一、HBase簡介
1、Apache HBase?是Hadoop數據庫,是一個分布式,可擴展的大數據存儲。
2、當您需要對大數據進行隨機,實時讀/寫訪問時,請使用Apache HBase?。 該項目的目標是托管非常大的表( 數十億的行*百萬的列 ) 在商品硬件集群上。 Apache HBase是一個開源的,分布式的,版本化的非關系數據庫
3、利用Hadoop HDS 作為其文件存儲系統,利用Hadoop MapReduce來處理HBASE中的海量數據,利用ZOOKEEPER作為其分布式協同服務
4、主要用來存儲非結構化和半結構化的松散數據
二、HBASE數據模型
1、Rowkey
rowkey類似于關系型數據庫的主鍵,是一行記錄的唯一標識。
rowkey是按照字典序自動排序的
rowkey只能存儲64K的字節數據
2、Column Family列族 (CF)
HBase表中的每個列都歸屬于某個列族,列族必須作為表模式(schema)定義的一部分預先給出。如 create ‘test’, ‘course’;
列名以列族作為前綴,每個“列族”都可以有多個列成員(column);如course:math, course:english, 新的列族成員(列)可以隨后按需、動態加入;
權限控制、存儲以及調優都是在列族層面進行的;
HBase把同一列族里面的數據存儲在同一目錄下,由幾個文件保存。
3、Timestamp時間戳
在HBase一份數據有多個版本,根據唯一的時間戳來區分每個版本之間的差異,不同版本的數據按照時間倒序排序,最新的數據版本排在最前面。
時間戳的類型是64位整形
時間戳可以在數據寫入時由HBase自動賦值也可以人員手動指定
4、cell單元格
cell單元格是由行和列的交叉坐標決定的
cell單元格是由版本的
cell單元格中的內容: 由{row key, column( =<family> +<qualifier>), version} 唯一確定的單元
cell中存儲的數據是沒有類型的,全部由字節數組組成,也就是說HBASE中的數據是沒有類型的,全都是字節數組
三、HBase的預寫日志(WAL)
因為HBase是實時讀寫的數據庫,所以我們在操作數據的時候,會把數據先放在內存中,當內存中的數據達到一定量的時候才會落盤。但數據放在內存中是有一定的風險的,比如掉電之后,內存中的數據就會丟失。為了防止這種情況,HBase中加入了WAL(write ahead log)預寫日志機制,每個數據的寫入操作(PUT/DELETE)執行前,必須先通過WAL記賬。先將數據寫入Hlog文件,如果寫入失敗,則寫入操作失敗。Hlog位于RegionServer中,每個RegionServer維護一個Hlog。
WAL的作用是災難恢復,一旦服務器崩潰,或者數據被誤刪,則通過log日志重放,可以恢復事故數據。
WAL如此重要,所以默認是開啟的
四。HBase架構
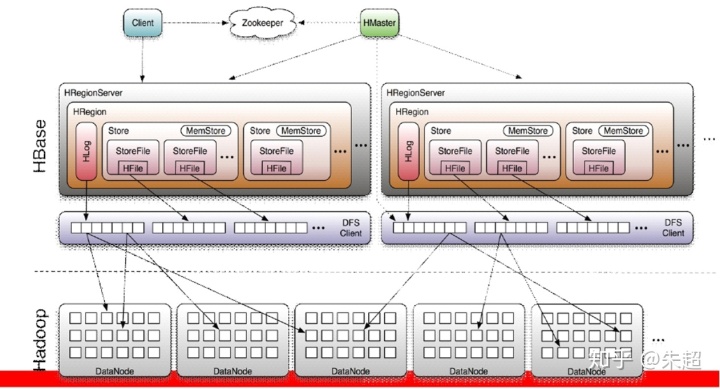
HBase架構的角色:
1、client
包含HBase的接口并維護cache來加快對hbase的訪問
2、zookeeper
保證任何時候,集群中只有一個活躍的HMaster
存儲所有的Region的尋址入口
實時監控所有HRegionServer的上下線消息,并通知HMaster
3、HMaster
HMaster是沒有單點故障的,因為集群中可以有多個HMaster,但是通過zookeeper的分布式協同服務保障有且只有一個活躍的HMaster對外提供服務。
HMaster負責為RegionServer分配region。
負責RegionServer的負載均衡。
發現失效的RegionServer并重新分配其上的region。
管理用戶對table的增刪改操作。
4、HRegionServer
RegionServer維護Region,處理對這些Region的I/O請求。
RegionServer負責切分在運行過程中逐漸變得過大的region。
HRegionServer中的組件
1、region
HBase自動把表水平劃分成多個區域(region),每個region會保存一個表里面某段連續的數據。也就是說一個大表被切成很多小份,每個小份是一個region。
每個表一開始只有一個region,隨著數據的不斷插入,region不斷增大。當region增大到某個閾值的時候,region就會等分為兩個新的region(裂變)。
