目錄
一、候選框大量重疊問題
1、NMS核心思想
2、 步驟:
????????3、缺陷
4、改進
1)soft NMS——衰減的方式來減小預測框的分類得分
?2)softer nms——增加了位置置信度
二、樣本不平衡問題
1、不平滑的來源(3方面)
1)正負樣本不平衡
2)難易樣本不平衡
3)類別間樣本不平衡
?2、解決樣本不平衡的方法
?1)在線難樣本挖掘(online hard example mining,OHEM)
2) Focal Loss(專注難樣本的一個損失函數)
??????? 標準交叉熵損失
??????? 平衡交叉熵損失
??????? Focal Loss
3、一階段和二階段的區別
三、過擬合問題
一、候選框大量重疊問題
1、NMS核心思想
NMS:非極大值抑制,抑制的是得分低的預測框,涉及到兩個指標,IOU(交并比:兩個框的重疊區域面積與兩個框并集面積的比值)和預測框得分,若有多個預測框預測的是同一個物體,若兩個框的IOU值大于閾值(一般閾值取0.5和0.7),那么NMS算法將會把得分低的預測框丟棄。
 ?
?
2、 步驟:
1)得到所有的預測框
2)將預測框按照得分降序排序
3)將最高得分的預測框與剩余的預測框,計算IOU,將IOU大于閾值的框去掉
4)將最高得分的預測框記錄下來,再從剩下的預測框中重復1)-4)直到只有一個預測框為止



3、缺陷
1)當物體出現比較密集的時候,兩個預測框的IOU比值也有可以會超過閾值,強制將得分低的預測框去掉,會導致漏檢,降低模型的召回率。這對于互相遮擋的物體群檢測是不利的。
2)閾值難以確定。過高導致誤檢率高,過低導致漏檢低。
3)單純使用預測框得分來作為預測框的置信度,不太合適,因為有的預測框雖然得分高,但是預測的位置不準確
4)速度慢,算法涉及多重循環,在進行大量預測框的計算時,會速度減慢
4、改進
1)soft NMS——衰減的方式來減小預測框的分類得分
NMS強制將IOU超過閾值的低分預測框歸零,soft nms是通過衰減的方法來將低分的預測框的得分降低,這樣在后面可能會將這個框保留下來。開始不會將預測框強制去掉,而是到最后去掉低于置信度閾值的預測框

 具體得分衰減公式主要分為線性衰減和高斯衰減,線性衰減因為在閾值附近會出現得分的突變,不是連續的,這種跳變會給檢測帶來很大的波動,一般情況下采用的是連續的高斯衰減。
具體得分衰減公式主要分為線性衰減和高斯衰減,線性衰減因為在閾值附近會出現得分的突變,不是連續的,這種跳變會給檢測帶來很大的波動,一般情況下采用的是連續的高斯衰減。
Soft-NMS的改進有兩種形式,一種是線性加權的:

一種是高斯加權的:

