AI 前線導讀:隨著互聯網行業的井噴式發展,數據規模呈現爆炸式增長。大數據中蘊含了巨大的價值,但同時也來了很 “信息過載” 的問題。推薦系統作為一個廣泛應用的信息過濾系統,在很多領域取得了巨大的成功。在電子商務上(Amazon,eBay,阿里巴巴),推薦系統為用戶提供個性化產品,發掘用戶潛在需求。那些電商的 “猜你喜歡” 其實就是推薦系統的應用。簡單的說,推薦系統的目標是根據用戶的偏好,為其找到并推薦可能感興趣的項目。
當今機器學習中最有價值的應用之一就是推薦系統。Amazon 將其 35% 的收入歸功于其推薦系統。
譯注:關于 35% 這一數據詳見《The Amazon Recommendations Secret to Selling More Online》(http://rejoiner.com/resources/amazon-recommendations-secret-selling-online/)
評估是研究和開發任何推薦系統的重要組成部分。根據你的業務和可用數據,有很多方法可以評估推薦系統。在本文中,我們會嘗試一些評估方法。
評級預測
在我上一篇文章中《Building and Testing Recommender Systems With Surprise, Step-By-Step 》(https://towardsdatascience.com/building-and-testing-recommender-systems-with-surprise-step-by-step-d4ba702ef80b):使用 Surprise 構建和測試推薦系統,Surprise 以各種機器學習算法為中心來預測用戶對商品條目的評級(即評級預測)。它要求用戶提供明確的反饋,比如讓用戶在購買圖書后對其進行 0~10 星的評級。然后我們用這些數據來建立用戶興趣的檔案。問題是,不是每個人都愿意留下評級,因此數據往往是稀疏的,就像我們之前看到的 Book-Crossing 數據集一樣:
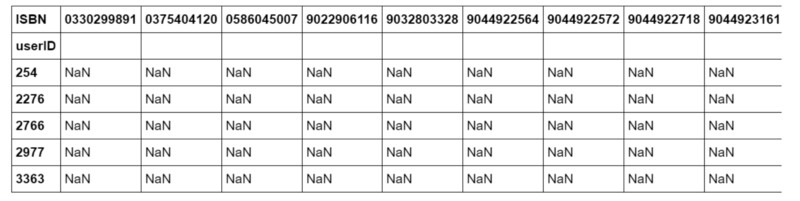
譯注:Book-Crossing 數據集可見 http://www2.informatik.uni-freiburg.de/~cziegler/BX/
大多數推薦系統是這樣試圖預測的:如果用戶對相應的圖書進行評級的話,他們會在里面放入什么內容。如果 “NaN” 太多,那么推薦系統就沒有足夠的數據來理解用戶究竟喜歡什么。
但是,如果你能說服用戶給你評級,那么明確的評級是很好的。因此,如果你擁有大量的數據和用戶評級,那么評估指標應該為 RMSE 或 MAE。讓我們展示一個帶有 Surprise 庫的 Movielens 數據集示例。
movies = pd.read_csv('movielens_data/movies.csv')ratings = pd.read_csv('movielens_data/ratings.csv')df = pd.merge(movies, ratings, on='movieId', how='inner')reader = Reader(rating_scale=(0.5, 5))data = Dataset.load_from_df(df[['userId', 'title', 'rating']], reader)trainSet, testSet = train_test_split(data, test_size=.25, random_state=0)algo = SVD(random_state=0)algo.fit(trainSet)predictions = algo.test(testSet)def MAE(predictions): return accuracy.mae(predictions, verbose=False)def RMSE(predictions): return accuracy.rmse(predictions, verbose=False) print(\u0026quot;RMSE: \u0026quot;, RMSE(predictions))print(\u0026quot;MAE: \u0026quot;, MAE(predictions))
Top-N
從網上購物網站到視頻門戶網站,Top-N 推薦系統的身影無處不在。它們為用戶提供他們可能感興趣的 N 個項目的排名列表,以鼓勵用戶瀏覽、下單購買。
譯注:Top-N 推薦系統的介紹可觀看 YouTube 視頻:https://www.youtube.com/watch?v=EeXBdQYs0CQ
Amazon 的推薦系統之一就是 “Top-N” 系統,它可以為個人提供頂級結果列表:
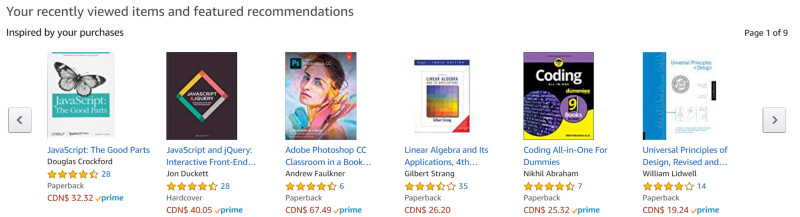
Amazon 的 “Top-N” 推薦包括 9 頁,第一頁有 6 項。一個好的推薦系統應該能夠識別某個用戶感興趣的一組 N 個條目。因為我很少在 Amazon 上買書,因此我的 “Top-N” 就差得很遠。換言之,我可能只會點擊或閱讀我的 “Top-N” 列表中的某本書。
下面的腳本為測試集中的每個用戶生成了前 10 條推薦。
