sep 輸出操作系統特定的路徑分隔符,win下為"\\",Linux下為"/"os.linesep 輸出當前平臺使用的行終止符,win下為"\t\n",Linux下為"\n"os.pathsep 輸出用于分割文件路徑的字符串 win下為;,Linux下為:
os.name 輸出字符串指示當前使用平臺。win->'nt'; Linux->'posix'os.system("bash command") 運行shell命令,直接顯示
os.environ 獲取系統環境變量
os.path.abspath(path) 返回path規范化的絕對路徑
os.path.split(path) 將path分割成目錄和文件名二元組返回
os.path.dirname(path) 返回path的目錄。其實就是os.path.split(path)的第一個元素
os.path.basename(path) 返回path最后的文件名。如何path以/或\結尾,那么就會返回空值。即os.path.split(path)的第二個元素
os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False
os.path.isabs(path) 如果path是絕對路徑,返回True
os.path.isfile(path) 如果path是一個存在的文件,返回True。否則返回False
os.path.isdir(path) 如果path是一個存在的目錄,則返回True。否則返回False
os.path.join(path1[, path2[, ...]]) 將多個路徑組合后返回,第一個絕對路徑之前的參數將被忽略
os.path.getatime(path) 返回path所指向的文件或者目錄的最后存取時間
os.path.getmtime(path) 返回path所指向的文件或者目錄的最后修改時間
os.path.getsize(path) 返回path的大小
在Linux和Mac平臺上,該函數會原樣返回path,在windows平臺上會將路徑中所有字符轉換為小寫,并將所有斜杠轉換為飯斜杠。>>> os.path.normcase('c:/windows\\system32\\')'c:\\windows\\system32\\'規范化路徑,如..和/
>>> os.path.normpath('c://windows\\System32\\../Temp/')'c:\\windows\\Temp'
>>> a='/Users/jieli/test1/\\\a1/\\\\aa.py/../..'
>>>print(os.path.normpath(a))/Users/jieli/test1
os路徑處理
#方式一:推薦使用
import os
#具體應用
import os,sys
possible_topdir=os.path.normpath(os.path.join(
os.path.abspath(__file__),
os.pardir, #上一級
os.pardir,
os.pardir
))
sys.path.insert(0,possible_topdir)
#方式二:不推薦使用
os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
四、sys模塊
sys.argv 命令行參數List,第一個元素是程序本身路徑
sys.exit(n) 退出程序,正常退出時exit(0)
sys.version 獲取Python解釋程序的版本信息
sys.maxint 最大的Int值
sys.path 返回模塊的搜索路徑,初始化時使用PYTHONPATH環境變量的值
sys.platform 返回操作系統平臺名稱
打印進度條
#=========知識儲備==========#進度條的效果
[# ]
[## ]
[### ]
[#### ]
#指定寬度
print('[%-15s]' %'#')
print('[%-15s]' %'##')
print('[%-15s]' %'###')
print('[%-15s]' %'####')
#打印%print('%s%%' %(100)) #第二個%號代表取消第一個%的特殊意義
#可傳參來控制寬度
print('[%%-%ds]' %50) #[%-50s]
print(('[%%-%ds]' %50) %'#')
print(('[%%-%ds]' %50) %'##')
print(('[%%-%ds]' %50) %'###')
#=========實現打印進度條函數==========import sys
import time
def progress(percent,width=50):if percent >= 1:
percent=1show_str=('[%%-%ds]' %width) %(int(width*percent)*'#')
print('\r%s %d%%' %(show_str,int(100*percent)),file=sys.stdout,flush=True,end='')
#=========應用==========data_size=1025recv_size=0
while recv_size
time.sleep(0.1) #模擬數據的傳輸延遲
recv_size+=1024#每次收1024
percent=recv_size/data_size #接收的比例
progress(percent,width=70) #進度條的寬度70
優化版本:
def progress(percent,width=50):
if percent > 1:
percent=1
show_str=('[%%-%ds]' %width) %(int(width*percent) * '#')
print('\r%s %d%%' %(show_str,int(100*percent)),end='')
import time
recv_size=0
total_size=100
while recv_size < total_size:
time.sleep(0.1)
