如何尋找無序數組中的第K大元素?
有這樣一個算法題:有一個無序數組,要求找出數組中的第K大元素。比如給定的無序數組如下所示:
如果k=6,也就是要尋找第6大的元素,很顯然,數組中第一大元素是24,第二大元素是20,第三大元素是17...... 第六大元素是9。
方法一:排序法
這是最容易想到的方法,先把無序數組從大到小進行排序,排序后的第k個元素自然就是數組中的第k大元素。但是這種方法的時間復雜度是O(nlogn),性能有些差。
方法二:插入法
維護一個長度為k的數組A的有序數組,用于存儲已知的K個較大的元素。然后遍歷無序數組,每遍歷到一個元素,和數組A中的最小元素進行比較,如果小于等于數組A中的最小元素,繼續遍歷;如果大于數組A中的最小元素,則插入到數組A中,并把曾經的最小元素"擠出去"。
比如K=3,先把最左側的7,5,15三個數有序放入到數組A中,代表當前最大的三個數。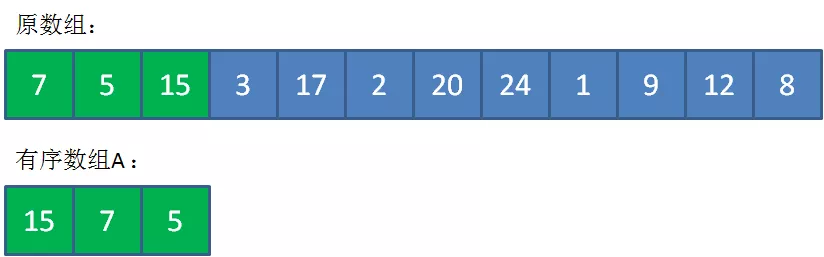
此時,遍歷到3時,由于3<5,繼續遍歷。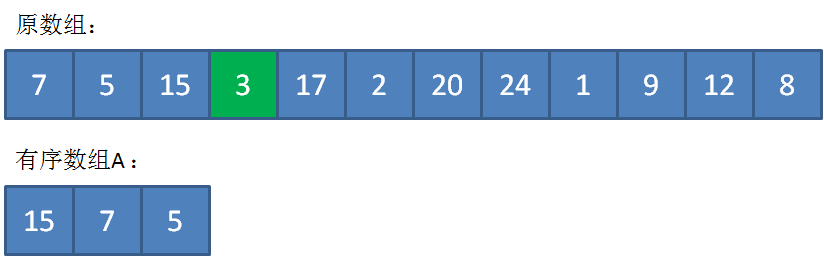
接下來遍歷到17,由于17>5,插入到數組A的合適位置,類似于插入排序,并把原先最小的元素5“擠出去”。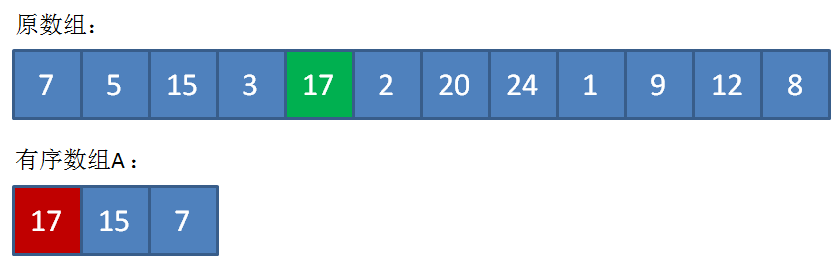
繼續遍歷原數組,一直遍歷到數組的最后一個元素......
最終,數組A中存儲的元素是24,20,17,代表著整個數組的最大的3個元素。此時數組A中的最小元素17就是我們要尋找的第K大元素。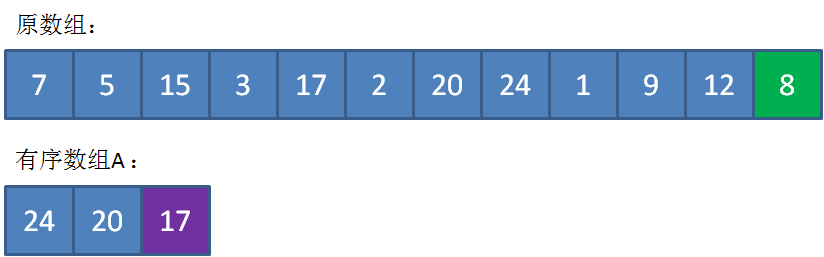
這個方法的時間復雜度是O(nk),但是如果K的值比較大的話,其性能可能還不如方法一。
小頂堆法
二叉堆是一種特殊的完全二叉樹,它包含大頂堆和小頂堆兩種形式。其中小頂堆的特點是每一個父節點都小于等于自己的兩個子節點。要解決這個算法題,我們可以利用小頂堆的特性。
維護一個容量為K的小頂堆,堆中的K個節點代表著當前最大的K個元素,而堆頂顯然是這K個元素中的最小值。
遍歷原數組,每遍歷一個元素,就和堆頂比較,如果當前元素小于等于堆頂,則繼續遍歷;如果元素大于堆頂,則把當前元素放在堆頂位置,并調整二叉堆(下沉操作)。
遍歷結束后,堆頂就是數組的最大K個元素中的最小值,也就是第K大元素。
假設K=5,具體操作步驟如下:
1.把數組的前K個元素構建成堆

