1、用原生JS實現forEach
if(!Array.prototype.forEach) {Array.prototype.forEach = function(fn, context) {var context = arguments[1];if(typeof fn !== "function") {throw new TypeError(fn + "is not a function");}for(var i = 0; i < this.length; i++) {fn.call(context, this[i], i, this);}};
}
讓我們先來看forEach的語法
array.forEach(callBack(currentValue, index, arr), thisValue)
callback
為數組中每個元素執行的函數,該函數接收一至三個參數:
-
currentValue數組中正在處理的當前元素。
-
index可選數組中正在處理的當前元素的索引。
-
array可選forEach()方法正在操作的數組。
thisArg 可選
可選參數。當執行回調函數 callback 時,用作 this 的值。
手撕算法中context, this[i], i, this與currentValue, index, arr一一對應,而context則是call()函數的指向,可有可無
2、實現apply方法
Function.prototype.apply = function (context, arr) {context = context ? Object(context) : windowcontext.fn = thislet resif (!arr) {res = context.fn()} else {res = context.fn(...arr)}delete context.fnreturn res
}3、實現事件委托
事件委托的原理:
事件委托是利用事件的冒泡原理來實現的,何為事件冒泡呢?就是事件從最深的節點開始,然后逐步向上傳播事件,舉個例子:頁面上有這么一個節點樹,div>ul>li>a;比如給最里面的a加一個click點擊事件,那么這個事件就會一層一層的往外執行,執行順序a>li>ul>div,有這樣一個機制,那么我們給最外面的div加點擊事件,那么里面的ul,li,a做點擊事件的時候,都會冒泡到最外層的div上,所以都會觸發,這就是事件委托,委托它們父級代為執行事件。
實現
<ul id="ul1"><li>111</li><li>222</li><li>333</li><li>444</li>
</ul>
window.onload = function(){var oUl = document.getElementById("ul1");oUl.onclick = function(){alert(123);}
}
這里用父級ul做事件處理,當li被點擊時,由于冒泡原理,事件就會冒泡到ul上,因為ul上有點擊事件,所以事件就會觸發,當然,這里當點擊ul的時候,也是會觸發的,那么問題就來了,如果我想讓事件代理的效果跟直接給節點的事件效果一樣怎么辦,比如說只有點擊li才會觸發,不怕,我們有絕招:
Event對象提供了一個屬性叫target,可以返回事件的目標節點,我們成為事件源,也就是說,target就可以表示為當前的事件操作的dom,但是不是真正操作dom,當然,這個是有兼容性的,標準瀏覽器用ev.target,IE瀏覽器用event.srcElement,此時只是獲取了當前節點的位置,并不知道是什么節點名稱,這里我們用nodeName來獲取具體是什么標簽名,這個返回的是一個大寫的,我們需要轉成小寫再做比較(習慣問題):
window.onload = function(){var oUl = document.getElementById("ul1");oUl.onclick = function(ev){var ev = ev || window.event;var target = ev.target || ev.srcElement;if(target.nodeName.toLowerCase() == 'li'){alert(123);alert(target.innerHTML);}}
}
4、用setTimeOut實現setInterval
function myInterval(fn,time){let interval=()=>{fn()setTimeout(interval,time)}setTimeout(interval,time)}
5、用JS實現map
Array.prototype.map = function (fn) {let arr = []for (let i = 0; i < this.length; i++) {arr. push(fn(this[i], i, this))}return arr
