近日,阿里云人工智能平臺PAI與華東師范大學數據科學與工程學院合作在自然語言處理頂級會議EMNLP2023上發表基于雙曲空間和對比學習的垂直領域預訓練語言模型。通過比較垂直領域和開放領域知識圖譜數據結構的不同特性,發現在垂直領域的圖譜結構具有全局稀疏,局部稠密的特點。為了補足全局稀疏特點,將垂直領域中分層語義信息通過雙曲空間注入到預訓練模型中。為了利用局部圖結構稠密特點,我們利用對比學習構造圖結構不同難度的正負樣本來進一步加強語義稀疏的問題。
論文:
Ruyao Xu, Taolin Zhang, Chengyu Wang, Zhongjie Duan, Cen Chen, Minghui Qiu, Dawei Cheng, Xiaofeng He, Weining Qian. Learning Knowledge-Enhanced Contextual Language Representations for Domain Natural Language Understanding. EMNLP 2023
背景
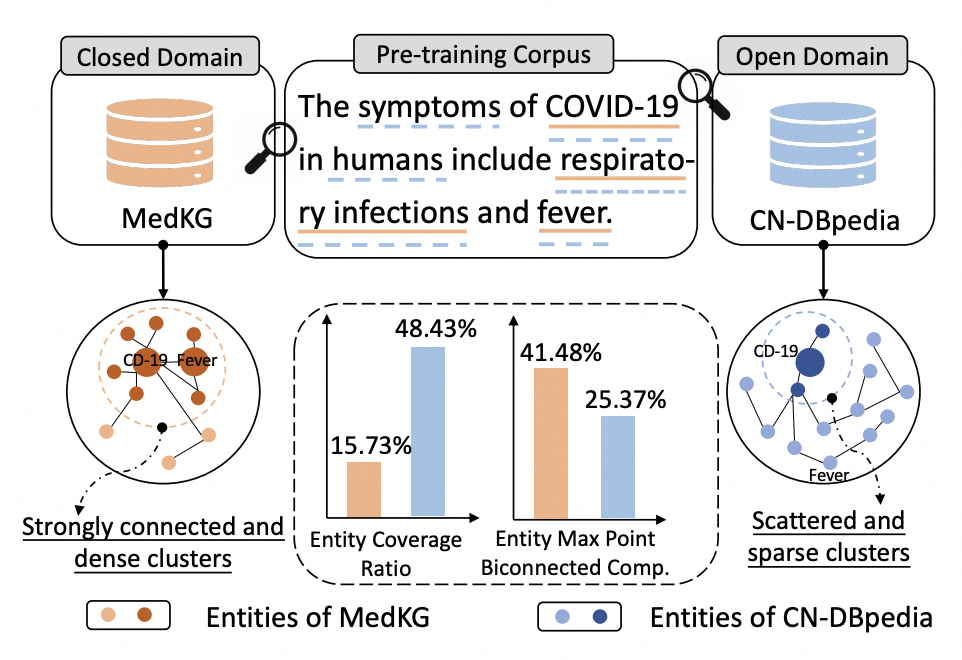
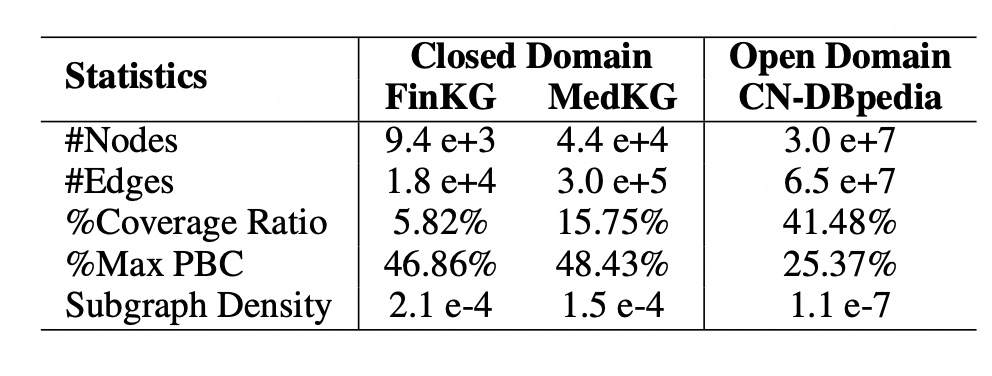
知識增強預訓練語言模型(KEPLM)通過從大規模知識圖(KGs)中注入知識事實來提高各種下游NLP任務的性能。然而,由于缺乏足夠的域圖語義,這些構建開放域KEPLM的方法很難直接遷移到垂直領域,因為它們缺乏對垂直領域KGs的特性進行深入建模。如下圖所示,KG實體相對于純文本的覆蓋率在垂直領域中明顯低于開放域,表明領域知識注入存在全局稀疏現象。這意味著將檢索到的少數相關三元組直接注入到PLM中對于領域來說可能是不夠的。