?
??
數據倉庫工具。構建在hadoop上的數據倉庫框架,可以把hadoop下的原始結構化數據變成Hive中的表。(主要解決ad-hoc query,即時查詢的問題)
支持一種與SQL幾乎完全相同的語言HQL。除了不支持更新,索引和事務,幾乎SQL其他的特性都支持。
可以看成是SQL到Map-reduce的映射器
提供shell,JDBC/ODBC,Thrift,Web等接口

?
HIVE組件與體系結構
用戶接口:shell,thrift,web
Thrift 服務器
元數據庫 (Derby是hive內嵌db 用于本地模式,一般都用mysql,所謂metadata,因為Hive本身不存儲數據,完全依賴于HDFS和MapReduce,Hive可以將結構化的數據文件映射為一張數據庫表,Hive中表純邏輯,這些有關邏輯的表的定義數據就是元數據)
HIVE QL(compiler,optimizer,executor)
Hadoop?

?
?
?
?

HIVE數據放在哪里?
在hdfs下的warehouse下面,一個表對應一個子目錄
桶與reducer
本地的/tmp目錄存放日志和執行計劃
?
HIVE安裝:
內嵌模式:元數據保持在內嵌的Derby,只允許一個會話連接(hive服務和metastore服務運行在同一個進程中,derby服務也運行在該進程中)
本地獨立模式:hive服務和metastore服務運行在同一個進程中,mysql是單獨的進程,可以在同一臺機器上,也可以在遠程機器上。
該模式只需將hive-site.xml中的ConnectionURL指向mysql,并配置好驅動名、數據庫連接賬號即可
遠程模式:hive服務和metastore在不同的進程內,可能是不同的機器。
該模式需要將hive.metastore.local設置為false,并將hive.metastore.uris設置為metastore服務器URI,如有多個metastore服務器,URI之間用逗號分隔。metastore服務器URI的格式為thrift://host port
<property>
<name>hive.metastore.uris</name>
<value>thrift://127.0.0.1:9083</value>
</property>
?
Hive2.1.1:
(1)內嵌模式
cp apache-hive-2.1.1-bin.tar.gz /home/hdp/ cd /home/hdp/ tar -zxvf apache-hive-2.1.1-bin.tar.gz
root修改/etc/profile
export HIVE_HOME=/home/hdp/hive211 export PATH=$PATH:$HIVE_HOME/bin export CLASSPATH=$CLASSPATH:$HIVE_HOME/lib:$HIVE_HOME/conf
export HIVE_AUX_JARS_PATH=/home/hdp/hive211/lib
切換hdp修改/home/hdp/hive211/conf 下的
hive-env.sh
cp hive-env.sh.template hive-env.sh vi hive-env.shHADOOP_HOME=/home/hdp/hadoop
export HIVE_CONF_DIR=/home/hdp/hive211/conf
hive-site.xml
cp hive-default.xml.template hive-site.xml vi hive-site.xml
?
#該參數指定了 Hive 的數據存儲目錄,默認位置在 HDFS 上面的 /user/hive/warehouse 路#徑下<property><name>hive.metastore.warehouse.dir</name><value>/user/hive/warehouse</value><description>location of default database for the warehouse</description></property>#該參數指定了 Hive 的數據臨時文件目錄,默認位置為 HDFS 上面的 /tmp/hive 路徑下<property><name>hive.exec.scratchdir</name><value>/tmp/hive</value><description>HDFS root scratch dir for Hive jobs which gets created with write all (733) permission. For each connecting user, an HDFS scratch dir: ${hive.exec.scratchdir}/<username> is created, with ${hive.scratch.dir.permission}.</description></property><property> <name>hive.querylog.location</name> <value>/home/hdp/hive211/iotmp</value> <description>Location of Hive run time structured log file</description> </property><property> <name>hive.exec.local.scratchdir</name> <value>/home/hdp/hive211/iotmp</value> <description>Local scratch space for Hive jobs</description> </property><property> <name>hive.downloaded.resources.dir</name> <value>/home/hdp/hive211/iotmp</value> <description>Temporary local directory for added resources in the remote file system.</description> </property><property><name>hive.server2.logging.operation.log.location</name><value>/home/hdp/hive211/iotmp/operation_logs</value><description>Top level directory where operation logs are stored if logging functionality is enabled</description> </property><property><name>javax.jdo.option.ConnectionURL</name><value>jdbc:derby:;databaseName=metastore_db;create=true</value><description>JDBC connect string for a JDBC metastore.To use SSL to encrypt/authenticate the connection, provide database-specific SSL flag in the connection URL.For example, jdbc:postgresql://myhost/db?ssl=true for postgres database.</description> </property><property><name>javax.jdo.option.ConnectionDriverName</name><value>org.apache.derby.jdbc.EmbeddedDriver</value><description>Driver class name for a JDBC metastore</description> </property><property><name>javax.jdo.option.ConnectionUserName</name><value>APP</value><description>Username to use against metastore database</description> </property><property><name>javax.jdo.option.ConnectionPassword</name><value>mine</value><description>password to use against metastore database</description> </property><property><name>hive.exec.reducers.bytes.per.reducer</name><value>256000000</value><description>size per reducer.The default is 256Mb, i.e if the input size is 1G, it will use 4 reducers.</description> </property><property><name>hive.exec.reducers.max</name><value>1009</value><description>max number of reducers will be used. If the one specified in the configuration parameter mapred.reduce.tasks isnegative, Hive will use this one as the max number of reducers when automatically determine number of reducers.</description> </property>
