C4.5是機器學習算法中的另一個分類決策樹算法,它是基于ID3算法進行改進后的一種重要算法,相比于ID3算法,改進有如下幾個要點:
- 用信息增益率來選擇屬性。ID3選擇屬性用的是子樹的信息增益,這里可以用很多方法來定義信息,ID3使用的是熵(entropy, 熵是一種不純度度量準則),也就是熵的變化值,而C4.5用的是信息增益率。
- 在決策樹構造過程中進行剪枝,因為某些具有很少元素的結點可能會使構造的決策樹過適應(Overfitting),如果不考慮這些結點可能會更好。
- 對非離散數據也能處理。
- 能夠對不完整數據進行處理。
首先,說明一下如何計算信息增益率。
熟悉了ID3算法后,已經知道如何計算信息增益,計算公式如下所示(來自Wikipedia):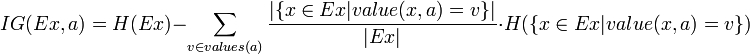
或者,用另一個更加直觀容易理解的公式計算:
- 按照類標簽對訓練數據集D的屬性集A進行劃分,得到信息熵:
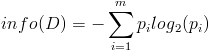
- 按照屬性集A中每個屬性進行劃分,得到一組信息熵:
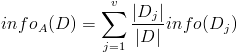
- 計算信息增益
然后計算信息增益,即前者對后者做差,得到屬性集合A一組信息增益:![]()
這樣,信息增益就計算出來了。
- 計算信息增益率
下面看,計算信息增益率的公式,如下所示(來自Wikipedia):![]()
其中,IG表示信息增益,按照前面我們描述的過程來計算。而IV是我們現在需要計算的,它是一個用來考慮分裂信息的度量,分裂信息用來衡量屬性分 裂數據的廣度和均勻程序,計算公式如下所示(來自Wikipedia):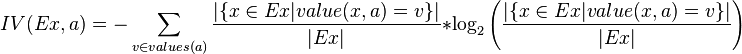
簡化一下,看下面這個公式更加直觀:![]()
其中,V表示屬性集合A中的一個屬性的全部取值。
我們以一個很典型被引用過多次的訓練數據集D為例,來說明C4.5算法如何計算信息增益并選擇決策結點。
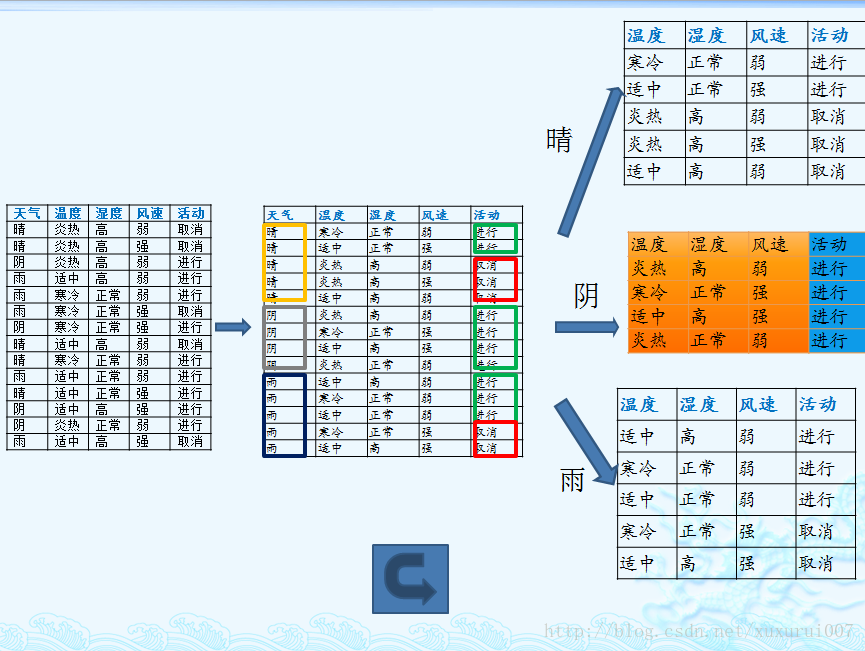
上面的訓練集有4個屬性,即屬性集合A={OUTLOOK, TEMPERATURE, HUMIDITY, WINDY};而類標簽有2個,即類標簽集合C={Yes, No},分別表示適合戶外運動和不適合戶外運動,其實是一個二分類問題。
我們已經計算過信息增益,這里直接列出來,如下所示:
數據集D包含14個訓練樣本,其中屬于類別“Yes”的有9個,屬于類別“No”的有5個,則計算其信息熵:
1 | Info(D) = -9/14 * log2(9/14) - 5/14 * log2(5/14) = 0.940 |
下面對屬性集中每個屬性分別計算信息熵,如下所示:
1 | Info(OUTLOOK) = 5/14 * [- 2/5 * log2(2/5) – 3/5 * log2(3/5)] + 4/14 * [ - 4/4 * log2(4/4) - 0/4 * log2(0/4)] + 5/14 * [ - 3/5 * log2(3/5) – 2/5 * log2(2/5)] = 0.694 |
2 Info(TEMPERATURE) = 4/14 * [- 2/4 * log2(2/4) – 2/4 * log2(2/4)] + 6/14 * [ - 4/6 * log2(4/6) - 2/6 * log2(2/6)] + 4/14 * [ - 3/4 * log2(3/4) – 1/4 * log2(1/4)] = 0.911 3 | Info(HUMIDITY) = 7/14 * [- 3/7 * log2(3/7) – 4/7 * log2(4/7)] + 7/14 * [ - 6/7 * log2(6/7) - 1/7 * log2(1/7)] = 0.789 |
4 Info(WINDY) = 6/14 * [- 3/6 * log2(3/6) – 3/6 * log2(3/6)] + 8/14 * [ - 6/8 * log2(6/8) - 2/8 * log2(2/8)] = 0.892 根據上面的數據,我們可以計算選擇第一個根結點所依賴的信息增益值,計算如下所示:
1 | Gain(OUTLOOK) = Info(D) - Info(OUTLOOK) = 0.940 - 0.694 = 0.246 |