}
6、用JS實現reduce方法
Array.prototype.myReduce = function (fn, initVal) {let res = initVal ? initVal : 0for (let i = 0; i < this.length; i++) {res = fn(res, this[i], i, this)}return res
}
7、用JS實現filter方法
Array.prototype.myFilter = function (fn) {let arr = []for (let i = 0; i < this.length; i++) {if (fn(this[i], i, this)) {arr.push(this[i])}}return arr
}
8、JS實現push
Array.prototype.myPush = function () {let args = argumentsfor (let i = 0; i < args.length; i++) {this[this.length] = args[i]}return this.length
}
9、實現pop
Array.prototype.pop = function () {if(this.length === 0) returnlet val = this[this.length - 1]this.length -= 1return val
}
10、實現unshift
Array.prototype.unshift = function () {let args = [...arguments]let len = args.lengthfor (let i = this.length - 1; i >= 0; i--) {this[i + len] = this[i]}for (let i = 0; i < len; i++) {this[i] = args[i]}return this.length
}
10、實現shift
Array.prototype.shift = function () {let removeVal = this[0]for (let i = 0; i < this.length; i++) {if (i !== this.length - 1) {this[i] = this[i + 1]}}this.length -= 1return removeVal
}
11、筆試題
var n=123
function f1(){console.log(n)
}
function f2(){var n=456f1()
}
f2()
console.log(n)//運行結果是123 123
12、筆試題
var length=100
function f1(){console.log(this.length)
}
var obj={x:10,f2:function(f1){f1()arguments[0]()}
}
obj.f2(f1,1)
13、–proto–和prototype和constructor
①__proto__和constructor屬性是對象所獨有的;② prototype屬性是函數所獨有的。但是由于JS中函數也是一種對象,所以函數也擁有__proto__和constructor屬性
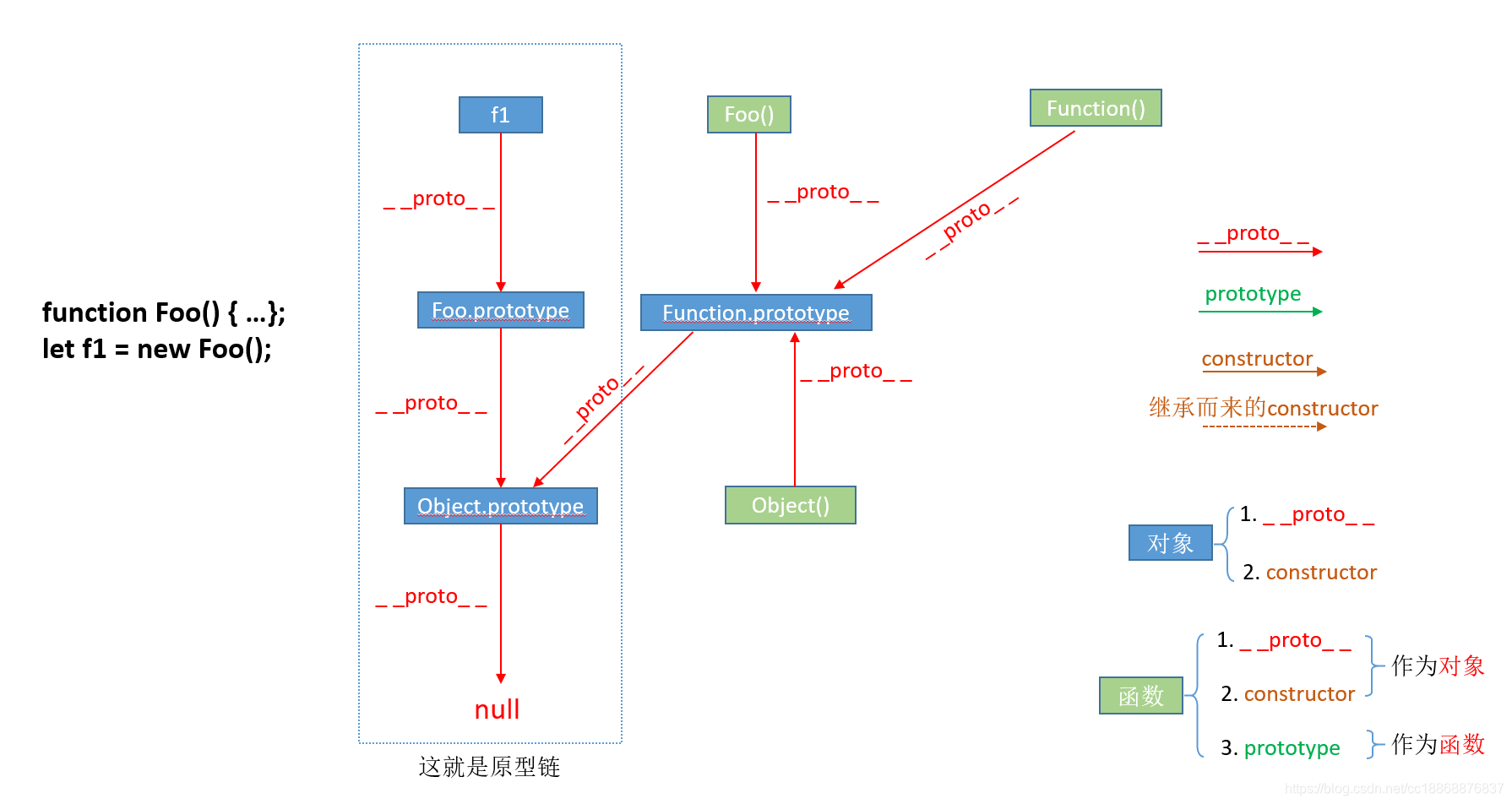



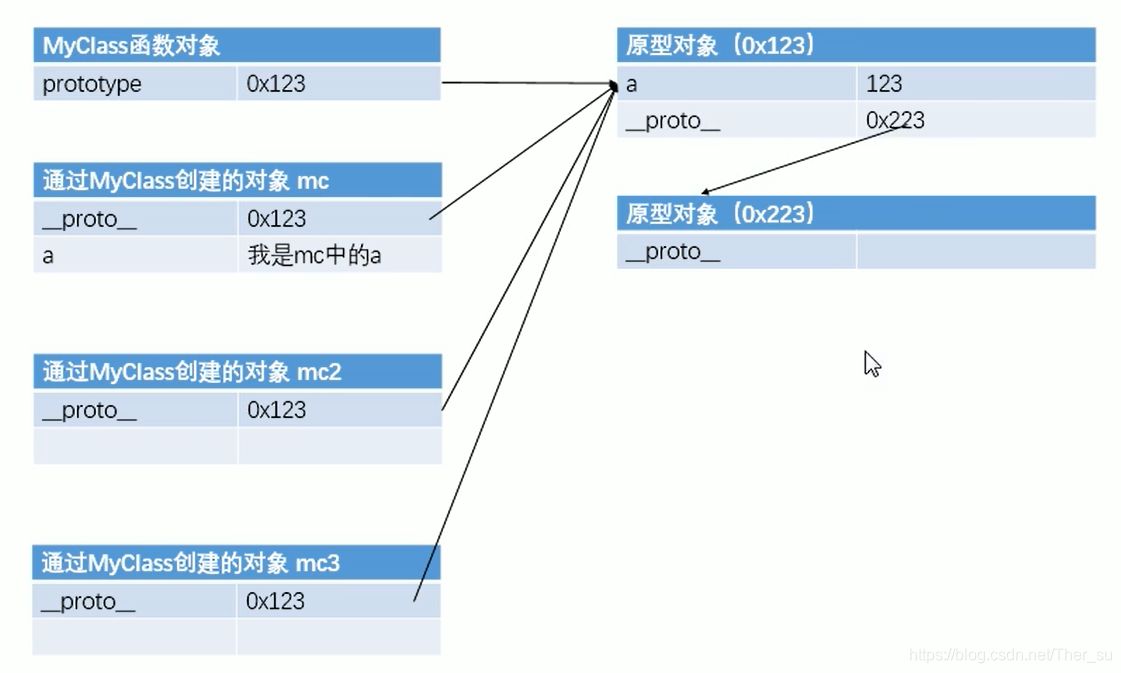
proto 屬性,它是對象所獨有的,可以看到__proto__屬性都是由一個對象指向一個對象,即指向它們的原型對象(也可以理解為父對象),那么這個屬性的作用是什么呢?它的作用就是當訪問一個對象的屬性時,如果該對象內部不存在這個屬性,那么就會去它的__proto__屬性所指向的那個對象(可以理解為父對象)里找,如果父對象也不存在這個屬性,則繼續往父對象的__proto__屬性所指向的那個對象(可以理解為爺爺對象)里找,如果還沒找到,則繼續往上找…直到原型鏈頂端null
prototype屬性,別忘了一點,就是我們前面提到要牢記的兩點中的第二點,它是函數所獨有的,它是從一個函數指向一個對象。它的含義是函數的原型對象,也就是這個函數(其實所有函數都可以作為構造函數)所創建的實例的原型對象,由此可知:f1.proto === Foo.prototype,它們兩個完全一樣。那prototype屬性的作用又是什么呢?它的作用就是包含可以由特定類型的所有實例共享的屬性和方法,也就是讓該函數所實例化的對象們都可以找到公用的屬性和方法。任何函數在創建的時候,其實會默認同時創建該函數的prototype對象。
constructor屬性也是對象才擁有的,它是從一個對象指向一個函數,含義就是指向該對象的構造函數,每個對象都有構造函數(本身擁有或繼承而來.