recv_size+=1
percent=recv_size / total_size
progress(percent)
五、shutil模塊
高級的 文件、文件夾、壓縮包 處理模塊
shutil.copyfileobj(fsrc, fdst[, length])
將文件內容拷貝到另一個文件中
import shutil
shutil.copyfileobj(open('old.xml','r'), open('new.xml', 'w'))
shutil.copyfile(src, dst)
拷貝文件
shutil.copyfile('f1.log', 'f2.log') #目標文件無需存在
shutil.copymode(src, dst)
僅拷貝權限。內容、組、用戶均不變
shutil.copymode('f1.log', 'f2.log') #目標文件必須存在
shutil.copystat(src, dst)
僅拷貝狀態的信息,包括:mode bits, atime, mtime, flags
shutil.copystat('f1.log', 'f2.log') #目標文件必須存在
shutil.copy(src, dst)
拷貝文件和權限
import shutil
shutil.copy('f1.log', 'f2.log')
shutil.copy2(src, dst)
拷貝文件和狀態信息
import shutil
shutil.copy2('f1.log', 'f2.log')
shutil.ignore_patterns(*patterns)
shutil.copytree(src, dst, symlinks=False, ignore=None)
遞歸的去拷貝文件夾
import shutil
shutil.copytree('folder1', 'folder2', ignore=shutil.ignore_patterns('*.pyc', 'tmp*')) #目標目錄不能存在,注意對folder2目錄父級目錄要有可寫權限,ignore的意思是排除
import shutil
shutil.copytree('f1', 'f2', symlinks=True, ignore=shutil.ignore_patterns('*.pyc', 'tmp*'))'''通常的拷貝都把軟連接拷貝成硬鏈接,即對待軟連接來說,創建新的文件'''
拷貝軟鏈接
shutil.rmtree(path[, ignore_errors[, onerror]])
遞歸的去刪除文件
import shutil
shutil.rmtree('folder1')
shutil.move(src, dst)
遞歸的去移動文件,它類似mv命令,其實就是重命名。
import shutil
shutil.move('folder1', 'folder3')
shutil.make_archive(base_name, format,...)
創建壓縮包并返回文件路徑,例如:zip、tar
創建壓縮包并返回文件路徑,例如:zip、tar
base_name: 壓縮包的文件名,也可以是壓縮包的路徑。只是文件名時,則保存至當前目錄,否則保存至指定路徑,
如 data_bak =>保存至當前路徑
如:/tmp/data_bak =>保存至/tmp/
format:壓縮包種類,“zip”, “tar”, “bztar”,“gztar”
root_dir:要壓縮的文件夾路徑(默認當前目錄)
owner:用戶,默認當前用戶
group:組,默認當前組
logger:用于記錄日志,通常是logging.Logger對象
#將 /data 下的文件打包放置當前程序目錄
import shutil
ret= shutil.make_archive("data_bak", 'gztar', root_dir='/data')
#將/data下的文件打包放置 /tmp/目錄
import shutil
ret= shutil.make_archive("/tmp/data_bak", 'gztar', root_dir='/data')
shutil 對壓縮包的處理是調用 ZipFile 和 TarFile 兩個模塊來進行的,詳細:
import zipfile
# 壓縮
z= zipfile.ZipFile('laxi.zip', 'w')
z.write('a.log')
z.write('data.data')
z.close()
# 解壓
z= zipfile.ZipFile('laxi.zip', 'r')
z.extractall(path='.')
z.close()
zipfile壓縮解壓縮
import tarfile
# 壓縮>>> t=tarfile.open('/tmp/egon.tar','w')>>> t.add('/test1/a.py',arcname='a.bak')>>> t.add('/test1/b.py',arcname='b.bak')>>>t.close()
# 解壓>>> t=tarfile.open('/tmp/egon.tar','r')>>> t.extractall('/egon')>>> t.close()
tarfile壓縮解壓縮
六、json&pickle模塊
之前我們學習過用eval內置方法可以將一個字符串轉成python對象,不過,eval方法是有局限性的,對于普通的數據類型,json.loads和eval都能用,但遇到特殊類型的時候,eval就不管用了,所以eval的重點還是通常用來執行一個字符串表達式,并返回表達式的值。
import json
x="[null,true,false,1]"print(eval(x)) #報錯,無法解析null類型,而json就可以
print(json.loads(x))
什么是序列化?
我們把對象(變量)從內存中變成可存儲或傳輸的過程稱之為序列化,在Python中叫pickling,在其他語言中也被稱之為serialization,marshalling,flattening等等,都是一個意思。
為什么要序列化?
