一、WHAT'S PYTHON ?
1、python 簡介
Python(英語發音:/?pa?θ?n/), 是一種面向對象、解釋型計算機程序設計語言,由Guido van Rossum于1989年發明,第一個公開發行版發行于1991年。
Python是純粹的自由軟件, 源代碼和解釋器CPython遵循 GPL(GNU General Public License)協議 。
Python語法簡潔清晰,特色之一是強制用空白符(white space)作為語句縮進。
2、誰在用 python
Python可以應用于眾多領域,如:數據分析、組件集成、網絡服務、圖像處理、數值計算和科學計算等眾多領域。目前業內幾乎所有大中型互聯網企業都在使用Python,如:Youtube、Dropbox、BT、Quora(中國知乎)、豆瓣、知乎、Google、Yahoo!、Facebook、NASA、百度、騰訊、汽車之家、美團等。互聯網公司廣泛使用Python來做的事一般有:自動化運維、自動化測試、大數據分析、爬蟲、Web 等。
3、python 的種類
- Cpython
Python的官方版本,使用C語言實現,使用最為廣泛,CPython實現會將源文件(py文件)轉換成字節碼文件(pyc文件),然后運行在Python虛擬機上。
- Jyhton
Python的Java實現,Jython會將Python代碼動態編譯成Java字節碼,然后在JVM上運行。
- IronPython
Python的C#實現,IronPython將Python代碼編譯成C#字節碼,然后在CLR上運行。(與Jython類似)
- PyPy(特殊)
Python實現的Python,將Python的字節碼字節碼再編譯成機器碼。
- RubyPython、Brython ...
?4、python 優缺點
優點:
* Simple Elegant Clear (簡單、優雅、明確)
* 強大的第三方庫
* 易移植
* 面向對象
* 可擴展
缺點:
* 速度慢(相對環境)
* 代碼不能加密
二、PYTHON BASE
1、安裝 python 環境
For Linux:
如果是ubuntu14.04+的版本,那么默認的python就是2.7+啦
1 tom@python:~$ cat /etc/issue 2 Ubuntu 14.04.3 LTS \n \l 3 4 tom@python:~$ python -V 5 Python 2.7.6
? 如果是centos6系列,那么請升級你的默認python到2.7+
1 1、安裝gcc,用于編譯Python源碼 2 ????yum install gcc 3 2、下載源碼包,https://www.python.org/ftp/python/ 4 3、解壓并進入源碼文件 5 4、編譯安裝 6 ????./configure 7 ????make all 8 ????make install 9 5、查看版本 10 ????/usr/local/bin/python2.7 -V 11 6、修改默認Python版本 12 ????mv /usr/bin/python /usr/bin/python2.6 13 ????ln -s /usr/local/bin/python2.7 /usr/bin/python 14 7、防止yum執行異常,修改yum使用的Python版本 15 ????vi /usr/bin/yum 16 ????將頭部 #!/usr/bin/python 修改為 #!/usr/bin/python2.6
For Windows:
1 1、下載安裝包 2 ????https://www.python.org/downloads/ 3 2、安裝 4 ????默認安裝路徑:C:\python27 5 3、配置環境變量 6 ????【右鍵計算機】--》【屬性】--》【高級系統設置】--》【高級】--》【環境變量】--》【在第二個內容框中找到 變量名為Path 的一行,雙擊】 --> 【Python安裝目錄追加到變值值中,用 ; 分割】 7 ????如:原來的值;C:\python27,切記前面有分號
2、python 代碼的執行過程
? ?Call :滕蘭老師說要把第一次交給“hello world”
#!/usr/bin/env python # coding:utf-8print 'hi,yue bu ?'
?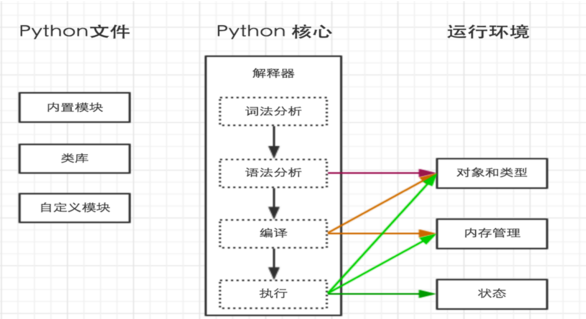
python 文件中的代碼會由解釋器進行語法/詞法的分析,沒有問題后進行編譯調入內存執行。
python在執行.py的文件時會生成一個同名.pyc的文件,這個文件是源文件編譯后的字節碼文件,源文件編譯成自解碼后再轉為機器可讀的二進制碼交給CPU處理。
3、什么是解釋器?
