1、消息丟失情況
消息發送端:
(1)acks=0: 表示producer不需要等待任何broker確認收到消息的回復,就可以繼續發送下一條消息。性能最高,但是最容易丟消息。大數據統計報表場景,對性能要求很高,對數據丟失不敏感的情況可以用這種。
(2)acks=1: 至少要等待leader已經成功將數據寫入本地log,但是不需要等待所有follower是否成功寫入。就可以繼續發送下一條消息。這種情況下,如果follower沒有成功備份數據,而此時leader又掛掉,則消息會丟失。
(3)acks=-1或all: 這意味著leader需要等待所有備份(min.insync.replicas配置的備份個數)都成功寫入日志,這種策略會保證只要有一個備份存活就不會丟失數據。這是最強的數據保證。一般除非是金融級別,或跟錢打交道的場景才會使用這種配置。當然如果min.insync.replicas配置的是1則也可能丟消息,跟acks=1情況類似。
消息消費端:
如果消費這邊配置的是自動提交,萬一消費到數據還沒處理完,就自動提交offset了,但是此時你consumer直接宕機了,未處理完的數據丟失了,下次也消費不到了。
2、消息重復消費
消息發送端:
發送消息如果配置了重試機制,比如網絡抖動時間過長導致發送端發送超時,實際broker可能已經接收到消息,但發送方會重新發送消息。
消息消費端:
如果消費這邊配置的是自動提交,剛拉取了一批數據處理了一部分,但還沒來得及提交,服務掛了,下次重啟又會拉取相同的一批數據重復處理。
一般消費端都是要做消費冪等處理的。
3、消息亂序
如果發送端配置了重試機制,kafka不會等之前那條消息完全發送成功才去發送下一條消息,這樣可能會出現,發送了1,2,3條消息,第一條超時了,后面兩條發送成功,再重試發送第1條消息,這時消息在broker端的順序就是2,3,1了。所以,是否一定要配置重試要根據業務情況而定。也可以用同步發送的模式去發消息,當然acks不能設置為0,這樣也能保證消息從發送端到消費端全鏈路有序。
kafka保證全鏈路消息順序消費,需要從發送端開始,將所有有序消息發送到同一個分區,然后用一個消費者去消費,但是這種性能比較低,可以在消費者端接收到消息后將需要保證順序消費的幾條消費發到內存隊列(可以搞多個),一個內存隊列開啟一個線程順序處理消息。
4、消息積壓
1)線上有時因為發送方發送消息速度過快,或者消費方處理消息過慢,可能會導致broker積壓大量未消費消息。此種情況如果積壓了上百萬未消費消息需要緊急處理,可以修改消費端程序,讓其將收到的消息快速轉發到其他topic(可以設置很多分區),然后再啟動多個消費者同時消費新主題的不同分區。
2)由于消息數據格式變動或消費者程序有bug,導致消費者一直消費不成功,也可能導致broker積壓大量未消費消息。
此種情況可以將這些消費不成功的消息轉發到其它隊列里去(類似死信隊列),后面再慢慢分析死信隊列里的消息處理問題。
5、延時隊列
延時隊列存儲的對象是延時消息。所謂的“延時消息”是指消息被發送以后,并不想讓消費者立刻獲取,而是等待特定的時間后,消費者才能獲取這個消息進行消費,延時隊列的使用場景有很多, 比如 :
1)在訂單系統中, 一個用戶下單之后通常有 30 分鐘的時間進行支付,如果 30 分鐘之內沒有支付成功,那么這個訂單將進行異常處理,這時就可以使用延時隊列來處理這些訂單了。
2)訂單完成1小時后通知用戶進行評價。
實現思路:發送延時消息時先把消息按照不同的延遲時間段發送到指定的隊列中(topic_1s,topic_5s,topic_10s,…topic_2h,這個一般不能支持任意時間段的延時),然后通過定時器進行輪訓消費這些topic,查看消息是否到期,如果到期就把這個消息發送到具體業務處理的topic中,隊列中消息越靠前的到期時間越早,具體來說就是定時器在一次消費過程中,對消息的發送時間做判斷,看下是否延遲到對應時間了,如果到了就轉發,如果還沒到這一次定時任務就可以提前結束了。