1:持久保存狀態
需知一個軟件/程序的執行就在處理一系列狀態的變化,在編程語言中,'狀態'會以各種各樣有結構的數據類型(也可簡單的理解為變量)的形式被保存在內存中。
內存是無法永久保存數據的,當程序運行了一段時間,我們斷電或者重啟程序,內存中關于這個程序的之前一段時間的數據(有結構)都被清空了。
在斷電或重啟程序之前將程序當前內存中所有的數據都保存下來(保存到文件中),以便于下次程序執行能夠從文件中載入之前的數據,然后繼續執行,這就是序列化。
具體的來說,你玩使命召喚闖到了第13關,你保存游戲狀態,關機走人,下次再玩,還能從上次的位置開始繼續闖關。或如,虛擬機狀態的掛起等。
2:跨平臺數據交互
序列化之后,不僅可以把序列化后的內容寫入磁盤,還可以通過網絡傳輸到別的機器上,如果收發的雙方約定好實用一種序列化的格式,那么便打破了平臺/語言差異化帶來的限制,實現了跨平臺數據交互。
反過來,把變量內容從序列化的對象重新讀到內存里稱之為反序列化,即unpickling。
如何序列化之json和pickle:
json
如果我們要在不同的編程語言之間傳遞對象,就必須把對象序列化為標準格式,比如XML,但更好的方法是序列化為JSON,因為JSON表示出來就是一個字符串,可以被所有語言讀取,也可以方便地存儲到磁盤或者通過網絡傳輸。JSON不僅是標準格式,并且比XML更快,而且可以直接在Web頁面中讀取,非常方便。
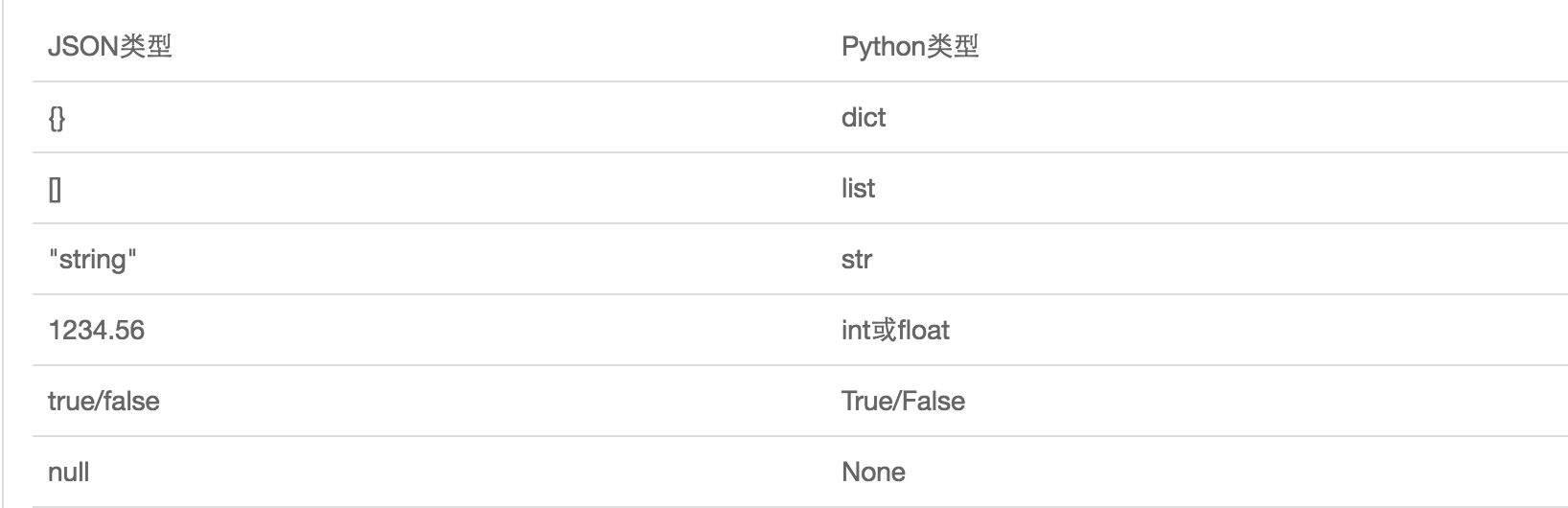
JSON表示的對象就是標準的JavaScript語言的對象,JSON和Python內置的數據類型對應如下:

Json模塊提供了四個功能:dumps、dump、loads、load
import json
dic= {'k1':'v1','k2':'v2','k3':'v3'}
str_dic=json.dumps(dic) #序列化:將一個字典轉換成一個字符串
print(type(str_dic),str_dic) # {"k3": "v3", "k1": "v1", "k2": "v2"}
#注意,json轉換完的字符串類型的字典中的字符串是由""表示的
dic2=json.loads(str_dic) #反序列化:將一個字符串格式的字典轉換成一個字典
#注意,要用json的loads功能處理的字符串類型的字典中的字符串必須由""表示
print(type(dic2),dic2) # {'k1': 'v1', 'k2': 'v2', 'k3': 'v3'}
list_dic= [1,['a','b','c'],3,{'k1':'v1','k2':'v2'}]
str_dic=json.dumps(list_dic) #也可以處理嵌套的數據類型
print(type(str_dic),str_dic) # [1, ["a", "b", "c"], 3, {"k1": "v1", "k2": "v2"}]
list_dic2=json.loads(str_dic)
print(type(list_dic2),list_dic2) # [1, ['a', 'b', 'c'], 3, {'k1': 'v1', 'k2': 'v2'}]
loads和dumps
import json
f= open('json_file','w')
dic= {'k1':'v1','k2':'v2','k3':'v3'}
json.dump(dic,f) #dump方法接收一個文件句柄,直接將字典轉換成json字符串寫入文件
f.close()
f= open('json_file')
dic2=json.load(f) #load方法接收一個文件句柄,直接將文件中的json字符串轉換成數據結構返回
