目錄
一、線程池的由來
二、線程池的簡單介紹
1、ThreadPoolExecutor類
(1)核心線程數和最大線程數:
(2)保持存活時間和存活時間的單位
(3)放任務的隊列
(4)線程工廠
(5)拒絕策略
2、Executors類
3、線程池的執行流程
4、討論線程池中創建多少線程合適
三、線程池的模擬實現
(1)阻塞隊列:存放要執行的任務
(2)submit方法:添加任務的方法,任務添加到隊列中
(3)構造方法:指定創建多少個線程,線程在這個構造方法中都創建好了
(4)存放線程的鏈表:每創建一個線程都放進鏈表中,這樣也能讓我們找到某個線程
(5)最終代碼( + 測試用例)
都看到這了,點個贊再走吧,謝謝謝謝謝
一、線程池的由來
最開始,進程可以解決并發編程的問題,但是這個代價太大了,于是引入了 “輕量級進程” :線程
線程也能解決并發編程的問題,而且線程的開銷比進程要小的多,但是線程如果太多了,創建銷毀線程的頻率進一步提高,此時的線程創建銷毀的開銷就不能忽視了。
為了解決上述問題,大佬們給出了兩個解決方案:
(1)引入 “輕量級線程”:纖程 / 協程
? ? ? ? 協程的本質是程序猿在用戶態代碼中進行調度,不是靠內核的調度器調度的,這樣就節省了很多開銷;協程是在用戶代碼中,基于線程封裝出來的,可能是N個協程對應1個線程,也可能是N個協程對應M個線程。
(2)引入 “線程池”
? ? ? ? 線程池的概念:創建一個線程,這個線程執行完,不會把這個線程給銷毀,而是把這個線程放到線程池中,當我們需要用這個線程的時候,再從線程池中拿,不需要的時候,就放在線程池中,并不會銷毀它;這樣,就省去了頻繁的創建銷毀線程了。
為啥從線程池中取線程 比 從系統中申請線程的創建更高效呢?
? ? ? ? 舉個栗子:
假設在銀行場景中,滑稽老鐵要去這個銀行辦理一個業務,一般銀行中大堂有復印機;這時,滑稽老鐵沒有帶身份證復印件,此時滑稽老鐵要去搞到身份證復印件,有兩個選擇,其一選擇:把身份證給柜員,讓柜員幫滑稽老鐵復印,但是這個操作是不可控的,可能這個柜員中途被老板安排了其他活,那這個時候,就不能幫滑稽老鐵復印身份證了,要等忙完老板安排的活,再幫滑稽老鐵復印身份證;其二選擇:滑稽老鐵自己去大堂中復印身份證,這樣就比較可控了,滑稽老鐵可以很快的去到打印機,立馬復印出來,再去辦理他的業務。如圖:

這里的大堂就是用戶態,柜臺就是內核態,從線程池中取線程,是純用戶態代碼(可控)? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ???通過系統申請創建線程,需要內核完成(不可控)
二、線程池的簡單介紹
1、ThreadPoolExecutor類
ThreadPoolExecutor參數最多的構造方法,明白了這個構造方法,其他構造方法的參數也就都明白了,如圖:

(1)核心線程數和最大線程數:
corePoolSize核心線程數:正式員工線程
maximumPoolSize最大線程數:正式員工線程 + 實習員工線程
????????舉個栗子:一個公司中有10個正式員工,這10個正式員工是不能隨便開除的,當這10個正式員工忙不過來的時候,公司為了降低成本,會招聘實習員工,而這幾個實習員工是可以隨便開除的,當公司穩定一段時間不忙后,就會開除幾個實習員工。

(2)保持存活時間和存活時間的單位
KeepAliveTime保持存活時間:實習生線程允許摸魚的最大時間
unit存活時間的單位:可以是hour 、 min 、 s 、 ms


