2017-2018-1 20155229 《信息安全系統設計基礎》第十三周學習總結
對“第二章 信息的表示和處理”的深入學習
- 這周的任務是選一章認為最重要的進行學習,我選擇了第二章。當今的計算機存儲和處理信息基本上是由二進制(位)組成,二進制能夠很容易的被表示、存儲和傳輸。當把位組合在一起,再加上某種解釋,即給不同的可能位模式賦予含義,我們就能表示任何有限集合的元素。而正因為信息表示和處理是計算機最基礎的東西,我認為弄懂基礎是很有必要的。
第二章主要是研究計算機上如何表示數字和其他形式數據的基本屬性,以及計算機對這些數據執行操作的屬性,計算機系統規定了三種重要的編碼方式:無符號編碼、補碼編碼、浮點數編碼。
無符號編碼:基于傳統的二進制表示法,表示大于或等于0的數字。
補碼編碼:表述有符號整數的常見方式,正或負的數字。
浮點數編碼:表示實數的科學計數法的以二進制為技術的版本。
將本章分為三個模塊
一、信息存儲
二、整數表示及運算
三、浮點數
一、信息存儲
大端小端
大端模式,是指數據的低位保存在內存的高地址中,而數據的高位,保存在內存的低地址中;
小端模式,是指數據的低位保存在內存的低地址中,而數據的高位保存在內存的高地址中。
1.為什么會有大小端之分
在計算機系統中,是以字節為單位的,每個地址單元都對應著一個字節,一個字節為8bit。但是在C語言中除了8bit的char之外,還有16bit的short型,32bit的long型(要看具體的編譯器),另外,對于位數大于8位的處理器,例如16位或者32位的處理器,由于寄存器寬度大于一個字節,那么必然存在著一個如果將多個字節安排的問題。因此就導致了大端存儲模式和小端存儲模式.但是,大端小端沒有誰優誰劣,各自優勢便是對方劣勢
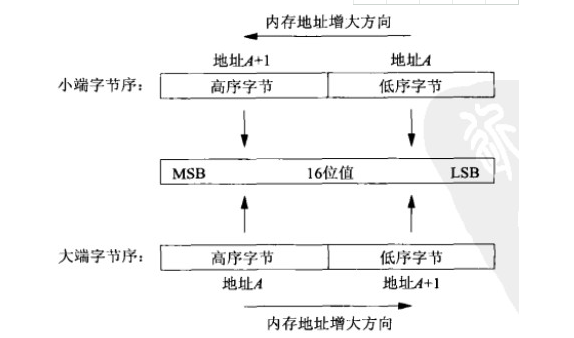
eg.一個16bit的short型x,在內存中的地址為0x0010,x的值為0x1122,那么0x11為高字節,0x22為低字節。對于大端模式,就將0x11放在低地址中,即0x0010中,0x22放在高地址中,即0x0011中。而對于小端模式,恰好相反
2.判斷機器的大小端
#include <stdio.h>
/*聯合*/
union node
{int num;char ch;
}
int main()
{union node p;//方法一p.num = 0x12345678;if (p.ch == 0x78){printf("Little endian\n");}else{printf("Big endian\n");}return 0;
}
- 所以Linux是小端的
3.如何進行轉換
對于字數據(16位)
#define BigtoLittle16(A) (( ((uint16)(A) & 0xff00) >> 8) | \ (( (uint16)(A) & 0x00ff) << 8)) 對于雙子數據(32位)
#define BigtoLittle32(A) ((( (uint32)(A) & 0xff000000) >> 24) | \ (( (uint32)(A) & 0x00ff0000) >> 8) | \ (( (uint32)(A) & 0x0000ff00) << 8) | \ (( (uint32)(A) & 0x000000ff) << 24)) 判斷CPU的大小端
int a = 1;
if ((char)a == 1) //取最低地址的一個字節cout << "小端序" << endl;
elsecout << "大端序" << endl;數據類型
- 數據類型在數據結構中的定義是一個值的集合以及定義在這個值集上的一組操作。
- 數據類型的出現是為了把數據分成所需內存大小不同的數據,編程的時候需要用大數據的時候才需要申請大內存,就可以充分利用內存。
- 數據類型的具體實現由計算機的體系結構決定。

typedef命名數據類型
- 用typedef可以聲明各種類型名,但不能用來定義變量,用typedef可以聲明數組類型、字符串類型、使用比較方便。
- typedef與#define有相似之處,但事實上二者是不同的,#define是在 預編譯 時處理,它只能做簡單的字符串替換,而typedef是在 編譯時 處理的。
- 用typedef只是對已經存在的類型增加一個類型名,而沒有創造新的類型。
位操作和邏輯運算
模數運算
- 模:是運算結果超出實際數據表示范圍的溢出量,它等于數的最大值加1.