不足:
1)閾值還是比較難確定
2)得分高的位置未必準確
改進:
相對于nms的改進在于不是強制將得分低的預測框給丟棄,而是將其保留但是降低了其得分,使得對于密集目標檢測的時候不至于漏檢,減緩了這種問題,有效地提高了準確率
?2)softer nms——增加了位置置信度
nms和soft nms都是采用了分類置信度(得分)來作為預測框的排序指標,這種情況只適用于所有的得分高的預測框的位置和分類一樣準確的情況下。但是實際情況不是這樣的,分類得分高的預測框其位置不一定準確,因此基于這個考慮,提出了sofer nms,主要是在nms的基礎上不斷地改變預測框的位置,以此來增加預測框的位置精度。
二、樣本不平衡問題
1、不平滑的來源(3方面)
1)正負樣本不平衡
正樣本:含有目標物體的候選框
負樣本:不含目標物體的候選框
在一張圖像中,一般只存在個位數的目標對象,但是深度學習網絡一般會生成大量的候選框,比如faster-rcnn利用RPN網絡生成了2000個錨框,這里面可能有100個正樣本框,其余都是大量的背景框(負樣本),導致正負樣本數量極度不平衡,降低了精度
2)難易樣本不平衡
難樣本:分類不明確的樣本,比如候選框在前景和背景的過渡區域的框,分為難正樣本,難負樣本
易樣本:分類明確,分為易正樣本與易負樣本,和真實框重合度非常高為易正樣本,和真實框不重合的為易負樣本
在fasterrcnn中rpn生成框網絡中,生成了大量的候選框,大部分的候選框都是易樣本,這對于模型的參數收斂作用是非常有限的,而我們更加希望的是模型去利用難樣本進行模型的訓練,以此來提高精確度。但是大量的候選框都是在背景上,這導致易樣本數量龐大,而這部分更有價值的難樣本的數量卻非常有限,這就造成了難易樣本的不平衡。一般難易不平衡和正負樣本不平衡問題是有交叉的,這就導致解決這兩個問題的方法是可以通用有效的。
3)類別間樣本不平衡
在有些問題中,存在多類別分類,但是不同目標的數量不一樣,如數據集中有100萬個車輛的標簽,有1000個行人的標簽,這導致在訓練的過程中,模型會更加地關注與減小車輛的損失,而導致行人的檢測精度大大下降。不同類別的數量差異,導致了類別間不平衡。
?2、解決樣本不平衡的方法
通用方法:
1)在fasterRcnn和SSD中,根據樣本與真實物體的IOU大小,設置了3:1的正負樣本比例。緩解了前兩種的不均衡物體
2)在RPN中根據前景的得分排序篩選出了2000個框作為候選框,也實現了樣本不平衡的緩解
3)權重懲罰:對于難易樣本不平衡和類別間不平衡的方法,可以增加對難樣本和少樣本的損失權重,緩解不平衡問題
4)數據增強:擴充數據量來實現類別間不平衡的方法
?1)在線難樣本挖掘(online hard example mining,OHEM)
由兩個RCNN組成,一個RCNN負責前向傳播,得到難樣本,一個RCNN進行前向和后向傳播,實現參數的更新。難樣本的話主要是將損失較大的樣本作為難樣本
參考:https://zhuanlan.zhihu.com/p/59002127
2) Focal Loss(專注難樣本的一個損失函數)
參考:https://blog.csdn.net/qq_42013574/article/details/105864230
1.標準交叉熵損失
標準的交叉熵(Cross Entropy,CE)函數,其形式如下所示。
公式中,p代表樣本在該類別的預測概率,y代表樣本標簽。可以看出,當標簽為1時,p越接近1,則損失越小;標簽為0時p越接近0,則損失越小,符合優化的方向。(當預測標簽越接近真實標簽時,損失越小)標準的交叉熵中所有樣本的權重都是相同的,因此如果正、負樣本不均衡,大量簡單的負樣本會占據主導地位,少量的難樣本與正樣 本會起不到作用,導致精度變差。
為了方便表示,按照中將p標記為pt:
則交叉熵可以表示為:
2.平衡交叉熵損失?
為了改善樣本的不平衡問題,平衡交叉熵在標準的基礎上增加了 一個系數αt來平衡正、負樣本的權重,αt由超參α按照下式計算得來,α取值在[0,1]區間內。
有了αt,平衡交叉熵損失公式如式:
盡管平衡交叉熵損失改善了正、負樣本間的不平衡,但由于其缺 乏對難易樣本的區分,因此沒有辦法控制難易樣本之間的不均衡。3.Focal Loss
Focal Loss為了同時調節正、負樣本與難易樣本,提出了如下式所示的損失函數。
對于該損失函數,有如下3個屬性:??? 與平衡交叉熵類似,引入了αt權重,為了改善正負樣本的不均衡,可以提升一些精度。
??? ·(1-pt)^γ是為了調節難易樣本的權重。當一個邊框被誤分類時,pt 較小,則(1-pt)γ接近于1,其損失幾乎不受影響;當pt接近于1時,表明其分類預測較好,是簡單樣本,(1-pt)γ接近于0,因此其損失被調低了。
??? γ是一個調制因子,γ越大,簡單樣本損失的貢獻會越低。為了驗證Focal Loss的效果,何凱明等人還提出了一個一階物體 檢測結構RetinaNet。
?對于RetinaNet的網絡結構,有以下5個細節:
??? 在Backbone部分,RetinaNet利用ResNet與FPN構建了一個多尺 度特征的特征金字塔。
??? RetinaNet使用了類似于Anchor的預選框,在每一個金字塔層, 使用了9個大小不同的預選框。
??? 分類子網絡:分類子網絡為每一個預選框預測其類別,因此其 輸出特征大小為KA×W×H,A默認為9,K代表類別數。中間使用全 卷積網絡與ReLU激活函數,最后利用Sigmoid函數輸出預測值。
??? 回歸子網絡:回歸子網絡與分類子網絡平行,預測每一個預選框的偏移量,最終輸出特征大小為4A×W×W。與當前主流工作不同 的是,兩個子網絡沒有權重的共享。
??? ·Focal Loss:Focal Loss在訓練時作用到所有的預選框上。對于兩個超參數,通常來講,當γ增大時,α應當適當減小。實驗中γ取2、α取0.25時效果最好。
?




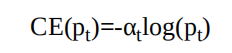

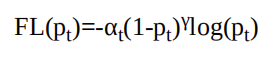

3、一階段和二階段的區別
fasterrcnn的精度比SSD高的原因主要是因為多了一個RPN網絡,用于生成正負樣本3:1的樣本,解決了正負樣本不平衡的問題,但是SSD一階段的是直接篩選得到的預測框,因此主要的原因就是因為正負樣本不平衡的原因造成了二者之間精度的區別。而focal loss損失函數構造出來的retinanet模型在精度上是可以和fasterrcnn媲美的。
三、過擬合問題
可看文章:原創 【深度學習】——過擬合的處理方法



)

:)
)






)

——ROS簡介)



?和?interceptor(攔截器)的區別)