大家好,我是若川。持續組織了6個月源碼共讀活動,感興趣的可以點此加我微信 ruochuan12?參與,每周大家一起學習200行左右的源碼,共同進步。同時極力推薦訂閱我寫的《學習源碼整體架構系列》?包含20余篇源碼文章。歷史面試系列
本文來自讀者@漫思維 投稿授權
原文鏈接:https://juejin.cn/post/7072677637117706270
1前言
以下我會列舉出我業務中遇到的問題難點及相對應的解決方法,解釋簡繁體插件怎么誕生的整個過程
2背景
目前開發工作有大量的營銷活動需要編寫,特點是小而多,同時現階段項目需要做大陸與港臺兩個版本
3現階段實現的方案
先做完大陸版本,最后再復刻一份代碼, 改成港臺版本
將項目中的漢字、價格、登錄方式進行替換。
4存在的問題
首先復制來復制去就不是一個很好的方案,容易復制出問題,其次兩個版本都是需要同一個時間點上線,復刻代碼的代碼的時機存在問題,如果復刻的過早,如果提測階段大陸版本有bug, 那么就需要修改兩份bug, 如果復刻的過晚那么會存在港臺版本測試時間不足,也易導致問題發生。
簡繁體轉換,都是將簡體手動復制到谷歌翻譯網頁端中翻譯好,再手動替換,繁瑣且工程量大, 登錄方式需要單獨的復制一份。
5兩個版本之間存在以下不同點
登錄方式的不同, 大陸主要是用賬號密碼登錄,而港臺使用谷歌、臉書、蘋果登錄
價格、單位不同,¥ 與 NT$
漢字的形式不同,中文簡體與中文繁體
核心問題在于復刻出一份項目存在的工作量與潛在風險較大,所以需要將兩個項目合成一個項目,怎么解決?
6解決方案
1. 將兩個項目合并成一個項目
如果需要將兩個項目合成一個項目,并解決以上分析出來的不同點,那么顯而易見,需要有個一標識去區分,那么使用環境變量解決這個問題是非常合適的,以vue項目舉例, 可以編寫對應的環境變量配置。
大陸版本生產環境:.env
VUE_APP_ENV=prod
VUE_APP_PUBLIC_PATH=/mainland大陸版本開發環境:.env
VUE_APP_ENV=dev
VUE_APP_PUBLIC_PATH=/mainland港臺版本開發環境:.env.ht
VUE_APP_ENV=ht
VUE_APP_PUBLIC_PATH=/ht
NODE_ENV=productionpackage.json
"serve":?"vue-cli-service?serve",
"build":?"vue-cli-service?build",
"build:ht":?"vue-cli-service?build?--mode?ht",可以看到這里使用了一個自定義變量 VUE_APP_ENV, 在項目代碼中就可以使用 process.env.VUE_APP_ENV 去做區分當前是大陸還是港臺了,同時為什么不使用NODE_ENV作為變量,因為該變量往往會有其他用途,如當NODE_ENV設置為production 時,打包時會做一些如壓縮等優化操作。
注: 港臺版本不做測試環境的區分,因為往往大陸版的邏輯沒有問題,港臺版的就沒有問題,所以只需要基于大陸版開發,港臺版只需要最后打包一次即可 **(測試環境可選,只需要多添加一個配置即可)**。
其他注意點: process.env.VUE_APP_ENV通常只能在node環境下才能訪問的,但是vue-cli創建項目會自動將.env里的變量注入到運行時環境中,也就是使用一個全局變量存起來,通常是使用webpack的define-plugin插件實現的。
解決了環境變量的問題,接下來的工作就比較好進行了。
2. 解決登錄方式的不同
將兩套登錄封裝成兩個不同的組件,因為登錄往往涉及到一些全局狀態,項目一般都會使用vuex等全局狀態管理工具,所以默認使用vuex儲存狀態,把整個包含登錄邏輯的代碼制作成一個項目的基礎模板,使用自定義腳手架拉取即可,同時注意使用vuex時,為登錄相關的狀態,放置到一個module下,這樣基于該模板創建項目后, 每個項目的其它狀態單獨再寫module即可,避免修改登錄的module。
自定義腳手架:交互式創建項目,輸入一些選項,如項目名稱,項目描述之類的,再從gitlab等遠程倉庫拉取已經寫好的模板,將模板中的一些特定變量,使用模板引擎將模板中的項目名稱等替換,最終產生一個新的項目。(腳手架還有其他用途,這里只描述使用它創建一個簡單的項目)
沒有腳手架那就只能使用