計算機只能進行非負的模數加法。
eg.
50+80=(1)30。
因為字長限制,運算結果自動舍去溢出量,只保留小于模的部分,這種受模限制的運算叫模數運算。
c的位級運算
- | 就是OR(或),&就是AND(與),~就是NOT(取反),而^就是EXCLUSIVE-OR(異或)
- 可用于任何整型數據:unsigned,long long int ,long,int short ,char
c邏輯運算
- 邏輯運算符:&&、||、!
- 總是返回0或1,是整數的布爾運算,返回0表示“假”,返回1表示“真”。
1、邏輯短路與運算
#include <stdio.h>
int main()
{ int a=5,b=6,c=7,d=8,m=2,n=2; (m=a>b)&&(n=c>d); printf("%d\t%d",m,n); return 0;
}輸出的結果為0,2。因為a>b為0,m=0,整個“與”邏輯判斷就為“假”,所以后面的“c>d”就被短路掉了,所以n還是等于原先的2。
2.邏輯運算或運算
#include <stdio.h>
int main()
{ int a=5,b=6,c=7,d=8,m=2,n=2; (m=a<b)||(n=c>d); printf("%d\t%d",m,n); return 0;
}
輸出的結果為1,2。因為a<b,m=1,這個“或”邏輯就被“短路”掉了,后面的語句就沒被執行,所以n還是等于原先的2

c移位操作
左移:x<<y
- 向量x向左移y個位置,丟棄左邊額外的位,右邊用0填充
右移:x>>y
- 向量x向右移動y個位置,丟棄右邊額外的為,左邊用0填充(邏輯右移),復制最高位用于整數的補碼表示(算術右移)
c和java對右移的規定
c語標準并沒有明確定義應該使用哪種類型的右移。對于無符號數據,右移必須是邏輯的,對于有符號數據,算術的或者邏輯的右移都可以,實際上,幾乎所有的編譯器/機器組合都對有符號數據使用算術右移。
- Java有明確的右移定義。表達式x>>k會將x算術右移K個位置,而x>>>k會對x做邏輯右移。
當移動位數k大于等于字長w,實際上位移量就是通過計算k mod w 得到的。
返回分類
二、整數表示及運算
整數是現實世界中使用最多的數,在計算機系統中,為整數定義了很多數據類型。
無符號和補碼編碼
數字編碼
數字信息的編碼方式:將數字x經過某種數學變換之后得到的另一個數字x1作為其編碼,這個數字x1常常寫成位向量形式。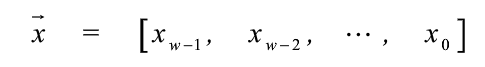
- 實際的應用常需要無符號數的編碼或有符號數的編碼,前者稱為無符號編碼,后者稱為二進制補碼編碼。
- 有符號編碼變換如下:
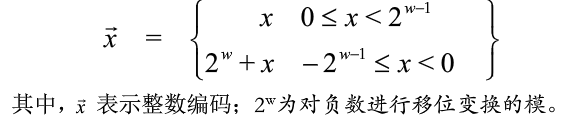
C庫
C庫中的頭文件
<limits.h>定義了一組宏,來限定編譯器運行的機器的不同整型和字符型的取值范圍。如它定義常量INT_MAX、INT_MIN和UINT_MAX來描述有符號和無符號整數的范圍。
<float.h>指定浮點型范圍和精度
<stdins.h>定義了一組形如intN_t和uintN_t的數據類型,其中N可為8、16、32、64.
