概述
28s應用崩潰查看內存使用有大量cache。
分析
- 查看free 信息平時的確存在大量cache使用的情況

- 查看dmes信息發現filesendserver崩潰

崩潰信息為系統調用 ?查看到page allocation failure:order 5
- 同時也看到系統內存使用情況

查看到系統實際還有部分內存為空閑內存,但是觀察mode 0 Nornal 內存中有部分連續內存頁使用完了。而恰巧重新申請的是order 為5的內存,查看內核中__get_free_pages()函數對于系統內存分配說明order參數是系統要分配的2的order次方的數量的連續內存頁申請,這里對應的就是2的5次方4k連續內存頁128kb內存的申請。因此應用崩潰的原因為,系統內存碎片化導致的。
- ?同時還觀察到系統find進程異常

同樣查看內存使用情況為申請2的8次方4k連續內存頁1024kb內存的申請同樣查看為內存沒有。
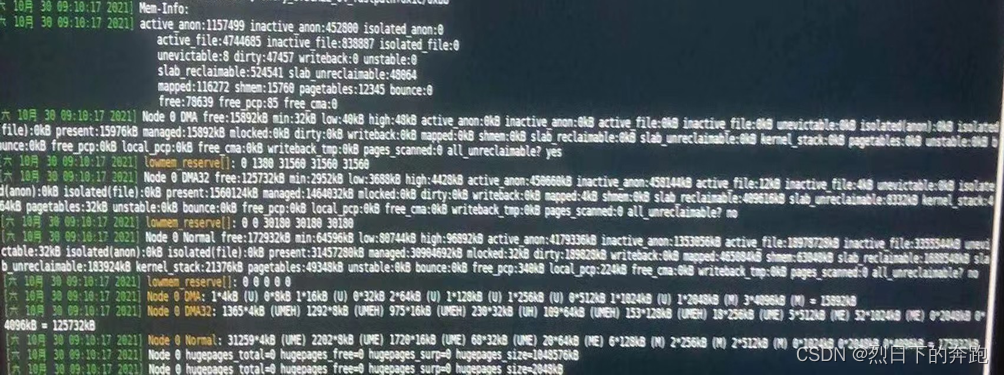
- 內存碎片化嚴重有2種解決思路
1 找到大量吃cache的進程進行程序的優化
2 調整系統預留內存修改vm.min_free_kbytes = 1153434
關于系統內存有pages_high? pages_low? pages_min 3條水位線

大概的關系換算關系的是
watermark[min] = per_zone_min_free_pages (min_free_kbytes換算為page單位)
watermark[low] = watermark[min] * 5 / 4
watermark[high] = watermark[min] * 3 / 2
系統內存使用達到pages_low才會開始回升cache,vm.min_free_kbytes可根據系統物理內存進行調節。
- 針對第一步情況我們進行了進一步的排查,通過腳本監控iotop信息發現find程序有長時間的讀寫操作。

和上面應用出現異常同時find程序異常相對應。同時觀察到時間得到每天的9點5分開始 9點55多還在運行,同時查看syslog日志每天的9點5只有corn.daily執行。

查看到locate比較像每天會執行一次updatedb。手動運行updatedb命令發現ps查看的一模一樣。updatedb主要用于生產系統所有文件的路徑和文件名索引。
結論
查看了 df -h系統有大概220g的文件,該問題是由于系統updatedb命令在執行find遍歷系統所有文件是占用了大量的buff導致的系統內存碎片化最終使得應用奔潰。
用戶最終采取了以下措施解決該問題
- 刪除了locate 定時任務
- 修改了vm.min_free_kbytes = 1153434
- 修改了/etc/crontab文件修改了每日定時任務的啟動時間

![[筆記] 使用 qemu/grub 模擬系統啟動(單分區)](http://pic.xiahunao.cn/[筆記] 使用 qemu/grub 模擬系統啟動(單分區))


)

)






 字節碼文件)

的實現)