我們進一步注意到,在垂直領域KGs中,最大點雙連通分量的比率要高得多,這意味著這些KGs中同一實體類下的實體相互連接更緊密,并表現出局部密度特性。因此,本文研究是基于上述領域KG的數據特性提出了一個簡單但有效的統一框架來學習各種垂直領域的KEPLM。
算法概述
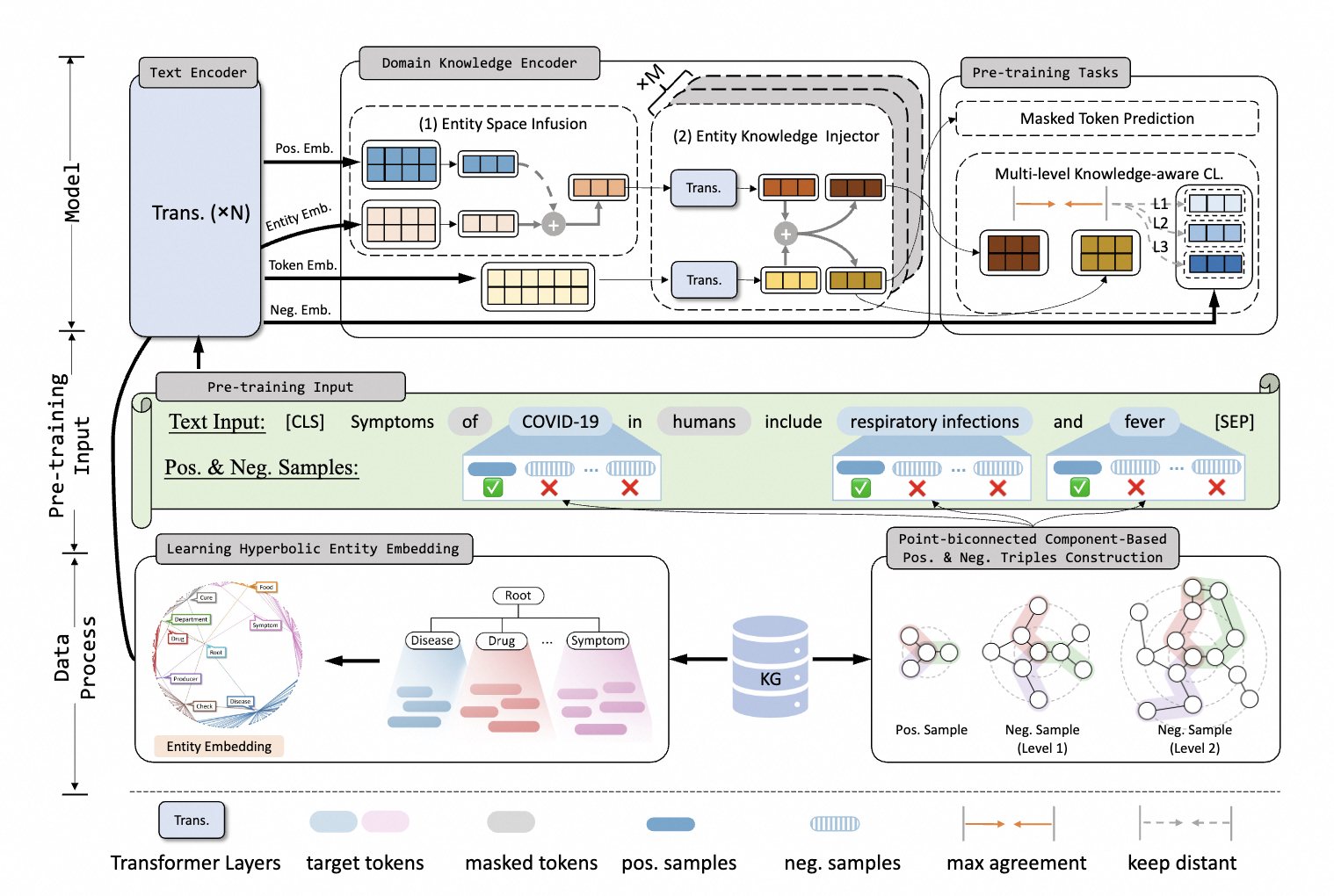
為了解決上述垂直領域知識增強框架的問題,KANGAROO模型分別通過雙曲空間學習垂直領域圖譜數據的分層語義信息來補充全局語義稀疏模塊Hyperbolic Knowledge-aware Aggregator,通過捕捉領域圖譜稠密的圖結構構造基于點雙聯通分量的對比學習模塊Multi-Level Knowledge-aware Augmenter,模型框架圖如下所示:
Hyperbolic Knowledge-aware Aggregator
Learning Hyperbolic Entity Embedding
首先,歐幾里得空間中的嵌入算法由于嵌入空間的維度而難以對復雜模式進行建模。受龐加萊球模型的啟發,由于重建的有效性,雙曲空間對層次結構具有更強的代表能力,為了彌補閉域的全局語義不足,我們采用Poincaréball模型來同時學習基于層次實體類結構的結構和語義表示。兩個實體(ei,ej)之間的距離為:
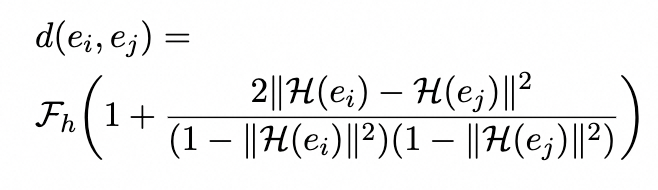
我們定義D={r(ei,ej)}是同義實體。然后我們最小化相關對象之間的距離以獲得雙曲嵌入
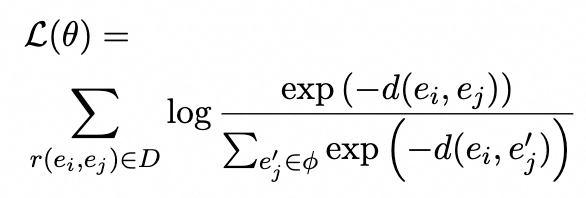
Domain Knowledge Encoder