(3)放任務的隊列
和定時器類似,線程池中也可以持有多個任務,要執行的任務,使用Runnable來描述任務。

(4)線程工廠
通過這個工廠類創建線程對象(Thread對象),工廠類里面有方法封裝了new Thread的操作,同時給Thread設置了一些屬性,我們想要創建線程的時候可以直接使用工廠類的方法創建。
舉個栗子:
描述一個點,可以用二維坐標和極坐標來表示:二維坐標:(x,y) 極坐標:(r,α)
這里,通過new一個類來得到一個點,這個類里有兩個構造方法,參數分別是(double x,double y),(double r,double α),那么這兩個構造方法的參數類型都一樣,構成不了重載,如圖:
那我們就改方法名不就好了,在使用static修飾,通過不同的方法名獲取類,在方法里new一個類,里面設置一些參數,再返回這個類,如圖:
這樣的的類,就稱為工廠類,工廠類里面得到類的方法就稱為工廠方法。
總的來說,通過靜態方法new了一個對象,在這個靜態方法設置不同的屬性,構造對象的過程,就稱為工廠模式。



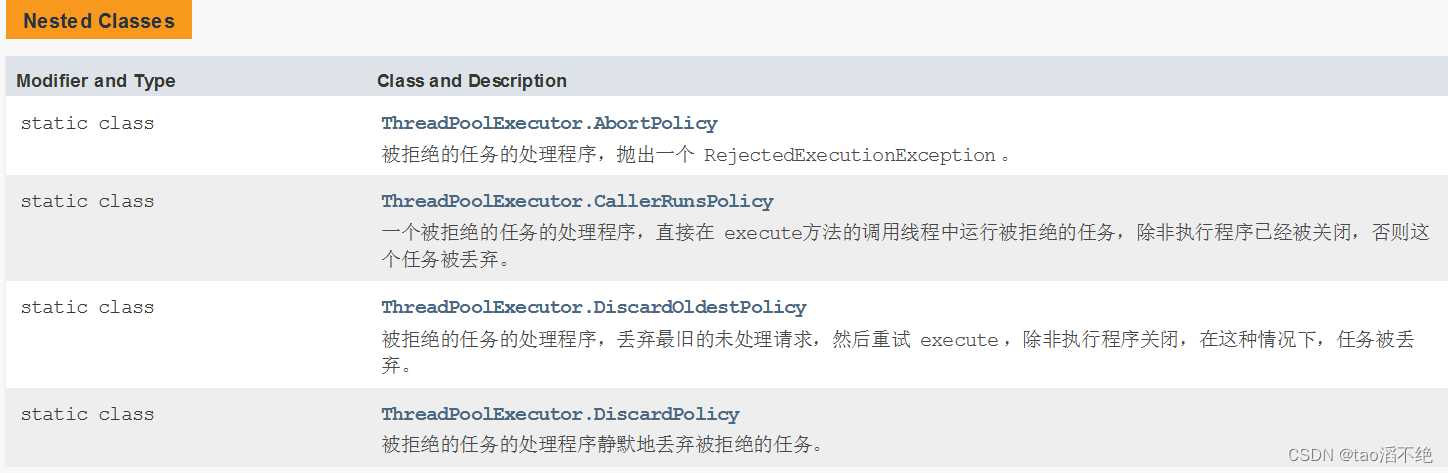
(5)拒絕策略
在線程池中有一個阻塞隊列,這個隊列容納線程有上限,如果這個任務隊列滿了,這時有往再添加任務,會發生啥事?
這就引出了拒絕策略,在線程池中,會有四個拒絕策略,如圖:
第一個策略:會直接拋出一個異常,這樣,舊的任務執行不了,新的任務也執行不了
第二個策略:把新的任務丟給添加任務隊列的線程執行,不給入隊列,同時舊的任務依然在執行
第三個策略:把最舊的任務丟棄,添加最新的任務進來
第四個策略:直接把新的任務丟棄了,不執行新的任務,舊的任務會繼續執行

