你可能對 torch 上的某些函數感到困惑,它們執行相同的操作但名稱不同。 例如:?reshape()、view()、permute()、transpose()?等。
這些函數的做法真的不同嗎? 不! 但為了理解它,我們首先需要了解一下張量在 pytorch 中是如何實現的。
NSDT工具推薦:?Three.js AI紋理開發包?-?YOLO合成數據生成器?-?GLTF/GLB在線編輯?-?3D模型格式在線轉換?-?可編程3D場景編輯器?-?REVIT導出3D模型插件?-?3D模型語義搜索引擎
張量(tensor)是抽象或邏輯結構,就像數組一樣,無法按照其設想的方式實現。 顯而易見的原因是內存單元是連續(contiguous)的,因此我們需要找到一種方法將它們保存在內存中。 例如,如果我們有一個如下所示的二維張量(或數組):
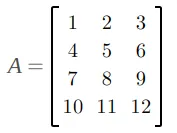
將其保存到內存中的正常(或連續)方式是逐行排列。 所以我們將有:

每個張量都有元數據來聲明如何讀取張量。 例如,在這個 2d 張量中,為了訪問下一行,我們必須向前移動 3 步,而下一列我們應該向前移動 1 步。 我們稱這兩個數字為步幅(stride)。 所以我們可以像下面這樣提取它們:

這為我們開辟了新的可能性,因為們可以通過改變步幅元數據來改變張量! 例如,如果我們將步長從(3, 1)?更改為(1, 3),我們實際上轉置了矩陣,而無需對所有內存項進行任何操作:

正如你所注意到的,張量不再連續,因為我們更改了它!為了轉到下一行,我們只需跳過 1 個值,而跳過3 個值則移動到下一列。
如果我們回想一下張量的內存布局,這是有道理的:
[0, 1, 2, 3, 4, …, 11]為了移動到下一列(例如從0到3,我們必須跳過 3 個值。因此張量不再是連續的!要使其連續,只需對其調用contigously()即可:

當你調用contigious()時,它實際上會創建張量的副本,因此元素的順序將與從頭開始創建相同形狀的張量相同。
請注意,“連續”這個詞有點誤導,因為它并不是張量的內容分布在斷開連接的內存塊周圍。 這里字節仍然分配在一塊內存中,但元素的順序不同!
同樣,視圖函數?view()只是原始變量的視圖,這意味著如果更改原始內存,它也會發生變化:

這實際上非常有效,因為我們不必為轉換創建新的內存槽。 但?reshape()可以復制原始數據。 來自原始文檔:
連續輸入和具有兼容步幅的輸入可以在不復制的情況下進行重塑,但你不應依賴于復制與查看行為。
例如,如果我們有如下代碼:

運行輸出結果如下:
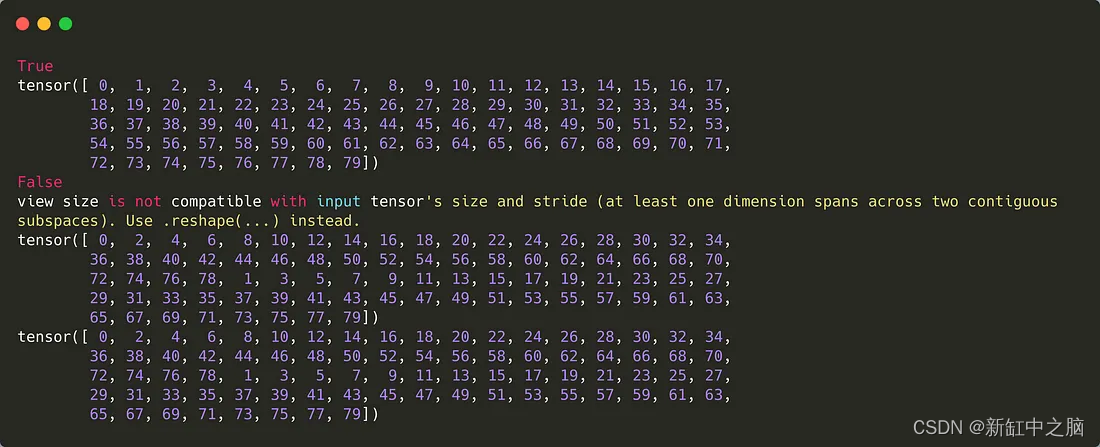
該視圖不適用于非連續數據。
另外,考慮到?permute()?是另一個僅適用于元數據的函數,因此它也會創建不連續的數據。?permute()?改變軸的順序,因此它與改變矩陣形狀的?view()?或?reshape()?完全不同。
原文鏈接:Pytorch張量內存布局 - BimAnt







![奧威亞視頻云平臺VideoCover.aspx 接口任意文件上傳漏洞復現 [附POC]](http://pic.xiahunao.cn/奧威亞視頻云平臺VideoCover.aspx 接口任意文件上傳漏洞復現 [附POC])
——什么問題適合使用卡方檢驗?)


| 數據庫概述、基本概念、關系型數據庫特點、超鍵候選碼等)







