目錄
一、知識儲備
1、IOU——交集面積與并集面積之比
?2、混淆矩陣(TP、FP、FN、TN)
?問題1:上面的TP等具體是如何計算得到的?
3、精度precision&召回率recall
?二、ap計算實戰
1、計算流程
1)準備數據:
2)獲取預測框:
3)獲取標簽框:
4)根據置信度對預測框排序:
5)統計TP和FP個數:
6)對整個測試集上的每一張圖像的每一類進行TP,FP統計
7)分別對每一個類別進行ap曲線的繪制,這里以一類為例講解,以類別1為例
8)計算不同置信度下的precision和recall
問題2:怎么求解不同置信度閾值下的precision,recall值
問題3:出現的兩次預測有什么區別?
9)計算AP
10)計算map
三、學習筆記
一、知識儲備:
睿智的目標檢測20——利用mAP計算目標檢測精確度 https://blog.csdn.net/weixin_44791964/article/details/104695264?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522162156782416780262569069%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=162156782416780262569069&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~baidu_landing_v2~default-1-104695264.pc_search_result_hbase_insert&utm_term=map%E8%AE%A1%E7%AE%97&spm=1018.2226.3001.4187
https://blog.csdn.net/weixin_44791964/article/details/104695264?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522162156782416780262569069%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=162156782416780262569069&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~baidu_landing_v2~default-1-104695264.pc_search_result_hbase_insert&utm_term=map%E8%AE%A1%E7%AE%97&spm=1018.2226.3001.4187
IOU、FP、TP、TP、FN、Precision、recall
1、IOU——交集面積與并集面積之比
IOU(交并比)就是兩個bounding box的交集與并集之比
理解目標檢測當中的mAP_hsqyc的博客-CSDN博客_目標檢測map![]() https://blog.csdn.net/hsqyc/article/details/81702437
https://blog.csdn.net/hsqyc/article/details/81702437
 ?
? ?
?
def box_iou(b1, b2):'''b1,b2均為[x1,y1,x2,y2],左上角點,右下角點坐標'''x1_1, y1_1, x2_1, y2_1 = b1x1_2, y1_2, x2_2, y2_2 = b2x1 = max(x1_1, x1_2) # 取左上角點最大y1 = max(y1_1, y1_2)x2 = min(x2_1, x2_2)y2 = min(y2_1, y2_2)if x2 - x1 + 1 <= 0 or y2 - y1 + 1 <= 0:return 0else:inter = (x2 - x1 + 1) * (y2 - y1 + 1)union = (x2_1 - x1_1 + 1) * (y2_1 - y1_1 + 1) + (x2_2 - x1_2 + 1) * (y2_2 - y1_2 + 1) - interiou = inter / unionreturn iouif __name__ == '__main__':b1 = [0,0,4,4]b2 = [1,1,5,5]print(box_iou(b1,b2))b1 = [1,1,4,4]b2 = [2,0,5,5]print(box_iou(b1, b2))b1 = [0,0,2,2]b2 = [3,3,4,4]print(box_iou(b1,b2)) ?
?
?0.47058823529411764
0.42857142857142855
0
?2、混淆矩陣(TP、FP、FN、TN)
TP TN FP FN里面一共出現了4個字母,分別是T F P N。
T是True;
F是False;
P是Positive;
N是Negative。T或者F代表的是該樣本 是否被正確分類。
P或者N代表的是該樣本 被預測成了正樣本還是負樣本。TP(True Positives)意思就是被分為了正樣本,而且分對了。
TN(True Negatives)意思就是被分為了負樣本,而且分對了。
FP(False Positives)意思是被分為了正樣本,但是分錯了(事實上這個樣本是負樣本)。
FN(False Negatives)意思是被分為了負樣本,但是分錯(事實上這個樣本是正樣本)。
注意:對于多目標檢測中,每一個類別都會有一個混淆矩陣。因此每一個類別都會產生一個ap曲線
深度學習-目標檢測評估指標P-R曲線、AP、mAP_‘Atlas’的博客-CSDN博客_ap值基本概念P-R曲線中,P為圖中precision,即精準度,R為圖中recall,即召回率。Example下面通過具體例子說明。首先用訓練好的模型得到所有測試樣本的confidence score,每一類(如car)的confidence score保存到一個文件中(如comp1_cls_test_car.txt)。假設共有20個測試樣本,每個的id,confide...https://blog.csdn.net/qq_41994006/article/details/81051150
 ?
?
?問題1:上面的TP等具體是如何計算得到的?