當table中的行不斷增多,就會有越來越多的region。這樣,一張完整的表就被 保存在多個RegionServer上。
region是HBase中分布式存儲和負載均衡的最小單元。最小單元就表示不同的region可以分布在不同的HRegionServer上。
2、store
一個region有多個store組成,每個store對應一個CF(列族)。
store中包含位于內存中的memstore和位于磁盤的storefile。
3、memstore與storefile
每當進行寫操作時,寫操作會先進入memstore,當memstore中的數據到達某個閾值,HRegionServer會啟動flashcache進程將數據寫到storefile,每次寫入形成一個單獨的storefile。
當storefile文件數量達到一定閾值后,系統會進行合并,在合并過程中會進行版本合并和刪除工作,形成各大的storefile。
當一個region所有的storefile的大小和數量達到一定的閾值后,會把當前的region分割為兩個,并有HMaster分配到不同的RegionServer服務器,實現負載均衡。
storefile以Hfile的格式存儲在HDFS上。
客戶端檢索數據,先到memstore中找,找不到再到blockcache,再找不到去storefile
五、HBase的讀寫流程(0.98以后版本)
寫請求
客戶端在進行寫請求的時候。首先會訪問zookeeper,因為zookeeper中存儲著HBase元數據(meta)所在節點的信息(HBase的元數據在某個RegionServer中存儲,但是存儲元數據的RegionServer的信息保存在zookeeper中)。客戶端拿到元數據所在節點后訪問相應節點的RegionServer拿到元數據。最后根據元數據找到要操作的region。但是,找到region后不是先往memstore中寫。而是要先寫入WAL(預寫日志)的hlog中(寫入hlog成功后,會有一個異步側線程sync(),這個線程會實時檢測hlog中有沒有數據,如果有,直接落盤),只有往hlog中寫入成功了,才能接著往memstore中寫。
當memstore中的數據到達某個閾值,HRegionServer會啟動flashcache進程將數據寫到storefile,每次寫入形成一個單獨的storefile。
當storefile文件數量達到一定閾值后,系統會進行合并,在合并的時候會對數據排序,同時在合并過程中會進行版本合并和刪除工作,形成各大的storefile。
合并的方式有兩種,分別是minor和major。minor默認是3~10個storefile進行合并。major則是將當前目錄下的所有的storefile合并。注意:在文件合并的時候是不提供服務的。
因為minor是3~10個文件進行合并,所以占用資源少,速度快。所以我們一般使用minor。而major因為熟讀慢,所以我們一般不用,用也是手動進行。
當一個region所有的storefile的大小和數量達到一定的閾值后,會把當前的region分割為兩個,并有HMaster分配到不同的RegionServer服務器,實現負載均衡。
讀請求
客戶端在進行讀請求的時候。尋找region的過程幾乎與寫請求相同。首先在zookeeper中找元數據在哪個RegionServer中存儲,然后找到RegionServer拿到元數據,然后根據元數據找相應的region。
在region中尋找數據的過程如下:首先,會在region的memstore中尋找,如果被查找的記錄是剛剛通過寫請求寫入的,還沒被寫入storefile,那么查找成功。如果沒有找到,則到blockcache(讀緩存)中找,找到返回。找不到會繼續深入到storefile中查找,注意:如果是在storefile中找到的,并不會立即返回,而是要先將數據寫入blockcache中(方便下次查找),寫入成功后返回數據。
但是,這樣存在一個問題,那就是隨著讀請求的增多,blockcache會不斷變大。為了防止這種情況,系統采用最近最少使用算法(LRU)來維護blockcache。
blockcache位于RegionServer中,一個RegionServer維護一個blockcache。
















 C#如何使用異步編程)

以及線性調頻信號的頻譜)
