zookeeper可謂是目前使用最廣泛的分布式組件了。其功能和職責單一,但卻非常重要。
在現今這個年代,介紹zookeeper的書和文章可謂多如牛毛,本人不才,試圖通過自己的理解來介紹zookeeper,希望通過一個初學者的視角來學習zookeeper,以期讓人更加深入和平穩的理解zookeeper。其中參考了不少教程和書,相關書目列在文末,也感謝這些作者。
學習新的框架,先讓我們搞清楚他是什么,這是它的內涵,然后再介紹它能做什么,這是它的外延,內涵和外延共同來定義框架本身,會對框架有較為深刻的理解,在應用層面上知道如何用。其次再搞清楚zookeeper相關的理論基礎,其目的是知道zookeeper是如何被發明的,是否能夠借鑒以便今后自己能夠用到其他地方。最后搞清楚zookeeper中一些設計的原理和細節,目的也是搞清來龍去脈,學會“術”從而應用到別的地方。當然了,加深的理解同樣能夠幫助認識zookeeper本身,在使用時才知道為什么這樣用。
首先,
zookeeper到底是什么?
zookeeper實際上是yahoo開發的,用于分布式中一致性處理的框架。最初其作為研發hadoop時的副產品。由于分布式系統中一致性處理較為困難,其他的分布式系統沒有必要 費勁重復造輪子,故隨后的分布式系統中大量應用了zookeeper,以至于zookeeper成為了各種分布式系統的基礎組件,其地位之重要,可想而知。著名的hadoop,kafka,dubbo 都是基于zookeeper而構建。
要想理解zookeeper到底是做啥的,那首先得理解清楚,什么是一致性。
所謂的一致性,實際上就是圍繞著“看見”來的。誰能看見?能否看見?什么時候看見?舉個例子:淘寶后臺賣家,在后臺上架一件大促的商品,通過服務器A提交到主數據庫,假設剛提交后立馬就有用戶去通過應用服務器B去從數據庫查詢該商品,就會出現一個現象,賣家已經更新成功了,然而買家卻看不到;而經過一段時間后,主數據庫的數據同步到了從數據庫,買家就能查到了。
假設賣家更新成功之后買家立馬就能看到賣家的更新,則稱為強一致性;
如果賣家更新成功后買家不能看到賣家更新的內容,則稱為弱一致性;
而賣家更新成功后,買家經過一段時間最終能看到賣家的更新,則稱為最終一致性。
更多的一致性例子可以參考文獻2,里面列舉了10種一致性的例子,如果要給一致性下個定義,可以是分布式系統中狀態或數據保持同步和一致。特別需要注意一致性跟事務的區別,可以記得學習數據庫時特別強調ACID,故而滿足ACID的數據庫能夠做事務,其中C即是一致性,因此,事務是一致性的一種特例,比起一致性更難達成。

如何保證在分布式環境下數據的最終一致,這個就是zookeeper需要解決的問題。對于這些問題,有哪些挑戰,zookeeper又是如何解決這些挑戰的,下一篇文章將會主要涉及這個主題。
一些常見的解決一致性問題的方式:
-
查詢重試補償。對于分布式應用中不確定的情況,先使用查詢接口查詢到當前狀態,如果當前狀態不一致則采用補償接口對狀態進行重試推進,或者回滾接口對業務做回滾。典型的場景如銀行跟支付寶之間的交互。支付寶發送一個轉賬請求到銀行,如一直未收到響應,則可以通過銀行的查詢接口查詢該筆交易的狀態,如該筆交易對方未收到,則采取補償的模式進行推送。
-
定時任務推送。對于上面的情況,有可能一次推送搞不定,于是需要2次,3次推送。不要懷疑,支付寶內最初掉單率很高,全靠后續不斷的定時任務推送增加成功率。
-
TCC。try-confirm-cancel。實際上是兩階段協議,第二階段的可以實現提交操作或是逆操作。
zookeeper到底能做什么?
在業界的實際應用是什么?了解這些應用,會對zookeeper能夠做的事有更直觀的認識。
hadoop:
鼻祖級應用,ResourceManager在整個hadoop中算是單點,為了實現其高可用,分為主備ResourceManager,zookeeper在其中管理整個ResourceManager。
可以想象,主備ResourceManager最初是主RM提供服務,如果一切安好,則zookeeper無用武之地。然而,總歸會出現主RM提供不了服務的情況。于是會出現主備切換的情況,而zookeeper正是為主備切換保駕護航。
先來推理一下,主備切換會出現什么問題。傳統的主備切換,可以讓主備之間維持心跳連接,一旦備機發現主機心跳檢測不到了,則自己切換為主機,原來的主機等待救援。這種方式有兩個問題,一是由于網絡抖動,負載過大等問題,備機檢測不到心跳并不能說明主機一定掛了,有可能一定時間后主機或網絡恢復,這時候主機并不知道備機已經切換為主機,2臺主機互相爭用,可能造成腦裂;二是如果一些數據集中在主機上面,則備機切換時由于同步延時勢必會損失掉一部分的數據。
如何解決這些問題?早期的方式提供了不少解決方案,比如備機一旦切換為主機,則通過電源控制直接切斷主機電源,簡單粗暴,但是此刻備機已經是單點,如果主機是因為量撐不住而掛,那備機有可能會重蹈覆轍,最終導致整個服務不可用。
zookeeper又是如何解決這個問題的呢?