在目標檢測中,混淆矩陣是針對一個類別來說的,利用訓練模型對測試集進行預測,此時會得到預測框和標簽框。每個預測框會有置信度、預測標簽、boxes(坐標)等信息;
1、若這個預測框被預測為正樣本計算這個預測框和真實標簽等于這個預測框的預測標簽的所有標簽框的IOU值:
1)當最大的iou值大于設定的閾值時,此時這個預測框就認為屬于TP樣本(預測和實際一致);
2)若iou最大值小于設定的閾值,則認為這個預測框為FP樣本(預測為該類的正樣本,實際不是);
2、若這個預測框被預測為負樣本,即背景框,計算這個預測框和所有標簽框的IOU值:
3)若iou值最大值小于閾值,則說明被正確預測為負樣本,即TN
4)若iou值最大值大于閾值,則說明被錯誤預測為負樣本,即FN
注意:在計算每一類ap的時候,一般只考慮預測為當前類的所有樣本,不考慮預測為背景的樣本
3、精度precision&召回率recall
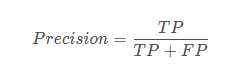 ?
?
TP是分類器認為是正樣本而且確實是正樣本的例子,FP是分類器認為是正樣本但實際上不是正樣本的例子,Precision翻譯成中文就是“分類器認為是正類并且確實是正類的部分占所有分類器認為是正類的比例”。
?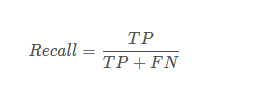 ?
?
TP是分類器認為是正樣本而且確實是正樣本的例子,FN是分類器認為是負樣本但實際上不是負樣本的例子,Recall翻譯成中文就是“分類器認為是正類并且確實是正類的部分占所有確實是正類的比例”。
?二、ap計算實戰
1、計算流程
準備數據:
- 測試集數據集(帶標簽框)、訓練好的深度學習模型、nms算法(iou閾值)(兩個重疊框iou大于閾值將低分的預測框去掉)
獲取預測框:
- 將測試數據集輸入到訓練好的深度學習模型當中,得到每張圖像的預測框,再利用nms算法去掉重復和重疊大的框后,記錄剩下預測框的信息(坐標信息——對角頂點坐標、類別、置信度)(boxes,label,confidence)——未排序
獲取標簽框:
- 根據測試數據集的xml文件得到真實標簽框的信息(groudtruth),包含每張圖像的標簽框信息(boxes,label),如下表所示:這里以兩類為例,標簽1,2表示不同的兩個目標類,0表示背景
序號(id) 對角頂點坐標(boxes) 真實類別(label) 1 【x1_1*,y1_1*,x1_2*,y1_2*】 1 2 【x2_1*,y2_1*,x2_2*,y2_2*】 1 3 【x3_1*,y3_1*,x3_2*,y3_2*】 2 4 【x4_1*,y4_1*,x4_2*,y4_2*】 2
根據置信度對預測框排序:
- 對每張圖像的預測框每一個類別按照置信度(分類得分)從高到低分別排序,得到類似與下列表格的信息
序號(id) 對角頂點坐標(boxes) 置信度(confidence) 預測類別(label) 1 【x1_1,y1_1,x1_2,y1_2】 0.98 2 2 【x2_1,y2_1,x2_2,y2_2】 0.90 1 3 【x3_1,y3_1,x3_2,y3_2】 0.88 1 4 【x4_1,y4_1,x4_2,y4_2】 0.86 2 5 【x5_1,y5_1,x5_2,y5_2】 0.67 1 6 【x6_1,y6_1,x6_2,y6_2】 0.51 2 預測為類別1:
序號(id) 對角頂點坐標(boxes) 置信度(confidence) 預測類別(label) 2 【x2_1,y2_1,x2_2,y2_2】 0.90 1 3 【x3_1,y3_1,x3_2,y3_2】 0.88 1 5 【x5_1,y5_1,x5_2,y5_2】 0.67 1 預測為類別2:
序號(id) 對角頂點坐標(boxes) 置信度(confidence) 預測類別(label) 1 【x1_1,y1_1,x1_2,y1_2】 0.98 2 4 【x4_1,y4_1,x4_2,y4_2】 0.86 2 6 【x6_1,y6_1,x6_2,y6_2】 0.51 2
?統計TP和FP個數:
- 對每張圖像中的每一類進行TP和FP個數統計,假設一個預測框預測為類別2,則計算這個預測框和該圖像中所有類別為2的標簽框的iou,若iou大于設定的閾值(一般默認閾值為0.5),則認為該預測框為TP,否則認為是FP,以下以一張圖像中的類別為例:(gtid表示序號為id的標簽框,preid表示序號為id的預測框),maxiou(preid,gtid(3,4))表示序號為id的預測框和所有類別為2的標簽框的最大iou值,tp/fp表示預測框預測的正確與否,正確則為tp,否則為fp,為了方便,這里tp記為1,fp記為0
序號id max iou(preid,gtid(3,4)) 置信度 預測label tp/fp 1 0.65 0.98 2 1 4 0.68 0.86 2 1 6 0.45 0.51 2 0 序號id max iou(preid,gtid(1,2)) 置信度 預測label tp/fp 2 0.51 0.90 1 1 3 0.4 0.88 1 0 5 0.9 0.67 1 1 由上表可以看到,在類別2預測框當中,2個預測正確,1個預測錯誤,在類別1預測框當中,2個預測正確,1個預測錯誤。
- 對單張圖像的每一類進行TP,FP統計,最后匯總到成一張表格,別處摘的圖,這里是3類
參考:目標檢測中的AP計算_lppfwl的博客-CSDN博客_目標檢測ap計算
?
