轉自:https://blog.csdn.net/fendouaini/article/details/79821852
1 詞向量
在NLP里,最細的粒度是詞語,由詞語再組成句子,段落,文章。所以處理NLP問題時,怎么合理的表示詞語就成了NLP領域中最先需要解決的問題。
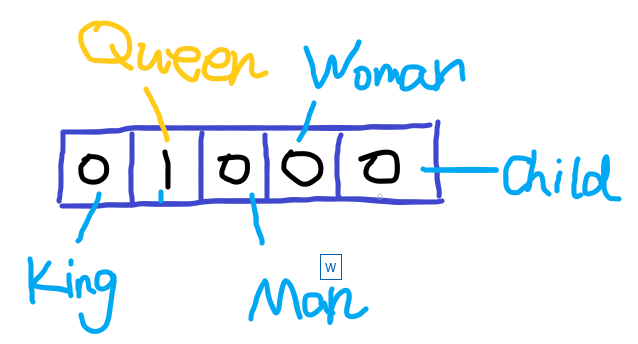
因為語言模型的輸入詞語必須是數值化的,所以必須想到一種方式將字符串形式的輸入詞語轉變成數值型。由此,人們想到了用一個向量來表示詞組。在很久以前,人們常用one-hot對詞組進行編碼,這種編碼的特點是,對于用來表示每個詞組的向量長度是一定的,這個長度就是對應的整個詞匯表的大小,對應每個具體的詞匯表中的詞,將該詞的對應的位置置為1,向量其他位置置為0。舉個例子,假設我們現有5個詞組組成的詞匯表,詞’Queen’對應的序號是2,那么它的詞向量就是(0,1,0,0,0)。其他的詞也都是一個長度為5的向量,對應位置是1,其余位置為0。
?
?
One-hot code非常簡單,但是存在很大的問題,當詞匯表很大,比如數百萬個詞組成了詞匯表時,每個詞的向量都是數百萬維,會造成維度災難。并且,one-hot 編碼的向量會過于稀疏,這樣的稀疏向量表達一個詞效率并不高。
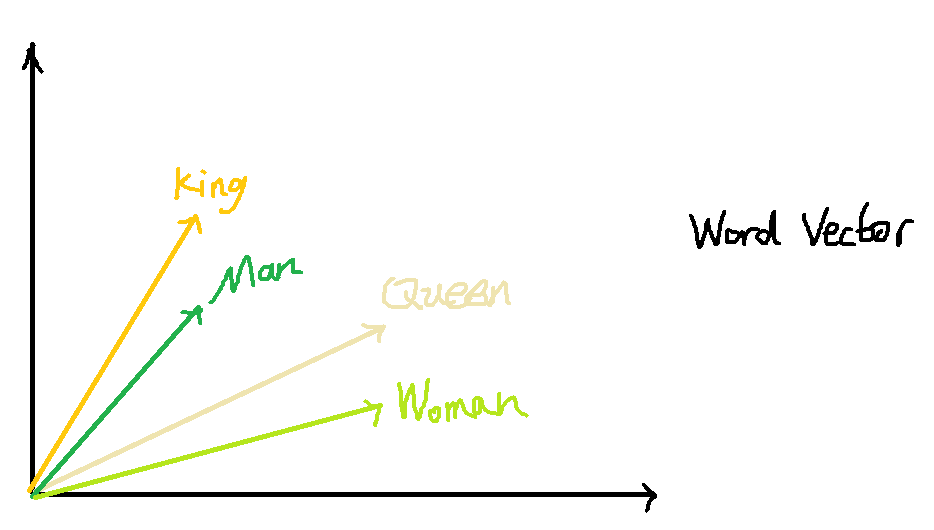
而dristributed representation(通常叫做詞向量)可以很好的解決one-hot code的問題,它是通過訓練,將每個詞都映射到一個較短的詞向量上(這樣就解決了每個詞向量的維度過大問題),所有的詞向量構成了詞匯表的每個詞。并且更重要的是,dristributed representation表示的較短詞向量還具有衡量不同詞的相似性的作用。比如‘忐’,‘忑’兩個字如果作為兩個詞,那么在dristributed representation表示下,這兩個詞的向量應該會非常相似。不僅如此,dristributed representation表示的詞向量還能表示不同詞組間組合的關系,比如假設現在由訓練好的詞向量,現在拿出King,Queen,Man,Woman四個詞的詞向量,則:
?