?解釋器(Interpreter),又譯為直譯器,能夠把高級編程語言轉譯運行。說白了就是一翻譯(也許是最近抗戰片看多了,總會聯想到穿著一半日本軍裝的漢奸翻譯* *)
4、內容編碼
python解釋器在讀取.py文件中的代碼時,會對內容進行編碼(默認是ASCII)
ASCII
ASCII(American Standard Code for Information Interchange,美國標準信息交換代碼)是基于拉丁字母的一套電腦編碼系統,主要用于顯示現代英語和其他西歐語言,其最多只能用 8 位來表示(一個字節),即:2**8 = 256,所以,ASCII碼最多只能表示 256 個符號。
1 >>> a = 'doudou' 2 >>> type(a) 3 <type 'str'>
UNICODE
Unicode(統一碼、萬國碼、單一碼)是一種在計算機上使用的字符編碼。Unicode 是為了解決傳統的字符編碼方案的局限而產生的,它為每種語言中的每個字符設定了統一并且唯一的二進制編碼,規定雖有的字符和符號最少由 16 位來表示(2個字節),即:2 **16 = 65536。Unicode的出現是因為ASCII的表示空間有限。
1 >>> name = u'小花' 2 >>> type(name) 3 <type 'unicode'> 4 >>> name 5 u'\u5c0f\u82b1' 6 >>> len(name) 7 2
UTF-8
UTF-8(8-bit Unicode Transformation Format)是一種針對Unicode的可變長度字符編碼,又稱萬國碼。針對unicode的可變長度的字符編碼,在內存中字符是Unicode進行處理的,硬盤存儲的時再轉為utf-8。
1 >>> name 2 u'\u5c0f\u82b1' 3 >>> name =name.encode('utf-8') # 使用encode將unicode轉為utf-8 4 >>> name 5 '\xe5\xb0\x8f\xe8\x8a\xb1' 6 >>> len(name) 7 6 8 >>> name = name.decode('utf-8') # 使用decode將utf-8轉為unicode9 >>> name 10 u'\u5c0f\u82b1' 11 >>> len(name) 12 2
?ps:在寫腳本的時候默認是ASCII的編碼方式,解釋器讀入內存的時候會轉換為Unicode進行處理,如果出現中文就會提示不能識別,所以我們在寫腳本的時候如果有中文,就要指定源文件以什么樣的編碼方式存儲。
1 #!/usr/bin/env python 2 # coding:utf-8 3 4 count = 0
5、編程風格
python 的代碼編寫會遵循Simple、Elegant、Clear的風格。
縮進統一
1 開頭行不能有空格 2 不同級別代碼縮進不同 3 同一級別代碼縮進必須相同 ?
6、注釋
對編寫的代碼文件要一定的注釋,保證簡單、易讀,方便他人方便自己。
單行注釋:# *****
1 # copy and rename
多行注釋/格式化輸出:’’’ ****** ‘’’?
1 ''' 2 copy 3 and 4 rename '''
?三、流程控制
?1、python模塊的調用與傳參的捕獲
Python有大量的模塊,從而使得開發Python程序非常簡潔。類庫有包括三中:
- Python內部提供的模塊
- 業內開源的模塊
- 程序員自己開發的模塊
Python內部提供一個 sys 的模塊,其中的 sys.argv 用來捕獲執行執行python腳本時傳入的參數
1 #!/usr/bin/env python 2 # coding:utf-8 3 4 import sys 5 print sys.argv
2、用戶交互(輸入內容)
raw_input、input
需求:要求用戶輸入用戶名密碼,正確后輸出歡迎信息。
1 #!/usr/bin/env python 2 # coding:utf-8 3 4 user_name = 'tom' 5 user_password = '123' 6 input_name = raw_input('User Name:') # raw_input() 默認把輸入的內容當作字符串來處理 7 input_password = input('Password:') # input() 會將輸入的內容保留原格式輸出 8 if input_name == user_name and input_password == user_password: 9 print "Welcome to Linux!" 10 else: 11 print "Login invalid"
getpass? 用戶輸入內容不可見
1 #!/usr/bin/env python 2 # coding:utf-8 3 4 import getpass # 調用getpass模塊 5 user_name = 'tom' 6 user_password = '123' 7 input_name = raw_input('User Name:') 8 input_password = getpass.getpass('Password:') # 引用功能,使用輸入內容不可見 9 if input_name == user_name and input_password == user_password: 10 print "Welcome to Linux!" 11 else: 12 print "Login invalid"
3、if ...elif ...break/continue...else、while
需求:要求用戶輸入用戶名密碼,正確后輸出歡迎信息,輸錯三次后退出。