14、手動實現new
function myNew(constrc, ...args) {const obj = {}; // 1. 創建一個空對象obj.__proto__ = constrc.prototype; // 2. 將obj的[[prototype]]屬性指向構造函數的原型對象// 或者使用自帶方法:Object.setPrototypeOf(obj, constrc.prototype)const result = constrc.apply(obj, args); // 3.將constrc執行的上下文this綁定到obj上,并執行return result instanceof Object ? result : obj; //4. 如果構造函數返回的是對象,則使用構造函數執行的結果。否則,返回新創建的對象
}// 使用的例子:
function Person(name, age){this.name = name;this.age = age;
}
const person1 = myNew(Person, 'Tom', 20)
console.log(person1) // Person {name: "Tom", age: 20}
15、瀏覽器事件循環機制
任務隊列
所有的任務可以分為同步任務和異步任務,同步任務,顧名思義,就是立即執行的任務,同步任務一般會直接進入到主線程中執行;而異步任務,就是異步執行的任務,比如ajax網絡請求,setTimeout 定時函數等都屬于異步任務,異步任務會通過任務隊列( Event Queue )的機制來進行協調。
同步和異步任務分別進入不同的執行環境,同步的進入主線程,即主執行棧,異步的進入 Event Queue 。主線程內的任務執行完畢為空,會去 Event Queue 讀取對應的任務,推入主線程執行。 上述過程的不斷重復就是我們說的 Event Loop (事件循環)。
在事件循環中,每進行一次循環操作稱為tick,通過閱讀規范可知,每一次 tick 的任務處理模型是比較復雜的,其關鍵的步驟可以總結如下:
- 在此次 tick 中選擇最先進入隊列的任務( oldest task ),如果有則執行(一次)
- 檢查是否存在 Microtasks ,如果存在則不停地執行,直至清空Microtask Queue
- 更新 render
- 主線程重復執行上述步驟
這里相信有人會想問,什么是 microtasks ?規范中規定,task分為兩大類, 分別是 Macro Task (宏任務)和 Micro Task(微任務), 并且每個宏任務結束后, 都要清空所有的微任務,這里的 Macro Task也是我們常說的 task ,有些文章并沒有對其做區分,后面文章中所提及的task皆看做宏任務( macro task)。
(macro)task 主要包含:script( 整體代碼)、setTimeout、setInterval、I/O、UI 交互事件、setImmediate(Node.js 環境)
microtask主要包含:Promise、MutaionObserver、process.nextTick(Node.js 環境)
setTimeout/Promise 等API便是任務源,而進入任務隊列的是由他們指定的具體執行任務。來自不同任務源的任務會進入到不同的任務隊列。其中 setTimeout 與 setInterval 是同源的。
console.log('script start');setTimeout(function() {console.log('timeout1');
}, 10);new Promise(resolve => {console.log('promise1');resolve();setTimeout(() => console.log('timeout2'), 10);
}).then(function() {console.log('then1')
})console.log('script end');
首先,事件循環從宏任務 (macrotask) 隊列開始,最初始,宏任務隊列中,只有一個 scrip t(整體代碼)任務;當遇到任務源 (task source) 時,則會先分發任務到對應的任務隊列中去。所以,就和上面例子類似,首先遇到了console.log,輸出 script start; 接著往下走,遇到 setTimeout 任務源,將其分發到任務隊列中去,記為 timeout1; 接著遇到 promise,new promise 中的代碼立即執行,輸出 promise1, 然后執行 resolve ,遇到 setTimeout ,將其分發到任務隊列中去,記為 timemout2, 將其 then 分發到微任務隊列中去,記為 then1; 接著遇到 console.log 代碼,直接輸出 script end 接著檢查微任務隊列,發現有個 then1 微任務,執行,輸出then1 再檢查微任務隊列,發現已經清空,則開始檢查宏任務隊列,執行 timeout1,輸出 timeout1; 接著執行 timeout2,輸出 timeout2 至此,所有的都隊列都已清空,執行完畢。其輸出的順序依次是:script start, promise1, script end, then1, timeout1, timeout2
