Linemod 代碼筆記
2019年03月11日 16:18:30 haithink 閱讀數:197
最近了解到 Linemod 這個模板匹配算法,印象不錯
準備仔細學習一下,先做點代碼筆記,免得后面不好回顧
目前的筆記基本上把 核心流程都分析得比較清楚了,除了一些閾值的選取
opencv 的contrib 模塊有這個算法的實現
我看的代碼來自這里
https://github.com/meiqua/shape_based_matching
先大概記錄下 代碼思路:
分兩個階段, train 和 test
Train
Train 中 , shapeInfo_producer 負責用來對 模板進行 各種旋轉和尺度縮放,
shapes.src_of 可以根據旋轉和尺度 生成變換后的 模板
對每一個模板 執行 detector.addTemplate 操作,
最后調用 shapes.save_infos 和 detector.writeClasses 這兩個保存訓練 結果。保存的信息用于 后續的匹配中。
首先構造
line2Dup::Detector detector(20, { 4, 8 });
第一個參數為 特征點個數 , 第二個參數是一個 vector, 每個元素代表每一層的T
構建 this->modality 對象
shape_based_matching::shapeInfo_producer shapes(padded_img, padded_mask);
兩個入參都是 圖像,第一個是用 輸入圖像構建,填充像素為0, 第二個用輸入圖像大小的大小構建掩碼圖像,掩碼為1, 填充像素為0
然后填充shapes.scale_range、 shapes.scale_step、 shapes.angle_range 、shapes.angle_step
這四個是對模板圖像進行 尺度縮放 和 旋轉的 量
shapes.produce_infos();
主要是用 尺度范圍 和 旋轉范圍 的組合 構建 std::vector infos
然后 就是 遍歷 shapes.infos
執行
detector.addTemplate(shapes.src_of(info), class_id, shapes.mask_of(info));
shapes.src_of(info) 產生變換后的圖像
class_id 是一個固定的字符串
shapes.mask_of(info) 返回 shapes.src_of(info) 產生變換后的圖像是否大于0的 掩碼圖像
addTemplate 是 核心函數,主要作用為 提取模板圖像的特征點,即梯度較強的點,得到 這些點的坐標和梯度方向值。
接著調用兩個函數
- shapes.save_infos 保存 的信息是 每張圖片是 原始圖像經過哪種旋轉和縮放得到的
- detector.writeClasses 則 保存 每個模板 的信息,包括cropTemplates(tp) 后的高寬和坐標、 特征點坐標信息,特征點的label 就是梯度方向
=============================================================================
Detector::addTemplate
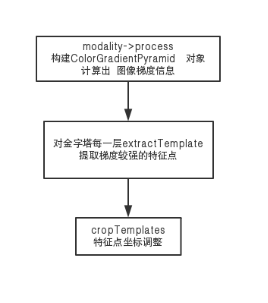
1 modality->process(source, object_mask)
這個是 直接構造一個 ColorGradientPyramid 對象,返回其指針
ColorGradientPyramid 構造函數中 update(); ,內部是
quantizedOrientations(src, magnitude, angle, weak_threshold);
先做 高斯模糊, 然后 在水平和垂直方向 調用 Sobel,
調用 phase 計算梯度方向,
調用 hysteresisGradient, 主要輸出就是 quantized_angle
過程為: 先把 連續的梯度方向 劃分為16個區間, 然后量化為8個方向
quant_r[c] &= 7; 這個代碼還沒看明白,這 相當于把一個整數 對8 求模
這么做沒問題應該是因為 認為 180度和190度之間的方向 和0度到10度之間的 方向是一個方向。
然后就是 對梯度幅值 超過一定閾值的 像素點 的 3*3 鄰域 求 梯度直方圖
投票數 超過 閾值的 方向 作為最終的 量化方向
至此, modality->process 完成
返回 一個 Ptr qp
然后 開始遍歷金字塔每一層, 如果不是最底層, 那么 qp 降采樣,并且 做梯度量化操作, 即調用上面的 update()
然后qp->extractTemplate(tp[l])
這一步是 提取第 L 層特征點, 保存在 tp[l]中。 細節參考后文
說明: tp是個vector, 每個 元素都是一個模板,對應金字塔某一層提取出來的特征點
每一層都遍歷完后, cropTemplates(tp)
這個函數 先 遍歷每一個 模板, 找出特征點最大最小坐標,注意,高層次的金字塔圖像的坐標會進行放大(根據層次)
得到 4個最小、最大坐標。 注意: 是所有層共用信息
然后再一次遍歷每個模板, 調整 templ.width ,templ.height ,templ.tl_x,templ.tl_y
然后用 templ.tl_x,templ.tl_y 修正了特征點坐標,
TODO: 這就 有點麻煩了, 修正后的 坐標肯定和 原始圖像 對應不上了啊!