1 #!/usr/bin/env python 2 # coding:utf-8 3 4 import getpass 5 count = 0 6 user_name = 'tom' 7 user_name1 = 'doudou' 8 user_password = '123' 9 while count < 3: # while 條件 10 input_name = raw_input('User Name:') 11 input_password = getpass.getpass('Password:') 12 if input_name == user_name1: 13 print "This user is not available." 14 continue # continue 中斷本次循環 15 elif input_name == user_name and input_password == user_password: 16 print "Welcome to Linux!" 17 break # break 退出循環 18 else: 19 print "Login invalid" 20 count += 1 # 一定要注意代碼塊的區分與縮進 條件+1
四、數據類型
1、數據類型分類
?? ???? >>>單值:
?? ??? ??? ??? ?數字:(digital)
?? ??? ??? ??? ??? ?整型:(integer)
?? ??? ??? ??? ??? ?長整型:(long)
?? ??? ??? ??? ??? ?符點型:(float)
?? ??? ??? ??? ??? ?復數:(complex)
?? ??? ??? ??? ??? ?字符串:(string)
?? ??? ??? ??? ?布爾值:(boolean)
?? ???? >>>集合:
?? ??? ??? ??? ?列表:(list)
?? ??? ??? ??? ?元組:(tuple)
?? ??? ??? ??? ?字典:(dict)
?? ??? ??? ??? ?哈希表:(hash)
2、變量:(variable)
變量,不只是一個可變化的量,它是一段內存空間的命名,指向內存地址的符號鏈接
1 變量標識符命名規范: 2 1、標識符的第一個字符必須是字母(大小寫字母)或”_”(下劃線) 3 2、標識符的其它部分可以由字母、”_”、數字(0-9)組成 4 3、標識符嚴格區分大小寫 5 4、以下關鍵字不能被定義為變量['and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'exec', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'not', 'or', 'pass', 'print', 'raise', 'return', 'try', 'while', 'with', 'yield']
定義變量與輸出變量:
1 >>> a = 'source' 2 >>> a 3 'source'
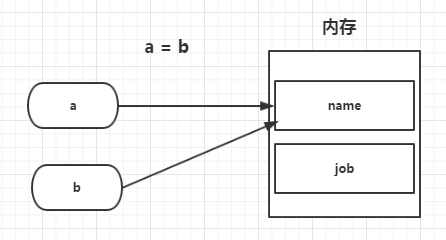
變量有意思的指向
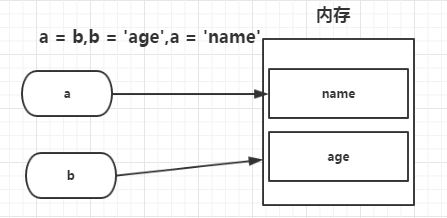
1 >>> a = 'job' 2 >>> b = 'name' 3 >>> a = b 4 >>> a 5 'name' 6 >>> b 7 'name' 8 >>> b = 'age' # 當變量b重新定義的時候,而a并沒有跟著b變化而變化,原因是:當a=b時,a的值是b所指向內存空間中的‘name’,所以當b重新定義新值的時候,a依然指向‘name’ 9 >>> a 10 'name' 11 >>> b 12 'age'
?
3、字符串(string)
占位符:
1 >>> name = 'how old are you %s' % '24' # %s (str) %d (digital) 2 >>> name 3 'how old are you 24' 4 >>> mame = 'i am %s ,%d years old.' % ('xiaohua',24) # 多個占位符,需要在后面按順序指定多個參數,只在內在中開辟一塊空間。 5 >>> name 6 'how old are you 24' 7 # 也可以這樣表示 8 >>> name = 'i am %s,%d years old.' 9 >>> name % ('xiaohua',24) 10 'i am xiaohua,24 years old.' 11 # 也可以這樣表示,三種方式執行過程一樣 12 >>> name = 'i am {0},age {1}' 13 >>> name.format('xiaohua',24) 14 'i am xiaohua,age 24'
索引/切片:
1 >>> name 2 'soure' 3 >>> name[0] 4 's' 5 >>> name[:0] 6 '' 7 >>> name[0:] 8 'soure' 9 >>> name[-1] 10 'e'
長度:len()
1 >>> len(name) 2 5 3 >>> print name[-1] 4 e 5 >>> print name[len(name)-1] # 最后一個值可以用len()做運算得到 6 e
去除空格:strip()
1 >>> name 2 ' home ' 3 >>> print name.strip() # strip() 去除字符串兩端的空格 4 home 5 >>> print name.lstrip() # lstrip() 去除字符串左端的空格 6 home 7 >>> print name.rstrip() # rstrip() 去除字符串右端的空格 8 home
