33、閉包
閉包的概念
上一節代碼中的f2函數,就是閉包。
各種專業文獻上的"閉包"(closure)定義非常抽象,很難看懂。我的理解是,閉包就是能夠讀取其他函數內部變量的函數。
由于在Javascript語言中,只有函數內部的子函數才能讀取局部變量,因此可以把閉包簡單理解成"定義在一個函數內部的函數"。
所以,在本質上,閉包就是將函數內部和函數外部連接起來的一座橋梁。
閉包的用途
閉包可以用在許多地方。它的最大用處有兩個,一個是前面提到的可以讀取函數內部的變量,另一個就是讓這些變量的值始終保持在內存中。
怎么來理解這句話呢?請看下面的代碼。
function f1(){var n=999; nAdd=function(){n+=1}function f2(){
alert(n);}return f2;}var result=f1(); result(); // 999 nAdd(); result(); // 1000
在這段代碼中,result實際上就是閉包f2函數。它一共運行了兩次,第一次的值是999,第二次的值是1000。這證明了,函數f1中的局部變量n一直保存在內存中,并沒有在f1調用后被自動清除。
為什么會這樣呢?原因就在于f1是f2的父函數,而f2被賦給了一個全局變量,這導致f2始終在內存中,而f2的存在依賴于f1,因此f1也始終在內存中,不會在調用結束后,被垃圾回收機制(garbage collection)回收。
這段代碼中另一個值得注意的地方,就是"nAdd=function(){n+=1}"這一行,首先在nAdd前面沒有使用var關鍵字,因此nAdd是一個全局變量,而不是局部變量。其次,nAdd的值是一個匿名函數(anonymous function),而這個匿名函數本身也是一個閉包,所以nAdd相當于是一個setter,可以在函數外部對函數內部的局部變量進行操作。
使用閉包的注意點
1)由于閉包會使得函數中的變量都被保存在內存中,內存消耗很大,所以不能濫用閉包,否則會造成網頁的性能問題,在IE中可能導致內存泄露。解決方法是,在退出函數之前,將不使用的局部變量全部刪除。
2)閉包會在父函數外部,改變父函數內部變量的值。所以,如果你把父函數當作對象(object)使用,把閉包當作它的公用方法(Public Method),把內部變量當作它的私有屬性(private value),這時一定要小心,不要隨便改變父函數內部變量的值。
var name = "The Window";var object = {name : "My Object",getNameFunc : function(){return function(){return this.name;};}}; alert(object.getNameFunc()());//The Window
var name = "The Window";var object = {name : "My Object",getNameFunc : function(){var that = this;return function(){return that.name;};}}; alert(object.getNameFunc()());//My Object
34、this指向
首先必須要說的是,this的指向在函數定義的時候是確定不了的,只有函數執行的時候才能確定this到底指向誰,實際上this的最終指向的是那個調用它的對象
例子1:
這里的函數a實際是被Window對象所點出來的
function a(){var user = "追夢子";console.log(this.user); //undefinedconsole.log(this); //Window
}
a();//window.a()
例子2:
var o = {user:"追夢子",fn:function(){console.log(this.user); //追夢子}
}
o.fn();
這里的this指向的是對象o,因為你調用這個fn是通過o.fn()執行的,那自然指向就是對象o,這里再次強調一點,this的指向在函數創建的時候是決定不了的,在調用的時候才能決定,誰調用的就指向誰,一定要搞清楚這個。
var o = {a:10,b:{a:12,fn:function(){console.log(this.a); //12}}
}
o.b.fn();
這里同樣也是對象o點出來的,但是同樣this并沒有執行它,那你肯定會說我一開始說的那些不就都是錯誤的嗎?其實也不是,只是一開始說的不準確,接下來我將補充一句話,我相信你就可以徹底的理解this的指向的問題。
情況1:如果一個函數中有this,但是它沒有被上一級的對象所調用,那么this指向的就是window,這里需要說明的是在js的嚴格版中this指向的不是window,但是我們這里不探討嚴格版的問題,你想了解可以自行上網查找。
情況2:如果一個函數中有this,這個函數有被上一級的對象所調用,那么this指向的就是上一級的對象。
情況3:如果一個函數中有this,**這個函數中包含多個對象,盡管這個函數是被最外層的對象所調用,this指向的也只是它上一級的對象,**例子3可以證明,如果不相信,那么接下來我們繼續看幾個例子。
var o = {a:10,b:{// a:12,fn:function(){console.log(this.a); //undefined}}
}
o.b.fn();
盡管對象b中沒有屬性a,這個this指向的也是對象b,因為this只會指向它的上一級對象,不管這個對象中有沒有this要的東西。
還有一種比較特殊的情況,例子4:
var o = {a:10,b:{a:12,fn:function(){console.log(this.a); //undefinedconsole.log(this); //window}}
}
var j = o.b.fn;
j();