16、強緩存與協商緩存
一、強緩存
到底什么是強緩存?強在哪?其實強是強制的意思。當瀏覽器去請求某個文件的時候,服務端就在respone header里面對該文件做了緩存配置。緩存的時間、緩存類型都由服務端控制,具體表現為:
respone header 的cache-control,常見的設置是max-age public private no-cache no-store等
max-age表示緩存的時間是315360000秒(10年),public表示可以被瀏覽器和代理服務器緩存,代理服務器一般可用nginx來做。immutable表示該資源永遠不變,但是實際上該資源并不是永遠不變,它這么設置的意思是為了讓用戶在刷新頁面的時候不要去請求服務器!啥意思?就是說,如果你只設置了cahe-control:max-age=315360000,public 這屬于強緩存,每次用戶正常打開這個頁面,瀏覽器會判斷緩存是否過期,沒有過期就從緩存中讀取數據;但是有一些 “聰明” 的用戶會點擊瀏覽器左上角的刷新按鈕去刷新頁面,這時候就算資源沒有過期(10年沒這么快過),瀏覽器也會直接去請求服務器,這就是額外的請求消耗了,這時候就相當于是走協商緩存的流程了(下面會講到)。如果cahe-control:max-age=315360000,public再加個immutable的話,就算用戶刷新頁面,瀏覽器也不會發起請求去服務,瀏覽器會直接從本地磁盤或者內存中讀取緩存并返回200狀態,看上圖的紅色框(from memory cache)。這是2015年facebook團隊向制定 HTTP 標準的 IETF 工作組提到的建議:他們希望 HTTP 協議能給 Cache-Control 響應頭增加一個屬性字段表明該資源永不過期,瀏覽器就沒必要再為這些資源發送條件請求了。
強緩存總結
- cache-control: max-age=xxxx,public
客戶端和代理服務器都可以緩存該資源;
客戶端在xxx秒的有效期內,如果有請求該資源的需求的話就直接讀取緩存,statu code:200 ,如果用戶做了刷新操作,就向服務器發起http請求 - cache-control: max-age=xxxx,private
只讓客戶端可以緩存該資源;代理服務器不緩存
客戶端在xxx秒內直接讀取緩存,statu code:200 - cache-control: max-age=xxxx,immutable
客戶端在xxx秒的有效期內,如果有請求該資源的需求的話就直接讀取緩存,statu code:200 ,即使用戶做了刷新操作,也不向服務器發起http請求 - cache-control: no-cache
跳過設置強緩存,但是不妨礙設置協商緩存;一般如果你做了強緩存,只有在強緩存失效了才走協商緩存的,設置了no-cache就不會走強緩存了,每次請求都回詢問服務端。 - cache-control: no-store
不緩存,這個會讓客戶端、服務器都不緩存,也就沒有所謂的強緩存、協商緩存了。
二、協商緩存
上面說到的強緩存就是給資源設置個過期時間,客戶端每次請求資源時都會看是否過期;只有在過期才會去詢問服務器。所以,強緩存就是為了給客戶端自給自足用的。而當某天,客戶端請求該資源時發現其過期了,這是就會去請求服務器了,而這時候去請求服務器的這過程就可以設置協商緩存。這時候,協商緩存就是需要客戶端和服務器兩端進行交互的。
etag:每個文件有一個,改動文件了就變了,就是個文件hash,每個文件唯一,就像用webpack打包的時候,每個資源都會有這個東西,如: app.js打包后變為 app.c20abbde.js,加個唯一hash,也是為了解決緩存問題。
last-modified:文件的修改時間,精確到秒
也就是說,每次請求返回來 response header 中的 etag和 last-modified,在下次請求時在 request header 就把這兩個帶上,服務端把你帶過來的標識進行對比,然后判斷資源是否更改了,如果更改就直接返回新的資源,和更新對應的response header的標識etag、last-modified。如果資源沒有變,那就不變etag、last-modified,這時候對客戶端來說,每次請求都是要進行協商緩存了,即:
發請求–>看資源是否過期–>過期–>請求服務器–>服務器對比資源是否真的過期–>沒過期–>返回304狀態碼–>客戶端用緩存的老資源。
這就是一條完整的協商緩存的過程。
當然,當服務端發現資源真的過期的時候,會走如下流程:
發請求–>看資源是否過期–>過期–>請求服務器–>服務器對比資源是否真的過期–>過期–>返回200狀態碼–>客戶端如第一次接收該資源一樣,記下它的cache-control中的max-age、etag、last-modified等。
所以協商緩存步驟總結:
請求資源時,把用戶本地該資源的 etag 同時帶到服務端,服務端和最新資源做對比。
如果資源沒更改,返回304,瀏覽器讀取本地緩存。
如果資源有更改,返回200,返回最新的資源。
為什么要有etag?
