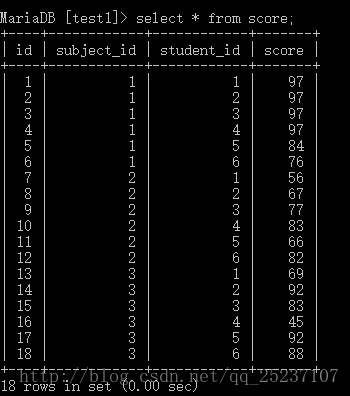
下列是各表的詳情,不想自己建表的同學可以直接copy code,數據隨意。
創建表成績詳情表:
CREATE TABLE score (
id int(10) NOT NULL AUTO_INCREMENT,
subject_id int(10) DEFAULT NULL,
student_id int(10) DEFAULT NULL,
score float DEFAULT NULL,
PRIMARY KEY (id)
) ENGINE=InnoDB AUTO_INCREMENT=19 DEFAULT CHARSET=utf8;
創建學生表:
CREATE TABLE student (
id int(10) NOT NULL AUTO_INCREMENT,
name varchar(10) DEFAULT NULL,
PRIMARY KEY (id)
) ENGINE=InnoDB AUTO_INCREMENT=7 DEFAULT CHARSET=utf8;

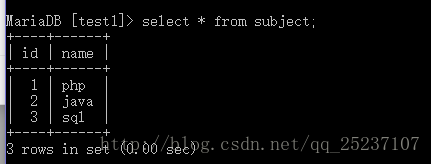
創建科目表:
CREATE TABLE subject (
id int(10) NOT NULL AUTO_INCREMENT,
name varchar(10) DEFAULT NULL,
PRIMARY KEY (id)
) ENGINE=InnoDB AUTO_INCREMENT=6 DEFAULT CHARSET=utf8;
查詢語句:
select a.id,a.subject_id,a.student_id,a.score from score as a left join score as b on a.subject_id=b.subject_id and a.score>=b.score
group by a.subject_id,a.student_id,a.score
having count(a.subject_id)>=4
order by a.subject_id,a.score desc;
分析:先將查詢語句分別拆開來一步一步分析
select a.id,a.subject_id,a.student_id,a.score,b.id,b.subject_id,b.student_id,b.score
from score as a left join score as b on a.subject_id=b.subject_id;
#這里把所有的列都列出來了便于對比
這里把表score的每一條同subject_id的數據都連接起來,形成笛卡爾積,如圖所示:共18*6=108條數據
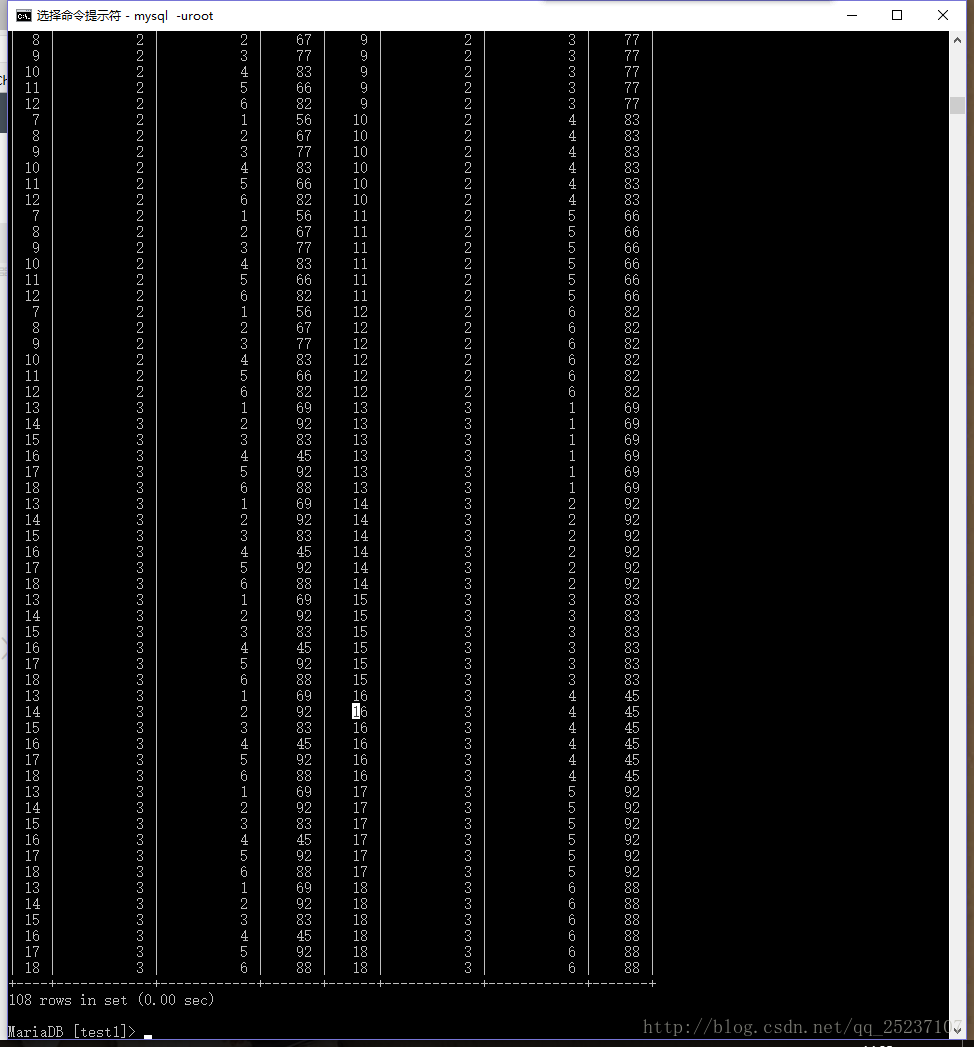
現在我們可以再進一步處理上面的數據了。這里我們再加上 a.score>=b.score 這個條件篩選再進行一次篩選。
select a.id,a.subject_id,a.student_id,a.score,b.id,b.subject_id,b.student_id,b.score
from score as a left join score as b on a.subject_id=b.subject_id and a.score>=b.score;
a.score>=b.score 這里是在同一門課程中,將每一個分數與其他分數(包括自己)進行一一對比,只留下大于自己,或者等于自己的分數。
如果選擇對比的行中的a.score是最高分,那么在后面利用group by a.subject_id,a.student_id,a.score分組的時候,此時計算得出的count(a.subject_id)就是最多的(count為總人數),因為其它的分數最多也只是和它一樣多,其它的都比它低;同理,如果a.score是最低分,那么count(a.subject_id)是最少的(count最少為1,只有它自己,其余分數都比它高;最多為總人數,這種情況是其它人的分數都和最低分一樣多...),其它的分數最差也和它一樣多,其它的都比它要高。例如:
100分是最高的,所以幾乎其他所有分數都符合100>=其他分數?這個條件,所以100分出現次數最多(count為總人數)
0分,是最低分,幾乎其他所有分數都不符合0>=其他分數這個條件,所以0分出現的次數應該是最少的(count最少為1;最多為總人數,此時其他的分數也都是最低分,即大家分數一樣低)
有同學可能會問為什么不用a.score > b.score來篩選。如果用a.score > b.score來進行篩選的話,如果數據中某個科目出現大量的并列第一名的話那么第一名就會被過濾掉,以至于得不到結果。如圖:

接下來就是分組:group by a.subject_id,a.student_id,a.score #按subject_id,student_id,score來進行分組
(這里使用group by a.subject_id,a.student_id,a.score和使用group by a.subject_id,a.student_id一樣的,因為兩表左連接之后,不可能出現相同的a.subject_id,a.student_id有多條不同的a.score的記錄;因為同一個同學a.student_id,同一個科目a.subject_id,只能有一個分數a.score,一個同學不可能一個科目有多個不同的分數);
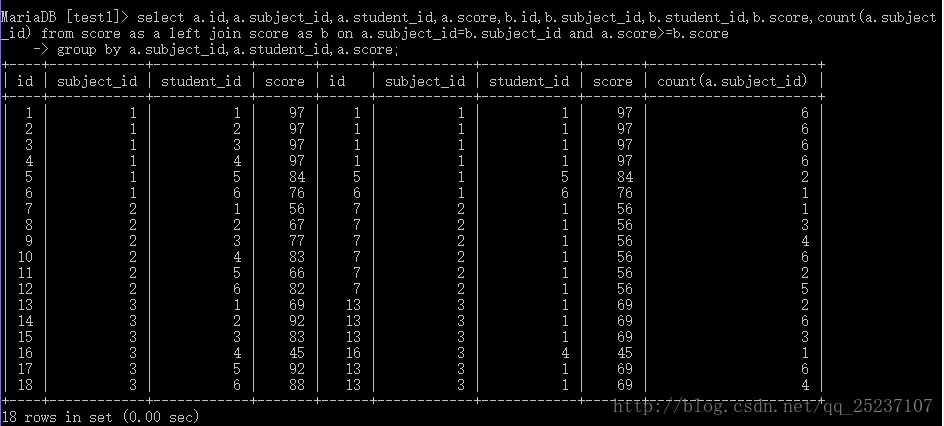
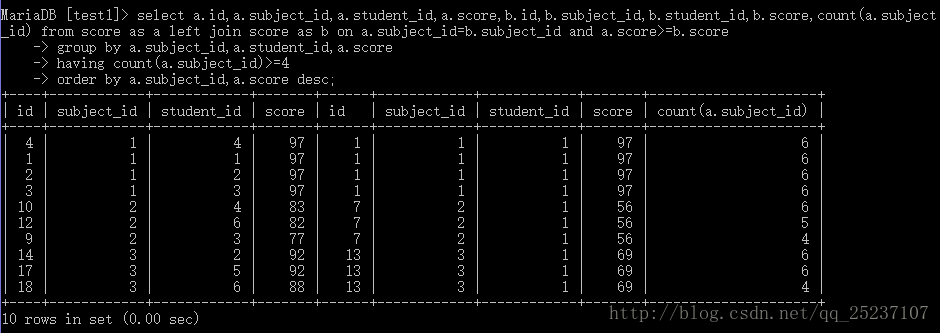
select a.id,a.subject_id,a.student_id,a.score,b.id,b.subject_id,b.student_id
b.score,count(a.subject_id) from score as a left join score as b
on a.subject_id=b.subject_id and a.score>=b.score?group by a.subject_id,a.student_id,a.score;
添加count(a.subject_id)來進行對比易于理解
分組后再進行條件查詢:having count(a.subject_id)>=4;
下面來討論下>=4是什么含義:正常來說,如果每門課程的各個同學的分數都不一樣,那么同一門課程中從最高分到最低分的count(a.subject_id)?分別為:6,5,4,3,2,1;取count>=4就是取6,5,4即取count最多的三個,所以取出的數據就是排名前三(count從高到低,取前三,那么就是前三甲的記錄):
接下來就是排序:order by a.subject_id,a.score desc。


)














)