def GetTopN(predictions, n=10, minimumRating=4.0): topN = defaultdict(list) for userID, movieID, actualRating, estimatedRating, _ in predictions: if (estimatedRating \u0026gt;= minimumRating): topN[int(userID)].append((int(movieID), estimatedRating)) for userID, ratings in topN.items(): ratings.sort(key=lambda x: x[1], reverse=True) topN[int(userID)] = ratings[:n] return topN LOOCV = LeaveOneOut(n_splits=1, random_state=1)for trainSet, testSet in LOOCV.split(data): # Train model without left-out ratings algo.fit(trainSet) # Predicts ratings for left-out ratings only leftOutPredictions = algo.test(testSet) # Build predictions for all ratings not in the training set bigTestSet = trainSet.build_anti_testset() allPredictions = algo.test(bigTestSet) # Compute top 10 recs for each user topNPredicted = GetTopN(allPredictions, n=10)下面是我們預測的 userId 2 和 userId 3 的前 10 項。

命中率
讓我們看看生成的前 10 項推薦究竟有多好。為評估前 10 項,我們使用命中率這一指標,也就是說,如果用戶對我們推薦的前 10 項中的一個進行了評級,那么我們就認為這是一個 “命中”。
計算單個用戶命中率的過程如下:
在訓練數據中查找此用戶歷史記錄中的所有項。
有意刪除其中一項條目(使用留一法,一種交叉驗證方法)。
使用所有其他項目為推薦系統提供信息,并要求提供前 10 項推薦。
如果刪除的條目出現在前 10 項推薦中,那么它就是命中的。如果沒有,那就不算命中。
def HitRate(topNPredicted, leftOutPredictions): hits = 0 total = 0 # For each left-out rating for leftOut in leftOutPredictions: userID = leftOut[0] leftOutMovieID = leftOut[1] # Is it in the predicted top 10 for this user? hit = False for movieID, predictedRating in topNPredicted[int(userID)]: if (int(leftOutMovieID) == int(movieID)): hit = True break if (hit) : hits += 1 total += 1 # Compute overall precision return hits/totalprint(\u0026quot;\Hit Rate: \u0026quot;, HitRate(topNPredicted, leftOutPredictions))
系統的總命中率是命中數除以測試用戶數。它衡量的是我們推薦刪除評級的頻率,越高越好。
如果命中率非常低的話,這只是意味著我們沒有足夠的數據可供使用。就像 Amazon 對我來說,命中率就非常低,因為它沒有足夠的我購買圖書的數據。
基于評級值的命中率
我們還可以通過預測的評級值來細分命中率。在理想情況下,我們希望預測用戶喜歡的電影,因此我們關心的是高評級值而不是低評級值。
def RatingHitRate(topNPredicted, leftOutPredictions): hits = defaultdict(float) total = defaultdict(float) # For each left-out rating for userID, leftOutMovieID, actualRating, estimatedRating, _ in leftOutPredictions: # Is it in the predicted top N for this user? hit = False for movieID, predictedRating in topNPredicted[int(userID)]: if (int(leftOutMovieID) == movieID): hit = True break if (hit) : hits[actualRating] += 1 total[actualRating] += 1 # Compute overall precision for rating in sorted(hits.keys()): print(rating, hits[rating] / total[rating])print(\u0026quot;Hit Rate by Rating value: \u0026quot;)RatingHitRate(topNPredicted, leftOutPredictions)
我們的命中率細分正是我們所期望的,評級值為 5 的命中率遠高于 4 或 3。越高越好。
累積命中率
因為我們關心更高的評級,我們可以忽略低于 4 的預測評級,來計算 \u0026gt; = 4 的評級命中率。