2、Executors類
ThreadPoolExecutor類本身使用起來比較復雜,標準庫給我們提供了另一個版本:把ThreadPoolExecutor封裝了一下,這個類就是Executor類,通過這個類創建出不同的線程池對象,在其內部,已經把ThreadPoolExecutor創建好了,并且設置了一些參數。
Executor的簡單使用,其中主要方法有一下4個,如圖:
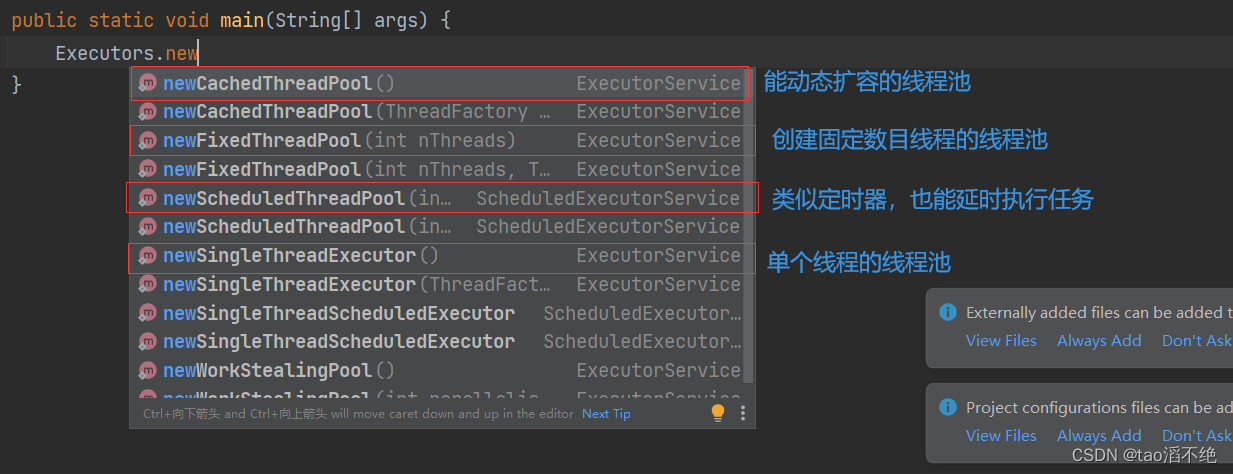
我們創建一個固定線程數目的線程池,再往里添加任務
代碼:
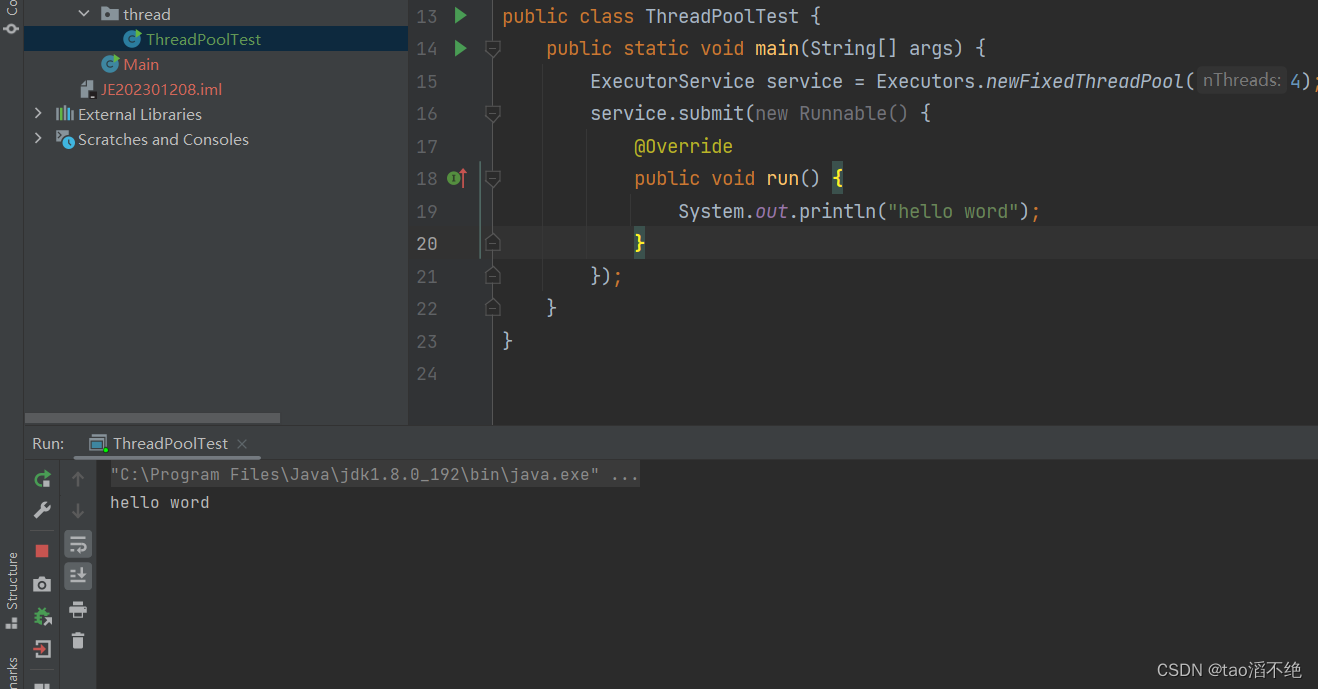
public class ThreadPoolTest {public static void main(String[] args) {ExecutorService service = Executors.newFixedThreadPool(4);service.submit(new Runnable() {@Overridepublic void run() {System.out.println("hello word");}});} }執行結果:
那啥時候使用Executor,啥時候使用ThreadPoolExecutor呢?
網上流傳了 阿里巴巴java開發編程規范,里面寫了不建議使用Executor,而且一定要使用ThreadPoolExecutor,里面說用ThreadPoolExecutor意味著一切都在掌控之中,可以避免一些不必要的因素;我們可以作為參考,不必奉為金科玉律,他們兩各有各的優缺點,這也要以以后入職的公司編程規范為準。
3、線程池的執行流程
(1)當有有任務要讓線程池里面的線程執行時,會比較工作線程數和核心線程數,? ? ? ? ? ? ? ? ? ? ?如果工作線程數 < 核心線程數,則會直接安排線程去執行這個任務。
(2)當工作線程數 > 核心線程數,即線程池中的核心線程數滿了,會添加進阻塞任務隊列中,天氣任務隊列前也會判斷任務隊列是不是空,是空就阻塞等待。
(3)如果線程池中的存活線程數 == 核心線程數,并且阻塞任務隊列也滿了,此時會判斷是否到了最大線程數:maximumPoolSize,如果沒有到達,就會讓非核心線程去執行這個任務。
(4)如果當前線程數到達了最大線程數,則會執行拒絕策略。
4、討論線程池中創建多少線程合適
假設一個進程中,所有線程都是cpu密集型,這時每個線程的工作都是在cpu上執行的,此時,線程池中的數目就不應該超過N(cpu的邏輯核心線程數)
