Chapter2 KNN
1.numpy.tile函數
格式:tile(A,reps)?
* A:array_like?
* 輸入的array?
* reps:array_like?
* A沿各個維度重復的次數
舉例:A=[1,2]?
1. tile(A,2)?
結果:[1,2,1,2]?
2. tile(A,(2,3))?
結果:[[1,2,1,2,1,2], [1,2,1,2,1,2]]?
3. tile(A,(2,2,3))?
結果:[[[1,2,1,2,1,2], [1,2,1,2,1,2]],?
[[1,2,1,2,1,2], [1,2,1,2,1,2]]]
reps的數字從后往前分別對應A的第N個維度的重復次數。
?
2.numpy.shape函數
shape函數是numpy.core.fromnumeric中的函數,它的功能是讀取矩陣的形狀,比如shape[0]就是讀取矩陣第一維度的長度。

?
?
3.numpy.sum函數(axis=)
python內建函數的sum應該是默認的axis=0 就是普通的相加,當加入axis=1以后就是將一個矩陣的每一行向量相加。
例如:
c = np.array([[0, 2, 1], [3, 5, 6], [0, 1, 1]])
print c.sum()
print c.sum(axis=0)
print c.sum(axis=1)
結果分別是:19, [3 8 8], [ 3 14 2]
#axis=0, 表示列。
#axis=1, 表示行。 ?
4.字典的get方法
dict.get(key, "NO")
如果key在字典中不存在,返回第二個參數的值,例如這里返回"NO"
?
5.numpy.argsort函數
array.argsort()返回的是array數組中的值的從小到大的索引
例如x = [2,4,3,1]
![]()

注意這里numpy的數組要用它自己的array函數來定義,不能直接定義數組
?
6. sorted函數
?
a = {'math':98, 'english':100, 'PE':77}
b = sorted(a.iteritems(), key=operator.itemgetter(1), reverse=True) ?
iteritems是循環迭代字典a中的每一個key-value對,itemgetter(1)表示排序是根據value的值排序(0則是key),reverse=True代表降序
?
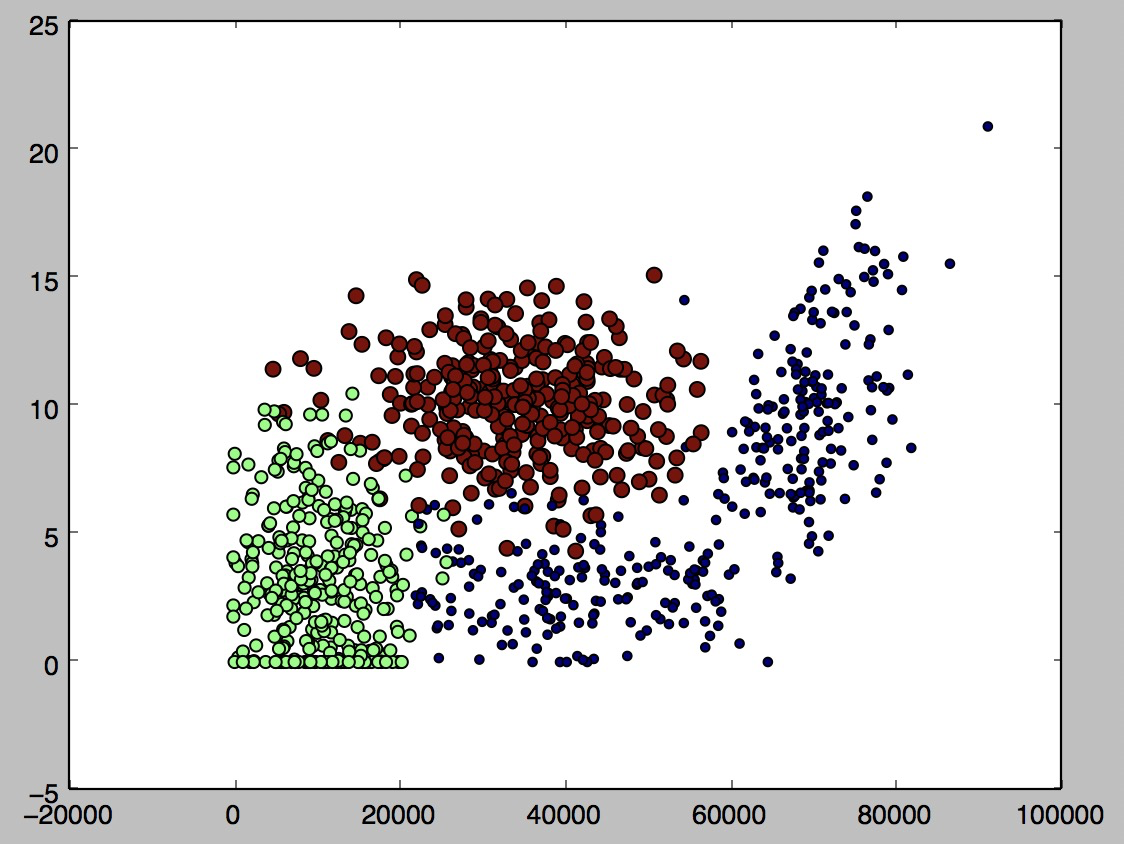
橫軸:每年飛行里程數 ?縱軸:玩電子游戲時間
綠色:不具魅力 ?藍色:魅力一般 ?紅色:極具魅力
Helen女士的擇偶標準挺不錯0.0
?
7.numpy.min() numpy.max()
numpy里的min(0)、max(0) 參數0表示列中取得最小值,而不是選取當前行的最小值,這也是用來處理矩陣的
?
8.使用open(filename)函數時出現錯誤:
File "/Users/qcy/PycharmProjects/MachineLearning/KNN.py", line 109, in img2vector
fr = open(filename)
TypeError: function takes at least 2 arguments (1 given)
這是由于在from os import * 時,把os.open()函數引入了,從而覆蓋了python的built-in的open()函數,這兩個open()函數使用的方法是不一樣的。所以只import需要使用的函數就行,改成from os import listdir
?
總結:KNN這個算法其實挺笨的,它并沒有真正的使用訓練集訓練出一個模型,而是在測試時直接把測試的矩陣擴大到訓練矩陣的規模,然后做一個距離的計算,取前K個,哪個類別的歸類多就歸到哪類。這種分類方式準確率還行,但是它運行的時間和占用的空間可能太過龐大了。 通過這一章也熟悉了使用numpy庫對矩陣進行操作。“KNN另一個缺陷時它無法給出任何數據的基礎結構信息,因此我們也無法知曉平均實例樣本和典型實例樣本具有什么特征。” ?(???)
?
?






)



【番外篇二】)
)