這里this指向的是window,是不是有些蒙了?其實是因為你沒有理解一句話,這句話同樣至關重要。
this永遠指向的是最后調用它的對象,也就是看它執行的時候是誰調用的,例子4中雖然函數fn是被對象b所引用,但是在將fn賦值給變量j的時候并沒有執行所以最終指向的是window,這和例子3是不一樣的,例子3是直接執行了fn。
構造函數版this:
function Fn(){this.user = "追夢子";
}
var a = new Fn();
console.log(a.user); //追夢子
這里之所以對象a可以點出函數Fn里面的user是因為new關鍵字可以改變this的指向,將這個this指向對象a,為什么我說a是對象,因為用了new關鍵字就是創建一個對象實例,理解這句話可以想想我們的例子3,我們這里用變量a創建了一個Fn的實例(相當于復制了一份Fn到對象a里面),此時僅僅只是創建,并沒有執行,而調用這個函數Fn的是對象a,那么this指向的自然是對象a,那么為什么對象a中會有user,因為你已經復制了一份Fn函數到對象a中,用了new關鍵字就等同于復制了一份。
更新一個小問題當this碰到return時
function fn()
{ this.user = '追夢子'; return {};
}
var a = new fn;
console.log(a.user); //undefined
再看一個
function fn()
{ this.user = '追夢子'; return function(){};
}
var a = new fn;
console.log(a.user); //undefined
再來
function fn()
{ this.user = '追夢子'; return 1;
}
var a = new fn;
console.log(a.user); //追夢子
function fn()
{ this.user = '追夢子'; return undefined;
}
var a = new fn;
console.log(a.user); //追夢子
什么意思呢?
如果返回值是一個對象,那么this指向的就是那個返回的對象,如果返回值不是一個對象那么this還是指向函數的實例。
function fn()
{ this.user = '追夢子'; return undefined;
}
var a = new fn;
console.log(a); //fn {user: "追夢子"}
還有一點就是雖然null也是對象,但是在這里this還是指向那個函數的實例,因為null比較特殊。
function fn()
{ this.user = '追夢子'; return null;
}
var a = new fn;
console.log(a.user); //追夢子
相關面試題
let n=1
function A() { this.n = 0; }
A.prototype.callMe = function () { console.log(this); };
let a = new A();
document.addEventListener("click", a.callMe); //undefined 這里調用callMe的實際是document,加監聽器時沒有調用函數
document.addEventListener("click", () => { a.callMe(); }); //0
document.addEventListener("click", function () { a.callMe(); }); //0
35、從URL輸入到頁面展現發生了什么?
1、域名解析。通過域名查找IP地址。可以從瀏覽器緩存,操作系統緩存,路由緩存,ISP的DNS服務器,根服務器中進行查找。
2、tcp三次握手
3、發送HTTP請求
4、服務器處理請求并返回HTTP報文
5、瀏覽器解析渲染頁面。解析HTML生成DOM樹,解析CSS生成CSSOM,結合DOM樹和CSSOM生成Render樹,重繪,重排。
6、tcp四次揮手
36、JS垃圾回收
標記清除
js中最常用的垃圾收集方式是標記清楚。當變量進入環境(例如,在函數中聲明一個變量)時,就將這個變量標記為“進入環境”。從邏輯上講,永遠不能釋放進入環境的變量所占用的內存,因為只要執行流進入相應的環境,就可能會用到他們。而當變量離開環境時,則將其標記為“離開環境”。
可以使用任何方式來標記變量。比如,可以通過翻轉某個特殊的位來記錄一個變量何時進入環境,或者使用一個“進入環境的”變量列表及一個“離開環境的”變量列表來跟蹤哪個變量發生變化。
垃圾收集器在運行的時候會給存儲在內存中的所有變量都加上標記(當然,可以使用任何標記方式)。然后,它會去掉環境中的變量以及被環境中的變量引用的變量標記。而在此之后再被加上標記的變量將被視為準備刪除的變量,原因是環境中的變量已經無法訪問到這些變量了。最后,垃圾收集器完成內存除工作,銷毀那些帶標記的值并回收他們所占用的內存空間。
引用計數(不常見)
引用計數的含義是跟蹤記錄每個值被引用的次數。當聲明了一個變量并將一個引用類型值賦給該變量時,則這個值的引用次數就是1。如果同一個值又被賦給另一個變量,則該值的引用次數加1.相反,如果包含對這個值引用的變量又取的了另一個值,則這個值的引用次數減1.當這個值的引用次數變成0時,則說明沒有辦法再訪問這個值了,因而就可以將其占用的內存空間收回來。這樣,當垃圾收集器下次再運行時,它就會釋放那些引用次數為零的值所占用的內存。
用引用計數法會存在內存泄露,下面來看原因:
function problem() {
var objA = new Object();
var objB = new Object();
objA.someOtherObject = objB;
objB.anotherObject = objA;
}
- 設置undefined不會被垃圾回收,設置null會
什么是?