2 Gain(TEMPERATURE) = Info(D) - Info(TEMPERATURE) = 0.940 - 0.911 = 0.029 3 | Gain(HUMIDITY) = Info(D) - Info(HUMIDITY) = 0.940 - 0.789 = 0.151 |
4 Gain(WINDY) = Info(D) - Info(WINDY) = 0.940 - 0.892 = 0.048 接下來,我們計算分裂信息度量H(V):
- OUTLOOK屬性
屬性OUTLOOK有3個取值,其中Sunny有5個樣本、Rainy有5個樣本、Overcast有4個樣本,則
1 | H(OUTLOOK) = - 5/14 * log2(5/14) - 5/14 * log2(5/14) - 4/14 * log2(4/14) = 1.577406282852345 |
- TEMPERATURE屬性
屬性TEMPERATURE有3個取值,其中Hot有4個樣本、Mild有6個樣本、Cool有4個樣本,則
1 | H(TEMPERATURE) = - 4/14 * log2(4/14) - 6/14 * log2(6/14) - 4/14 * log2(4/14) = 1.5566567074628228 |
- HUMIDITY屬性
屬性HUMIDITY有2個取值,其中Normal有7個樣本、High有7個樣本,則
1 | H(HUMIDITY) = - 7/14 * log2(7/14) - 7/14 * log2(7/14) = 1.0 |
- WINDY屬性
屬性WINDY有2個取值,其中True有6個樣本、False有8個樣本,則
1 | H(WINDY) = - 6/14 * log2(6/14) - 8/14 * log2(8/14) = 0.9852281360342516 |
根據上面計算結果,我們可以計算信息增益率,如下所示:
1 | IGR(OUTLOOK) = Info(OUTLOOK) / H(OUTLOOK) = 0.246/1.577406282852345 = 0.15595221261270145 |
2 IGR(TEMPERATURE) = Info(TEMPERATURE) / H(TEMPERATURE) = 0.029 / 1.5566567074628228 = 0.018629669509642094 3 | IGR(HUMIDITY) = Info(HUMIDITY) / H(HUMIDITY) = 0.151/1.0 = 0.151 |
4 IGR(WINDY) = Info(WINDY) / H(WINDY) = 0.048/0.9852281360342516 = 0.048719680492692784 根據計算得到的信息增益率進行選擇屬性集中的屬性作為決策樹結點,對該結點進行分裂。
C4.5算法的優點是:產生的分類規則易于理解,準確率較高。
C4.5算法的缺點是:在構造樹的過程中,需要對數據集進行多次的順序掃描和排序,因而導致算法的低效。
參考鏈接
- http://blog.sina.com.cn/s/blog_68ffc7a40100urn3.html
- http://en.wikipedia.org/wiki/Information_gain_ratio
- http://blog.sina.com.cn/s/blog_54c5622701016h4j.html
- http://en.wikipedia.org/wiki/Information_gain_ratio
- http://baike.baidu.com/view/8775136.htm
- http://www.cnblogs.com/zhangchaoyang/articles/2842490.html
- http://private.codecogs.com/latex/eqneditor.php
Sort the Array)
)


![談談分布式事務之三: System.Transactions事務詳解[下篇]](http://pic.xiahunao.cn/談談分布式事務之三: System.Transactions事務詳解[下篇])









...)


)
:菜鳥CEO的自我修養)