分割:split()
1 >>> names = 'xiaohua,xiaoli' 2 >>> names 3 'xiaohua,xiaoli' 4 >>> names.split(',') 5 ['xiaohua', 'xiaoli'] # 字符串分割后得到一個列表 6 >>> names.split('h') 7 ['xiao', 'ua,xiaoli'
4、列表:(list)
列表是數據的集合,列表內的元素可以被查詢、修改
1 >>> b = ['job', 'salary', 'name',12,'shop','xyz','copy'] # 列表中的元素可以修改,支持增刪改查
# 或 b = (['job', 'salary', 'name',12,'shop','xyz','copy']) 列表的創建會調用([])來完成 2 >>> b 3 ['job', 'salary', 'name',12,'shop','xyz','copy']
長度: len() 可以查看列表中元素的個數
1 >>> len(b) 2 3
索引:NAME[N] 可以查看元素在列表中的位置
1 >>> b[0] 2 'job' 3 >>> b[1] 4 'salary' 5 >>> b[-1] # -1就是倒數嘍 6 'copy'
切片(slice) 切片指從列表中取出多個元素
1 >>> b[0:3] # 取從0到第3個元素,不包括第4個 2 ['job', 'salary', 'name'] 3 >>> b[:3] # 與上面一至 4 ['job', 'salary', 'name'] 5 >>> b[2:5] # 取從第3到第5個元素 6 ['name', 12, 'shop'] 7 >>> b[0:-3] # 取從第1至倒數第3個元素(之間) 8 ['job', 'salary', 'name', 12] 9 >>> b[-3:] # 取倒數第3個至最后一個元素 10 ['shop', 'xyz', 'copy'] 11 >>> b[1:8:2] # 取第1到最后,每隔一個取一個元素,最后:2是步長,以第隔幾個元素取一個 12 ['salary', 12, 'xyz'] 13 >>> b[::2] # 從頭到尾每隔一個取一個 14 ['job', 'name', 'shop', 'copy']
增加:NAME.append()??? 在列表后添加一個元素
1 ['job', 'salary', 'name', 12, 'shop', 'xyz', 'copy'] 2 >>> b.append('sese') 3 >>> b 4 ['job', 'salary', 'name', 12, 'shop', 'xyz', 'copy', 'sese']
刪除1:NAME.pop()?? ??? 刪除列表中最后一個元素
1 >>> b.pop() 2 'sese' 3 >>> b 4 ['job', 'salary', 'name', 12, 'shop', 'xyz', 'copy']
刪除2:NAME.remove()???? 刪除列表中一個元素,如果有相同元素,從左向右刪除
1 >>> b.remove('xyz') 2 >>> b 3 ['job', 'salary', 'name', 12, 'shop', 'copy']
刪除3:del NAME[索引]
1 >>> del b[3:7] # 刪除3到7的元素(不包括7) 2 >>> b 3 ['shop', 'salary', 'name', 'copy', 'NAME', 12]
修改:NAME.insert(索引,新值 )????? 修改目標位置的元素
1 >>> b 2 ['job', 'salary', 'name', 12, 'shop', 'copy'] 3 >>> b.insert(3,'NAME') 4 >>> b 5 ['job', 'salary', 'name', 'NAME', 12, 'shop', 'copy']
查詢:NAME.index()????? 查詢元素在列表中的索引位置
1 >>> b.index('shop') 2 5
聯結:‘’join
1 >>> name_list 2 ['xiaohua', 'xiaoming', 'old', 'yound', 'boy', 'doudou'] 3 >>> '_'.join(name_list) # join 用來指定列表內元素的聯結方式,只對字符串生效 4 'xiaohua_xiaoming_old_yound_boy_doudou'
包含:''in
1 >>> 'doudou' in name_list 2 True # in 返回一個bool值,多用來做判斷
統計:NAME.count()?? ??? ?統計元素在列表中的個數
1 >>> b.append('copy') 2 >>> b.count('copy') 3 2
合并:NAME.extend(NAME2)? 將列表2合并到列表1中
1 >>> b1 = ['haha','heihei'] 2 >>> b .extend(b1) 3 >>> b 4 ['job', 'salary', 'name', 'NAME', 12, 'shop', 'copy', 'copy', 'haha', 'heihei']
排序:NAME.sort()
1 >>> b 2 ['job', 'salary', 'name', 'NAME', 12, 'shop', 'copy', 'copy', 'haha', 'heihei'] 3 >>> b.sort() 4 >>> b 5 [12, 'NAME', 'copy', 'copy', 'haha', 'heihei', 'job', 'name', 'salary', 'shop'] ?