f.close()
print(type(dic2),dic2)
load和dump
import json
#dct="{'1':111}"#json 不認單引號
#dct=str({"1":111})#報錯,因為生成的數據還是單引號:{'one': 1}
dct='{"1":"111"}'print(json.loads(dct))
#conclusion:
# 無論數據是怎樣創建的,只要滿足json格式,就可以json.loads出來,不一定非要dumps的數據才能loads
注意點
pickle

import pickle
dic={'name':'alvin','age':23,'sex':'male'}
print(type(dic))#j=pickle.dumps(dic)
print(type(j))#f=open('序列化對象_pickle','wb')#注意是w是寫入str,wb是寫入bytes,j是'bytes'f.write(j) #-------------------等價于pickle.dump(dic,f)
f.close()
#-------------------------反序列化
import pickle
f=open('序列化對象_pickle','rb')
data=pickle.loads(f.read())# 等價于data=pickle.load(f)
print(data['age'])
Pickle的問題和所有其他編程語言特有的序列化問題一樣,就是它只能用于Python,并且可能不同版本的Python彼此都不兼容,因此,只能用Pickle保存那些不重要的數據,不能成功地反序列化也沒關系。
七、logging模塊
日志級別
CRITICAL = 50 #FATAL =CRITICAL
ERROR= 40WARNING= 30 #WARN =WARNING
INFO= 20DEBUG= 10NOTSET= 0 #不設置
默認級別為warning,默認打印到終端
import logging
logging.debug('調試debug')
logging.info('消息info')
logging.warning('警告warn')
logging.error('錯誤error')
logging.critical('嚴重critical')'''WARNING:root:警告warn
ERROR:root:錯誤error
CRITICAL:root:嚴重critical'''
為logging模塊指定全局配置,針對所有logger有效,控制打印到文件中
可在logging.basicConfig()函數中通過具體參數來更改logging模塊默認行為,可用參數有
filename:用指定的文件名創建FiledHandler(后邊會具體講解handler的概念),這樣日志會被存儲在指定的文件中。
filemode:文件打開方式,在指定了filename時使用這個參數,默認值為“a”還可指定為“w”。
format:指定handler使用的日志顯示格式。
datefmt:指定日期時間格式。
level:設置rootlogger(后邊會講解具體概念)的日志級別
stream:用指定的stream創建StreamHandler。可以指定輸出到sys.stderr,sys.stdout或者文件,默認為sys.stderr。若同時列出了filename和stream兩個參數,則stream參數會被忽略。