返回 Rect(min_x, min_y, max_x - min_x, max_y - min_y)
但 外部并未接收 這個返回值
addTemplate 的最后 template_pyramids.push_back(tp);
ColorGradientPyramid::extractTemplate(Template &templ)
函數輸出應該是 templ.features, 即提取出 特征點
先對 mask 進行 腐蝕,
Magnitude 是 之前 quantizedOrientations 中計算出的梯度幅值(梯度平方和)
對 Magnitude 搞一個 遍歷,
如果對每個像素,如果 magnitude_valid 值 大于0
如果其鄰域內 有像素的梯度幅值超過它,
那么 is_max 為 false, 如果遍歷完后 , is_max 為true, 那么 所有 鄰域像素對應 magnitude_valid 值 置為0
通過上述檢驗的點 , 如果 幅值超過閾值, 且 方向不為 0, 進入 candidates
(注意 opencv在這里的實現方法, 先設置了一個 score = 0, 如果沒通過上述檢驗, 該值依然為0, 這種實現方法好嗎?)
遍歷完后,如果 candidates 個數低于閾值, 返回 false, 此次 抽取失敗。。。
對 candidates 按照 score 進行一次穩定排序
selectScatteredFeatures 最后 從 candidates 中 選取一些 散得 比較開的點, 這里while 循環寫得還比較有技巧, 如果遍歷完一輪, 數量不夠,那么 降低 距離閾值, 再選!
和 orb-slam或者說opencv 里面 ORBextractor 提取特征點 那個 四叉樹的方法誰優誰劣?
選取的特征點保存 在 templ.features 中
Test
先讀取 train 階段保存的兩個信息文件
detector.readClasses(ids, prefix + “myCase/%s_templ.yaml”);
讀取 每個模板 的信息,包括cropTemplates(tp) 后的高寬和坐標、 特征點坐標信息,特征點的label 就是梯度方向。
構建出: class_templates
shape_based_matching::shapeInfo_producer::load_infos
每張圖片是 原始圖像經過哪種旋轉和縮放得到的
對測試圖像 進行一下調整, 使得高寬都是 16 的倍數
auto matches = detector.match(img, 90, ids);
90 是閾值, ids 是 訓練時 指定的id字符串 test
然后 modality->process(source, mask),
這個調用在前面已經介紹過了,會 構造一個 ColorGradientPyramid 對象,對source圖像計算量化后的梯度信息
然后遍歷 金字塔, construct response map
先不看 具體的函數調用實現過層, 從函數名字 和 注釋來看, 這就是 論文當中第三節講的東西, 包括 方向擴散spread、 梯度響應計算computeResponseMaps、 線性化存儲linearize。 最終存在在 LinearMemoryPyramid 結構里面。
遍歷class_ids, 從 class_templates獲取 對應 std::vector
matchClass(lm_pyramid, sizes, threshold, matches, it->first, it->second);
這個函數完成整個匹配過程
=============================================================================
Detector::matchClass
遍歷template_pyramids, 提取出 每個 Template,
調用 similarity, 計算相似性, similarity中, 核心調用是 accessLinearMemory,
這里面第一行代碼
const Mat &memory_grid = linear_memories[f.label];
很關鍵,這是根據模板中特征點 來 定位 response map 相應的數據
定位到以后,然后 就是 SIMD 指令 來 累加數據了!
static void spread(const Mat &src, Mat &dst, int T)
這個地方實現的是 論文3.3 節的所謂 梯度方向展開
所要實現的功能很好理解, 即把每個像素及其鄰域的離散化的梯度方向進行 或運算。
OpenCV 這里再一次展現了實現技巧, 最直觀的方法是 每次遍歷一個像素時,取出其所有鄰域內的像素的梯度方向值,然后做一個或運算, 這樣做 內存訪問性能較低, 因為圖像的下一行和上一行 距離較大, 很可能緩存命中失敗。
OpenCV 的做法是: 每次遍歷時, 只做整個鄰域內某個特定位置的像素梯度方向值 的 或運算,這個地方說的鄰域包含像素自身,即鄰域中心。 所以總共循環 T*T次。 T 為鄰域直徑。
這樣做, 內存訪問友好,并且方便使用 SSE指令進行優化, 因為連續參與運算的數據在內存中是連續的!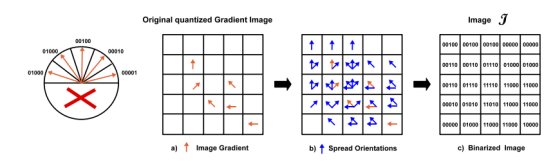
static void computeResponseMaps
(const Mat &src, std::vector &response_maps)
實現論文3.4節 響應圖的計算
這個地方 把論文中的相似度 也給離散化了。
并且事先計算了 某個方向 和 某組方向的余弦值的最大值,并且離散化, (或者稱為根據余弦值 實行打分制) 存儲到一個數組SIMILARITY_LUT 中,即查找表。 這個查找表中針對某個方向的值有32個元素, 總共8個方向, 所以有 256個元素。 32個元素中 , 又分為兩組, 前16個是8個方向中前4個方向的各種組合 與 當前32個元素針對的方向 的余弦值的最大值對應的得分。
這個數組, 上交這個學生 對原來的值 進行了修改: 1,2–>0 3–>1
為什么這么改?