如果一個進程中,所有線程都是IO密集型的,這時每個線程的大部分工作都是在等待IO,此時,線程池中的數目就可以遠遠超過N(cpu的邏輯核心線程數)
上述情況都是極端情況,實際上一個進程中的線程,有cpu密集型的,也有IO密集型的,只是比例不同。由于程序的復雜性,很難直接對線程池進行預估,更準確的做法是通過實驗 / 測試的方法,找出合適的線程數目;也就是嘗試給線程池設定不同的線程,對不同線程情況線程池執行的效率、性能進行評估,找到合適的線程數目。
三、線程池的模擬實現
模擬線程數目固定的線程池
(1)阻塞隊列:存放要執行的任務
代碼:
//阻塞隊列:存放要執行的任務
private BlockingQueue<Runnable> queue = new ArrayBlockingQueue<>(5);(2)submit方法:添加任務的方法,任務添加到隊列中
代碼:
//提供submit方法,可以添加任務
public void submit(Runnable runnable) throws InterruptedException {queue.put(runnable);
}(3)構造方法:指定創建多少個線程,線程在這個構造方法中都創建好了
public MyThreadPoolExecutor(int n) {for (int i = 0; i < n; i++) {Thread t = new Thread(() -> {while (true) {try {//取出一個任務Runnable runnable = queue.take();//執行任務runnable.run();} catch (InterruptedException e) {e.printStackTrace();}}});t.start();list.add(t);}}解析:線程里面,取出一個任務就執行這個任務,如果隊列里沒有任務,就會阻塞等待,等有任務,再執行任務,如此循環往復;每創建一個線程,都要放進鏈表中,也要記得start。
(4)存放線程的鏈表:每創建一個線程都放進鏈表中,這樣也能讓我們找到某個線程
代碼:
//存放線程的鏈表
List<Thread> list = new ArrayList<>();(5)最終代碼( + 測試用例)