git clone下來后再修改項目名稱之類的東西,會增加一點額外的工作,但不影響不大。
封裝的部分邏輯:
比如大陸的登錄組件叫做 mainlandLogin, 港臺的登錄組件叫 htLogin,再寫一個 login組件將他們整合,通過環境變量進行區分引入不同的組件,使用component動態加載對應的登錄組件如下:
login.vue:
<component?:is="currentLogin"?@sure="sure"?cancel="cancel"></component>data:{return?{currentLogin:?process.env.VUE_APP_ENV?===?'ht'???'mainlandLogin'?:?'htLogin'}
},
components:?{mainlandLogin:?()?=>?import("./components/mainlandLogin.vue"),htLogin:?()?=>?import("./components/htLogin.vue"),
},
method:{sure(){this.$emit('sure')},cancel(){this.$emit('cancel')}
}注意: 引入組件的方式使用動態加載,打包時會將兩個組件打包成兩個單獨的chunk, 因為大陸版本與港臺版本只會用到一種登錄,另一個用不到的不需要引入
經過如上操作將登錄的組件封裝好以后使用起來就很簡單了
<login?@sure="sure"?cancel="cancel"></login>3. 解決價格不一致問題
與登錄一樣,根據環境變量區分即可,在原來大陸版本的商品JSON中加入一個字段即可如htPrice
const?commodityList?=?[{id:?1name:?"xxx",count:1,price:1,htPrice:?2}
]遍歷的時候還是根據process.env.VUE_APP_ENV === 'ht'進行顯示對應價格與單位
{{?isHt???`${commodity.htPrice}?NT$`?:?`${commodity.price}?¥`?}}data()?{return?{isHt:?process.env.VUE_APP_ENV?===?'ht'}
}4. 簡繁體轉換
解決了兩個項目合并成一個項目和登錄、價格、單位不一致的問題,最后只剩下簡體轉繁體,也是最難解決的一部分,經過了多次技術調研沒有找到合適的方案,最后只能自己寫一套。
1. 使用i18n, 維護兩套語言文件
優點: 國際化使用的最多的一個庫,不用改動代碼中的文字,使用變量替換,只需維護兩套語言文件,改動點集中在一個文件中
缺點: 使用變量進行替換一定程度上增加了代碼的復雜性,無法省去手動復制簡體去翻譯在額外寫入特定的語言文件這一過程,對于這個場景不是一個最好的方案
2. 采用:language-tw-loader
優點: ? 看似 可以自動化將簡體轉換成繁體,方便快捷
缺點: 在使用時發現一個致命的缺點, 無法準確替換,原因: 不同的詞組,同一個詞可能對應多個字形,如:聯系 -> 聯繫, 系鞋帶 -> 系鞋帶。
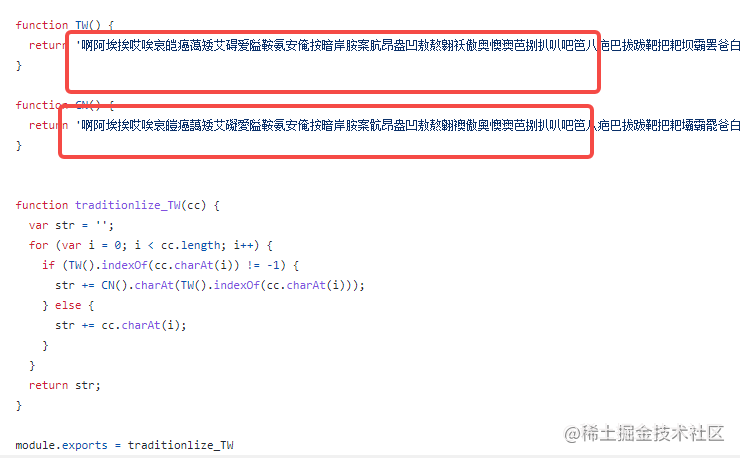
基本原理: 列舉常用的中文簡體與繁體,一一對應,逐一替換, 如下圖所示:
3. 采用 v-google-translate優點: 運行時采用谷歌翻譯,自動將網頁的簡體翻譯成繁體
缺點: 因為是運行時轉義,所以頁面始終會先展示簡體,過一段時間再顯示繁體
綜上所述: 現有的一些方案存在以下幾個問題
需要維護額外的語言文件,使用變量替換文字
編譯時轉換無法正確轉換,運行時轉換有延時
為了解決以上問題:
1. 無需寫多套語言文件,正常開發使用中文進行編寫即可
需要一個翻譯的API,且翻譯要準確,經測試簡繁體轉換谷歌翻譯是最準確的。
2. 在編譯時轉換
編寫打包工具的plugin,這里主要以webpack為打包工具,所以需要編寫一個webpack的plugin。
翻譯API
需要一個免費、準確、且不易掛的翻譯服務,但是谷歌翻譯API是需要付費的,有錢付費的很方便就能享受這個服務,但是為了一個簡體轉繁體產生額外的支出,不太現實。
開源項目中有很多的免費谷歌API, 但都是去嘗試模擬生成其加密token,進行請求,服務很容易掛掉,所以很多 直接變成了沒有。
但是!!!你要記得,谷歌翻譯是提供免費的網頁版的!