1作用:聲明文檔的解析類型(document.compatMode),避免瀏覽器的怪異模式。
document.compatMode:
BackCompat:怪異模式,瀏覽器使用自己的怪異模式解析渲染頁面。
CSS1Compat:標準模式,瀏覽器使用W3C的標準解析渲染頁面。
BackCompat:標準兼容模式關閉。瀏覽器客戶區寬度是document.body.clientWidth;CSS1Compat:標準兼容模式開啟。 瀏覽器客戶區寬度是document.documentElement.clientWidth。
? 這個屬性會被瀏覽器識別并使用,但是如果你的頁面沒有DOCTYPE的聲明,那么compatMode默認就是BackCompat,
瀏覽器按照自己的方式解析渲染頁面,那么,在不同的瀏覽器就會顯示不同的樣式。
如果你的頁面添加了那么,那么就等同于開啟了標準模式,那么瀏覽器就得老老實實的按照W3C的
標準解析渲染頁面,這樣一來,你的頁面在所有的瀏覽器里顯示的就都是一個樣子了。
這就是的作用。
2 使用:
2.1 使用也很簡單,就是在你的html頁面的第一行添加""一行代碼就可以了
2.2 jsp的話,添加在<%@ page %>的下一行。
2.3 不用區分大小寫
37、盒模型
IE盒模型
定義的width=content實際寬度+padding+border
可以通過box-sizing屬性設置為border-box使用這種IE盒模型
W3C標準盒模型
盒模型的總寬度為:margin+padding+border+定義的width
此處定義width,就是實際的content的寬度。box-sizing的默認屬性content-box,即設置為W3C標準盒模型;
IE盒模型和W3C標準盒模型的兼容性
對于盒模型的優先如何選用?前面有提到,除了一些非常特殊的場合之外,我們很少使用box-sizing:border-box去調用IE盒模型,而是默認設置box-sizing:content-box使用W3C標準盒模型,這樣可以避免多個瀏覽器對同一頁面的不兼容。
38、跨域
什么是跨域?
跨域是指從一個域名去請求另一個域名的資源,嚴格來說,只要域名,協議,端口任何一個不同,就視為跨域。
同源策略限制的具體表現是什么?
(1)coikie、LocalStorage和Index DB 無法讀取
(2)Dom 無法獲得
(3)AJAX請求不能發送
JS中自帶跨域技能的標簽是什么 ?
