不久乘高鐵出行,看見高鐵火車站已經實現了“刷臉進站”,而且效率很高,很感興趣,今天抽時間研究一下,其實沒那么復雜。
我基本上是基于https://github.com/ageitgey/face_recognition上的資料和源碼做一些嘗試和試驗。
首先,需要配置我們的python環境,我懸著的python27(比較穩定),具體過程不多說了。
然后,需要安裝這次的主角face_recognition庫,這個的安裝花了我不少時間,需要注意一下幾點(按照本人的環境):
1,首先,安裝visual studio 2015,因為vs2015默認只安裝c#相關組件,所以需要安裝c++相關組件。
ps:vs2015安裝c++相關組件的方法:在vs2015中新建c++項目,出現下面場景

選擇第二項,確定后就會自動安裝。
為什么需要安裝c++,因為安裝face_recognition時會先安裝dlib,dlib是基于c++的一個庫。
2,安裝cmake(一個跨平臺編譯工具),然后需要將cmake的安裝路徑加入到系統環境變量path中去。
最后,就可以直接在dos中執行安裝命令了(需要切換到python目錄下的Script目錄下):pip install? face_recognition,命令會自動幫你安裝好需要的dlib庫。
到此為止,我們完成了face_recognition安裝工作。
?
---------------------------------------------------------------分割線----------------------------------------------------------------------------------
下面給出幾個實例來逐步了解“人臉識別”:
1.一行代碼實現“人臉識別”
?
在Python目錄中新建兩個文件夾:分別表示“已知姓名的人”和“未知姓名的人”,圖片以額、人名命名,如下:

?
?接下來,我們通過“認識的人”來識別“不認識的人”:

結果表明:1.jpg不認識,3.jpg是obama,unkown.jpg中有兩個人,一個是obama,另一個不認識
結果還挺準確的!很給力!!
?
2.識別圖片中所有的人臉,并顯示出來


import Image import face_recognition image = face_recognition.load_image_file('F:/Python27/Scripts/all.jpg') face_locations = face_recognition.face_locations(image)#face_locations =face_recognition.#face_locations(image,number_of_times_to_upsample=0,model='cnn') print('i found {} face(s) in this photograph.'.format(len(face_locations))) for face_location in face_locations:top,right,bottom,left = face_locationprint('A face is located at pixel location Top:{},Left:{},Bottom:{},Right:{}'.format(top,right,bottom,left))face_image = image[top:bottom,left:right]pil_image=Image.fromarray(face_image)pil_image.show()
避坑指南:import Image需要先安裝PIL庫,在pycharm中安裝的時候會報錯(因為pil沒有64位的版本),這時我們安裝Pillow-PIL就好了。
我們的all.jpg如下:

?
?執行以下,看看結果:
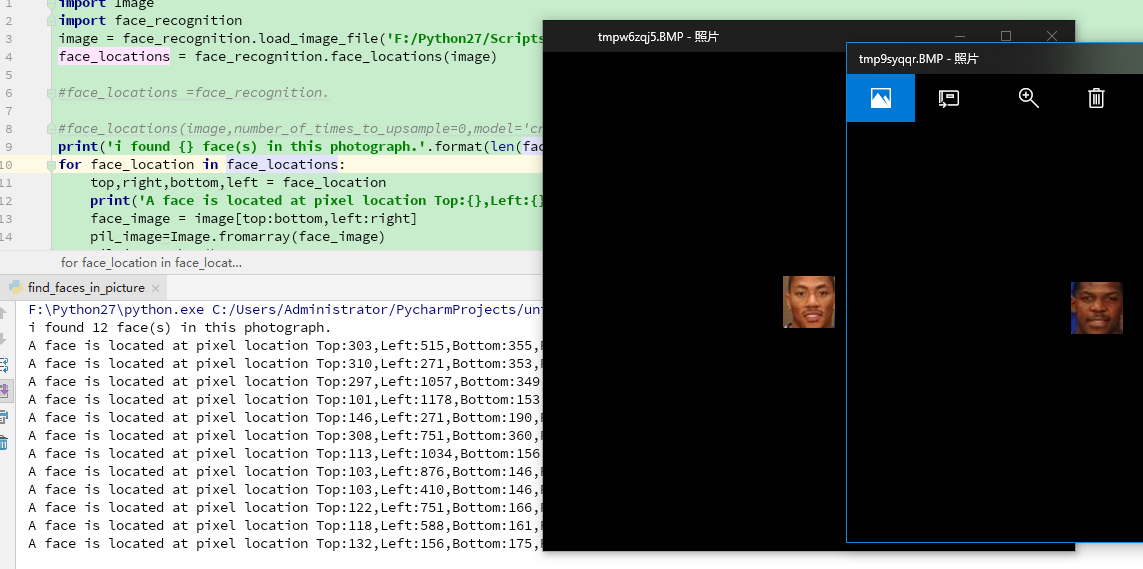
沒有錯,總共12個人臉都被識別出來了!!!
?
3.給照片“美顏”
face_recognition可以識別人像的下巴,眼睛,鼻子,嘴唇,眼球等區域,包含以下這些個特征:
facial_features = [?'chin',?'left_eyebrow',?'right_eyebrow',?'nose_bridge',?'nose_tip',?'left_eye',?'right_eye',?'top_lip',?'bottom_lip' ]
? ? ? ?利用這些特征屬性,可以輕松的給人像“美顏”
from PIL import Image, ImageDraw face_recognition import face_recognitionimage = face_recognition.load_image_file("F:/Python27/Scripts/known_people/obama.jpg")#查找圖像中所有面部的所有面部特征 face_landmarks_list = face_recognition.face_landmarks(image)for face_landmarks in face_landmarks_list:pil_image = Image.fromarray(image)d = ImageDraw.Draw(pil_image, 'RGBA')#讓眉毛變成了一場噩夢d.polygon(face_landmarks['left_eyebrow'], fill=(68, 54, 39, 128))d.polygon(face_landmarks['right_eyebrow'], fill=(68, 54, 39, 128))d.line(face_landmarks['left_eyebrow'], fill=(68, 54, 39, 150), width=5)d.line(face_landmarks['right_eyebrow'], fill=(68, 54, 39, 150), width=5)#光澤的嘴唇d.polygon(face_landmarks['top_lip'], fill=(150, 0, 0, 128))d.polygon(face_landmarks['bottom_lip'], fill=(150, 0, 0, 128))d.line(face_landmarks['top_lip'], fill=(150, 0, 0, 64), width=8)d.line(face_landmarks['bottom_lip'], fill=(150, 0, 0, 64), width=8)#閃耀眼睛d.polygon(face_landmarks['left_eye'], fill=(255, 255, 255, 30))d.polygon(face_landmarks['right_eye'], fill=(255, 255, 255, 30))#涂一些眼線d.line(face_landmarks['left_eye'] + [face_landmarks['left_eye'][0]], fill=(0, 0, 0, 110), width=6)d.line(face_landmarks['right_eye'] + [face_landmarks['right_eye'][0]], fill=(0, 0, 0, 110), width=6)pil_image.show()
執行下看看結果:

有點辣眼睛!!!!
?
4.利用筆記本攝像頭識別人像
回到前面說的高鐵站的“刷臉”,其實就是基于攝像頭的“人像識別”。
這里要調用電腦的攝像頭,而且涉及一些計算機視覺系統的計算,所以我們要先安裝opencv庫,
安裝方法:
pip install --upgrade setuptools pip install numpy Matplotlib pip install opencv-python
ps:如果報錯:EnvironmentError:?[Errno 13]?Permission denied: 在install后加上--user即可
? ? ? ? ?小技巧:可以在python命令行中用?import site; site.getsitepackages()來確定當前的python環境的site-packages目錄的位置
目的:這里我們需要用攝像頭識別自己,那么首先需要有一張自己的照片,我將我的照片命名為mike.jpg,然后使用攝像頭來識別我自己。
?看看代碼:
import face_recognition import cv2# This is a demo of running face recognition on live video from your webcam. It's a little more complicated than the # other example, but it includes some basic performance tweaks to make things run a lot faster: # 1. Process each video frame at 1/4 resolution (though still display it at full resolution) # 2. Only detect faces in every other frame of video.# PLEASE NOTE: This example requires OpenCV (the `cv2` library) to be installed only to read from your webcam. # OpenCV is *not* required to use the face_recognition library. It's only required if you want to run this # specific demo. If you have trouble installing it, try any of the other demos that don't require it instead.# Get a reference to webcam #0 (the default one) video_capture = cv2.VideoCapture(0)# Load a sample picture and learn how to recognize it. obama_image = face_recognition.load_image_file("F:/Python27/Scripts/known_people/obama.jpg") obama_face_encoding = face_recognition.face_encodings(obama_image)[0]# Load a second sample picture and learn how to recognize it. biden_image = face_recognition.load_image_file("F:/Python27/Scripts/known_people/mike.jpg") biden_face_encoding = face_recognition.face_encodings(biden_image)[0]# Create arrays of known face encodings and their names known_face_encodings = [obama_face_encoding,biden_face_encoding ] known_face_names = ["Barack Obama","mike" ]# Initialize some variables face_locations = [] face_encodings = [] face_names = [] process_this_frame = Truewhile True:# Grab a single frame of videoret, frame = video_capture.read()# Resize frame of video to 1/4 size for faster face recognition processingsmall_frame = cv2.resize(frame, (0, 0), fx=0.25, fy=0.25)# Convert the image from BGR color (which OpenCV uses) to RGB color (which face_recognition uses)rgb_small_frame = small_frame[:, :, ::-1]# Only process every other frame of video to save timeif process_this_frame:# Find all the faces and face encodings in the current frame of videoface_locations = face_recognition.face_locations(rgb_small_frame)face_encodings = face_recognition.face_encodings(rgb_small_frame, face_locations)face_names = []for face_encoding in face_encodings:# See if the face is a match for the known face(s)matches = face_recognition.compare_faces(known_face_encodings, face_encoding)name = "Unknown"# If a match was found in known_face_encodings, just use the first one.if True in matches:first_match_index = matches.index(True)name = known_face_names[first_match_index]face_names.append(name)process_this_frame = not process_this_frame# Display the resultsfor (top, right, bottom, left), name in zip(face_locations, face_names):# Scale back up face locations since the frame we detected in was scaled to 1/4 sizetop *= 4right *= 4bottom *= 4left *= 4# Draw a box around the facecv2.rectangle(frame, (left, top), (right, bottom), (0, 0, 255), 2)# Draw a label with a name below the facecv2.rectangle(frame, (left, bottom - 35), (right, bottom), (0, 0, 255), cv2.FILLED)font = cv2.FONT_HERSHEY_DUPLEXcv2.putText(frame, name, (left + 6, bottom - 6), font, 1.0, (255, 255, 255), 1)# Display the resulting imagecv2.imshow('Video', frame)# Hit 'q' on the keyboard to quit!if cv2.waitKey(1) & 0xFF == ord('q'):break# Release handle to the webcam video_capture.release() cv2.destroyAllWindows()
只想看看結果:
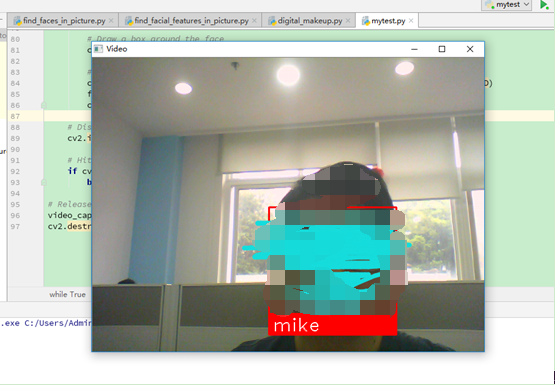
?
看來,我被識別成功了。看起來有點小激動呢。
?
?
?
通過上面四個小例子基本了解face_recognition的用法,這只是小試牛刀,具體在現實中的應用要復雜很多,
我們需要大量的人臉數據,會涉及到機器學習和數學算法等等,而且根據應用場景的不同也會出現很多不同的要求。
這里只是一起學習分享,期待后續關于"人工智能"的內容。
?

)













)



