BW算法是對某一個HMM(一個音素)進行訓練,需要該HMM對應的觀察向量(一段音頻),如何讓一段文本中的某個音素找到對應一整段音頻中的一小段音頻?需要用到對齊來找到所有的[音素-音頻]的配對。
? ?
訓練時也需要解碼

1,設訓練的一句話有n個音素,即n個HMM,即3n個狀態。將這句話對應的音頻平均地切分為n個片段(無環回的HMM),每個片段有3個狀態(無環回,否則一個HMM大于三個狀態)
2,使用k-means算法,將每個狀態對應的所有特征向量聚類為M個簇(這句話有3nM個簇)
3,為狀態i中的每個簇計算均值、協方差矩陣和混合權重(即計算一個GMM,這句話有3nM個GMM)
4,用3中計算好的所有GMMs(3nM個)將這一段音頻解碼(維特比解碼)為多個狀態,多個HMM
5,重復上述2-4步直至收斂
? ?
hmm_chinese.pdf p59
在訓練時用的是Viterbi算法,在識別時則用狀態Viterbi算法處理狀態級數據,用詞匯Viterbi算法處理詞匯級數據
? ?
識別過程
不考慮句法時,識別過程很類似連接詞識別中的一次通過算法
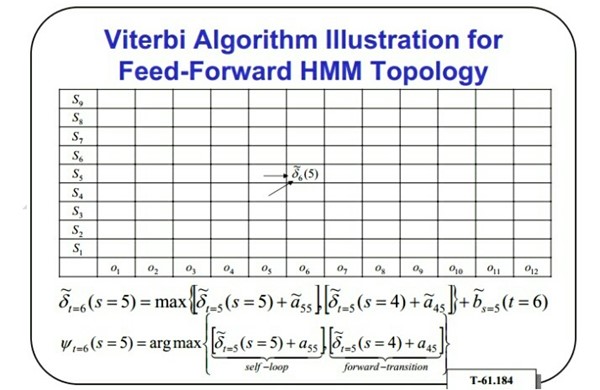
將詞匯表中所有詞對應的所有音素的所有狀態排成一排,讀入一個待識別句子的語音數據,由維特比算法可得到一個最佳狀態序列。得到狀態序列后,可通過類似編譯原理中的文法來得到對應的HMM序列。
? ?
聲學模型(HMMs)表示的是各詞內狀態之間的轉移
語言模型(n-gram)表示的是詞之間的轉移概率關系
? ?
解碼時需要用到狀態Viterbi算法和詞匯Viterbi算法
? ?
一句話的識別過程需要在狀態層與詞匯層之前不斷切換,狀態層:為當前狀態選擇概率最大的幾個下一狀態,直至詞的最后狀態處;詞匯層:為當前詞選擇概率最大的幾個下一詞。這樣直至這句話的結尾,就得到了多條路徑,每條路徑包含兩個信息:累積概率和回溯路徑,選擇多條路徑中累積概率最大的那條路徑,使用其回溯路徑進行回溯,就得到了該句子的識別結果。









)

)