JS中有兩個神奇的標簽,從出生起就自帶跨域技能,就是和
跨域解決方法
【1】設置document.domain解決無法讀取非同源網頁的 Cookie問題
因為瀏覽器是通過document.domain屬性來檢查兩個頁面是否同源,因此只要通過設置相同的document.domain,兩個頁面就可以共享Cookie(此方案僅限主域相同,子域不同的跨域應用場景。)
【2】跨文檔通信 API:window.postMessage()
調用postMessage方法實現父窗口http://test1.com向子窗口http://test2.com發消息(子窗口同樣可以通過該方法發送消息給父窗口)
它可用于解決以下方面的問題:
頁面和其打開的新窗口的數據傳遞
多窗口之間消息傳遞
頁面與嵌套的iframe消息傳遞
上面三個場景的跨域數據傳遞
// 父窗口打開一個子窗口
var openWindow = window.open('http://test2.com', 'title');// 父窗口向子窗口發消息(第一個參數代表發送的內容,第二個參數代表接收消息窗口的url)
openWindow.postMessage('Nice to meet you!', 'http://test2.com');
調用message事件,監聽對方發送的消息
// 監聽 message 消息
window.addEventListener('message', function (e) {console.log(e.source); // e.source 發送消息的窗口console.log(e.origin); // e.origin 消息發向的網址console.log(e.data); // e.data 發送的消息
},false);
【3】JSONP
JSONP 是服務器與客戶端跨源通信的常用方法。最大特點就是簡單適用,兼容性好(兼容低版本IE),缺點是只支持get請求,不支持post請求。
核心思想:網頁通過添加一個
①原生實現:
<script src="http://test.com/data.php?callback=dosomething"></script>
// 向服務器test.com發出請求,該請求的查詢字符串有一個callback參數,用來指定回調函數的名字// 處理服務器返回回調函數的數據
<script type="text/javascript">function dosomething(res){// 處理獲得的數據console.log(res.data)}
</script>
② jQuery ajax:
$.ajax({url: 'http://www.test.com:8080/login',type: 'get',dataType: 'jsonp', // 請求方式為jsonpjsonpCallback: "handleCallback", // 自定義回調函數名data: {}
});
③ Vue.js:
this.$http.jsonp('http://www.domain2.com:8080/login', {params: {},jsonp: 'handleCallback'
}).then((res) => {console.log(res);
})
【4】CORS
CORS 是跨域資源分享(Cross-Origin Resource Sharing)的縮寫。它是 W3C 標準,屬于跨源 AJAX 請求的根本解決方法。
1、普通跨域請求:只需服務器端設置Access-Control-Allow-Origin
2、帶cookie跨域請求:前后端都需要進行設置
【前端設置】根據xhr.withCredentials字段判斷是否帶有cookie
①原生ajax
var xhr = new XMLHttpRequest(); // IE8/9需用window.XDomainRequest兼容// 前端設置是否帶cookie
xhr.withCredentials = true;xhr.open('post', 'http://www.domain2.com:8080/login', true);
xhr.setRequestHeader('Content-Type', 'application/x-www-form-urlencoded');
xhr.send('user=admin');xhr.onreadystatechange = function() {if (xhr.readyState == 4 && xhr.status == 200) {alert(xhr.responseText);}
};
② jQuery ajax
$.ajax({url: 'http://www.test.com:8080/login',type: 'get',data: {},xhrFields: {withCredentials: true // 前端設置是否帶cookie},crossDomain: true, // 會讓請求頭中包含跨域的額外信息,但不會含cookie
});
39、requestAnimationFrame和setTimeout()作動畫的區別
動畫原理
根據上面的原理我們知道,你眼前所看到圖像正在以每秒60次的頻率刷新,由于刷新頻率很高,因此你感覺不到它在刷新。而動畫本質就是要讓人眼看到圖像被刷新而引起變化的視覺效果,這個變化要以連貫的、平滑的方式進行過渡。 那怎么樣才能做到這種效果呢?