所以只需要打開一個瀏覽器,填入需要翻譯的文字,獲取翻譯后的文字即可,只不過需要程序自動幫我們打開一個瀏覽器,你沒想錯,已經有很成熟的方案puppeteer 就是干這件事情的。
所以最終采用: 基于puppeteer的訪問谷歌https://translate.google.cn 獲得翻譯結果,比其他方案都要穩定。
同時已有大佬寫了一個基于puppeteer的轉換服務 translateer,感興趣的可以看看其源碼,也不復雜。
但是注意,基于 translateer 啟動API服務, 存在幾個可以優化的點:
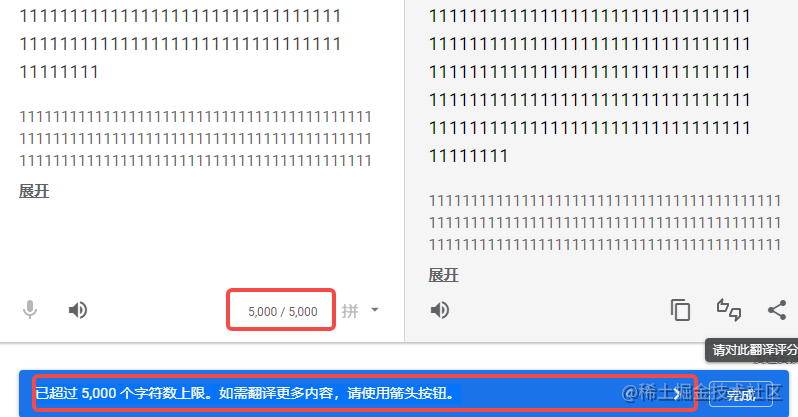
先看下為什么需要優化, 首先我們得要知道谷歌翻譯網頁端最大支持多少字符,測試得知如下最大支持一頁最大支持 5000字符,超過的部分可以翻頁。
 再以上左側輸入框內輸入源文本,該網頁會發送一個
再以上左側輸入框內輸入源文本,該網頁會發送一個post請求,一小會延遲右側出現翻譯后的內容,同時注意導航欄上的鏈接會變成如下形式:
https://translate.google.cn/?sl=zh-CN&tl=zh-TW&text=哈哈哈&op=translate上面幾個參數分別的含義
sl:?源語言;?tl:?目標語言;?text:?翻譯的文本;?op:?translate?(翻譯)如果直接使用以上鏈接進行請求,經過測試,將text值替換為'1'.repeat(16346), 16346 個字符時 (該數值不包括url上其它字符,算上其它字符,那么總的url長度是16411) ,谷歌接口會返回400錯誤。
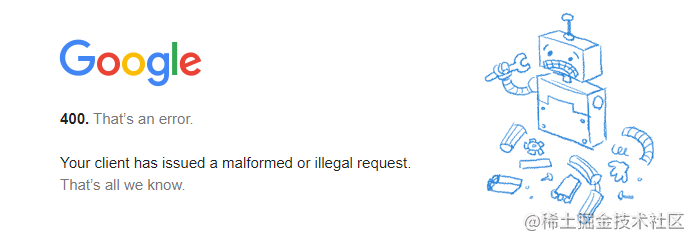
值得提的是: 看了很多的文章都說chrome的get請求最大字符長度限制是2048或8182,但是都不太準確,上述測試就可以證明,總長度少于16411 谷歌翻譯依舊可以正常訪問,超過以后還是由谷歌翻譯對應的后臺服務器拋出的400 錯誤。
參考了GET請求的長度限制, 以下幾點是可以知道的:
1、首先即使有長度限制,也是限制的是整個URI長度,而不僅僅是你的參數值數據長度。
2、HTTP協議從未規定GET/POST的請求長度限制是多少
3、所謂的請求長度限制是由瀏覽器和web服務器決定和設置的,瀏覽器和web服務器的設定均不一樣
所以瀏覽器到底限制的是多少字符呢,暫時還沒有找到正確答案,有知道的大佬可以幫忙解釋一下
測試所用的谷歌瀏覽器版本: 98.0.4758.102(正式版本)(64 位)
分析了以上基本的限制,接下來看看translateer 的實現:
translateer 服務啟動時創建一個 PagePool頁面池,開啟5個tab頁面并且都跳轉至https://translate.google.cn/, 以下為刪減后的部分代碼:
export?default?class?PagePool?{private?_pages:?Page[]?=?[];private?_pagesInUse:?Page[]?=?[];constructor(private?browser:?Browser,?private?pageCount:?number?=?5)?{pagePool?=?this;}public?async?init()?{this._pages?=?await?Promise.all([...Array(this.pageCount)].map(()?=>this.browser.newPage().then(async?(page)?=>?{await?page.goto("https://translate.google.cn/",?{waitUntil:?"networkidle2",});return?page;})));}
}然后使用fastify啟動一個Node服務器,對外提供一個get請求API。以下為刪減后的部分代碼:
fastify.get("/",async?(request,?reply)?=>?{const?{?text,?from?=?"auto",?to?=?"zh-CN",?lite?=?false?}?=?request.query;const?page?=?pagePool.getPage();await?page.evaluate(([from,?to,?text])?=>?{location.href?=?`?sl=${from}&tl=${to}&text=${encodeURIComponent(text)}`;},[from,?to,?text]);//?translating...await?page.waitForSelector(`span[lang=${to}]`);//?get?translated?textlet?result?=?await?page.evaluate((to)?=>(document.querySelectorAll(`span[lang=${to}]`)[0]?as?HTMLElement).innerText,to);
}傳入sl: 源語言; tl: 目標語言; text: 翻譯的文本 這幾個參數,location.href 跳轉至
?sl=${from}&tl=${to}&text=${encodeURIComponent(text)} 從而獲得右側輸入框的返回結果。
分析了其基本的實現原理,接下來分析其中存在的坑點。
location.href 是個get請求,經過上面的分析暫時不知道瀏覽器get請求的字符長度限制,但是已經知道谷歌后臺服務的對請求長度的限制為16411, 再粗略減去411個字符作為url的其他字符長度, 那么每次的翻譯文本最大支持長度就為16000個字符。
而如上代碼對text進行encodeURIComponent 編碼 (get請求默認也會對中文及其它特殊字符進行編碼)
需要注意的是中文一個字符編碼后為9個字符 聯 => %E8%81%94, 那么16000 / 9 約等于 1777個漢字
階段總結:
由于谷歌翻譯網頁版的一些限制,直接使用get請求,一次最大支持翻譯1777個漢字, 而在輸入框內模擬輸入漢字無字符長度限制,一頁最大支持5000 字符,超出的部分可進行翻頁。
需要達到的效果是一次翻譯最少要能翻譯5000個字符,盡量少請求次數,能減少翻譯的時間,進而加快插件編譯的速度,所以需要開始改進 translateer:
使用
fastify創建一個新的post請求API
export?const?post?=?((fastify,?opts,?done)?=>?{fastify.post('/',async?(request,?reply)?=>?{...more...});done();
});跳轉時只添加參數
sl源語言與tl目標語言不加text參數
await?page.evaluate(([from,?to])?=>?{location.href?=?`?sl=${from}&tl=${to}`;},[from,?to]);選中谷歌翻譯頁面左側的文本輸入框,并將
需要翻譯的文本賦值給輸入框,并且需要使用page.type鍵入一個空字符,觸發一次文本框的input事件,網頁才會執行翻譯。
await?page.waitForSelector(`span[lang=${from}]?textarea`);const?fromEle?=?await?page.$(`span[lang=${from}]?textarea`);await?page.evaluate((el,?text)?=>?{el.value=?text},fromEle,?text)//?模擬一次輸入觸發input事件,使得谷歌翻譯可以翻譯await?page.type(`span[lang=${from}]?textarea`,?'?');//?translating...await?page.waitForSelector(`span[lang=${to}]`);//?get?translated?textconst?result?=?await?page.evaluate((to)?=>(document.querySelectorAll(`span[lang=${to}]`)[0]?as?HTMLElement).innerText,to);這里有個坑點,就是 page.type 是模擬用戶輸入所以他會一個字一個字的輸入,一開始的時候我使用它去給文本輸入框賦值,文本過長時,輸入的時間巨長,當時不知道怎么處理,為此我還專門提了個issue, 被指導后才改寫成現在的寫法: ?issues
總結:
前面提到,超過5000字符可以進行翻頁,這里沒有進行翻譯處理,目前限制就每次請求翻譯5000個字符已經夠用,超過5000再請求一次翻譯接口 (后續可處理一下翻頁,不管多長的字符都一次翻譯完畢, 不過還需要進一步對比兩者的所用時間長短)
最后以上修改過的代碼github地址: Translateer
translate-language-webpack-plugin
解決了翻譯API的問題,剩下的事情就只剩將代碼中的中文簡體轉換成繁體了,由于打包工具使用的webpack, 所以編寫webpack plugin 進行讀取中文并替換, 同時需要支持webpack5.0與webpack4.0版本,以下以5.0版本為例:
首先理一下該插件的思路
編寫webpack插件
讀取代碼中所有的中文
請求翻譯API, 獲得翻譯后的結果
將翻譯后的結果寫入至代碼中
額外的功能:將每次讀取的源文本與目標文本輸出至日志中, 特別是在翻譯返回的文本長度與源文本長度不一致時用于對照。
接下來一步步實現上述功能
1. 第一步需要編寫一個插件,怎么寫?這是個問題
4.0版本 和 5.0版本 的鉤子是不一樣的,而且很多,這里不會介紹webpack plugin中每個鉤子的含義,不是兩句話能說的清楚的, 網上有很多介紹的如揭秘webpack插件工作流程和原理,要想快速的寫一個插件,那么最快的方式就是參考現有的成熟的插件,我在編寫的時候就是直接參照的html-webpack-plugin, 4.0版本與5.0版本都是參照其對應版本寫的。
tips: ?看開源項目的源碼的意義就在于此,可以學到很多的成熟的解決方案,可以稍微少踩一點坑, 所以最基本也需要學會如何找入口文件,如何調試代碼。
部分代碼如下,參考如下注釋:
const?{?sources,?Compilation?}?=?require('webpack');
//?日志輸出文件
const?TRANSFROMSOURCETARGET?=?'transform-source-target.txt';
//?谷歌翻譯一次最大支持字符
const?googleMaxCharLimit?=?5000;
//?插件名稱
const?pluginName?=?'TransformLanguageWebpackPlugin';class?TransformLanguageWebpackPlugin?{constructor(options?=?{})?{//?默認的一些參數const?defaultOptions?=?{?translateApiUrl:?'',?from:?'zh-CN',?to:?'zh-TW',?separator:?'-',?regex:?/[\u4e00-\u9fa5]/g,?outputTxt:?false,?limit:?googleMaxCharLimit,};//?translateApiUrl?翻譯API必須傳if?(!options.translateApiUrl)throw?new?ReferenceError('The?translateApiUrl?parameter?is?required');//?將傳入的參數與默認參數合并this.options?=?{?...defaultOptions,?...options?};}//?添加apply方法,供webpack調用apply(compiler)?{const?{separator,?translateApiUrl,?from,?to,?regex,?outputTxt,?limit}?=?this.options;//?監聽compiler?的thisCompilation?鉤子compiler.hooks.thisCompilation.tap(pluginName,?(compilation)?=>?{//?監聽compilation?的processAssets?鉤子compilation.hooks.processAssets.tapAsync({name:?pluginName,// stage 代表資源處理的階段, PROCESS_ASSETS_STAGE_ANALYSE:analyze the existing assets.stage:?Compilation.PROCESS_ASSETS_STAGE_ANALYSE,},//?assets?代表所有chunk文件`路徑及內容async?(assets,?callback)?=>?{// TODO:在此處填充要實現的功能})})}
