目錄
- 概述
- 配置
- 關鍵配置
- 測試
- 啟動 kyuubi
- 執行配置中的命令
- bug解決
- bug01
- bug02
- 結束
概述
目標:生產中有需要外部源數據做paimon的數據源,生成臨時表,以使用與現有正式表做相關統計及 join 操作。
環境:各組件版本如下
- kyuubi 1.8.0
- flink 1.17.1
- paimon 0.5 正式版本
- hive 3.1.3
閱讀此文前,需涉及前置的知識點如下
- kyuubi整合flink yarn application model
配置
概述:臨時表 paimon 此版本僅 Flink支持。與外部表一樣,臨時表只是記錄的,而不是由當前Flink SQL會話管理的。如果刪除臨時表,則不會刪除其資源。當 Flink SQL 會話關閉時,臨時表也會被丟棄。
如果您想將 Paimon catalog與其他表一起使用,但不想將它們存儲在其他的 catalog 中,可以創建一個臨時表。下面的關鍵配置 Flink SQL 創建了一個 Paimon catalog 和一個臨時表,并進行了測試。
關鍵配置
來看一些關鍵配置,其它配置如有疑問,請參考 kyuubi整合flink yarn application model
CREATE CATALOG paimon_hive WITH ('type' = 'paimon','metastore' = 'hive','uri' = 'thrift://10.xx.xx.22:9083','warehouse' = 'hdfs:///data/hive/warehouse/paimon','default-database'='tmp'
);CREATE TEMPORARY TABLE test (UnitId STRING,WorkOrder STRING
) WITH ('connector' = 'filesystem','path' = 'hdfs:///data/hive/warehouse/tmp/Small.csv','format' = 'csv'
);SET execution.runtime-mode=batch;select * from test;
使用的 csv 文件如下,學習時,可以自己創建測試內容

測試
啟動 kyuubi

執行配置中的命令
執行配置中的命令,幾條命令依次執行如下圖:
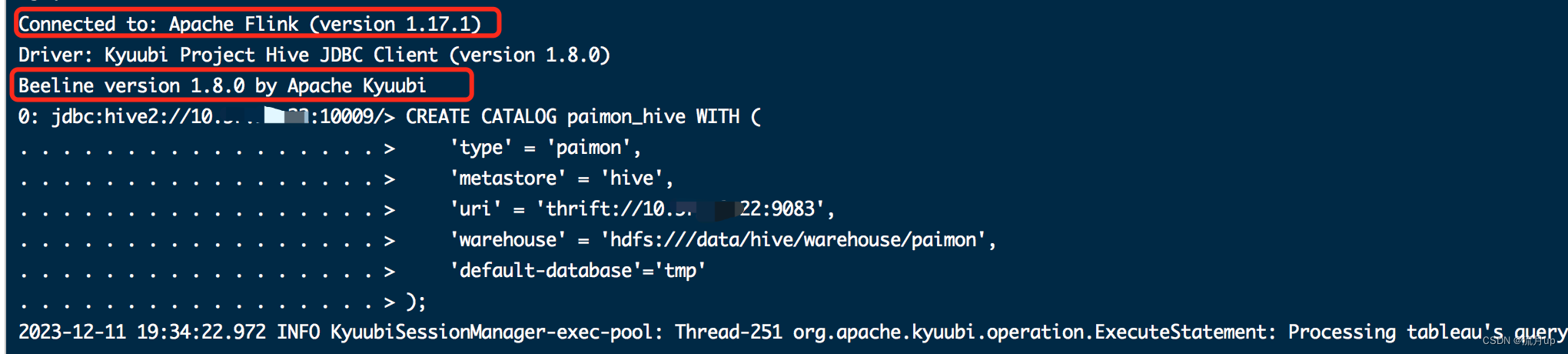
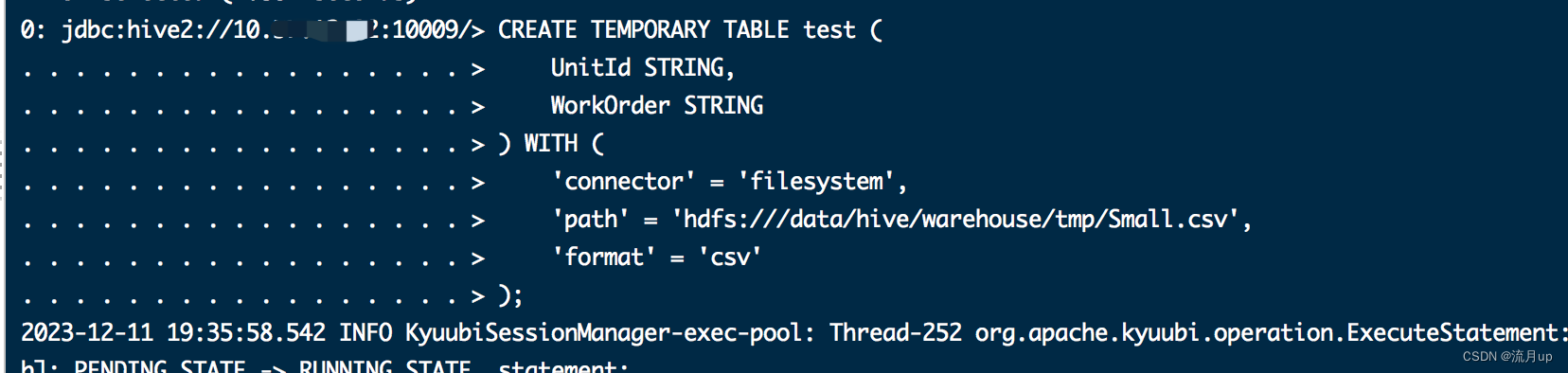