#格式%(name)s:Logger的名字,并非用戶名,詳細查看%(levelno)s:數字形式的日志級別%(levelname)s:文本形式的日志級別%(pathname)s:調用日志輸出函數的模塊的完整路徑名,可能沒有%(filename)s:調用日志輸出函數的模塊的文件名%(module)s:調用日志輸出函數的模塊名%(funcName)s:調用日志輸出函數的函數名%(lineno)d:調用日志輸出函數的語句所在的代碼行%(created)f:當前時間,用UNIX標準的表示時間的浮 點數表示%(relativeCreated)d:輸出日志信息時的,自Logger創建以 來的毫秒數%(asctime)s:字符串形式的當前時間。默認格式是 “2003-07-08 16:49:45,896”。逗號后面的是毫秒%(thread)d:線程ID。可能沒有%(threadName)s:線程名。可能沒有%(process)d:進程ID。可能沒有%(message)s:用戶輸出的消息
format參數中可能用到的格式化串:
%(name)s Logger的名字
%(levelno)s 數字形式的日志級別
%(levelname)s 文本形式的日志級別
%(pathname)s 調用日志輸出函數的模塊的完整路徑名,可能沒有
%(filename)s 調用日志輸出函數的模塊的文件名
%(module)s 調用日志輸出函數的模塊名
%(funcName)s 調用日志輸出函數的函數名
%(lineno)d 調用日志輸出函數的語句所在的代碼行
%(created)f 當前時間,用UNIX標準的表示時間的浮 點數表示
%(relativeCreated)d 輸出日志信息時的,自Logger創建以 來的毫秒數
%(asctime)s 字符串形式的當前時間。默認格式是 “2003-07-08 16:49:45,896”。逗號后面的是毫秒
%(thread)d 線程ID。可能沒有
%(threadName)s 線程名。可能沒有
%(process)d 進程ID。可能沒有
%(message)s用戶輸出的消息
#========使用
import logging
logging.basicConfig(filename='access.log',
format='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s',
datefmt='%Y-%m-%d %H:%M:%S %p',
level=10)
logging.debug('調試debug')
logging.info('消息info')
logging.warning('警告warn')
logging.error('錯誤error')
logging.critical('嚴重critical')
#========結果
access.log內容:
2017-07-28 20:32:17 PM - root - DEBUG -test: 調試debug
2017-07-28 20:32:17 PM - root - INFO -test: 消息info
2017-07-28 20:32:17 PM - root - WARNING -test: 警告warn
2017-07-28 20:32:17 PM - root - ERROR -test: 錯誤error
2017-07-28 20:32:17 PM - root - CRITICAL -test: 嚴重critical
part2: 可以為logging模塊指定模塊級的配置,即所有logger的配置
logging模塊的Formatter,Handler,Logger,Filter對象
原理圖:
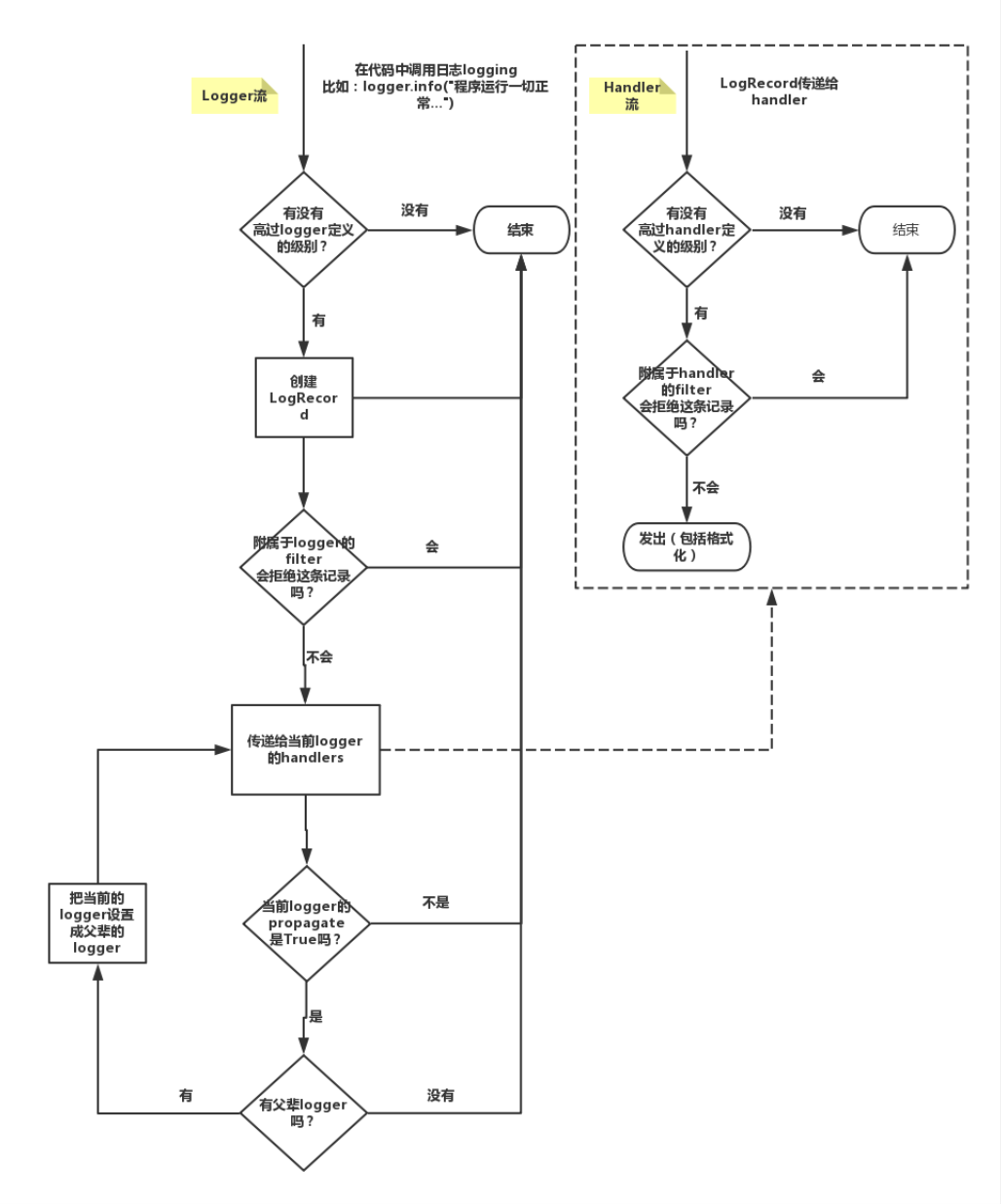
logger:產生日志的對象