你可能會覺得使用last-modified已經足以讓瀏覽器知道本地的緩存副本是否足夠新,為什么還需要etag呢?HTTP1.1中etag的出現(也就是說,etag是新增的,為了解決之前只有If-Modified的缺點)主要是為了解決幾個last-modified比較難解決的問題:
-
一些文件也許會周期性的更改,但是他的內容并不改變(僅僅改變的修改時間),這個時候我們并不希望客戶端認為這個文件被修改了,而重新get;
-
某些文件修改非常頻繁,比如在秒以下的時間內進行修改,(比方說1s內修改了N次),if-modified-since能檢查到的粒度是秒級的,這種修改無法判斷(或者說UNIX記錄MTIME只能精確到秒);
-
某些服務器不能精確的得到文件的最后修改時間。
17、實現深拷貝
let deepCopy = (obj) => {if (!obj instanceof Object) {throw new Error('not a object')}let newObj = Array.isArray(obj)?[]:{}for (let key in obj) {newObj[key] = obj[key] instanceof Object?deepObj(obj[key]):obj[key]}return newObj
}
18、nodeValue、value和innerHTML的區別
DOM一共有12種節點,其中常見的有:
1.文檔節點(document,一個文檔只能有一個文檔元素(在html文檔中,它是))
2.元素節點(div、p之類)
3.屬性節點(class、id、src之類)
4.文本節點(插入在div、p之類里面的內容)
5.注釋節點
nodeValue,是節點的值,其中屬性節點和文本節點是有值的,而元素節點沒有值。
innerHTML以字符串形式返回該節點的所有子節點及其值
value是獲取input標簽value的值
19、箭頭函數與普通函數的區別
1、箭頭函數全都是匿名函數
2、箭頭函數中this的指向不同
3、箭頭函數不具有arguments對象
20、MVVM
MVVM是Model-View-ViewModel的簡寫。即模型-視圖-視圖模型。【模型】指的是后端傳遞的數據。【視圖】指的是所看到的頁面。【視圖模型】mvvm模式的核心,它是連接view和model的橋梁。它有兩個方向:一是將【模型】轉化成【視圖】,即將后端傳遞的數據轉化成所看到的頁面。實現的方式是:數據綁定。二是將【視圖】轉化成【模型】,即將所看到的頁面轉化成后端的數據。實現的方式是:DOM 事件監聽。這兩個方向都實現的,我們稱之為數據的雙向綁定。總結:在MVVM的框架下視圖和模型是不能直接通信的。它們通過ViewModel來通信,ViewModel通常要實現一個observer觀察者,當數據發生變化,ViewModel能夠監聽到數據的這種變化,然后通知到對應的視圖做自動更新,而當用戶操作視圖,ViewModel也能監聽到視圖的變化,然后通知數據做改動,這實際上就實現了數據的雙向綁定。并且MVVM中的View 和 ViewModel可以互相通信。
21、js小數運算不準問題的分析
程序中的數據都會被轉換成二進制數,小數參與運算時,也會被轉成二進制,如十進制的11.1875 會被轉換成1101.0010。
小數點后 4 位用二進制數表示的數值范圍是 0.0000~0.1111,因此,這只能表示 0.5、0.25、0.125、0.0625 這四個十進制數以及小數點后面的位權組合(相加)而成的小數
大整數的精度丟失和浮點數本質上是一樣的,尾數位最大是 52 位,因此 JS 中能精準表示的最大整數是 Math.pow(2, 53),十進制即 9007199254740992。
大于 9007199254740992 的可能會丟失精度
23、Promise的三種狀態
-
pending - 進行中
-
fulfilled - 成功
-
rejected - 失敗
-
一個promise的狀態只可能從“等待”轉到“完成”態或者“拒絕”態,不能逆向轉換,同時“完成”態和“拒絕”態不能相互轉換
24、HTTP1,HTTP1.1,HTTP2
HTTP1.0和HTTP1.1的一些區別
HTTP1.0最早在網頁中使用是在1996年,那個時候只是使用一些較為簡單的網頁上和網絡請求上,而HTTP1.1則在1999年才開始廣泛應用于現在的各大瀏覽器網絡請求中,同時HTTP1.1也是當前使用最為廣泛的HTTP協議。 主要區別主要體現在:
- 緩存處理,在HTTP1.0中主要使用header里的If-Modified-Since,Expires來做為緩存判斷的標準,HTTP1.1則引入了更多的緩存控制策略例如Entity tag,If-Unmodified-Since, If-Match, If-None-Match等更多可供選擇的緩存頭來控制緩存策略。
- 帶寬優化及網絡連接的使用,HTTP1.0中,存在一些浪費帶寬的現象,例如客戶端只是需要某個對象的一部分,而服務器卻將整個對象送過來了,并且不支持斷點續傳功能,HTTP1.1則在請求頭引入了range頭域,它允許只請求資源的某個部分,即返回碼是206(Partial Content),這樣就方便了開發者自由的選擇以便于充分利用帶寬和連接。
- 錯誤通知的管理,在HTTP1.1中新增了24個錯誤狀態響應碼,如409(Conflict)表示請求的資源與資源的當前狀態發生沖突;410(Gone)表示服務器上的某個資源被永久性的刪除。
- Host頭處理,在HTTP1.0中認為每臺服務器都綁定一個唯一的IP地址,因此,請求消息中的URL并沒有傳遞主機名(hostname)。但隨著虛擬主機技術的發展,在一臺物理服務器上可以存在多個虛擬主機(Multi-homed Web Servers),并且它們共享一個IP地址。HTTP1.1的請求消息和響應消息都應支持Host頭域,且請求消息中如果沒有Host頭域會報告一個錯誤(400 Bad Request)。
- 長連接,HTTP 1.1支持長連接(PersistentConnection)和請求的流水線(Pipelining)處理,在一個TCP連接上可以傳送多個HTTP請求和響應,減少了建立和關閉連接的消耗和延遲,在HTTP1.1中默認開啟Connection: keep-alive,一定程度上彌補了HTTP1.0每次請求都要創建連接的缺點。