該模塊設計用于對輸入token和實體進行編碼,并融合它們的異構嵌入,包含兩部分:Entity Space Infusion 和 Entity Knowledge Injector。
Entity Space Infusion
為了將雙曲嵌入集成到上下文表示中,我們通過級聯將實體類嵌入注入到實體表示中:
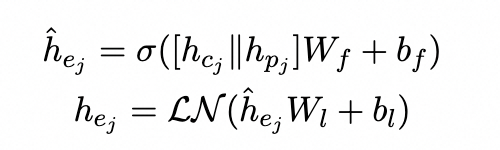
Entity Knowledge Injector
它旨在融合實體嵌入{hej}m的異構特征。為了匹配來自領域KGs的相關實體,我們采用重疊單詞數量大于閾值的實體。利用M層聚合器作為知識注入器,能夠集成不同級別的學習融合結果。在每個聚合器中,兩個嵌入都被輸送到多頭注意力層:
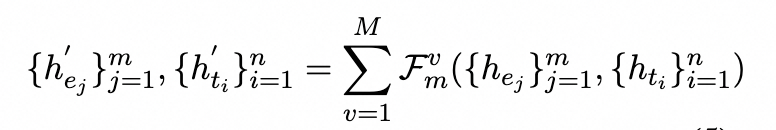
我們將實體嵌入注入上下文感知表示中,并從混合表示中重新獲取它們:
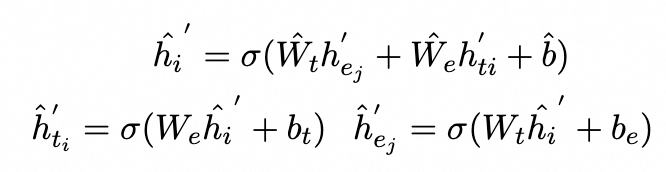
Multi-Level Knowledge-aware Augmenter
它使模型能夠學習注入的知識三元組的更細粒度的語義關系,利用圖譜局部結構特征來進一步糾正全局稀疏性問題。我們著重于通過點雙連通分量子圖結構構造具有多個難度級別的高質量正樣本和負樣本。示例構造流程如下圖所示。
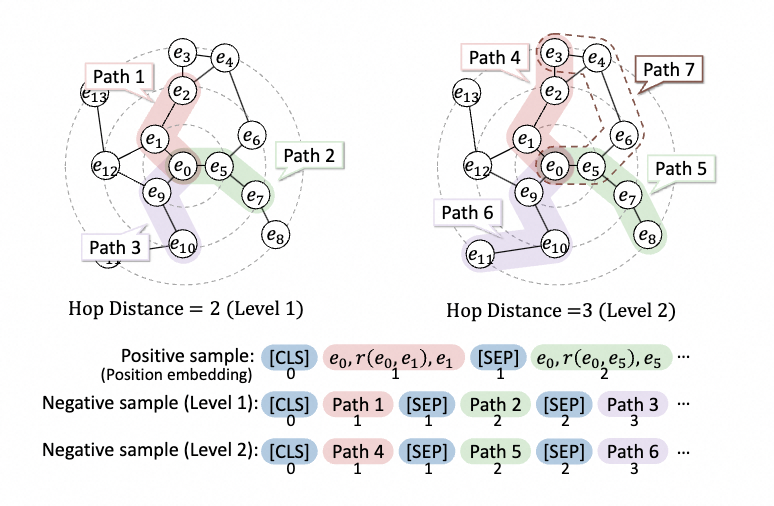
Positive Sample Construction
我們提取目標實體的K個相鄰三元組作為正樣本,它們在相鄰候選子圖結構中最接近目標實體。這些三元組中包含的語義信息有利于增強上下文知識。為了更好地聚合目標實體和上下文標記表示,將K個相鄰三元組轉換后拼接到一個句子中。通過共享的文本編碼器(例如BERT)獲得統一的語義表示。