Filter:過濾日志的對象
Handler:接收日志然后控制打印到不同的地方,FileHandler用來打印到文件中,StreamHandler用來打印到終端
Formatter對象:可以定制不同的日志格式對象,然后綁定給不同的Handler對象使用,以此來控制不同的Handler的日志格式'''critical=50error=40warning=30info= 20debug=10
'''import logging
#1、logger對象:負責產生日志,然后交給Filter過濾,然后交給不同的Handler輸出
logger=logging.getLogger(__file__)
#2、Filter對象:不常用,略
#3、Handler對象:接收logger傳來的日志,然后控制輸出
h1=logging.FileHandler('t1.log') #打印到文件
h2=logging.FileHandler('t2.log') #打印到文件
h3=logging.StreamHandler() #打印到終端
#4、Formatter對象:日志格式
formmater1=logging.Formatter('%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s',
datefmt='%Y-%m-%d %H:%M:%S %p',)
formmater2=logging.Formatter('%(asctime)s : %(message)s',
datefmt='%Y-%m-%d %H:%M:%S %p',)
formmater3=logging.Formatter('%(name)s %(message)s',)
#5、為Handler對象綁定格式
h1.setFormatter(formmater1)
h2.setFormatter(formmater2)
h3.setFormatter(formmater3)
#6、將Handler添加給logger并設置日志級別
logger.addHandler(h1)
logger.addHandler(h2)
logger.addHandler(h3)
logger.setLevel(10)
#7、測試
logger.debug('debug')
logger.info('info')
logger.warning('warning')
logger.error('error')
logger.critical('critical')
Logger與Handler的級別
logger是第一級過濾,然后才能到handler,我們可以給logger和handler同時設置level,但是需要注意的是
Logger is also the first to filter the message based on a level — if you set the logger to INFO, and all handlers to DEBUG, you still won't receive DEBUG messages on handlers — they'll be rejected by the logger itself. If you set logger to DEBUG, but all handlers to INFO, you won't receive any DEBUG messages either — because while the logger says "ok, process this", the handlers reject it (DEBUG < INFO).