def CumulativeHitRate(topNPredicted, leftOutPredictions, ratingCutoff=0): hits = 0 total = 0 # For each left-out rating for userID, leftOutMovieID, actualRating, estimatedRating, _ in leftOutPredictions: # Only look at ability to recommend things the users actually liked... if (actualRating \u0026gt;= ratingCutoff): # Is it in the predicted top 10 for this user? hit = False for movieID, predictedRating in topNPredicted[int(userID)]: if (int(leftOutMovieID) == movieID): hit = True break if (hit) : hits += 1 total += 1 # Compute overall precision return hits/totalprint(\u0026quot;Cumulative Hit Rate (rating \u0026gt;= 4): \u0026quot;, CumulativeHitRate(topNPredicted, leftOutPredictions, 4.0))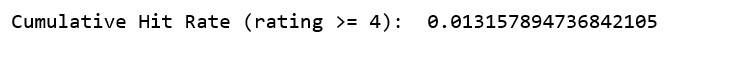
越高越好。
平均對等命中排名(Average Reciprocal Hit Ranking,ARHR)
常用于 Top-N 推薦系統排名評估的指標,只考慮第一個相關結果出現的地方。我們在推薦用戶排名靠前而不是靠后的產品獲得了更多的好評。越高越好。
def AverageReciprocalHitRank(topNPredicted, leftOutPredictions): summation = 0 total = 0 # For each left-out rating for userID, leftOutMovieID, actualRating, estimatedRating, _ in leftOutPredictions: # Is it in the predicted top N for this user? hitRank = 0 rank = 0 for movieID, predictedRating in topNPredicted[int(userID)]: rank = rank + 1 if (int(leftOutMovieID) == movieID): hitRank = rank break if (hitRank \u0026gt; 0) : summation += 1.0 / hitRank total += 1 return summation / totalprint(\u0026quot;Average Reciprocal Hit Rank: \u0026quot;, AverageReciprocalHitRank(topNPredicted, leftOutPredictions))view rawAverageReciprocalHitRank.py hosted with ? by GitHub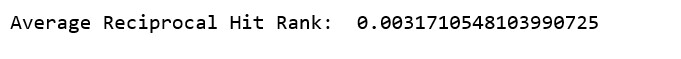
你的第一個真實推薦系統可能質量很低,哪怕是成熟系統,用于新用戶的表現也是一樣。但是,這仍然比沒有推薦系統要好多得多。推薦系統的目的之一,就是在推薦系統中了解用戶 / 新用戶的偏好,這樣他們就可以開始從系統中接收準確的個性化推薦。
然而,如果你剛剛起步的話,那么你的網站就是全新的,這時候推薦系統并不能為任何人提供個性化的推薦,因為這時候并沒有任何人的評價。然后,這就變成了一個系統引導問題。
譯注:有關系統引導問題可參閱:《Learning Preferences of New Users in RecommenderSystems: An Information Theoretic Approach》(https://www.kdd.org/exploration_files/WebKDD08-Al-Rashid.pdf)
本文的Jupyter Notebook 可以在 Github 上找到:https://github.com/susanli2016/Machine-Learning-with-Python/blob/master/Movielens Recommender Metrics.ipynb。
參考文獻:Building Recommender Systems with Machine Learning and AI(《使用機器學習和人工智能構建推薦系統》https://learning.oreilly.com/videos/building-recommender-systems/9781789803273)
原文鏈接:https://towardsdatascience.com/evaluating-a-real-life-recommender-system-error-based-and-ranking-based-84708e3285b






)



)








用restTemplate消費服務)