反轉:NAME.reverse()
1 >>> b 2 [12, 'NAME', 'copy', 'copy', 'haha', 'heihei', 'job', 'name', 'salary', 'shop'] 3 >>> b.reverse() 4 >>> b 5 ['shop', 'salary', 'name', 'job', 'heihei', 'haha', 'copy', 'copy', 'NAME', 12] ?
循環: for
1 #!/usr/bin/env python 2 # coding:utf-8 3 4 name_list = ['xiaohua','xiaoli','xiaoping'] 5 for item in name_list: 6 if item == 'xiaohua': 7 print 'yuanlaizoushiniya!' 8 continue # 當次循環不再繼續 9 elif item == 'xiaoli' 10 print 'shaobing' 11 break # 退出循環 12 else: 13 pass # 寫也可以,不寫也可以
5、元組(tuple)
1 >>> name_tuple = (12,14,15,16,18) # 元組里的元素一旦初始化后,但不能修改 2 >>> name_tuple 3 (12, 14, 15, 16, 18) 4 >>> name_tuple = tuple((12,14,15,16,18)) 5 >>> name_tuple 6 (12, 14, 15, 16, 18)
索引/切片
1 >>> name_tuple[0] 2 'xiaohua' 3 >>> name_tuple[0:] 4 ('xiaohua', ['old', 'age', 14])
長度: len()
1 >>> name_tuple = ('xiaohua',['old','age',14]) 2 >>> name_tuple 3 ('xiaohua', ['old', 'age', 14]) 4 >>> len(name_tuple)
包含:in
1 >>> 'age' in name_tuple 2 False
循環:for?????? 與列表中的循環一樣
6、字典(dict)
1 # 字典使用key/value的格式來存儲數據,每一個key/value是一個鍵值對,鍵值對是唯一的,字典支持增刪改查 2 >>> name_dict = {'name':'xiaoping','age':18,'job':'it'} 3 >>> name_dict 4 {'job': 'it', 'age': 18, 'name': 'xiaoping'}
items()/keys()/values()
1 #!/usr/bin/env python 2 # coding:utf-8 3 4 name_dict = {'name':'xiaoping','age':18,'job':'it'} 5 6 for k,v in name_dict.items(): # .items() 表示字典里所有的元素 7 print k,v 8 name_dict = {'name':'xiaoping','age':18,'job':'it'} 9 print name_dict.keys() # .keys() 表示字典里所有的key 10 name_dict = {'name':'xiaoping','age':18,'job':'it'} 11 print name_dict.values() # .values() 表示字典里所有的value
字典是無序輸出的
1 tom@python:/data/python/day1$ python dict.py 2 job it 3 age 18 4 name xiaoping ?
五、運算
?
六、文件的基本操作
過程:
找到文件--打開文件--文件操作(讀/寫)--關閉文件?? ??? ??? ?
使用方式:
1 open/file(PATH,MODE)? ????
模式:
1 r, 只讀,以只讀的方式打開文件,讀取內容。 2 w, 只寫,如果文件已經存在,會將文件覆蓋,如果不存在,將會創建新文件。 3 a, 追加,如果文件已經存在,內容會追加到末尾,如果不存在,將會創建新文件。 4 w+, 讀寫,如果文件已經存在,會將文件覆蓋,如果不存在,將會創建新文件。
讀取 ??
1 read() # 一次性全部讀入內存 2 readlines() # 逐行讀入內存 3 for line in FILE: # 每次循環,只讀一行
read() 全部讀入到內存
1 file_obj = file('/data/python/day1/tt.txt','read') 2 print file_obj.read() 3 file_obj.close() 4 # 輸出 5 tom@python:/data/python/day1$ python file.py 6 job,12,home 7 copy,sel,45
readlines()逐行讀取入到內存。
1 file_obj = file('/data/python/day1/tt.txt','read') 2 print file_obj.read() 3 file_obj.close() 4 #輸出后是一個列表,每個元素后面都帶一個換行符 5 tom@python:/data/python/day1$ python file.py 6 ['job,12,home\n', 'copy,sel,45\n']
?寫入
1 write_list.write() # 可以一次性寫入 2 write_list.writelines() # 也可以逐行寫入?
write()例子
1 write_obj = file('./name.txt','w') 2 write_obj.write(str_list) 3 write_obj.close()
?
?
計算器鏈接:http://www.cnblogs.com/wupeiqi/articles/4949995.html
?
?參考鏈接:http://www.cnblogs.com/wupeiqi/articles/4906230.html
?
的那些事)
















)