}以上為該插件的基本結構, webpack5.0中processAssets鉤子用于處理文件,我們主要看一下 Compilation.PROCESS_ASSETS_STAGE_ANALYSE階段assets 中有什么. 以提供的github倉庫中提供的例子為例
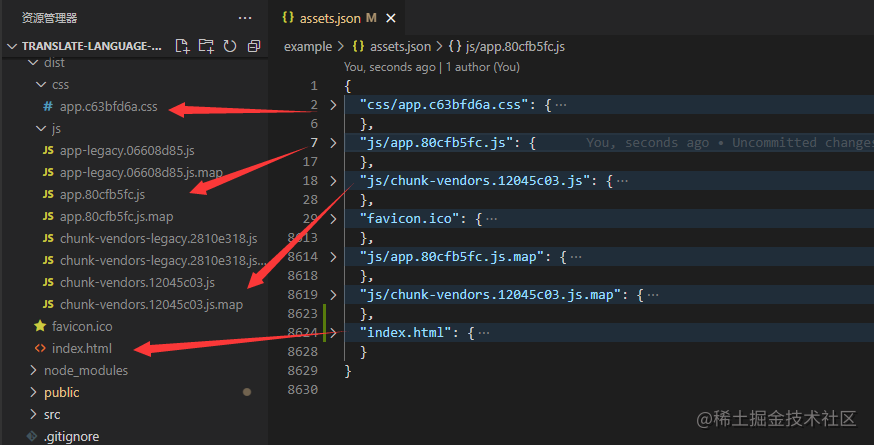 可以看到
可以看到assets就是最終會輸出的文件,根據需要做的事選擇不同的stage, 這里選擇PROCESS_ASSETS_STAGE_ANALYSE的原因是,需要處理index.htm中的中文,所以需要選擇一個非常靠后的鉤子,其他鉤子參考 (相關文檔)
2. 讀取代碼中所有的中文
首先需要寫一個函數,用于匹配相鄰的中文字符,如,源碼中含有<p>失聯</p><div>系鞋帶</div>, 返回:['失聯', '系鞋帶']。將返回的字符數組,以分隔符分隔,如['失聯', '系鞋帶'] => 失聯'-'系鞋帶' , 分隔的原因:如中文簡體 => 中文繁體(存在多形字):失聯系鞋帶 => 失聯繫鞋帶, 而正確的結果應該是 失聯系鞋帶, 失聯是一個詞組,系鞋帶是一個詞組,轉換后不會有變化的, 而聯系在一起的時候就會變成 聯繫
/***?@description?返回中文詞組數組, 如:?<p>你好</p><div>世界</div>, ?返回:?['你好', '世界']*?@param?{*}?content?打包后的bundle文件內容*?@returns*/
function?getLanguageList(content,?regex)?{let?index?=?0,termList?=?[],term?=?'',list;?//?遍歷獲取到的中文數組while?((list?=?regex.exec(content)))?{if?(list.index?!==?index?+?1?&&?term)?{termList.push(term);term?=?'';}term?+=?list[0];index?=?list.index;}if?(term?!==?'')?{termList.push(term);}return?termList;
}在以上代碼TODO: 的位置繼續編寫, 獲取所有chunk中的中文并保存至chunkAllList數組中
let?chunkAllList?=?[];
//?先將所有的chunk中的`指定字符詞組`存起來
for?(const?[pathname,?source]?of?Object.entries(assets))?{//?只讀取js與html文件中的中文,其他的文件不需要if?(!(pathname.endsWith('js')?||?pathname.endsWith('.html')))?{continue;}//?獲取當前chunk的源代碼字符串let?chunkSourceCode?=?source.source();//?獲取chunk中所有的中文。const?chunkSourceLanguageList?=?getLanguageList(chunkSourceCode,?regex);//?如果小于0,說明當前文件中沒有?`指定字符詞組`,不需要替換if?(chunkSourceLanguageList.length?<=?0)?continue;chunkAllList.push({//?原文本數組chunkSourceLanguageList,// separator為分割符默認為:?-chunkSourceLanguageStr:?chunkSourceLanguageList.join(separator),//?chunk原代碼chunkSourceCode,//?chunk的輸出路徑pathname,});
}3. 請求翻譯API, 獲得翻譯后的結果
因為有些chunk中中文是很少的, 比如一個chunk中只有2個字,另一個chunk中只有3個字,那么就沒必要請求兩次翻譯接口,為了減少請求次數,先將所有chunk中的中文合成一個字符串,并用_分隔開用于區分是屬于那個chunk中的內容。
const?chunkAllSourceLanguageStr?=?chunkAllList