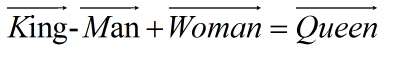
?
?
?
2.DNN訓練詞向量
詞向量怎么得到呢,這里得先說語言模型:
f(x)=y
在NLP中,我們把x看作是一個句子里的一個詞,y是這個詞的上下文。這里的f就是語言模型,通過它判斷(x,y)這個樣本,是否符合自然語言的邏輯法則。直白的說,語言模型判斷樣本(x,y)是不是人話。
而詞向量正是從這個訓練好的語言模型中的副產物模型參數(也就是神經網絡的權重)得來的。這些參數是作為輸入x的某種向量化表示,這個向量就叫做詞向量。
注意我們訓練詞向量的邏輯,我們是為了得到一個語言模型的副產物-詞向量,去訓練這個模型。所以我們的目的不是關注在怎么優化該模型,而是為了獲取該模型的參數構造詞向量。
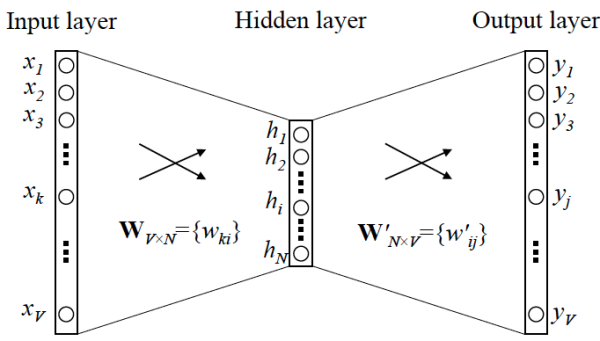
在Word2vec出現之前,已經有用神經網絡DNN來訓練出詞向量了。一般采用三層神經網絡結構,分為輸入層,隱藏層,和輸出層(softmax層)。
?
?
該模型中V代表詞匯表的大小,N代表隱藏層神經元個數(即想要的詞向量維度)。輸入是某個詞,一般用one-hot表示該詞(長度為詞匯表長度),隱藏層有N個神經元,代表我們想要的詞向量的維度,輸入層與隱藏層全連接。輸出層的神經元個數和輸入相同,隱藏層再到輸出層時最后需要計算每個位置的概率,使用softmax計算,每個位置代表不同的單詞。該模型中我們想要的就是經過訓練以后,輸入層到隱藏層的權重作為詞向量。
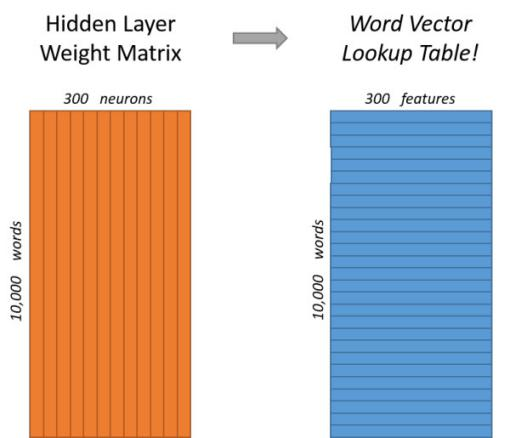
假設詞匯表有10000個,詞向量維度設定為300。
輸入層:
為詞匯表中某一個詞,采用one-hot編碼 長度為1X10000
隱藏層:
從輸入層到隱藏層的權重矩陣W_v*n就是10000行300列的矩陣,其中每一行就代表一個詞向量。這樣詞匯表中所有的詞都會從10000維的one-hot code轉變成為300維的詞向量。
?
?
輸出層:
經過神經網絡隱層的計算,這個輸入的詞就會變為1X300的向量,再被輸入到輸出層。輸出層就是一個sotfmax回歸分類器。它的每個結點將會輸出一個0-1的概率,所有結點的值之和為1,我們就會取最大概率位置檢測是否為輸入樣本x對應的y。
?