#驗證
import logging
form=logging.Formatter('%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s',
datefmt='%Y-%m-%d %H:%M:%S %p',)
ch=logging.StreamHandler()
ch.setFormatter(form)
# ch.setLevel(10)
ch.setLevel(20)
l1=logging.getLogger('root')
# l1.setLevel(20)
l1.setLevel(10)
l1.addHandler(ch)
l1.debug('l1 debug')
重要,重要,重要!!!
Logger的繼承(了解)
import logging
formatter=logging.Formatter('%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s',
datefmt='%Y-%m-%d %H:%M:%S %p',)
ch=logging.StreamHandler()
ch.setFormatter(formatter)
logger1=logging.getLogger('root')
logger2=logging.getLogger('root.child1')
logger3=logging.getLogger('root.child1.child2')
logger1.addHandler(ch)
logger2.addHandler(ch)
logger3.addHandler(ch)
logger1.setLevel(10)
logger2.setLevel(10)
logger3.setLevel(10)
logger1.debug('log1 debug')
logger2.debug('log2 debug')
logger3.debug('log3 debug')'''2017-07-28 22:22:05 PM - root - DEBUG -test: log1 debug2017-07-28 22:22:05 PM - root.child1 - DEBUG -test: log2 debug2017-07-28 22:22:05 PM - root.child1 - DEBUG -test: log2 debug2017-07-28 22:22:05 PM - root.child1.child2 - DEBUG -test: log3 debug2017-07-28 22:22:05 PM - root.child1.child2 - DEBUG -test: log3 debug2017-07-28 22:22:05 PM - root.child1.child2 - DEBUG -test: log3 debug'''
了解即可
logging應用
"""logging配置"""import os
import logging.config
# 定義三種日志輸出格式 開始
standard_format= '[%(asctime)s][%(threadName)s:%(thread)d][task_id:%(name)s][%(filename)s:%(lineno)d]'\'[%(levelname)s][%(message)s]'#其中name為getlogger指定的名字
simple_format= '[%(levelname)s][%(asctime)s][%(filename)s:%(lineno)d]%(message)s'id_simple_format= '[%(levelname)s][%(asctime)s] %(message)s'# 定義日志輸出格式 結束
logfile_dir=os.path.dirname(os.path.abspath(__file__)) # log文件的目錄
logfile_name= 'all2.log'# log文件名
# 如果不存在定義的日志目錄就創建一個ifnot os.path.isdir(logfile_dir):
os.mkdir(logfile_dir)
# log文件的全路徑
logfile_path=os.path.join(logfile_dir, logfile_name)
# log配置字典
LOGGING_DIC={'version': 1,'disable_existing_loggers': False,'formatters': {'standard': {'format': standard_format
},'simple': {'format': simple_format
},
},'filters': {},'handlers': {
#打印到終端的日志'console': {'level': 'DEBUG','class': 'logging.StreamHandler', # 打印到屏幕'formatter': 'simple'},
#打印到文件的日志,收集info及以上的日志'default': {'level': 'DEBUG','class': 'logging.handlers.RotatingFileHandler', # 保存到文件'formatter': 'standard','filename': logfile_path, # 日志文件'maxBytes': 1024*1024*5, # 日志大小 5M'backupCount': 5,'encoding': 'utf-8', # 日志文件的編碼,再也不用擔心中文log亂碼了
},
},'loggers': {
#logging.getLogger(__name__)拿到的logger配置'': {'handlers': ['default', 'console'], # 這里把上面定義的兩個handler都加上,即log數據既寫入文件又打印到屏幕'level': 'DEBUG','propagate': True, # 向上(更高level的logger)傳遞
},
},
}
def load_my_logging_cfg():
logging.config.dictConfig(LOGGING_DIC) # 導入上面定義的logging配置
logger=logging.getLogger(__name__) # 生成一個log實例
logger.info('It works!') # 記錄該文件的運行狀態if __name__ == '__main__':
load_my_logging_cfg()
logging配置文件
"""MyLogging Test"""import time
import logging
import my_logging # 導入自定義的logging配置
logger=logging.getLogger(__name__) # 生成logger實例
def demo():
logger.debug("start range... time:{}".format(time.time()))