由于來自離散實體和關系的不同三元組的采樣之間存在語義不連續性,我們修改位置嵌入,使相同三元組的標記共享相同的位置索引,反之亦然。例如,上圖中輸入標記的三元組位置(e0,r(e0、e1)、e1)均為1。為了統一表示空間,我們采用[CLS](即BERT中的輸入格式的token)表示為正樣本嵌入以表示樣本序列信息。
Point-biconnected Component-based Negative Sample Construction
在領域KGs中,由于具有有利于圖的局部稠密性質,節點與相鄰節點是稠密連接的搜索。因此,我們搜索大量距離目標實體更遠的節點作為負樣本。
- 第一步:以起始節點Estart(即e0)為中心點,沿著這些relation向外進行搜索,我們得到了具有不同hop(P(G,estart,eend))的端節點Eend,其中hop(·)表示跳距,P(G,ei,ej)表示圖G中實體之間的最短路徑。例如,路徑3中的跳躍點(P(G,e0,e10))=2,路徑6中的躍點數(P(G,e0、e11))=3
- 我們利用跳躍距離來構建具有不同結構難度水平的負樣本,其中,對于1級樣本,hop(·)=2,對于n級樣本,hop(·)=n+1。我們假設跳躍距離越近,就越難區分三元組與起始節點之間包含的語義知識。
- 負樣本的構造模式類似于正樣本,正樣本具有相同距離的路徑被合并成句子。注意,當節點對包含至少兩條不相交的路徑(即點雙連通分量)時,我們選擇最短路徑(例如,路徑4)。對于每個實體,我們構建k個級別的負樣本。
Training Objectives
我們模型的損失函數主要包含了兩個部分,一個是普通token級別的MLM掩碼任務,另外一個是基于點雙聯通分量的對比學習任務。