-
zookeeper作為第三方集群參與到主備節點中去,當主備啟動時會在zookeeper上競爭創建一個臨時鎖節點,爭用成功者則充當主機,其余備機
-
所有備機會監聽該臨時鎖節點,一旦主機與zookeeper間session失效,則臨時節點被刪除
-
一旦臨時節點被刪除,備機開始重新申請創建臨時鎖節點,重新爭用為主機;
-
用zookeeper如何解決腦裂?實際上主機爭用到節點后通過對根節點做一個ACL權限控制,則其他搶占的機器由于無法更新臨時鎖節點,只有放棄成為備機。
zookeeper使用了非常簡單又現成的方式來解決的這個問題,比起其他方案方便不少,這也是為啥zookeeper流行的原因。說白了,就是把復雜操作封裝化精簡化
dubbo:
作為業界知名的分布式soa框架,dubbo的主要的服務注冊發現功能便是由zookeeper來提供的。
對于一個服務框架,注冊中心是其核心中的核心,雖然暫時掛掉并不會導致整個服務出問題,但是一旦掛掉,整體風險就很高。考慮一般情況,注冊中心就是單臺機器的時候,其實現很容易,所有機器起來都去注冊服務給它,并且所有調用方都跟它保持長連接,一旦服務有變,即通過長連接來通知到調用方。但是當服務集群規模擴大時,這事情就不簡單了,單機保持連接數有限,而且容易故障。
作為一個穩定的服務化框架,dubbo可以選擇并推薦zookeeper作為注冊中心。其底層將zookeeper常用的客戶端zkclient和curator封裝成為ZookeeperClient。
-
當服務提供者服務啟動時,向zookeeper注冊一個節點
-
服務消費者則訂閱其父節點的變化,諸如啟動停止都能夠通過節點創建刪除得知,異常情況比如被調用方掉線也可以通過臨時節點session 斷開自動刪除得知
-
服務消費方同時也會將自己訂閱的服務以節點創建的方式放到zookeeper
-
于是可以得到映射關系,諸如誰提供了服務,誰訂閱了誰提供的服務,基于這層關系再做監控,就能輕易得知整個系統情況。
zookeeper的基本數據模型
一句話,類似linux文件系統的節點模型
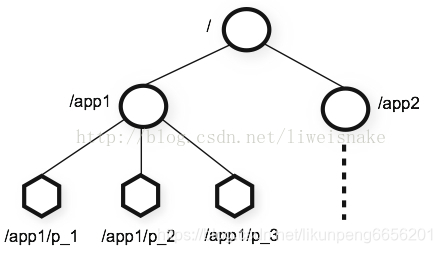
其節點有如下有趣而又重要的特性:
-
同一時刻多臺機器創建同一個節點,只有一個會爭搶成功。利用這個特性可以做分布式鎖。
-
臨時節點的生命周期與會話一致,會話關閉則臨時節點刪除。這個特性經常用來做心跳,動態監控,負載等動作
-
順序節點保證節點名全局唯一。這個特性可以用來生成分布式環境下的全局自增長id
通過zookeeper提供的原語服務,可以對zookeeper能做的事情有個精確和直觀的認識
zookeeper提供的原語服務
-
創建節點。
-
刪除節點
-
更新節點
-
獲取節點信息
-
權限控制
-
事件監聽
實際上,就是對節點的增刪查改加上權限控制與事件監聽,但是通過對這些原語的組合以及不同場景的使用,可以實現很多用法。參考文獻5
-
數據發布訂閱。即注冊中心,見上面dubbo用法。主要通過對節點管理做到發布以及事件監聽做到訂閱
-
負載均衡。見上面kafka用法
-
命名服務。zookeeper的節點結構天然支持命名服務,即把信息集中存儲,并以樹狀管理,方便統一查閱
-
分布式協調通知。協調通知實際上與發布訂閱類似,由于引入的第三方的zookeeper,實際上對很多種協調通知做了解耦,比如參考文獻4中提到的消息推送,心跳檢測等
-
集群管理與master選舉。通過上面的第二點特性,可以輕易得知集群機器存活狀況,從而輕松管理集群;通過上面第一點特性,可以做出master爭搶。
-
分布式鎖。實際上就是第一點特性的應用。
-
分布式隊列。實際上就是第三點特性的應用。
-
分布式的并發等待。類似于多線程的join問題,主任務的執行依賴于其他子任務全部執行完畢,在單機多線程里可以用join,但是分布式環境下如何實現呢。利用zookeeper,可以創建一個主任務節點,旗下子任務一旦執行完畢,則在主任務節點下掛一個子任務節點,等節點數量足夠,則認為主任務可以開始執行。
可以發現,所有的原語就是zookeeper的基礎,而其他的用法總結無非是將原語放到不同場景下的歸類罷了。
相信到這里你對zookeeper應該有個初步的了解和大致的印象了。





![[POI2007]MEG-Megalopolis](http://pic.xiahunao.cn/[POI2007]MEG-Megalopolis)