https://zhuanlan.zhihu.com/p/35683990
這篇文章給出了 修改的解釋
論文3.4 節 也給出了 這個查找表的計算啊!
疑問待定: n0 為8的時候, 針對某個方向的查找表元素 按照論文實際上應該是有 2的8次方, 即 256種情況。 這個地方是不想搞出那么大一個數組, 所以, 把8位分拆成兩組, 每組只需16個元素, 然后再進行一次比較,拿到最終的最大值? 為啥不直接構建大小為 256*8的查找表? 這樣可以省掉一次 max的運算。
看了下 _mm_shuffle_epi8 的介紹
這個地方 index 只用低4位進行運算, 也就是只支持 4個bit作為索引值,
如果只能用這個指令,的確 只能把 8位拆分成兩組4位,再max
不知道有沒有 能直接用8位作為 所以索引的SSE指令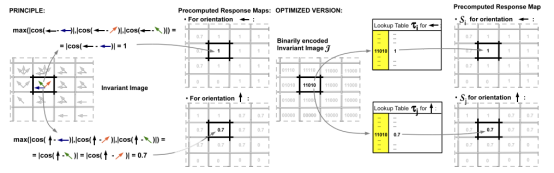
static void linearize
(const Mat &response_map, Mat &linearized, int T)
這個是改變存儲方式,先行后列, 間隔T 讀取,然后寫入。沒有比較復雜和特殊的處理。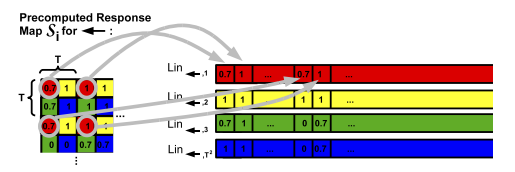
similarity_64
這個函數計算 模板和 輸入圖像的 相似性, 即論文中的 similarity map
計算相似性的時候, 并不是 把 模板上的每個像素都和 輸入圖像上對應的像素 一一對應,然后進行 某種計算, 這和 NCC, SSD 這些方法的做法不一樣!一開始受這些方法先入為主的影響,導致論文里的Fig 7 以及代碼中的操作
實際上, 只比較模板上提取的特征點, 以及 模板 覆蓋在 輸入圖像上某個位置時, 這些模板特征點對應到 輸入圖像上的像素點 之間的梯度差異。
意識到這點以后,就比較好理解代碼了。 因為模板需要在輸入圖像上進行 滑動,所以產生了 similarity map。 每次滑動,模板和輸入圖像產生一個 相似度。 模板在 水平和垂直方向進行滑動, 所以 產生一個 二維的相似度矩陣。這個矩陣的寬 自然就是 輸入圖像的寬減去模板的寬, 也就是代碼中的span_x。 高的情況類似。
代碼當中用 template_positions 表示 模板的當前滑動位置。
計算similarity map最直觀的方法是:對每個模板位置, 找出所有特征點在輸入圖像上對應的像素, 計算所有梯度方向的相似性,累加。 然后 處理下一個模板位置。
但代碼中的做法是: 對每個特征點,計算出所有模板位置上 這個特征點 和 所有輸入圖像上對應點的 梯度方向相似性,保存到similarity map中。 然后 計算下一個特征點的相似性,累加到 similarity map中。
整個算法中 不是第一次使用這種思路了。

![BZOJ 5249: [2018多省省隊聯測]IIIDX(貪心 + 線段樹)](http://pic.xiahunao.cn/BZOJ 5249: [2018多省省隊聯測]IIIDX(貪心 + 線段樹))

















![Java基礎教程:面向對象編程[2]](http://pic.xiahunao.cn/Java基礎教程:面向對象編程[2])