eg.1
#include <stdio.h>
#include <limits.h>
int main(int argc,char* argv[]) {
printf("INT_MAX=%d\n",INT_MAX);
printf("INT_MIN=%d\n",INT_MIN);
printf("UINT_MAX=%u\n",UINT_MAX);
return 0;
}

eg.2
#include <stdio.h>
#include <limits.h>
#if INT_MAX>=3000000000
typedef int Quantity;
#else
typedef long long Quantity;
#endif
int main(int argc,char* argv[]) {
printf("int=%d\n",sizeof(int));
printf("long long=%d\n",sizeof(long long));
printf("quantity=%d\n",sizeof(Quantity));
return 0;
}
有符號數和無符號數之間的轉換
C允許無符號數和有符號數之間的轉換,原則是位表示保持不變。這些轉換可以是顯示的或隱式的。
eg
int tx,ty
unsigned ux,uy;
tx = (int)ux;
uy = (unsigned)ty;//顯示
tx = ux;
uy = ty;//隱式- 當用printf輸出一個整數時,按照整數的編碼根據不同的指示符分別輸出int類型(%d)、unsigned類型(%u)或十六進制格式(%x)
int x = -1;
unsigned u = 2147483648;
printf("x = %u = %d = %x\n",x,x,x);
printf("u = %u = %d = %x\n",u,u,u);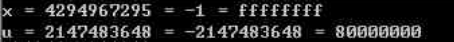
對于大多數C語言實現,處理同樣位長的有符號數(補碼)和無符號數間轉換規則是:位模式不變,改變解釋這些位的方式
數字的擴展和截斷
- 當對一個無符號數轉換為一個更大的數據類型,只需要簡單地在其位表示開頭的擴展字節添加0,稱為零擴展。
- 要將一個有符號數(補碼)轉換為一個更大的數據類型,需要在其位表示開頭的擴展字節添加最高有效位的值,稱為符號擴展。
什么時候使用無符號類型
- 盡量不要在代碼中使用無符號數類型,以免增加不必要的復雜性。
- 僅當需要對二進制位進行操作的時候,才使用無符號數。
- 在表示內存地址、實現模運算和多精度運算的數學包時,也可使用無符號數。
整數加法
無符號加法
①操作數:w bits → w+1 bits
②精確值:w+1 bits
③截斷值:w bits
運算法則:為了不丟失精度,x、y的編碼應零擴展為w+1位無符號數編碼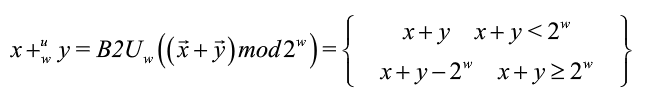
無符號減法
通過模數加法來實現
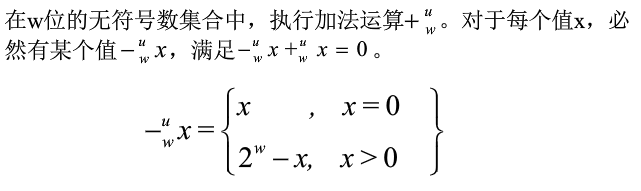
在無符號減法中,減去一個無符號數,相當于加上它的加法逆元。無符號數的加法逆元都為正數。
有符號數加法
①操作數:w bits → w+1 bits
②精確值:w+1 bits
③截斷值:w bits
運算法則:為了不丟失精度,x、y的編碼應符號擴展為w+1位二進制編碼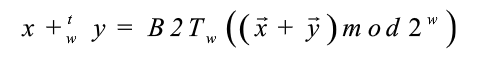
有符號減法
通常轉換為有符號加法來實現

在有符號減法中,減去一個有符號數,相當于加上它的加法逆元。有符號數的加法逆元是它的相反數。
整數乘法
- 計算w位數字x、y的實際乘積
返回分類
三、浮點數
浮點數是屬于有理數中某特定子集的數的數字表示,在計算機中用以近似表示任意某個實數。具體的說,這個實數由一個整數或定點數(即尾數)乘以某個基數(計算機中通常是2)的整數次冪得到,這種表示方法類似于基數為10的科學計數法。
IEEE浮點標準
浮點的引入
- 使用整數的編碼可以表示以0為中心的一定范圍內的正負整數,但缺陷為:
①無法表示那些絕對值“很大的”數值
②除了整數以外,在很多場合還需使用絕對值“極小的”小數,由于小數的某些特點,不能使用表示整數的方式去表示小數。
浮點數和IEEE754
科學記數法表示二進制數:
-1^s*2^E*Ms是符號位;2是基數,E是指數,
2^E構成一個冪,表示數量級范圍;M是有效數字部分(尾數),主要表示數值精度。M的位數越多,有效數字越多,數值精度越高。
IEEE754浮點標準
- IEEE754中,指定長度的浮點實數格式只有兩種:float(單精度浮點實數)和double(雙精度浮點實數),float的長度固定為4字節,double的長度固定為8字節。
V = -1^s*2^E*M = -1^s*2^(e-bias)*Ms=0或1,表示正或負值,用1bit編碼S
E=e-bias。
M=1+f或f,0≤f<1。M應取哪個值依賴于e是否等于0.
規格化值:當exp編碼不全為0,不全為1,可得到浮點數編碼的規格化值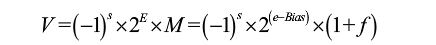
非規格化值:exp編碼全為0時,可得到浮點數編碼的非規格化值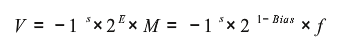
特殊值:exp編碼全為1,可得到浮點數編碼的特殊值
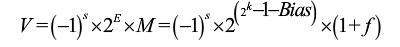
eg.
