參考
Reinforcement Learning, Second Edition
An Introduction
By Richard S. Sutton and Andrew G. Barto
強化學習與監督學習
強化學習與其他機器學習方法最大的不同,就在于前者的訓練信號是用來評估(而不是指導)給定動作的好壞的。
強化學習:評估性反饋
有監督學習:指導性反饋
價值函數
最優價值函數,是給定動作 a a a 的期望,可以理解為理論最優
q ? ( a ) ? E [ R t ∣ A t = a ] q_*(a) \doteq\mathbb{E}[R_t|A_t=a] q??(a)?E[Rt?∣At?=a]
我們將算法對動作 a a a 在時刻 t t t 時的價值的估計記作 Q t ( a ) Q_t(a) Qt?(a),我們希望它接近 q ? ( a ) q_*(a) q??(a)
利用(Exploit)與探索(Explore)
利用:選擇最高估計價值的動作(貪心)
探索:選擇非貪心的動作
動作-價值方法(基于價值的方法)
思想:對價值進行估計,來選擇動作。
采樣平均方法
Q t ( a ) ? t 時刻前執行動作 a 得到的收益總和 t 時刻前執行動作 a 的次數 = ∑ i = 1 t ? 1 R i 1 A i = a ∑ i = 1 t ? 1 1 A i = a Q_t(a)\doteq \frac{t時刻前執行動作a得到的收益總和}{t時刻前執行動作a的次數}=\frac{\sum_{i=1}^{t-1} R_i \mathbf{1}_{A_i=a}}{\sum_{i=1}^{t-1} \mathbf{1}_{A_i=a}} Qt?(a)?t時刻前執行動作a的次數t時刻前執行動作a得到的收益總和?=∑i=1t?1?1Ai?=a?∑i=1t?1?Ri?1Ai?=a??
貪心動作選擇
最簡單的動作選擇規則是選擇具有最高估計值的動作,即貪心動作
A t ? arg ? max ? a Q t ( a ) A_{t}\ \doteq \ {\arg \max_a}\ Q_{t}(a) At????argamax??Qt?(a)
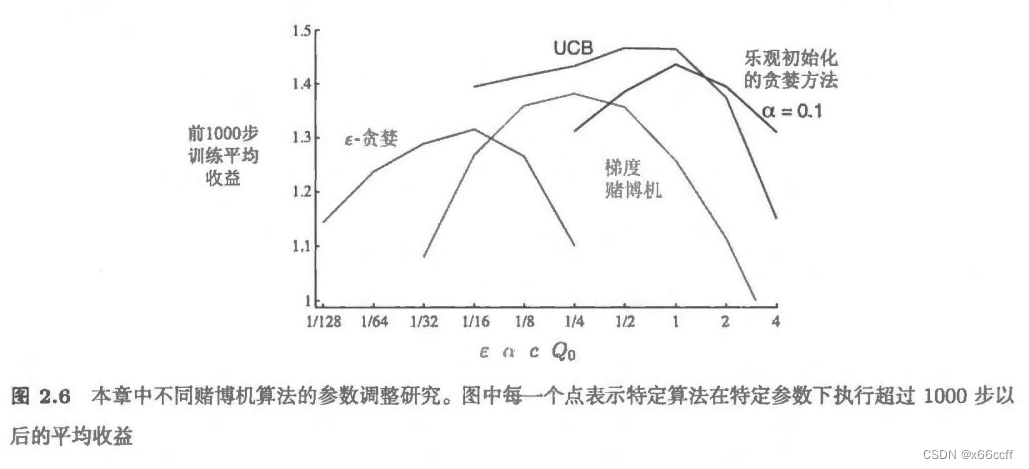
缺點:不能持續探索(雖然可以樂觀初始化在開始階段進行探索)
樂觀初始化:對于純粹貪心策略,可以把每一個初始值 Q 0 ( a ) Q_0(a) Q0?(a)都設置得更大,從而鼓勵算法在算法剛開始的時候嘗試其他狀態。因為一開始獲得獎勵之后都把 Q 0 ( a ) Q_0(a) Q0?(a)降低了。
? \epsilon ?-貪心方法
以小概率 ? \epsilon ?隨機選擇動作, 1 ? ? 1-\epsilon 1?? 貪心選擇
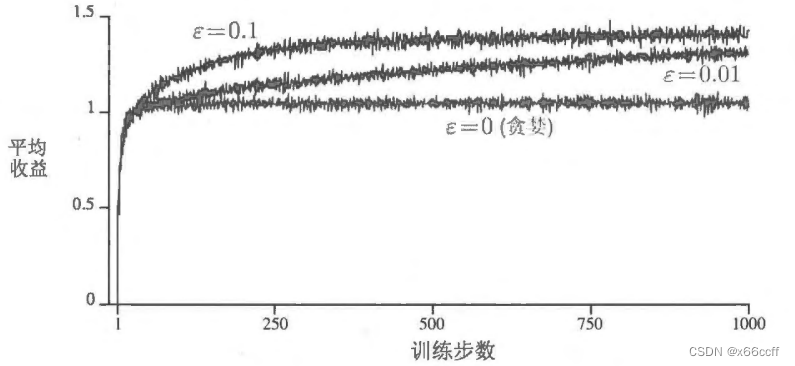