刷新頻率為60Hz的屏幕每16.7ms刷新一次,我們在屏幕每次刷新前,將圖像的位置向左移動一個像素,即1px。這樣一來,屏幕每次刷出來的圖像位置都比前一個要差1px,因此你會看到圖像在移動;由于我們人眼的視覺停留效應,當前位置的圖像停留在大腦的印象還沒消失,緊接著圖像又被移到了下一個位置,因此你才會看到圖像在流暢的移動,這就是視覺效果上形成的動畫。
setTimeout
理解了上面的概念以后,我們不難發現,setTimeout 其實就是通過設置一個間隔時間來不斷的改變圖像的位置,從而達到動畫效果的。但我們會發現,利用seTimeout實現的動畫在某些低端機上會出現卡頓、抖動的現象。 這種現象的產生有兩個原因:
- setTimeout的執行時間并不是確定的。在Javascript中, setTimeout 任務被放進了異步隊列中,只有當主線程上的任務執行完以后,才會去檢查該隊列里的任務是否需要開始執行,因此 setTimeout 的實際執行時間一般要比其設定的時間晚一些。
- 刷新頻率受屏幕分辨率和屏幕尺寸的影響,因此不同設備的屏幕刷新頻率可能會不同,而 setTimeout只能設置一個固定的時間間隔,這個時間不一定和屏幕的刷新時間相同。
requestAnimationFrame
window.requestAnimationFrame() 這個方法是用來在頁面重繪之前,通知瀏覽器調用一個指定的函數。這個方法接受一個函數為參,該函數會在重繪前調用。
與setTimeout相比,requestAnimationFrame最大的優勢是**由系統來決定回調函數的執行時機。**具體一點講,如果屏幕刷新率是60Hz,那么回調函數就每16.7ms被執行一次,如果刷新率是75Hz,那么這個時間間隔就變成了1000/75=13.3ms,換句話說就是,requestAnimationFrame的步伐跟著系統的刷新步伐走。它能保證回調函數在屏幕每一次的刷新間隔中只被執行一次,這樣就不會引起丟幀現象,也不會導致動畫出現卡頓的問題。
這個API的調用很簡單,如下所示:
var progress = 0;
//回調函數
function render() {progress += 1; //修改圖像的位置if (progress < 100) {//在動畫沒有結束前,遞歸渲染window.requestAnimationFrame(render);}
}
//第一幀渲染
window.requestAnimationFrame(render);
除此之外,requestAnimationFrame還有以下兩個優勢:
-
CPU節能:使用setTimeout實現的動畫,當頁面被隱藏或最小化時,setTimeout 仍然在后臺執行動畫任務,由于此時頁面處于不可見或不可用狀態,刷新動畫是沒有意義的,完全是浪費CPU資源。而requestAnimationFrame則完全不同,當頁面處理未激活的狀態下,該頁面的屏幕刷新任務也會被系統暫停,因此跟著系統步伐走的requestAnimationFrame也會停止渲染,當頁面被激活時,動畫就從上次停留的地方繼續執行,有效節省了CPU開銷。
-
函數節流:在高頻率事件(resize,scroll等)中,為了防止在一個刷新間隔內發生多次函數執行,使用requestAnimationFrame可保證每個刷新間隔內,函數只被執行一次,這樣既能保證流暢性,也能更好的節省函數執行的開銷。一個刷新間隔內函數執行多次時沒有意義的,因為顯示器每16.7ms刷新一次,多次繪制并不會在屏幕上體現出來。
40、JS 中對變量類型的五種判斷方法
方法一:使用typeof檢測
當需要變量是否是number,string,boolean
,function,undefined,json類型時,可以使用typeof進行判斷;其他變量是判斷不出類型的,包括null。
typeof是區分不出array和json類型的,因為使用typeof這個變量時,array和json類型輸出的都是object
方法二:使用instance檢測
instanceof 運算符與 typeof 運算符相似,用于識別正在處理的對象的類型。與 typeof 方法不同的是,instanceof 方法要求開發者明確地確認對象為某特定類型
方法三:使用constructor檢測
constructor本來是原型對象上的屬性,指向構造函數。但是根據實例對象尋找屬性的順序,若實例對象上沒有實例屬性或方法,就去原型鏈上尋找,因此,實例對象也是能使用constructor屬性的
因為undefined和null沒有constructor屬性,所以不能使用constructor判斷
方法四:使用Object.prototype.toString.call
Object.prototype.toString.call(變量)輸出的是一個字符串,字符串里有一個數組,第一個參數是Object,第二個參數就是這個變量的類型,而且,所有變量的類型都檢測出來了,我們只需要取出第二個參數即可。或者可以使用Object.prototype.toString.call(arr)=="object Array"來檢測變量arr是不是數組。
41、對promise中resolve()的理解
可以這樣理解,在新建 promise 的時候就傳入了兩個參數
這兩個參數用來標記 promise的狀態的,這兩個參數是兩個方法,并且這兩個參數可以隨意命名,我這里的使用的是omg 也不影響使用
用于表示 promise 的狀態
到執行到 resolve()這個方法的時候,就改變promise的狀態為
fullfiled ,當狀態為 fuulfiled的時候就可以執行.then()
當執行到 reject() 這個方法的時候,就改變 promise 的狀態為
reject,當 promise 為reject 就可以.catch() 這個promise了
然后這兩個方法可以帶上參數,用于.then() 或者 .catch() 中使用。
所以這兩個方法不是替代,或者是執行什么,他們的作用就是 用于改變
promise 的狀態。
然后,因為狀態改變了,所以才可以執行相應的 .then() 和 .catch()操作。
42、DNS請求順序
當一個用戶在地址欄輸入www.taobao.com時,DNS解析有大致十個過程,如下:
-
瀏覽器先檢查自身緩存中有沒有被解析過的這個域名對應的ip地址,如果有,解析結束。同時域名被緩存的時間也可通過TTL屬性來設置。
-
如果瀏覽器緩存中沒有(專業點叫還沒命中),瀏覽器會檢查操作系統緩存中有沒有對應的已解析過的結果。而操作系統也有一個域名解析的過程。在windows中可通過c盤里一個叫hosts的文件來設置,如果你在這里指定了一個域名對應的ip地址,那瀏覽器會首先使用這個ip地址。
但是這種操作系統級別的域名解析規程也被很多黑客利用,通過修改你的hosts文件里的內容把特定的域名解析到他指定的ip地址上,造成所謂的域名劫持。所以在windows7中將hosts文件設置成了readonly,防止被惡意篡改。
-
如果至此還沒有命中域名,才會真正的請求本地域名服務器(LDNS)來解析這個域名,這臺服務器一般在你的城市的某個角落,距離你不會很遠,并且這臺服務器的性能都很好,一般都會緩存域名解析結果,大約80%的域名解析到這里就完成了。
-
如果LDNS仍然沒有命中,就直接跳到Root Server 域名服務器請求解析
-
根域名服務器返回給LDNS一個所查詢域的主域名服務器(gTLD Server,國際頂尖域名服務器,如.com .cn .org等)地址
-
此時LDNS再發送請求給上一步返回的gTLD
-
接受請求的gTLD查找并返回這個域名對應的Name Server的地址,這個Name Server就是網站注冊的域名服務器
-
Name Server根據映射關系表找到目標ip,返回給LDNS
-
LDNS緩存這個域名和對應的ip
-
LDNS把解析的結果返回給用戶,用戶根據TTL值緩存到本地系統緩存中,域名解析過程至此結束
43、document.write和innerHTML的區別
document.write只能重繪整個頁面
innerHTML可以重繪頁面的一部分。
44、HTMLCollection vs. NodeList
HTMLCollection與NodeList都是DOM節點的集合,兩者都屬于Collections范疇,兩者的區別在于:
方法略有差異:HTMLCollection比NodeList多了一個namedItem方法,其他方法保持一致
包含節點類型不同:NodeList可以包含任何節點類型,HTMLCollection只包含元素節點(ElementNode)
當返回多個節點(如:getElementByTagName)或者得到所有子元素(如:element.childNodes)時,Collections就會出現,這時候就有可能返回HTMLCollection或者NodeList
1、HTMLCollection
HTMLCollection是以節點為元素的列表,可以憑借索引、節點名稱、節點屬性來對獨立的節點進行訪問。HTML DOM中的Collections是實時變動的,當原始文件變化,Collections也會隨之發生變化。
-
屬性:
length(返回的是列表的長度) -
方法1:
item(通過序號索引來獲取節點,參數是索引值,超過索引值返回null)方法2:
namedItem(用名字來返回一個節點,首先搜尋是否有匹配的id屬性,如果沒有就尋找是否有匹配的name屬性,如果都沒有,返回null)
2、NodeList
NodeList返回節點的有序集合,DOM中的NodeList也是實時變動的
-
屬性:
length(列表中節點的數量) -
方法:
item(返回集合中的元素,如果超過范圍返回null)
HTMLCollection和NodeList的共同點顯而易見:
- 都是類數組對象,都有
length屬性 - 都有共同的方法:
item,可以通過item(index)或者item(id)來訪問返回結果中的元素 - 都是實時變動的(live),document上的更改會反映到相關對象上(例外:
document.querySelectorAll返回的NodeList不是實時的)
HTMLCollection和NodeList的區別是:
NodeList可以包含任何節點類型,HTMLCollection只包含元素節點(elementNode),elementNode就是HTML中的標簽HTMLCollection比NodeList多一項方法:namedItem,可以通過傳遞id或name屬性來獲取節點信息
45、Node vs Element
簡單的說就是Node是一個基類,DOM中的Element,Text和Comment都繼承于它。
換句話說,Element,Text和Comment是三種特殊的Node,它們分別叫做ELEMENT_NODE,
TEXT_NODE和COMMENT_NODE。
*所以我們平時使用的html上的元素,即Element,是類型為ELEMENT_NODE的Node。*
46、與=區別(兩個等號與三個等號)
1、對于string,number等基礎類型,和=是有區別的
1)不同類型間比較,==之比較“轉化成同一類型后的值”看“值”是否相等,===如果類型不同,其結果就是不等
2)同類型比較,直接進行“值”比較,兩者結果一樣
2、對于Array,Object等高級類型,和=是沒有區別的
進行“指針地址”比較
3、基礎類型與高級類型,和=是有區別的
1)對于==,將高級轉化為基礎類型,進行“值”比較
2)因為類型不同,===結果為false
47、使一個函數只調用一次
export function once (fn) {let called = falsereturn function () {if (!called) {called = truefn.apply(this, arguments)}}
}
48、生成/獲取緩存了的函數
export function cached (fn) {const cache = Object.create(null)return (function cachedFn (str) {const hit = cache[str]return hit || (cache[str] = fn(str))})
}
49、單頁應用和多頁應用
多頁應用
每一次頁面跳轉的時候,后臺服務器都會給返回一個新的html文檔,這種類型的網站也就是多頁網站,也叫做多頁應用。

為什么多頁應用的首屏時間快?