SPDY:HTTP1.x的優化
2012年google如一聲驚雷提出了SPDY的方案,優化了HTTP1.X的請求延遲,解決了HTTP1.X的安全性,具體如下:
- 降低延遲,針對HTTP高延遲的問題,SPDY優雅的采取了多路復用(multiplexing)。多路復用通過多個請求stream共享一個tcp連接的方式,解決了HOL blocking的問題,降低了延遲同時提高了帶寬的利用率。
- 請求優先級(request prioritization)。多路復用帶來一個新的問題是,在連接共享的基礎之上有可能會導致關鍵請求被阻塞。SPDY允許給每個request設置優先級,這樣重要的請求就會優先得到響應。比如瀏覽器加載首頁,首頁的html內容應該優先展示,之后才是各種靜態資源文件,腳本文件等加載,這樣可以保證用戶能第一時間看到網頁內容。
- **header壓縮。**前面提到HTTP1.x的header很多時候都是重復多余的。選擇合適的壓縮算法可以減小包的大小和數量。
- 基于HTTPS的加密協議傳輸,大大提高了傳輸數據的可靠性。
- 服務端推送(server push),采用了SPDY的網頁,例如我的網頁有一個sytle.css的請求,在客戶端收到sytle.css數據的同時,服務端會將sytle.js的文件推送給客戶端,當客戶端再次嘗試獲取sytle.js時就可以直接從緩存中獲取到,不用再發請求了。
HTTP2.0和HTTP1.X相比的新特性
- 新的二進制格式(Binary Format),HTTP1.x的解析是基于文本。基于文本協議的格式解析存在天然缺陷,文本的表現形式有多樣性,要做到健壯性考慮的場景必然很多,二進制則不同,只認0和1的組合。基于這種考慮HTTP2.0的協議解析決定采用二進制格式,實現方便且健壯。
- 多路復用(MultiPlexing),即連接共享,即每一個request都是是用作連接共享機制的。一個request對應一個id,這樣一個連接上可以有多個request,每個連接的request可以隨機的混雜在一起,接收方可以根據request的 id將request再歸屬到各自不同的服務端請求里面。
- header壓縮,如上文中所言,對前面提到過HTTP1.x的header帶有大量信息,而且每次都要重復發送,HTTP2.0使用encoder來減少需要傳輸的header大小,通訊雙方各自cache一份header fields表,既避免了重復header的傳輸,又減小了需要傳輸的大小。
- 服務端推送(server push),同SPDY一樣,HTTP2.0也具有server push功能。
頭部壓縮需要在支持 HTTP/2 的瀏覽器和服務端之間:
- 維護一份相同的靜態字典(Static Table),包含常見的頭部名稱,以及特別常見的頭部名稱與值的組合;
- 維護一份相同的動態字典(Dynamic Table),可以動態地添加內容;
- 支持基于靜態哈夫曼碼表的哈夫曼編碼(Huffman Coding);
靜態字典的作用有兩個:1)對于完全匹配的頭部鍵值對,例如 :method: GET,可以直接使用一個字符表示;2)對于頭部名稱可以匹配的鍵值對,例如 cookie: xxxxxxx,可以將名稱使用一個字符表示。同時,瀏覽器可以告知服務端,將 cookie: xxxxxxx 添加到動態字典中,這樣后續整個鍵值對就可以使用一個字符表示了。類似的,服務端也可以更新對方的動態字典。
20、數組扁平化的幾種方法
/*實現一:遞歸*/
function flatArray(arr){var result = [];for(var i=0; i<arr.length; i++){if(Array.isArray(arr[i])){result = result.concat(flatArray(arr[i]));}else{result.push(arr[i]);}}return result;
}
/*實現二:如果數組的元素均為數字,可以考慮使用toString()方法或者join()方法,在使用split()方法轉化為數組。*/
function flatArray2(arr){//記得最后將得到的字符串元素轉化為數字return arr.toString().split(',').map( item => +item);//return arr.join(',').split(',').map( item => +item);
}/*實現三:使用ES6新增的擴展運算符*/
/*console.log([].concat(...[1, 2, [3, 4]])); => [1, 2, 3, 4]
console.log([].concat(...[1, [2, [3, 4]]])); =>[1, 2, [3, 4]]*/
function flatArray3(arr){while(arr.some( item => Array.isArray(item) )){arr = [].concat(...arr);}return arr;/*實現四:reduce*/
function flatArray4(arr){return arr.reduce((result, item) => {return result.concat(Array.isArray(item) ? flatArray4(item) : item);}, []);//[]作為result的初始值
}
21、對稱加密和非對稱加密
對稱加密過程和解密過程使用的同一個密鑰,加密過程相當于用原文+密鑰可以傳輸出密文,同時解密過程用密文-密鑰可以推導出原文。但非對稱加密采用了兩個密鑰,一般使用公鑰進行加密,使用私鑰進行解密。
基本概念
數字證書:CA用自己的私鑰,對發送者的公鑰和一些相關信息一起加密,生成"數字證書"
數字簽名:先用Hash函數,將發送內容生成摘要,然后,使用私鑰,對這個摘要加密,生成"數字簽名"
基于公開密鑰的加密過程
比如有兩個用戶Alice和Bob,Alice想把一段明文通過雙鑰加密的技術發送給Bob,Bob有一對公鑰和私鑰,那么加密解密的過程如下:
- Bob將他的公開密鑰傳送給Alice。
- Alice用Bob的公開密鑰加密她的消息,然后傳送給Bob。
- Bob用他的私人密鑰解密Alice的消息。