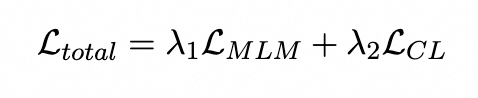
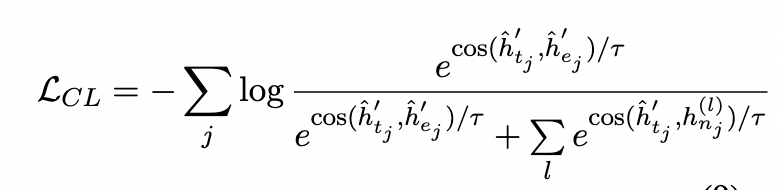
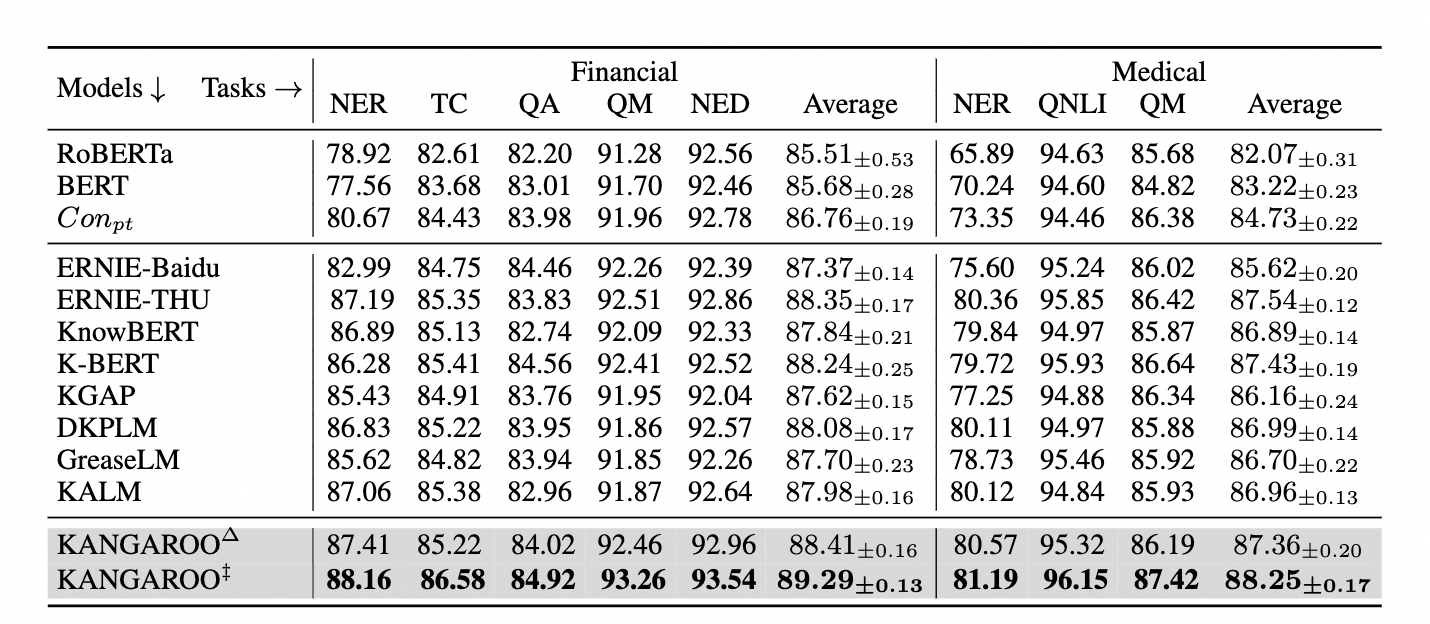
算法精度評測
為了評估KANGAROO模型在垂直領域預訓練模型的效果,我們選取了金融和醫療等領域的各種下游任務的全數據量和少樣本數據量場景進行評測。
- 全數據量微調實驗結果
- 少樣本數據微調數據結果

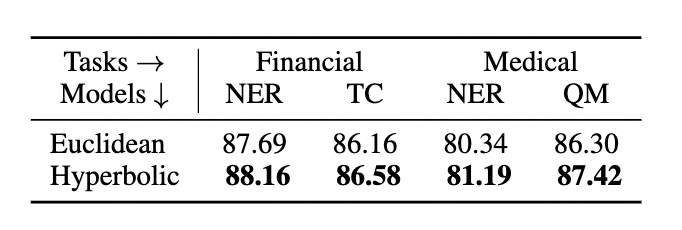
為了比較不同圖譜數據表示方法的效果不同,我們對比了歐式距離和雙曲距離之間的結果如下:
為了更好地服務開源社區,KANGAROO算法的源代碼即將貢獻在自然語言處理算法框架EasyNLP中,歡迎NLP從業人員和研究者使用。
EasyNLP開源框架:GitHub - alibaba/EasyNLP: EasyNLP: A Comprehensive and Easy-to-use NLP Toolkit
參考文獻
- Chengyu Wang, Minghui Qiu, Taolin Zhang, Tingting Liu, Lei Li, Jianing Wang, Ming Wang, Jun Huang, Wei Lin. EasyNLP: A Comprehensive and Easy-to-use Toolkit for Natural Language Processing. EMNLP 2022
- Zhengyan Zhang, Xu Han, Zhiyuan Liu, Xin Jiang, Maosong Sun, and Qun Liu. 2019. ERNIE: enhanced language representation with informative entities. In ACL, pages 1441–1451.
- Xiaozhi Wang, Tianyu Gao, Zhaocheng Zhu, Zhengyan Zhang, Zhiyuan Liu, Juanzi Li, and Jian Tang. 2021. KEPLER: A unified model for knowledge embedding and pre-trained language representation.Trans. Assoc. Comput. Linguistics, 9:176–194.
- Yusheng Su, Xu Han, Zhengyan Zhang, Yankai Lin, Peng Li, Zhiyuan Liu, Jie Zhou, and Maosong Sun. 2021. Cokebert: Contextual knowledge selection and embedding towards enhanced pre-trained language models. AI Open, 2:127–134
論文信息
論文標題:Learning Knowledge-Enhanced Contextual Language Representations for Domain Natural Language Understanding
論文作者:徐如瑤、張濤林、汪誠愚、段忠杰、陳岑、邱明輝、程大偉、何曉豐、錢衛寧
論文pdf鏈接:https://arxiv.org/abs/2311.06761





)



)