首屏時間叫做頁面首個屏幕的內容展現的時間,當我們訪問頁面的時候,服務器返回一個html,頁面就會展示出來,這個過程只經歷了一個HTTP請求,所以頁面展示的速度非常快。
為什么搜索引擎優化效果好(SEO)?
搜索引擎在做網頁排名的時候,要根據網頁內容才能給網頁權重,來進行網頁的排名。搜索引擎是可以識別html內容的,而我們每個頁面所有的內容都放在Html中,所以這種多頁應用,seo排名效果好。
但是它也有缺點,就是切換慢
因為每次跳轉都需要發出一個http請求,如果網絡比較慢,在頁面之間來回跳轉時,就會發現明顯的卡頓。
單頁應用
第一次進入頁面的時候會請求一個html文件,刷新清除一下。切換到其他組件,此時路徑也相應變化,但是并沒有新的html文件請求,頁面內容也變化了。
原理是:JS會感知到url的變化,通過這一點,可以用js動態的將當前頁面的內容清除掉,然后將下一個頁面的內容掛載到當前頁面上,這個時候的路由不是后端來做了,而是前端來做,判斷頁面到底是顯示哪個組件,清除不需要的,顯示需要的組件。這種過程就是單頁應用,每次跳轉的時候不需要再請求html文件了。

我是單頁應用
為什么頁面切換快?
頁面每次切換跳轉時,并不需要做html文件的請求,這樣就節約了很多http發送時延,我們在切換頁面的時候速度很快。
缺點:首屏時間慢,SEO差
單頁應用的首屏時間慢,首屏時需要請求一次html,同時還要發送一次js請求,兩次請求回來了,首屏才會展示出來。相對于多頁應用,首屏時間慢。
SEO效果差,因為搜索引擎只認識html里的內容,不認識js的內容,而單頁應用的內容都是靠js渲染生成出來的,搜索引擎不識別這部分內容,也就不會給一個好的排名,會導致單頁應用做出來的網頁在百度和谷歌上的排名差。
有這些缺點,為什么還要使用Vue呢?