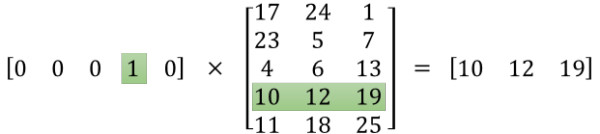
在此補充一下,有沒有考慮過一個問題,采用one-hot編碼時,輸入維度是10000,如果我們將1X10000 向量與10000X300的矩陣相乘,它會消耗大量的計算資源。
?
?
我們發現,one-hot編碼時,由于只有一個位置是1,將該向量與隱藏層權重矩陣相乘會發現,one-hot編碼向量中對應1的index,詞向量中這個下標對應的一行詞向量正式輸出結果。所以,在真正的從輸入到隱藏層的計算中,并不會真正的進行矩陣相乘計算,而是通過one-hot向量1的index取直接查找隱藏層的權重矩陣對應的行,這樣極大的簡化了計算。
?
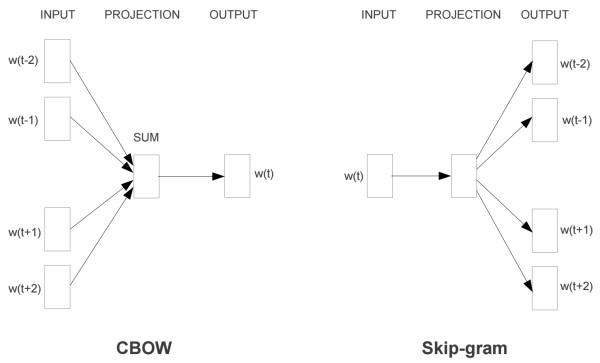
3.CBOW與Skip-gram模型:
該模型更一般情況是使用CBOW(Continuous Bag-of-Words)或Skip-gram兩種模型來定義數據的輸入和輸出。CBOW的訓練輸入的是某一個特征詞的上下文相關的詞對應的詞向量,輸出是這個特定詞的詞向量。而Skip-gram剛好相反,輸入一個特征詞,輸出是這個特征詞。上下文相關的詞。
?
?
這里我們以CBOW模型為例
假設我們有一句話,people make progress every day。輸入的是4個詞向量,’people’ , ‘make‘ , ‘every’ , ‘day’, 輸出是詞匯表中所有詞的softmax概率,我們的目標是期望progress詞對應的softmax概率最大。
?

?
開始時輸入層到隱藏層的權重矩陣和隱藏層到輸出層的權重矩陣隨機初始化,然后one-hot編碼四個輸入的詞向量’people’ ‘make’ ‘every’ ‘day’,并通過各自向量1的位置查詢輸入到隱藏層的權重矩陣行數,找尋其對應的詞向量。將4個詞向量與隱藏層到輸出層的權重相乘通過激活函數激活后再求平均,最后進行softmax計算輸出的每個位置的概率。再通過DNN反向傳播算法,我們就可以更新DNN的隱藏層的權重參數,也就得到了更新后詞向量。通過不斷的訓練,我們得到的模型參數就會越來越準確,詞向量也會變得越來越好。
?
通過這樣的訓練,為什么詞向量會具有衡量不同詞語義相似性的功能呢?
以CBOW模型為例,這里我們可以看到,通過one-hot編碼的輸入樣本,每次只會在隱藏層中輸出與它對應的權重矩陣的行。也就是說在本次訓練中,隱藏層只會調用與輸入樣本相關的某一行的權重參數,然后反向傳播后每次都是局部更新隱藏層的權重矩陣。
?
?
根據語言學,同義詞的上下文很相似,這樣在訓練模型中,相似輸入值都是對應相似的輸出值,每次就會更偏向于局部更新對應這些詞的詞向量的參數,那么久而久之意思有關聯且相近的詞就會在詞向量上很接近。模型的輸出只是每個位置一一對應了詞向量,本身沒有太大的意義。我的理解訓練詞向量的模型就像在做聚類一樣,每次把上下文的詞與中心詞對應的詞向量通過訓練關聯在一起并彼此影響,這樣意思相近的詞對應的詞向量也會越來越像近。













: error C4996: ‘fopen': This function or variable may be unsafe問題)