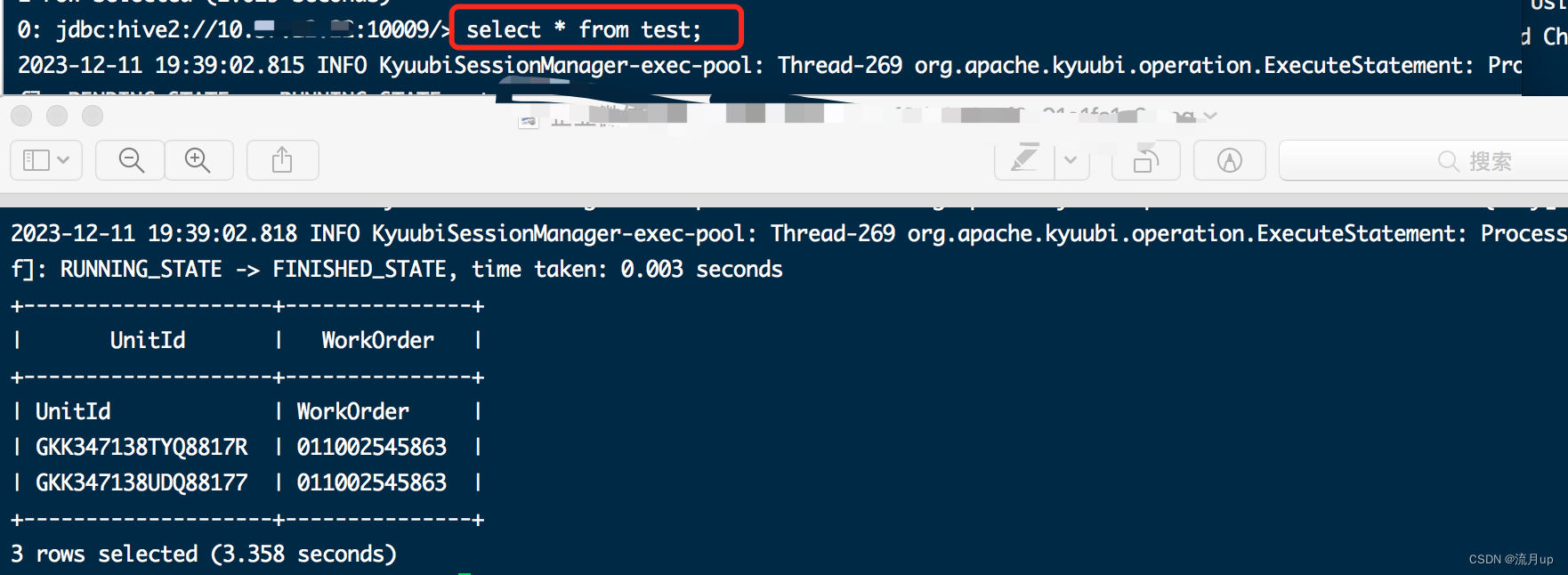
bug解決
坑隨時都有,下面解決一下測試過程的bug。
bug01
來圖如下:
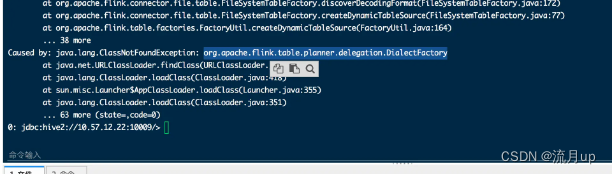
一看缺失類,老套路,看看是哪個包下的,添加至 flink 1.17.1 下面的 lib 下。

bug02
重新啟動時,報有重復類,沖突了
這個以前解決過,直接上解決方案。如下圖:

這兩個解決之后,就按上文中 測試 流程走就可以了。
結束
以csv為源 flink 創建paimon 臨時表相關 join 操作 ,至此就結束了。如有疑問,歡迎評論區留言。
:numpy科學計算庫)
 基礎)


![[筆記] 使用 qemu/grub 模擬系統啟動(單分區)](http://pic.xiahunao.cn/[筆記] 使用 qemu/grub 模擬系統啟動(單分區))


)

)






 字節碼文件)

的實現)