.map((item)?=>?item.chunkSourceLanguageStr).join(`_`);合成一個字符串以后,還需要進行切割,因為一次最大支持翻譯5000個字符
//?合理的分割所有chunk中讀取的字符,供谷歌API翻譯,不能超過谷歌翻譯的限制
const?sourceList?=?this.getSourceList(chunkAllSourceLanguageStr,?limit);getSourceList(sourceStr,?limit)?{let?len?=?sourceStr.length;let?index?=?0;if?(limit)?{}const?chunkSplitLimitList?=?[];while?(len?>?0)?{let?end?=?index?+?limit;const?str?=?sourceStr.slice(index,?end);chunkSplitLimitList.push(str);index?=?end;len?=?len?-?limit;}return?chunkSplitLimitList;
}切割完成后,最后使用Promise.all去請求所有的接口,所有的翻譯成功才能算成功
//?翻譯
const?tempTargetList?=?await?Promise.all(sourceList.map(async?(text)?=>?{return?await?transform({translateApiUrl:?translateApiUrl,text:?text,from:?from,to:?to,});})
);4. 將翻譯后的結果寫入至代碼中
得到了所有chunk中的中文簡體翻譯后的繁體,最后遍歷chunk數組chunkAllList,將源代碼中的
for?(let?i?=?0;?i?<?chunkAllList.length;?i++)?{const?{chunkSourceLanguageStr,chunkSourceLanguageList,pathname,chunkSourceCode,}?=?chunkAllList[i];let?sourceCode?=?chunkSourceCode;//?將簡體轉換為繁體targetList[i].split(separator).forEach((phrase,?index)?=>?{sourceCode?=?sourceCode.replace(chunkSourceLanguageList[index],phrase);});//?if?(outputTxt)?{writeContent?+=?this.writeFormat(pathname,chunkSourceLanguageStr,targetList[i]);}compilation.updateAsset(pathname,?new?sources.RawSource(sourceCode));
}以上代碼為不完全代碼,完整代碼及插件使用方式請參考:translate-language-webpack-plugin
5. 輸出對照文本
如下:主要是輸出每個chunk中的中文用于對照,如果說頁面沒有其它動態的文字,且這些文字需要應用特殊的字體,也可以使用這些讀取出來的字打包一個字體文件,比一整個字體文件小很多很多。
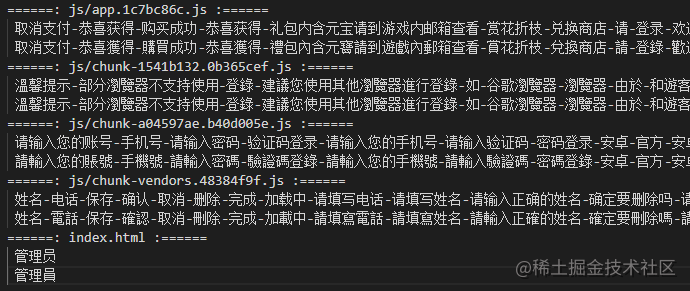
7總結
注意:會將頁面上包括js中的中文全部替換,但是接口返回的文字是無法轉換的,由后端返回對應繁體
至此一個完整的業務需求就已經優化的七七八八了,翻譯插件理論上支持任意語言互轉,但是由于翻譯的語義不同,往往翻譯出來的意思不是我們想要的,適用于簡體繁體互轉。

·················?若川簡介?·················
你好,我是若川,畢業于江西高校。現在是一名前端開發“工程師”。寫有《學習源碼整體架構系列》20余篇,在知乎、掘金收獲超百萬閱讀。
從2014年起,每年都會寫一篇年度總結,已經寫了7篇,點擊查看年度總結。
同時,最近組織了源碼共讀活動,幫助3000+前端人學會看源碼。公眾號愿景:幫助5年內前端人走向前列。

識別上方二維碼加我微信、拉你進源碼共讀群
今日話題
略。分享、收藏、點贊、在看我的文章就是對我最大的支持~


)


精)








高級職位)




