點擊上方關注,All in AI中國
上周,我看了一個關于“NLP的實踐特性工程”的演講。主要是關于LIME和SHAP在文本分類可解釋性方面是如何工作的。
我決定寫一篇關于它們的文章,因為它們很有趣、易于使用,而且視覺上很吸引人。
所有的機器學習模型都是在更高的維度上運行的,而不是在人腦可以直接看到的維度上運行的,這些機器學習模型都可以被稱為黑盒模型,它可以歸結為模型的可解釋性。特別是在NLP領域中,特征的維數往往很大,說明特征的重要性變得越來越復雜。
LIME & SHAP不僅幫助我們向最終用戶解釋NLP模型的工作原理,而且幫助我們自己解釋NLP模型是如何工作的。
利用 Stack Overflow 問題標簽分類數據集,我們將構建一個多類文本分類模型,然后分別應用LIME和SHAP對模型進行解釋。由于我們之前已經做過多次文本分類,所以我們將快速構建NLP模型,并著重于模型的可解釋性。
數據預處理、特征工程和邏輯回歸
import pandas as pdimport numpy as npimport sklearnimport sklearn.ensembleimport sklearn.metricsfrom sklearn.utils import shufflefrom __future__ import print_functionfrom io import StringIOimport refrom bs4 import BeautifulSoupfrom nltk.corpus import stopwordsfrom sklearn.model_selection import train_test_splitfrom sklearn.feature_extraction.text import CountVectorizerfrom sklearn.linear_model import LogisticRegressionfrom sklearn.metrics import accuracy_score, f1_score, precision_score, recall_scoreimport limefrom lime import lime_textfrom lime.lime_text import LimeTextExplainerfrom sklearn.pipeline import make_pipelinedf = pd.read_csv('stack-overflow-data.csv')df = df[pd.notnull(df['tags'])]df = df.sample(frac=0.5, random_state=99).reset_index(drop=True)df = shuffle(df, random_state=22)df = df.reset_index(drop=True)df['class_label'] = df['tags'].factorize()[0]class_label_df = df[['tags', 'class_label']].drop_duplicates().sort_values('class_label')label_to_id = dict(class_label_df.values)id_to_label = dict(class_label_df[['class_label', 'tags']].values)REPLACE_BY_SPACE_RE = re.compile('[/(){}[]|@,;]')BAD_SYMBOLS_RE = re.compile('[^0-9a-z #+_]')# STOPWORDS = set(stopwords.words('english'))def clean_text(text): """ text: a string return: modified initial string """text = BeautifulSoup(text, "lxml").text # HTML decoding. BeautifulSoup's text attribute will return a string stripped of any HTML tags and metadata. text = text.lower() # lowercase text text = REPLACE_BY_SPACE_RE.sub(' ', text) # replace REPLACE_BY_SPACE_RE symbols by space in text. substitute the matched string in REPLACE_BY_SPACE_RE with space. text = BAD_SYMBOLS_RE.sub('', text) # remove symbols which are in BAD_SYMBOLS_RE from text. substitute the matched string in BAD_SYMBOLS_RE with nothing. # text = ' '.join(word for word in text.split() if word not in STOPWORDS) # remove stopwors from text return textdf['post'] = df['post'].apply(clean_text)list_corpus = df["post"].tolist()list_labels = df["class_label"].tolist()X_train, X_test, y_train, y_test = train_test_split(list_corpus, list_labels, test_size=0.2, random_state=40)vectorizer = CountVectorizer(analyzer='word',token_pattern=r'w{1,}', ngram_range=(1, 3), stop_words = 'english', binary=True)train_vectors = vectorizer.fit_transform(X_train)test_vectors = vectorizer.transform(X_test)logreg = LogisticRegression(n_jobs=1, C=1e5)logreg.fit(train_vectors, y_train)pred = logreg.predict(test_vectors)accuracy = accuracy_score(y_test, pred)precision = precision_score(y_test, pred, average='weighted')recall = recall_score(y_test, pred, average='weighted')f1 = f1_score(y_test, pred, average='weighted')print("accuracy = %.3f, precision = %.3f, recall = %.3f, f1 = %.3f" % (accuracy, precision, recall, f1))
我們現在目標并不是產生最好的結果。我想盡快進入LIME & SHAP,這就是接下來發生的事情。
用LIME解釋文本預測
從現在開始,這是有趣的部分。下面的代碼片段主要是從LIME教程中借來的。
c = make_pipeline(vectorizer, logreg)class_names=list(df.tags.unique())explainer = LimeTextExplainer(class_names=class_names)idx = 1877exp = explainer.explain_instance(X_test[idx], c.predict_proba, num_features=6, labels=[4, 8])print('Document id: %d' % idx)print('Predicted class =', class_names[logreg.predict(test_vectors[idx]).reshape(1,-1)[0,0]])print('True class: %s' % class_names[y_test[idx]])
我們在測試集中隨機選擇一個文檔,它恰好是一個標記為sql的文檔,我們的模型也預測它是sql。使用這個文檔,我們為標簽4 (sql)和標簽8 (python)生成解釋。
print ('Explanation for class %s' % class_names[4])print (''.join(map(str, exp.as_list(label=4))))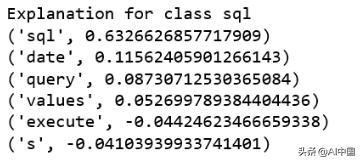
print ('Explanation for class %s' % class_names[8])print (''.join(map(str, exp.as_list(label=8))))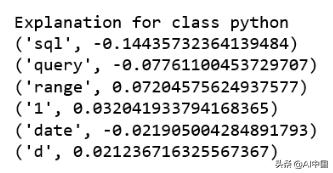
很明顯,這個文檔對標簽sql有最高的解釋。我們還注意到正負號與特定的標簽有關,例如單詞"sql"對類sql是正的,而對類python是負的,反之亦然。
我們要為這個文檔生成2類標簽頂部。
exp = explainer.explain_instance(X_test[idx], c.predict_proba, num_features=6, top_labels=2)print(exp.available_labels())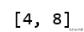
它給出了sql和python。
exp.show_in_notebook(text=False)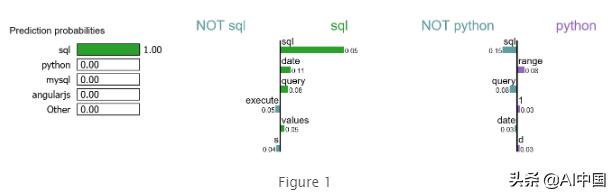
讓我來解釋一下這種可視化:
1. 對于本文檔,詞 "sql"對于類sql具有最高的正分數。
2. 我們的模型預測該文檔應該標記為sql,其概率為100%。
3. 如果我們從文檔中刪除word"sql",我們期望模型預測label sql的概率為100% - 65% = 35%。
4. 另一方面,單詞"sql"對于類python是負面的,我們的模型已經了解到單詞"range"對于類python有一個小的正面得分。
我們可能想放大并研究類sql的解釋,以及文檔本身。
exp.show_in_notebook(text=y_test[idx], labels=(4,))
使用SHAP解釋文本預測
以下過程是從本教程中學到的。「鏈接」