class MyThreadPoolExecutor {//存放線程的鏈表List<Thread> list = new ArrayList<>();//阻塞隊列:存放要執行的任務private BlockingQueue<Runnable> queue = new ArrayBlockingQueue<>(5);//提供submit方法,可以添加任務public void submit(Runnable runnable) throws InterruptedException {queue.put(runnable);}public MyThreadPoolExecutor(int n) {for (int i = 0; i < n; i++) {Thread t = new Thread(() -> {while (true) {try {//取出一個任務Runnable runnable = queue.take();//執行任務runnable.run();} catch (InterruptedException e) {e.printStackTrace();}}});t.start();list.add(t);}}
}
public class MyThreadPoolExecutorTest {public static void main(String[] args) throws InterruptedException {MyThreadPoolExecutor myThreadPoolExecutor = new MyThreadPoolExecutor(4);for (int i = 0; i < 1000; i++) {//變量捕獲int n = i;myThreadPoolExecutor.submit(new Runnable() {@Overridepublic void run() {System.out.println("執行任務:" + n + ",當前線程:" + Thread.currentThread().getName());}});}}
}
測試用例:指定線程池的數目為4個線程,添加1000次任務到阻塞隊列中,讓著4個線程從阻塞隊列中拿任務,再執行任務,任務:打印0~1000,并顯示是哪個線程打印的;
注意:這里我們打印那里我們不能直接放 i ,這里涉及到變量捕獲,不能編譯通過,但他們可以在循環里創建一個變量,把 i 的值賦值給這個變量,再打印 n,這樣每循環一次,都會創建一個成員變量,這個成員變量也不會變,預期也和我們想要預期效果一樣。
執行結果,如圖:
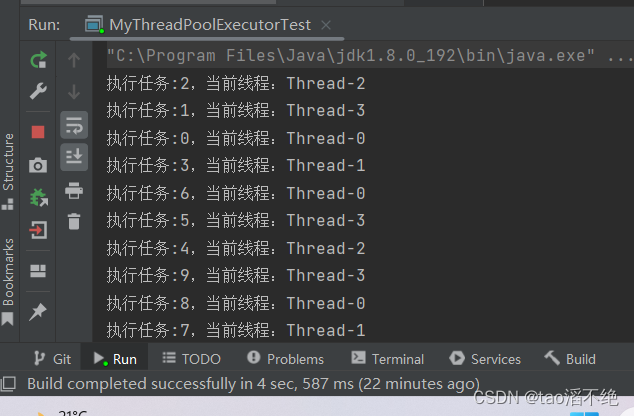
可以看到,并不是順序打印1~1000的,因為不同線程拿到任務的時機不同,多線程執行的順序也是隨機的。





一定數量的行)




和庫(Library)的區別)






 企業項目如何使用jwt?)
:信息流控制之IOC容器)