?
根據上面的參數創造必要的文件夾
[hdp@hdp265m conf]$ hadoop fs -mkdir -p /user/hive/warehouse [hdp@hdp265m conf]$ hadoop fs -mkdir -p /tmp/hive [hdp@hdp265m conf]$ hadoop fs -chmod 777 /tmp/hive [hdp@hdp265m conf]$ hadoop fs -chmod 777 /user/hive/warehouse [hdp@hdp265m conf]$ hadoop fs ls / [hdp@hdp265m hive211]$ pwd /home/hdp/hive211 [hdp@hdp265m hive211]$ mkdir iotmp [hdp@hdp265m hive211]$ chmod 777 iotmp
把hive-site.xml?中所有包含?${system:java.io.tmpdir}替換成/home/hdp/hive211/iotmp
用vi打開編輯全局替換命令 先按Esc鍵 ?再同時按shift加: 把以下替換命令粘貼按回車即可全局替換
%s#${system:java.io.tmpdir}#/home/hdp/hive211/iotmp#g 運行hive
./bin/hive
hive <parameters> --service serviceName <serviceparameters>啟動特定的服務
[hadoop@hadoop~]$ hive --service help Usage ./hive<parameters> --service serviceName <service parameters> Service List: beelinecli help hiveserver2 hiveserver hwi jar lineage metastore metatool orcfiledumprcfilecat schemaTool version Parametersparsed: --auxpath : Auxillary jars --config : Hive configuration directory --service : Starts specificservice/component. cli is default Parameters used: HADOOP_HOME or HADOOP_PREFIX : Hadoop installdirectory HIVE_OPT : Hive options For help on aparticular service: ./hive --service serviceName --help Debug help: ./hive --debug --help
?
?
?
報錯
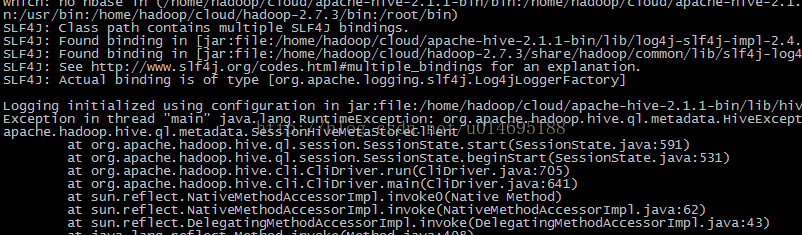
解決辦法:./bin/schematool -initSchema -dbType derby
報錯
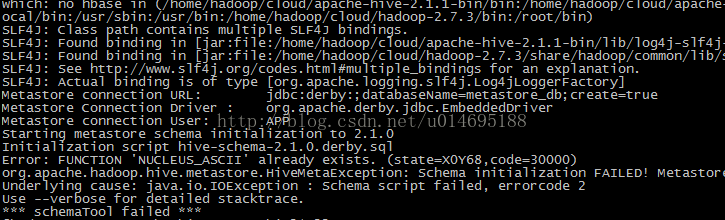
解決方法:刪除
/home/hdp/hive211/metastore_db
目錄下 rm -rf metastore_db/ 在初始化:./bin/schematool -initSchema -dbType derby
重新運行
./bin/hive
Logging initialized using configuration in jar:file:/home/hdp/hive211/lib/hive-common-2.1.1.jar!/hive-log4j2.properties Async: true Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. tez, spark) or using Hive 1.X releases. hive>
?
HIVE遠程模式
在hdp265dnsnfs上安裝mysql
編譯hive-site.html
?
<configuration> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://192.168.56.108:3306/hive?createDatabaseIfNotExist=true</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>111111</value> </property> <property> <name>hive.metastore.schema.verification</name> <value>false</value> <description> Enforce metastore schema version consistency. True: Verify that version information stored in metastore matches with one from Hive jars. Also disable automatic schema migration attempt. Users are required to manully migrate schema after Hive upgrade which ensures proper metastore schema migration. (Default) False: Warn if the version information stored in metastore doesn't match with one from in Hive jars. </description> </property> </configuration>
報錯:Caused by: MetaException(message:Version information not found in metastore. )
解決:hive-site.xml加入
<name>hive.metastore.schema.verification</name> <value>false</value>
報錯:缺少mysql jar包
解決:將其(如mysql-connector-java-5.1.42-bin.jar)拷貝到$HIVE_HOME/lib下即可
報錯:
Exception in thread "main" java.lang.RuntimeException: Hive metastore database is not initialized. Please use schematool (e.g. ./schematool -initSchema -dbType ...) to create the schema. If needed, don't forget to include the option to auto-create the underlying database in your JDBC connection string (e.g. ?createDatabaseIfNotExist=true for mysql) 解決:
#數據庫的初始化。 bin/schematool -initSchema -dbType mysql 啟動:
bin/hive
啟動后mysql 多了hive 數據庫
?
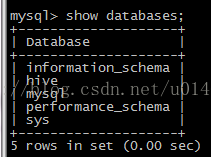
?
測試
?
創建數據庫

