一、B+樹是應文件系統所需而產生的一種B樹的變形樹
1. 定義(使用階數m來定義)
- 除了根結點外,其他非終端結點最多有m個關鍵字,最少有?m/2?個關鍵字
- 結點中的每個關鍵字對應一個子樹
- 所有的非終端結點可以看成是索引部分,結點中僅含有其子樹根結點中最大(或最小)關鍵字
-
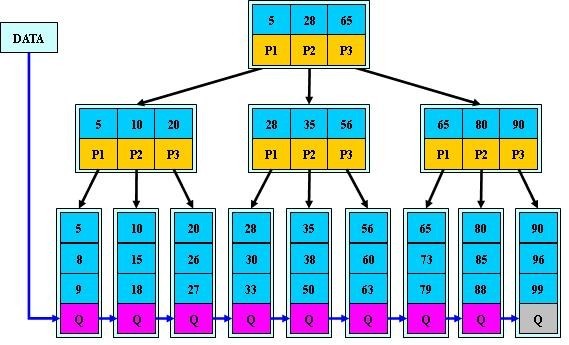
所有的葉子節點包含了全部的關鍵字以及指向含有這些關鍵字記錄的指針,并且:
- 同一葉子節點中的關鍵字按大小順序排列
- 相鄰的葉子節點順序鏈接(相當于是構成了一個順序鏈表)
- 所有葉子節點在同一層
?
2. 和B樹的區別
對于非終端結點,關鍵字的個數與其子樹的個數相同;不像B樹,子樹的個數總比關鍵字的個數多1。
所有的關鍵字及相應的指針都在葉子結點中;不像B樹,有的關鍵字是在內部結點中。(換句話說,在B+樹中,內部結點僅僅起到索引的作用。在搜索過程中,如果待查詢的關鍵字和內部結點的關鍵字一致,那么搜索過程不停止,而是繼續向下搜索這個分支)
- 關鍵字的數量不同:B+樹中,對于非終端結點,關鍵字的個數與其子樹的個數相同;而B樹中,關鍵字的個數比子樹的個數少1。
- 存儲的位置不同:B+樹中的數據都存儲在葉子結點上,也就是其所有葉子結點的數據組合起來就是完整的數據;而B樹的數據存儲在每一個結點中。
- 非終端結點的構造不同:B+樹的非終端結點僅僅存儲著關鍵字信息和指向孩子的指針(這里的指針指的是磁盤塊的偏移量),也就是說內部結點僅僅包含著索引信息。
- 查詢不同:B樹在找到具體的數值以后,則結束;而B+樹則需要通過索引找到葉子結點中的數據才結束,也就是說B+樹的搜索過程中走了一條從根結點到葉子結點的路徑。
?
?
二、關于B+樹的面試題
1. 為何B+樹用于數據庫索引?
B樹在提高了磁盤IO性能的同時并沒有解決元素遍歷的效率低下的問題。B樹的其非終端結點同樣存儲著數據,因此如果我們要找到具體的數據,就需要進行一次中序遍歷。正是為了解決這個問題,B+樹應運而生。
B+樹的數據都存儲在葉子結點中,非終端結點均為索引,方便掃庫,只需要遍歷葉子結點即可實現整棵樹的遍歷。所以B+樹更加適合在區間查詢的情況,而且在數據庫中基于范圍的查詢是非常頻繁的,所以通常B+樹用于數據庫索引。
?
2. 為何相比于B樹,B+樹在文件系統和數據庫系統中更具優勢?
①B+樹的磁盤讀寫代價更低?
B+樹的非終端結點并沒有指向關鍵字具體信息的指針,因此其內部結點相對B樹更小。如果把同一非終端結點的所有關鍵字存放在同一盤塊中,那么盤塊所能容納的關鍵字數量也越多。一次性讀入內存中的需要查找的關鍵字也就越多。相對來說I/O讀寫次數也就降低了。
舉個例子,假設磁盤中的一個盤塊容納16bytes,而一個關鍵字2bytes,一個關鍵字具體信息指針2bytes。一棵9階B樹(一個結點最多8個關鍵字)的非終端結點需要2個盤快。而B+樹非終端結點只需要1個盤快。當需要把非終端結點讀入內存中的時候,B樹就比B+樹多一次盤塊查找時間(在磁盤中就是盤片旋轉的時間)。
②B+樹的查詢效率更加穩定?
由于非終端結點并不是最終指向文件內容的結點,而只是葉子結點中關鍵字的索引。所以任何關鍵字的查找必須走一條從根結點到葉子結點的路徑。所有關鍵字查詢的路徑長度相同,導致每一個數據的查詢效率相當。
③B+樹更有利于對數據庫的掃描?
B樹在提高了磁盤IO性能的同時并沒有解決元素遍歷的效率低下的問題,而B+樹只需要遍歷葉子節點就可以解決對全部關鍵字信息的掃描,所以對于數據庫中頻繁使用的范圍查詢,B+樹有著更高的性能。
?




)
)
————HDFS HA)


)
 整體架構介紹)

項目實戰工具類(一):PhoneUtil(手機信息相關))

—— LOFIC)
![[模板]平面最近點對](http://pic.xiahunao.cn/[模板]平面最近點對)