6、消息回溯
如果某段時間對已消費消息計算的結果覺得有問題,可能是由于程序bug導致的計算錯誤,當程序bug修復后,這時可能需要對之前已消費的消息重新消費,可以指定從多久之前的消息回溯消費,這種可以用consumer的offsetsForTimes、seek等方法指定從某個offset偏移的消息開始消費,參見上節課的內容。
7、分區數越多吞吐量越高嗎
可以用kafka壓測工具自己測試分區數不同,各種情況下的吞吐量
# 往test里發送一百萬消息,每條設置1KB
# throughput 用來進行限流控制,當設定的值小于 0 時不限流,當設定的值大于 0 時,當發送的吞吐量大于該值時就會被阻塞一段時間
bin/kafka‐producer‐perf‐test.sh ‐‐topic test ‐‐num‐records 1000000 ‐‐record‐size 1024 ‐‐throughput ‐1
‐‐producer‐props bootstrap.servers=192.168.65.60:9092 acks=1
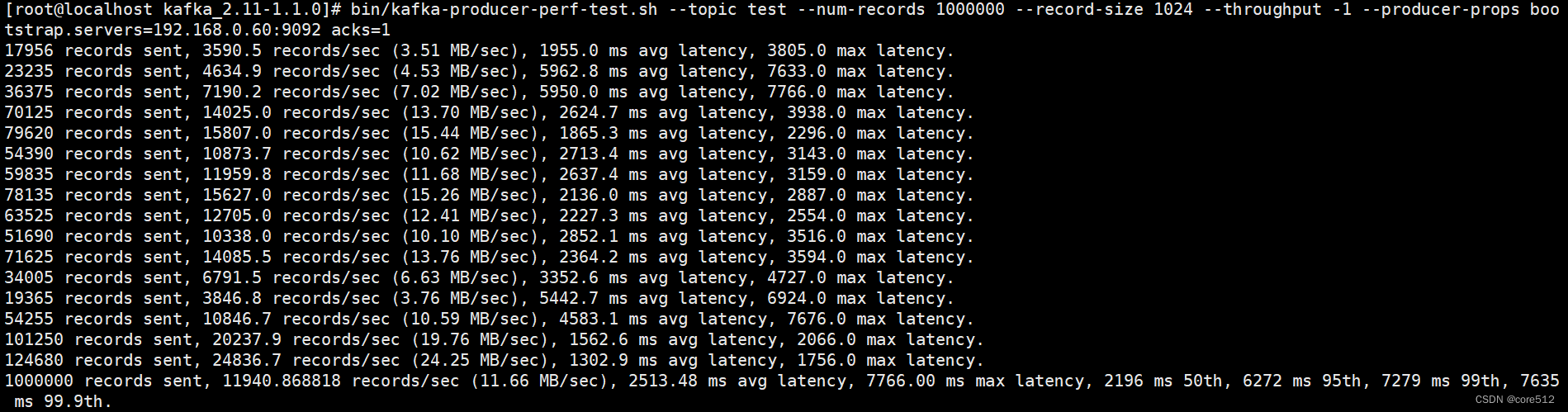
網絡上很多資料都說分區數越多吞吐量越高 , 但從壓測結果來看,分區數到達某個值吞吐量反而開始下降,實際上很多事情都會有一個臨界值,當超過這個臨界值之后,很多原本符合既定邏輯的走向又會變得不同。一般情況分區數跟集群機器數量相當就差不多了。
當然吞吐量的數值和走勢還會和磁盤、文件系統、 I/O調度策略等因素相關。
注意:如果分區數設置過大,比如設置10000,可能會設置不成功,后臺會報錯"java.io.IOException : Too many open files"。
異常中最關鍵的信息是“ Too many open flies”,這是一種常見的 Linux 系統錯誤,通常意味著文件描述符不足,它一般發生在創建線程、創建 Socket、打開文件這些場景下 。 在 Linux系統的默認設置下,這個文件描述符的個數不是很多 ,通過 ulimit -n 命令可以查看:一般默認是1024,可以將該值增大,比如:ulimit -n 65535
8、消息傳遞保障
at most once(消費者最多收到一次消息,0-1次):acks = 0 可以實現。
at least once(消費者至少收到一次消息,1-多次):ack = all 可以實現。
exactly once(消費者剛好收到一次消息):at least once 加上消費者冪等性可以實現,還可以用kafka生產者的冪等性來實
現。
kafka生產者的冪等性::因為發送端重試導致的消息重復發送問題,kafka的冪等性可以保證重復發送的消息只接收一次,只需在生產者加上參數 props.put(“enable.idempotence”, true) 即可,默認是false不開啟。
具體實現原理是,kafka每次發送消息會生成PID和Sequence Number,并將這兩個屬性一起發送給broker,broker會將PID和
Sequence Number跟消息綁定一起存起來,下次如果生產者重發相同消息,broker會檢查PID和Sequence Number,如果相同不會再接收。
PID:每個新的 Producer 在初始化的時候會被分配一個唯一的 PID,這個PID 對用戶完全是透明的。生產者如果重啟則會生成新的PID。