from sklearn.preprocessing import MultiLabelBinarizerimport tensorflow as tffrom tensorflow.keras.preprocessing import textimport keras.backend.tensorflow_backend as KK.set_sessionimport shaptags_split = [tags.split(',') for tags in df['tags'].values]tag_encoder = MultiLabelBinarizer()tags_encoded = tag_encoder.fit_transform(tags_split)num_tags = len(tags_encoded[0])train_size = int(len(df) * .8)y_train = tags_encoded[: train_size]y_test = tags_encoded[train_size:]class TextPreprocessor(object): def __init__(self, vocab_size): self._vocab_size = vocab_size self._tokenizer = None def create_tokenizer(self, text_list): tokenizer = text.Tokenizer(num_words = self._vocab_size) tokenizer.fit_on_texts(text_list) self._tokenizer = tokenizer def transform_text(self, text_list): text_matrix = self._tokenizer.texts_to_matrix(text_list) return text_matrixVOCAB_SIZE = 500train_post = df['post'].values[: train_size]test_post = df['post'].values[train_size: ]processor = TextPreprocessor(VOCAB_SIZE)processor.create_tokenizer(train_post)X_train = processor.transform_text(train_post)X_test = processor.transform_text(test_post)def create_model(vocab_size, num_tags): model = tf.keras.models.Sequential() model.add(tf.keras.layers.Dense(50, input_shape = (VOCAB_SIZE,), activation='relu')) model.add(tf.keras.layers.Dense(25, activation='relu'))model.add(tf.keras.layers.Dense(num_tags, activation='sigmoid')) model.compile(loss = 'binary_crossentropy', optimizer='adam', metrics = ['accuracy']) return model model = create_model(VOCAB_SIZE, num_tags)model.fit(X_train, y_train, epochs = 2, batch_size=128, validation_split=0.1) print('Eval loss/accuracy:{}'.format(model.evaluate(X_test, y_test, batch_size = 128)))- 模型訓練完成后,我們使用前200個訓練文檔作為背景數據集進行集成,并創建一個SHAP explainer對象。
- 我們在測試集的子集上獲得各個預測的屬性值。
- 將索引轉換為單詞。
- 使用SHAP的summary_plot方法來顯示影響模型預測的主要特性。
attrib_data = X_train[:200]explainer = shap.DeepExplainer(model, attrib_data)num_explanations = 20shap_vals = explainer.shap_values(X_test[:num_explanations])words = processor._tokenizer.word_indexword_lookup = list()for i in words.keys(): word_lookup.append(i)word_lookup = [''] + word_lookupshap.summary_plot(shap_vals, feature_names=word_lookup, class_names=tag_encoder.classes_)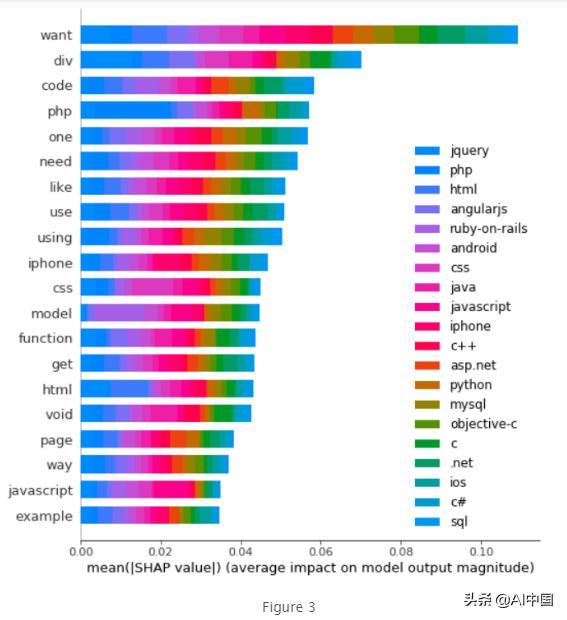
- 單詞"want"是我們模型使用的最大信號詞,對類jquery預測貢獻最大。
- 單詞"php"是我們模型使用的第四大信號詞,當然對PHP類貢獻最大。
- 另一方面,單詞"php"可能對另一個類有負面信號,因為它不太可能在python文檔中看到單詞"php"。
關于LIME & SHAP的機器學習可解釋性,還有很多需要學習的地方。我只介紹了一小部分NLP。其余的可以在Github上找到。NLP-with-Python/LIME_SHAP_StackOverflow.ipynb at master · susanli2016/NLP-with-Python · GitHub

)

管理...)
之timer的使用,鍵盤,鼠標的監聽)
)



)