Vue還提供了一些其它的技術來解決這些缺點,比如說服務器端渲染技術(我是SSR),通過這些技術可以完美解決這些缺點,解決完這些問題,實際上單頁面應用對于前端來說是非常完美的頁面開發解決方案。
50、JS模塊化
模塊化進化史

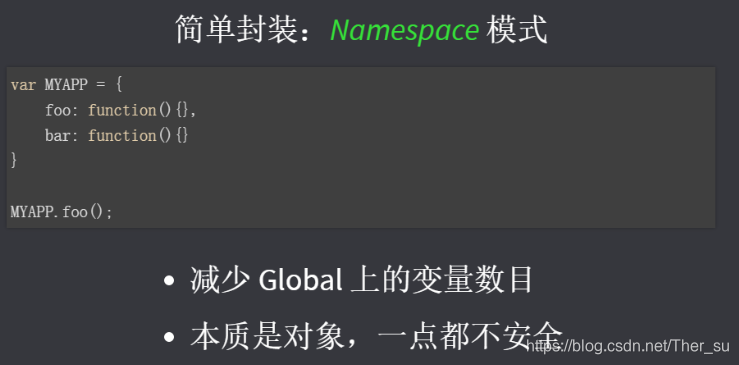
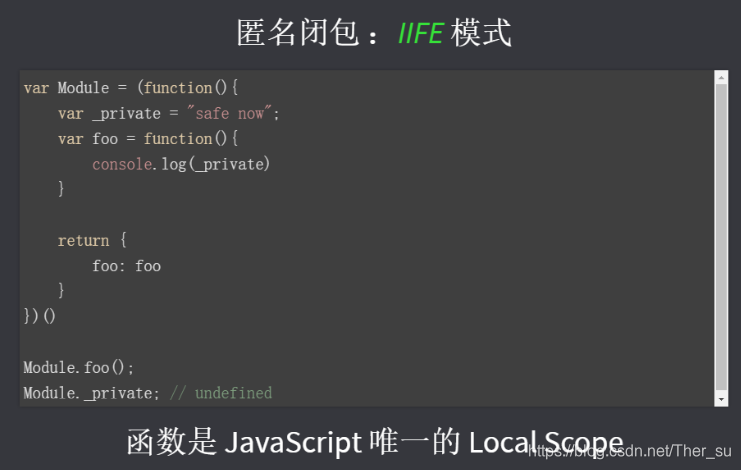
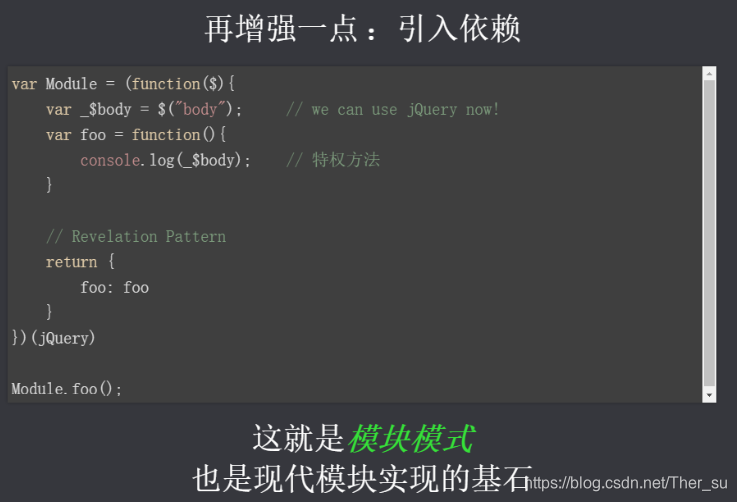

1、commonJS規范
基本語法:
//暴露模塊
module.exports=value
exports.xxx=value
//引入模塊
require(xx)
在服務器端node.js可以直接使用
但在瀏覽器端必須用webpack/Browserify打包編譯
2、AMD規范(Asynchronous Module Definition(異步模塊定義))
專門用于瀏覽器端, 模塊的加載是異步的
基本語法:
//定義沒有依賴的模塊
define(function(){return 模塊
})
//定義有依賴的模塊
define(['module1', 'module2'], function(m1, m2){return 模塊
})
//導入使用模塊
require(['module1', 'module2'], function(m1, m2){使用m1/m2
})
用require.js實現
export var firstName = 'Michael';
export var lastName = 'Jackson';
export var year = 1958;//分別暴露
var firstName = 'Michael';
var lastName = 'Jackson';
var year = 1958;//整體暴露
export {firstName, lastName, year};
這種情況下import命令接受一對大括號,里面指定要從其他模塊導入的變量名。大括號里面的變量名,必須與被導入模塊(profile.js)對外接口的名稱相同。
如果想為輸入的變量重新取一個名字,import命令要使用as關鍵字,將輸入的變量重命名。
import { lastName as surname } from './profile.js';
使用export default命令,可以為模塊指定默認輸出。
export default function () {//默認暴露console.log('foo');
}
其他模塊加載該模塊時,import命令可以為該匿名函數指定任意名字。
import customName from './export-default';
要想在瀏覽器端實現,要先用Babel將ES6編譯成ES5的CommomJS規范的代碼,然后再用Browserify編譯

![[Spark]-RDD詳解之變量操作](http://pic.xiahunao.cn/[Spark]-RDD詳解之變量操作)
)

)



)





—— vue工程打包上線樣式錯亂問題)


—— 阿里云服務器 ECS升級node版本)
淺復制解決方法)