2.繼續遍歷數組,和堆頂比較,如果小于等于堆頂,則繼續遍歷;如果大于堆頂,則取代堆頂元素并調整堆。
遍歷到元素2,由于2<3,所以繼續遍歷。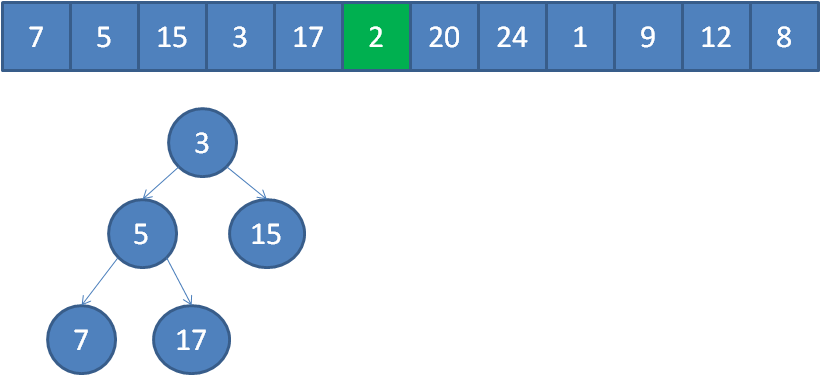
遍歷到元素20,由于20>3,20取代堆頂位置,并調整堆。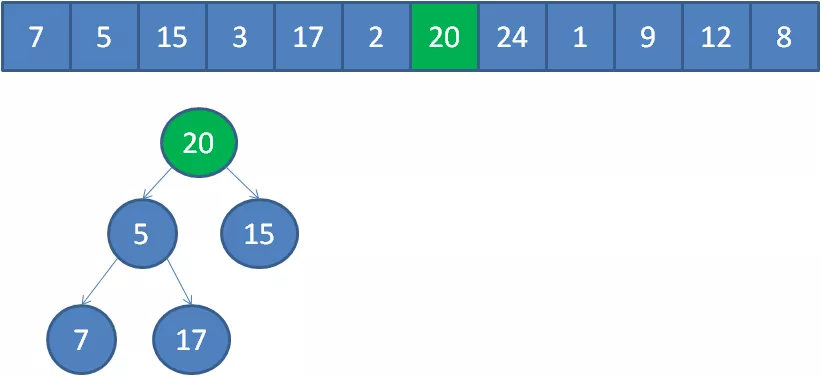