Sequence Number:對于每個 PID,該 Producer 發送到每個 Partition 的數據都有對應的序列號,這些序列號是從0開始單調遞增的。
9、kafka的事務
Kafka的事務不同于Rocketmq,Rocketmq是保障本地事務(比如數據庫)與mq消息發送的事務一致性,Kafka的事務主要是保障一次發送多條消息的事務一致性(要么同時成功要么同時失敗),一般在kafka的流式計算場景用得多一點,比如,kafka需要對一個topic里的消息做不同的流式計算處理,處理完分別發到不同的topic里,這些topic分別被不同的下游系統消費(比如hbase,redis,es等),這種我們肯定希望系統發送到多個topic的數據保持事務一致性。Kafka要實現類似Rocketmq的分布式事務需要額外開發功能。
kafka的事務處理可以參考官方文檔:
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("transactional.id", "my‐transactional‐id");
Producer<String, String> producer = new KafkaProducer<>(props, new StringSerializer(), new StringSerializer());
//初始化事務
producer.initTransactions();try {
//開啟事務
producer.beginTransaction();
for (int i = 0; i < 100; i++){
//發到不同的主題的不同分區
producer.send(new ProducerRecord<>("hdfs‐topic", Integer.toString(i), Integer.toString(i)));
producer.send(new ProducerRecord<>("es‐topic", Integer.toString(i), Integer.toString(i)));
producer.send(new ProducerRecord<>("redis‐topic", Integer.toString(i), Integer.toString(i)));
}
//提交事務
producer.commitTransaction();
} catch (ProducerFencedException | OutOfOrderSequenceException | AuthorizationException e) {
// We can't recover from these exceptions, so our only option is to close the producer and exit.
producer.close();
} catch (KafkaException e) {
// For all other exceptions, just abort the transaction and try again.
//回滾事務
producer.abortTransaction();
}
producer.close();
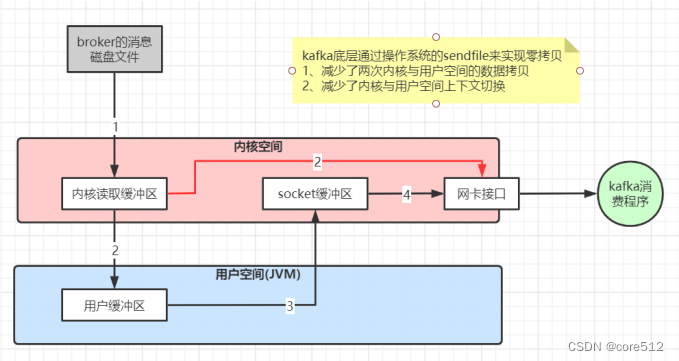
10、kafka高性能的原因
磁盤順序讀寫:kafka消息不能修改以及不會從文件中間刪除保證了磁盤順序讀,kafka的消息寫入文件都是追加在文件末尾,
不會寫入文件中的某個位置(隨機寫)保證了磁盤順序寫。
數據傳輸的零拷貝。
讀寫數據的批量batch處理以及壓縮傳輸。
)
:35、搜索插入位置)





)




 ?))