基于公開密鑰的認證過程
身份認證和加密就不同了,主要用戶鑒別用戶的真偽。這里我們只要能夠鑒別一個用戶的私鑰是正確的,就可以鑒別這個用戶的真偽。
還是Alice和Bob這兩個用戶,Alice想讓Bob知道自己是真實的Alice,而不是假冒的,因此Alice只要使用公鑰密碼學對文件簽名發送給Bob,Bob使用Alice的公鑰對文件進行解密,如果可以解密成功,則證明Alice的私鑰是正確的,因而就完成了對Alice的身份鑒別。整個身份認證的過程如下:
- Alice用她的私人密鑰對文件加密,從而對文件簽名。
- Alice將簽名的文件傳送給Bob。
- Bob用Alice的公鑰解密文件,從而驗證簽名。
22、HTTP劫持和DNS劫持
HTTP劫持
HTTP劫持:你DNS解析的域名的IP地址不變。在和網站交互過程中的劫持了你的請求。在網站發給你信息前就給你返回了請求。
23、XSS和CSRF
XSS
全稱Cross Site Scripting,名為跨站腳本攻擊,黑客將惡意腳本代碼植入到頁面中從而實現盜取用戶信息等操作。
常見的攻擊情景:
1、用戶A訪問安全網站B,然后用戶C發現B網站存在XSS漏洞,此時用戶C向A發送了一封郵件,里面有包含惡意腳本的URL地址(此URL地址還是網站B的地址,只是路徑上有惡意腳本),當用戶點擊訪問時,因為網站B中cookie含有用戶的敏感信息,此時用戶C就可以利用腳本在受信任的情況下獲取用戶A的cookie信息,以及進行一些惡意操作。這種攻擊叫做反射性XSS2、假設網站B是一個博客網站,惡意用戶C在存在XSS漏洞的網站B發布了一篇文章,文章中存在一些惡意腳本,例如img標簽、script標簽等,這篇博客必然會存入數據庫中,當其他用戶訪問該文章時惡意腳本就會執行,然后進行惡意操作。這種攻擊方式叫做持久性XSS,將攜帶腳本的數據存入數據庫,之后又由后臺返回。
CSRF
全稱cross-site request forgery,名為跨站請求偽造,顧名思義就是黑客偽裝成用戶身份來執行一些非用戶自愿的惡意以及非法操作
常見攻擊情景:
用戶A經常訪問博客網站B,用戶C發現網站B存在CSRF漏洞,想盡了各種辦法勾引用戶A訪問了C寫好的危險網站D,而此時用戶A的cookie信息還沒有失效,危險網站D中有向網站B求請求的非法操作,這樣用戶在不知情的情況下就被操控了。
防范
(1)驗證 HTTP Referer 字段
(2)在請求地址中添加 token 并驗證
24、駝峰命名和下劃線互換
// 下劃線轉換駝峰
function toHump(name) {return name.replace(/\_(\w)/g, function(all, letter){return letter.toUpperCase();});
}
// 駝峰轉換下劃線
function toLine(name) {return name.replace(/([A-Z])/g,"_$1").toLowerCase();
}
25、animation 和 transition 的區別
區別:
1、transition 是過渡,是樣式值的變化的過程,只有開始和結束;animation 其實也叫關鍵幀,通過和 keyframe 結合可以設置中間幀的一個狀態;
2、animation 配合 @keyframe 可以不觸發時間就觸發這個過程,而 transition 需要通過 hover 或者 js 事件來配合觸發;
3、animation 可以設置很多的屬性,比如循環次數,動畫結束的狀態等等,transition 只能觸發一次;
4、animation 可以結合 keyframe 設置每一幀,但是 transition 只有兩幀;
5、在性能方面:瀏覽器有一個主線程和排版線程;主線程一般是對 js 運行的、頁面布局、生成位圖等等,然后把生成好的位圖傳遞給排版線程,而排版線程會通過 GPU 將位圖繪制到頁面上,也會向主線程請求位圖等等;我們在用使用 aniamtion 的時候這樣就可以改變很多屬性,像我們改變了 width、height、postion 等等這些改變文檔流的屬性的時候就會引起,頁面的回流和重繪,對性能影響就比較大,但是我們用 transition 的時候一般會結合 tansfrom 來進行旋轉和縮放等不會生成新的位圖,當然也就不會引起頁面的重排了;
26、vue中key
Diff算法
當頁面的數據發生變化時,Diff算法只會比較同一層級的節點:
*** 如果節點類型不同,直接干掉前面的節點,再創建并插入新的節點,不會再比較這個節點以后的子節點了。
** 如果節點類型相同,則會重新設置該節點的屬性,從而實現節點的更新。
當某一層有很多相同的節點時,也就是列表節點時,Diff算法的更新過程默認情況下也是遵循以上原則。
比如一下這個情況:
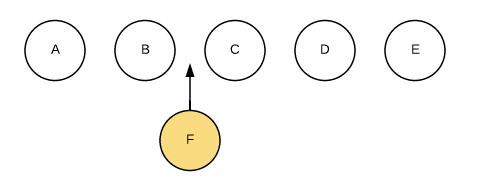
image
我們希望可以在B和C之間加一個F,Diff算法默認執行起來是這樣的:
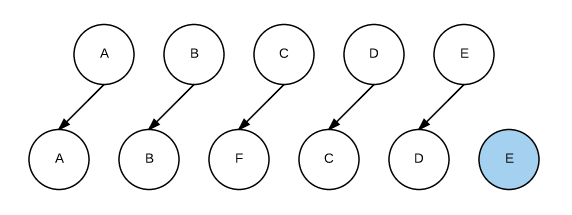
image
即把C更新成F,D更新成C,E更新成D,最后再插入E,是不是很沒有效率?
所以我們需要使用key來給每個節點做一個唯一標識,Diff算法就可以正確的識別此節點,找到正確的位置區插入新的節點。
key使用index的弊端
增刪后導致的問題就是以前的數據和重新渲染后的數據隨著 key 值的變化從而沒法建立關聯關系. 這就失去了 key 值存在的意義. 也是導致數據出現詭異的罪魁禍首!
27、JS的8種數據類型
JS數據類型:JS 的數據類型有幾種?
8種。Number、String、Boolean、Null、undefined、object、symbol、bigInt。
雖然typeof null =='Object'但它并不是對象
null其實并不是一個對象,盡管typeof null 輸出的是object,但是這其實是一個bug。在js最初的版本中使用的是32位系統,為了性能考慮地位存儲變量的類型信息,000開頭表示為對象類型,然而null為全0,故而null被判斷為對象類型。
28、簡單請求和非簡單請求
瀏覽器將CORS請求分為兩類:簡單請求(simple request)和非簡單請求(not-simple-request),簡單請求瀏覽器不會預檢,而非簡單請求會預檢。這兩種方式怎么區分?