遍歷到元素24,由于24>5,24取代堆頂位置,并調整堆。
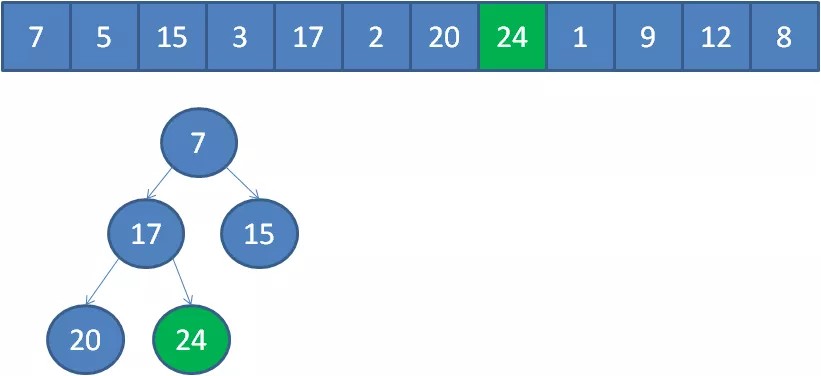
以此類推,我們一個一個遍歷元素,當遍歷到最后一個元素8時,小頂堆的情況如下: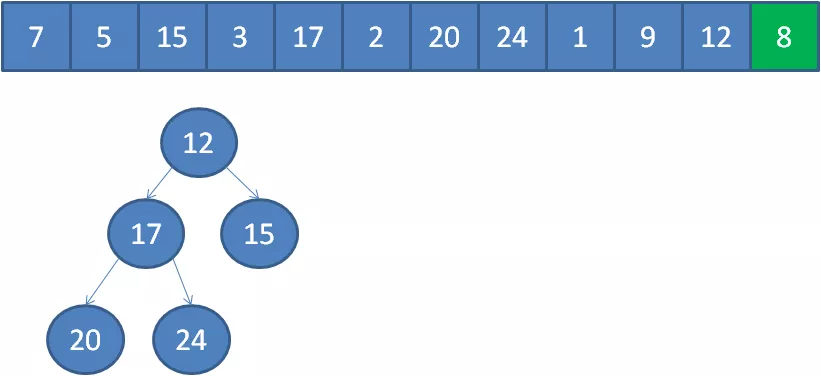
3.此時的堆頂,就是堆中的最小元素,也就是數組中的第K大元素。
這個方法的時間復雜度是多少呢?
1.構建堆的時間復雜度是O(K)
2.遍歷剩余數組的時間復雜度O(n-K)
3.每次調整堆的時間復雜度是O(logk)
其中2和3是嵌套關系,1和2,3是并列關系,所以總的最壞時間復雜度是O((n-k)logk + k)。當k遠小于n的情況下,也可以近似地認為是O(nlogk)。
這個方法的空間復雜度是多少呢?
剛才我們在詳細步驟中把二叉堆單獨拿出來演示,是為了便于理解。但如果允許改變原數組的話,我們可以把數組的前K個元素“原地交換”來構建成二叉堆,這樣就免去了開辟額外的存儲空間。因此空間復雜度是O(1)。
代碼如下:
/*** 尋找第k大元素* @param array 待調整的數組* @param k 第幾大* @return*/public static int findNumberK(int[] array, int k) {//1.用前k個元素構建小頂堆buildHeap(array, k);//2.繼續遍歷數組,和堆頂比較for (int i = k; i < array.length; i++) {if(array[i] > array[0]) {array[0] = array[i];downAdjust(array, 0, k);}}//3.返回堆頂元素return array[0];}private static void buildHeap(int[] array, int length) {//從最后一個非葉子節點開始,依次下沉調整for (int i = (length - 2) / 2; i >= 0; i--) {downAdjust(array, i, length);}}/*** 下沉調整* @param array 待調整的堆* @param index 要下沉的節點* @param length 堆的有效大小*/private static void downAdjust(int[] array, int index, int length) {//temp保存父節點的值,用于最后的賦值int temp = array[index];int childIndex = 2 * index + 1;while (childIndex < length) {//如果有右孩子,且右孩子小于左孩子的值,則定位到右孩子if (childIndex + 1 < length && array[childIndex + 1] < array[childIndex]) {childIndex++;}//如果父節點小于任何一個孩子的值,直接跳出if (temp <= array[childIndex])break;//無需真正交換,單項賦值即可array[index] = array[childIndex];index = childIndex;childIndex = 2 * childIndex + 1;}array[index] = temp;}public static void main(String[] args) {int[] array = new int[] {7, 5, 15, 3, 17, 2, 20, 24, 1, 9, 12, 8};System.out.println(findNumberK(array, 5));}方法四:分治法
大家都了解快速排序,快速排序利用分治法,每一次把數組分成較大和較小元素兩部分。我們在尋找第K大元素的時候,也可以利用這個思路,以某個元素A為基準,把大于A的元素都交換到數組左邊,小于A的元素交換到數組右邊。
比如我們選擇以元素7作為基準,把數組分成了左側較大,右側較小的兩個區域,交換結果如下:
包括元素7在內的較大元素有8個,但我們的K=5,顯然較大元素的數目過多了。于是我們在較大元素的區域繼續分治,這次以元素12為基準:
這樣一來,包括元素12在內的較大元素有5個,正好和K相等。所以,基準元素12就是我們所求的。
這就是分治法的思想,這種方法的時間復雜度甚至優于小頂堆法,可以達到O(n)。
)

?幫你迅速定位代碼位置)


)
![[翻譯]三張卡片幫你記住TDD的基本原則](http://pic.xiahunao.cn/[翻譯]三張卡片幫你記住TDD的基本原則)

)
)