兩者都并不是完美的
貪心動作雖然在當前時刻看起來最好,但實際上其他一些動作可能從長遠看更好
? \epsilon ?-貪心算法會嘗試選擇非貪心的動作,但是這是一種盲目的選擇,因為它不大會去選擇接近貪心或者不確定性特別大的動作
增量更新、平穩/非平穩問題
為了計算效率,采用增量更新:
Q n + 1 = Q n + 1 n [ R n ? Q n ] Q_{n+1} = Q_n + \frac{1}{n}[R_n - Q_n ] Qn+1?=Qn?+n1?[Rn??Qn?]
此時 α = 1 n \alpha = \frac{1}{n} α=n1?,適合平穩分布的問題,但是如果 bandit 背后的分布是會變化的,那么 α \alpha α 應該采用 > 1 n >\frac{1}{n} >n1? ,從而給更靠近的獎勵更大的權重。
UCB
置信度上界 (upper confidence bound, UCB)——平衡了 探索與利用
A t ? a r g max ? a [ Q t ( a ) + c ln ? t N t ( a ) ] A_{t}\ \doteq \ {\mathrm{arg}}\max_a\left[Q_{t}(a)+c\sqrt{\frac{\ln t}{N_{t}(a)}}\,\right] At????argamax?[Qt?(a)+cNt?(a)lnt??]
左邊:利用平均獎勵大的動作
右邊:鼓勵探索訪問次數少的動作,但是同時要考慮到其他非 a a a 的狀態的訪問次數,用 t t t近似。每次選 a a a之外的動作時,在分子上的 ln ? t \ln t lnt增大,而 N t ( a ) N_t(a) Nt?(a) 卻沒有變化,所以不確定性增加了
UCB一般來說比貪心、 ? \epsilon ?-貪心 要好。
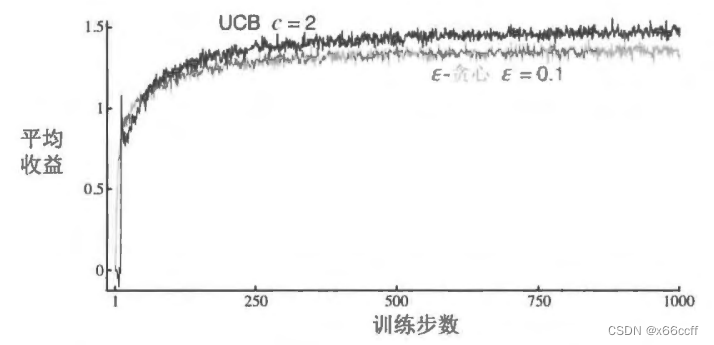
UCB 的缺點:
- 處理非平穩問題時,需要一些更復雜的 tricks, 不能僅僅使用這樣的策略。
- 處理不了很大的狀態空間。
上下文賭博機(Contextual Bandit)
普通的賭博機:算法每一次選擇新動作的時候,沒有額外的環境信息。
上下文賭博機:算法每一次選擇新動作的時候,有額外的環境信息。
也許你面對的是一個真正的老虎機、它的外觀顏色與它的動作價值集合一一對應,動作價值集合改變的時候,外觀顏色也會改變.那么,現在你可以學習一些任務相關的操作策略,例如,用你所看到的顏色作
為信號,把每個任務和該任務下最優的動作直接關聯起來,比如,如果為紅色, 則選擇1號臂 ;如果為綠色,則選擇2號臂。有了這種任務相關的策略,在知道任務編號信息時,你通常要比不知道任務編號信息時做得更好。
——《RL》
上下文賭博機介于多臂賭博機問題和完整強化學習問題之間。它與完整強化學習問題的相似點是,它需要學習一種策略,但它又與多臂賭博機問題相似,體現在每個動作只影響即時收益。
總結
在多臂賭博機問題來說,一般來說,UCB是比貪心, ? \epsilon ?-貪心更好的




應用開發——保存應用數據)

)



)

![[cleanrl] ppo_continuous_action源碼解析](http://pic.xiahunao.cn/[cleanrl] ppo_continuous_action源碼解析)
-防止k8s namespace被誤刪除)


)

)