1.采用IEEE單精度格式,試求出32位浮點編碼0xAC710000的值。
解:1,01011000,11100010000000000000000
s=[1],為負數
exp=[01011000],E=88-127=-39
frac=[1110001]
M=1+(0.1110001)b=1+141/16+21/256=1+0.875+0.0078125=1.8828125
2.試寫出數0.8125的IEEE單精度浮點數編碼
解:
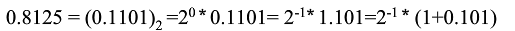
該數為正,s=0;E=-1=126-127,exp=126=[01111110]
尾數frac=[10100000000000000000000]
- 浮點編碼:[0 01111110 10100000000000000000000]=0x3F500000
舍入
- 由于浮點表示方法只是離散地表示了實數,所以相應的浮點運算只能是近似的實數運算。
- 對于值x,我們一般想有一種系統的方法,能夠找到“最接近的”,用x’的浮點形式來表示x,這就是舍入的任務。
浮點運算
C浮點類型
C提供了2種浮點類型:float和double。
int、float、double之間的強制類型轉換。
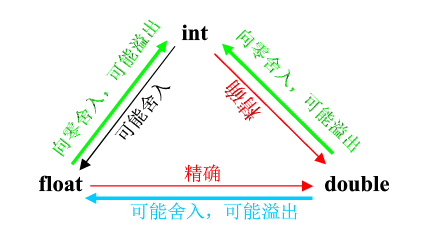
為什么int到float,為什么可能被舍入
float有23位用來表示有效數字,對于整數來說,超過2^23之后,很多數字都沒法精確表示了,比如2^23+1。
如果把2^23+1這個int轉化位float,就只能轉換成最接近的2^23。
返回分類
習題
2.60
#include <stdio.h>
#include <assert.h>unsigned replace_byte(unsigned x, int i, unsigned char b) {if (i < 0) {printf("error: i is negetive\n");return x;}if (i > sizeof(unsigned)-1) {printf("error: too big i");return x;}unsigned mask = ((unsigned) 0xFF) << (i << 3);unsigned pos_byte = ((unsigned) b) << (i << 3);return (x & ~mask) | pos_byte;
}int main(int argc, char *argv[]) {unsigned rep_0 = replace_byte(0x12345678, 0, 0xAB);unsigned rep_3 = replace_byte(0x12345678, 3, 0xAB);assert(rep_0 == 0x123456AB);assert(rep_3 == 0xAB345678);return 0;
}代碼托管
上周考試錯題總結
1.給定32位虛給定32位虛擬地址空間和24位的物理地址,頁面大小為8K,下面說法正確的是()
A .
VPN=13
B .
VPN=19
C .
PPO=13
D .
VPO=11
E .
PPN=11
正確答案: B C E
結對及互評
點評模板:
- 博客中值得學習的或問題:
-
- 代碼中值得學習的或問題:
- 本周結對學習情況
- [20155225](http://www.cnblogs.com/clever-universe/p/8052696.html)
- 結對照片
- 結對學習內容- 相互講解第二章和第五章的內容其他(感悟、思考等,可選)
在此學習第二章,相比于開學那一次學習有更多的收獲與見解。
學習進度條
| 代碼行數(新增/累積) | 博客量(新增/累積) | 學習時間(新增/累積) | 重要成長 | |
|---|---|---|---|---|
| 目標 | 5000行 | 15篇 | 400小時 | |
| 第一周 | 20/20 | 1/ | 12/12 | |
| 第二周 | 42/62 | 1/2 | 8/20 | |
| 第三周 | 62/124 | 1/3 | 14/34 | |
| 第四周 | 61/185 | 1/4 | 10/44 | |
| 第五周 | / | 2/6 | 13/57 | |
| 第六周 | / | 2/8 | 17/74 | |
| 第七周 | / | 2/10 | 15/89 | |
| 第八周 | / | 2/12 | 12/101 | |
| 第九周 | / | 2/14 | 10/111 | |
| 第十一周 | / | 1/16 | 12/123 | |
| 第十三周 | / | 2/18 | 17/140 | 學習認為最重要的一章 |
嘗試一下記錄「計劃學習時間」和「實際學習時間」,到期末看看能不能改進自己的計劃能力。這個工作學習中很重要,也很有用。
耗時估計的公式
:Y=X+X/N ,Y=X-X/N,訓練次數多了,X、Y就接近了。
參考:軟件工程軟件的估計為什么這么難,軟件工程 估計方法
計劃學習時間:18小時
實際學習時間:18小時
改進情況:本周是學習認為最重要的一章,雖然是重新學一遍,有了第一遍的基礎,但還是在一些問題上更深的去探討了
(有空多看看現代軟件工程 課件
軟件工程師能力自我評價表)
參考資料
- 《深入理解計算機系統V3》學習指導
- C語言中int到float的強制類型轉換








?是誰?))










?))