同時滿足下列三大條件,就屬于簡單請求,否則屬于非簡單請求
1.請求方式只能是:GET、POST、HEAD
2.HTTP請求頭限制這幾種字段:Accept、Accept-Language、Content-Language、Content-Type、Last-Event-ID
3.Content-type只能取:application/x-www-form-urlencoded、multipart/form-data、text/plain
對于簡單請求,瀏覽器直接請求,會在請求頭信息中,增加一個origin字段,來說明本次請求來自哪個源(協議+域名+端口)。服務器根據這個值,來決定是否同意該請求,服務器返回的響應會多幾個頭信息字段,如圖所示:上面的頭信息中,三個與CORS請求相關,都是以Access-Control-開頭。
1.Access-Control-Allow-Origin:該字段是必須的,* 表示接受任意域名的請求,還可以指定域名
2.Access-Control-Allow-Credentials:該字段可選,是個布爾值,表示是否可以攜帶cookie,(注意:如果Access-Control-Allow-Origin字段設置*,此字段設為true無效)
3.Access-Control-Allow-Headers:該字段可選,里面可以獲取Cache-Control、Content-Type、Expires等,如果想要拿到其他字段,就可以在這個字段中指定。
非簡單請求是對那種對服務器有特殊要求的請求,比如請求方式是PUT或者DELETE,或者Content-Type字段類型是application/json。都會在正式通信之前,增加一次HTTP請求,稱之為預檢。瀏覽器會先詢問服務器,當前網頁所在域名是否在服務器的許可名單之中,服務器允許之后,瀏覽器會發出正式的XMLHttpRequest請求,否則會報錯。
很明顯,請求頭中預檢請求不會攜帶cookie,正式請求會攜帶cookie和參數。跟普通請求一樣,響應頭也會增加同樣字段。
一旦服務器通過了“預檢”請求,以后每次瀏覽器正常的CORS請求,就都跟簡單請求一樣。
29、深拷貝的實現
1、使用遞歸的方式實現深拷貝
//使用遞歸的方式實現數組、對象的深拷貝
function deepClone1(obj) {//判斷拷貝的要進行深拷貝的是數組還是對象,是數組的話進行數組拷貝,對象的話進行對象拷貝var objClone = Array.isArray(obj) ? [] : {};//進行深拷貝的不能為空,并且是對象或者是if (obj && typeof obj === "object") {for (key in obj) {if (obj.hasOwnProperty(key)) {if (obj[key] && typeof obj[key] === "object") {objClone[key] = deepClone1(obj[key]);} else {objClone[key] = obj[key];}}}}return objClone;
}
30、x-requested-with的作用
可以用來判斷客戶端的請求是Ajax請求還是其他請求。。
若 req.headers[‘x-requested-with’].toLowerCase() == ‘xmlhttprequest’ 則為ajax請求。
31、VUE中父子組件生命周期
- 加載渲染過程
父beforeCreate->父created->父beforeMount->子beforeCreate->子created->子beforeMount->子mounted->父mounted
- 子組件更新過程
父beforeUpdate->子beforeUpdate->子updated->父updated
- 父組件更新過程
父beforeUpdate->父updated
- 銷毀過程
父beforeDestroy->子beforeDestroy->子destroyed->父destroyed
32、堆和棧的區別
1、堆棧空間分配區別
棧(操作系統):由操作系統(編譯器)自動分配釋放 ,存放函數的參數值,局部變量的值等。其操作方式類似于數據結構中的棧。
堆(操作系統): 一般由程序員分配釋放, 若程序員不釋放,程序結束時可能由OS回收,分配方式倒是類似于鏈表。
2、堆棧緩存方式區別
棧使用的是一級緩存, 它們通常都是被調用時處于存儲空間中,調用完畢立即釋放。
堆則是存放在二級緩存中,生命周期由虛擬機的垃圾回收算法來決定(并不是一旦成為孤兒對象就能被回收)。所以調用這些對象的速度要相對來得低一些。
32、作用域鏈
一、作用域
在 Javascript 中,作用域分為 全局作用域 和 函數作用域
全局作用域:
代碼在程序的任何地方都能被訪問,window 對象的內置屬性都擁有全局作用域。
函數作用域:
在固定的代碼片段才能被訪問
作用域有上下級關系,上下級關系的確定就看函數是在哪個作用域下創建的。如上,fn作用域下創建了bar函數,那么“fn作用域”就是“bar作用域”的上級。
作用域最大的用處就是隔離變量,不同作用域下同名變量不會有沖突。
變量取值:到創建 這個變量 的函數的作用域中取值
二、作用域鏈
一般情況下,變量取值到 創建 這個變量 的函數的作用域中取值。
但是如果在當前作用域中沒有查到值,就會向上級作用域去查,直到查到全局作用域,這么一個查找過程形成的鏈條就叫做作用域鏈。
為什么在js當中沒有var就是全局變量
因為,在js中,如果某個變量沒有var聲明,會自動移到上一層作用域中去找這個變量的聲明語句,如果找到,就是用,如果沒找到,
就繼續向上尋找,一直查找到全局作用域為止,如果全局中仍然沒有這個變量的聲明語句,那么自動在全局作用域進行聲明,這個就
是js中的作用域鏈,也叫變量提升

)



)

![[Spark]-RDD詳解之變量操作](http://pic.xiahunao.cn/[Spark]-RDD詳解之變量操作)
)

)



)