logger.info("中文測試開始。。。")for i in range(10):
logger.debug("i:{}".format(i))
time.sleep(0.2)else:
logger.debug("over range... time:{}".format(time.time()))
logger.info("中文測試結束。。。")if __name__ == "__main__":
my_logging.load_my_logging_cfg() # 在你程序文件的入口加載自定義logging配置
demo()
應用
注意注意注意:
#1、有了上述方式我們的好處是:所有與logging模塊有關的配置都寫到字典中就可以了,更加清晰,方便管理
#2、我們需要解決的問題是:1、從字典加載配置:logging.config.dictConfig(settings.LOGGING_DIC)2、拿到logger對象來產生日志
logger對象都是配置到字典的loggers 鍵對應的子字典中的
按照我們對logging模塊的理解,要想獲取某個東西都是通過名字,也就是key來獲取的
于是我們要獲取不同的logger對象就是
logger=logging.getLogger('loggers子字典的key名')
但問題是:如果我們想要不同logger名的logger對象都共用一段配置,那么肯定不能在loggers子字典中定義n個key'loggers': {'l1': {'handlers': ['default', 'console'], #'level': 'DEBUG','propagate': True, # 向上(更高level的logger)傳遞
},'l2: {
'handlers': ['default', 'console'],'level': 'DEBUG','propagate': False, # 向上(更高level的logger)傳遞
},'l3': {'handlers': ['default', 'console'], #'level': 'DEBUG','propagate': True, # 向上(更高level的logger)傳遞
},
}
#我們的解決方式是,定義一個空的key'loggers': {'': {'handlers': ['default', 'console'],'level': 'DEBUG','propagate': True,
},
}
這樣我們再取logger對象時
logging.getLogger(__name__),不同的文件__name__不同,這保證了打印日志時標識信息不同,但是拿著該名字去loggers里找key名時卻發現找不到,于是默認使用key=''的配置
!!!關于如何拿到logger對象的詳細解釋!!!
另外一個django的配置,瞄一眼就可以,跟上面的一樣
#logging_config.py
LOGGING={'version': 1,'disable_existing_loggers': False,'formatters': {'standard': {'format': '[%(asctime)s][%(threadName)s:%(thread)d][task_id:%(name)s][%(filename)s:%(lineno)d]'
'[%(levelname)s][%(message)s]'},'simple': {'format': '[%(levelname)s][%(asctime)s][%(filename)s:%(lineno)d]%(message)s'},'collect': {'format': '%(message)s'}
},'filters': {'require_debug_true': {'()': 'django.utils.log.RequireDebugTrue',
},
},'handlers': {
#打印到終端的日志'console': {'level': 'DEBUG','filters': ['require_debug_true'],'class': 'logging.StreamHandler','formatter': 'simple'},
#打印到文件的日志,收集info及以上的日志'default': {'level': 'INFO','class': 'logging.handlers.RotatingFileHandler', # 保存到文件,自動切'filename': os.path.join(BASE_LOG_DIR, "xxx_info.log"), # 日志文件'maxBytes': 1024 * 1024 * 5, # 日志大小 5M'backupCount': 3,'formatter': 'standard','encoding': 'utf-8',
},
#打印到文件的日志:收集錯誤及以上的日志'error': {'level': 'ERROR','class': 'logging.handlers.RotatingFileHandler', # 保存到文件,自動切'filename': os.path.join(BASE_LOG_DIR, "xxx_err.log"), # 日志文件'maxBytes': 1024 * 1024 * 5, # 日志大小 5M'backupCount': 5,'formatter': 'standard','encoding': 'utf-8',
},
#打印到文件的日志'collect': {'level': 'INFO','class': 'logging.handlers.RotatingFileHandler', # 保存到文件,自動切'filename': os.path.join(BASE_LOG_DIR, "xxx_collect.log"),'maxBytes': 1024 * 1024 * 5, # 日志大小 5M'backupCount': 5,'formatter': 'collect','encoding': "utf-8"}
},'loggers': {
#logging.getLogger(__name__)拿到的logger配置'': {'handlers': ['default', 'console', 'error'],'level': 'DEBUG','propagate': True,
},
#logging.getLogger('collect')拿到的logger配置'collect': {'handlers': ['console', 'collect'],'level': 'INFO',
}
},
}
#-----------# 用法:拿到倆個logger
logger=logging.getLogger(__name__) #線上正常的日志
collect_logger= logging.getLogger("collect") #領導說,需要為領導們單獨定制領導們看的日志
View Code




)
)





單元格函數,OP參數)



)