創建測試表
?
use db_hive_test;
create table student(id int,name string) row format delimited fields terminated by '\t';


?
加載數據到表中
?
新建student.txt 文件寫入數據(id,name 按tab鍵分隔)
vi student.txt
?
- 1001????zhangsan??
- 1002????lisi??
- 1003????wangwu??
- 1004????zhaoli??
load data local inpath '/home/hadoop/student.txt' into table? db_hive_test.student
?
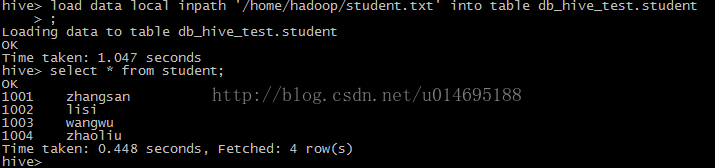
?
查詢表信息
select * from student;
?
?
查看表的詳細信息
desc formatted student;
?
通過Mysql查看創建的表

?
查看hive的函數?
show functions;
查看函數詳細信息?
desc function sum;?
desc function extended
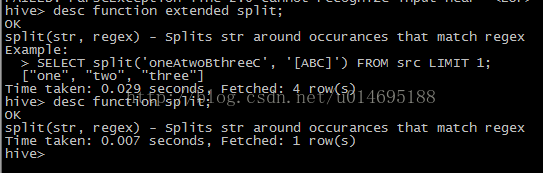
?
?
?
?
?
?
?
?
Hive 快速入門
https://cwiki.apache.org/confluence/display/Hive/GettingStarted
Hive語言手冊
https://cwiki.apache.org/confluence/display/Hive/LanguageManual
Hive指南
https://cwiki.apache.org/confluence/display/Hive/Tutorial
?




)













)