對整個測試集上的每一張圖像的每一類進行TP,FP統計
- 最后匯總到成一張表格,表格和上面表格一樣,只是數量上增加了而已,為了方便講解這里以一張圖像的為例進行講解
分別對每一個類別進行ap曲線的繪制,這里以一類為例講解,以類別1為例
計算不同置信度下的precision和recall
--------------------------------------------------------------------------------------------------------------------------
問題2:怎么求解不同置信度閾值下的precision,recall值
答:假設置信度閾值為thre,則當預測框的置信度大于等于thre時,將預測框視為正樣本,小于閾值thre時,將預測框視為負樣本。前面利用iou得到的tp/fp則作為當前預測框的真實標簽,1表示實際為正樣本,0表示實際為負樣本。這樣又有預測框的真實標簽、預測標簽、置信度、置信度閾值就可以求解出當前類的TP.FP.FN.TN,進而求解precision和recall
問題3:出現的兩次預測有什么區別?
答:仔細看可以發現,在前面出現了兩次預測框的標簽預測,
1)第一次確定預測框的預測類別是否正確。根據預測框和當前預測類的所有標簽框進行iou計算,然后判斷是否預測成功,這里其實就是將預測為同一類的預測框分為兩類,預測正確和不正確兩類,正確為1,不正確為0,這個就作為這個預測框在預測類中的真實標簽;
2)第二次是人為劃分了置信度閾值,根據閾值來決定預測框的正負性,當預測框的置信度大于等于thre時,將預測框視為正樣本,小于閾值thre時,將預測框視為負樣本。這個作為當前置信度閾值下的預測標簽。
根據預測標簽和真實標簽就能夠計算在當前置信度閾值下的混淆矩陣,從而得到precision和recall
--------------------------------------------------------------------------------------------------------------------------
序號id 置信度conference 預測標簽 tp/fp 5 0.66 1 1 10 0.55 1 0 2 0.45 1 1 8 0.34 1 0 1 0.23 1 0 ?將置信度從1到0依次取點會得到一系列的(precision,recall)的坐標點,初始坐標點為(0,1),結束點為(1,0),置信度的取點我們可以根據預測框的置信度進行取點,比如conferences = 【0.66,0.55,0.45,0.34,0.23】,當置信度閾值分別等于這些值時,precision和recall取值是不一樣的
???
????
序號id 置信度conference 置信度閾值 tp/fp precision recall 5 0.66 0.66 1 1/(1+0) = 1 1/(1+1)=1/2 10 0.55 0.55 0 1/(1+1)=1/2 1/(1+1)=1/2 2 0.45 0.45 1 2/(2+1) = 2/3 2/(2+0) = 1 8 0.34 0.34 0 2/(2+2) = 1/2 2/(2+0) = 1 1 0.23 0.23 0 2/(2+3) = 2/5 2/(2+0) = 1 由上表可以看出,這樣我們就得到了precision和recall的點對,注意,當一個recall對應多個precision時,取最大的precision即可,例如在recall=1時,對應precision=2/3、1/2、2/5、0,這時候我們取2/3即可
點對如下:(recall,precision)
【(0,1),(1/2,1),(1,2/3),(1,1/2),(1,2/5),(1,0)】最終根據這些點就可以繪制出ap曲線圖
?
計算AP
AP(average precision)= 曲線面積
比如上圖:
AP = 1/2 + (1/2+2/3)*1/2*1/2 = 19/24
計算map
map指的就是所有類的平均ap值,map = (ap1+ap2+...+apn)/n,其中n為標簽類別號
三、學習筆記
 ?
?





 module for PHP 5))


-Wednesday)
...)


![[OJ] Wildcard Matching (Hard)](http://pic.xiahunao.cn/[OJ] Wildcard Matching (Hard))
)





