- AR-LDM原理
- AR-LDM代碼分析
- pytorch_lightning(pl)的hook流程
- main.py 具體分析
- Train
- Sample
- LightningDataset
- ARLDM
- blip mm encoder
AR-LDM原理
左邊是模仿了自回歸地從1, 2, ..., j-1來構造 j 時刻的 frame 的過程。
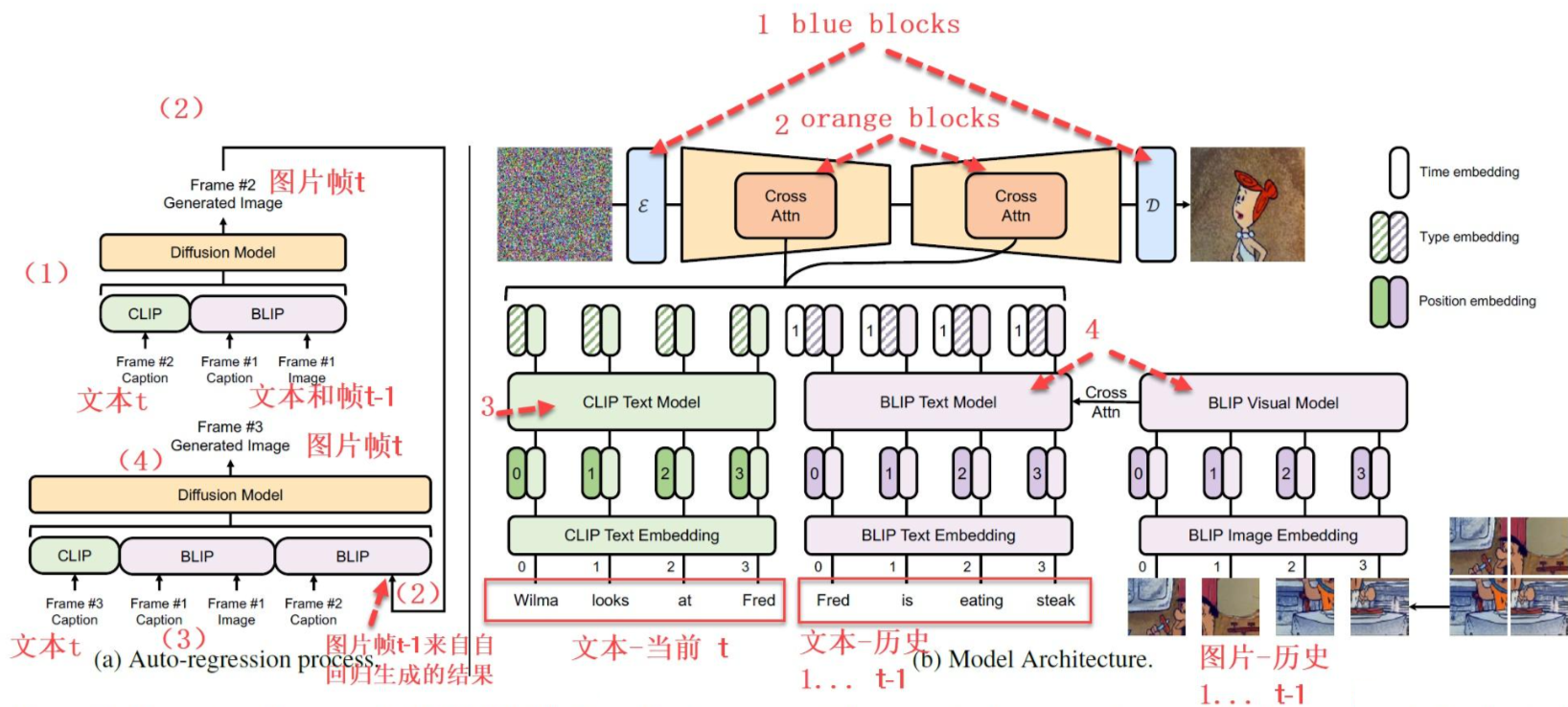
在普通Stable Diffusion的基礎上,使用了1, 2, ..., j-1 時刻的文本信息 history text prompt(BLIP編碼)、1, 2, ..., j-1 時刻的參考視頻幀history frame(BLIP編碼)、當前 j 時刻frame的 text prompt(CLIP編碼),作為condition φ j \varphi_j φj? 來引導第 j 幀的生成。公式表達如下:
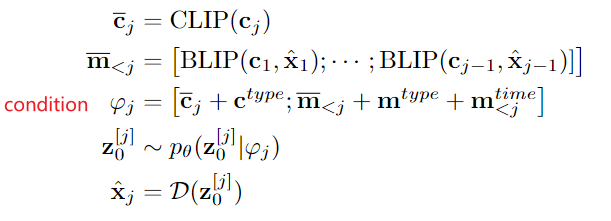
其中,注意 ① c t y p e ∈ R D c^{type}\in R^D ctype∈RD是當前 j 時刻視頻幀的 text prompt 的 type embedding、② m t y p e ∈ R D m^{type}\in R^D mtype∈RD是1, 2, ..., j-1 時刻視頻幀的 history text prompt 或 history frame 的 type embedding、③ m t i m e ∈ R L × D m^{time}\in R^{L\times D} mtime∈RL×D是1, 2, ..., j-1 時刻視頻幀的 history text prompt 或 history frame 的 frame time embedding(表示第幾幀)。
另外,為了適應沒有見過的新角色,添加一個新token<char>來表示沒見過的字符,新token的embedding<char>由相似單詞的embedding初始化,如“man”或“woman”,然后在4-5張圖像上,微調AR-LDM(除了VAE的參數不變)將其擴展到<char>字符。
AR-LDM代碼分析
項目架構
├── README.md
├── requirements.txt
├── utils
│ ├── utils.py
│ └── __init__.py
├── data_script
│ └── flintsones_hdf5.py
│ └── pororo_hdf5.py
│ └── vist_hdf5.py
│ └── vist_img_download.py
├── dataset
│ └── flintsones.py
│ └── pororo.py
│ └── vistdii.py
│ └── vistsis.py
├── models
│ ├── blip_override
│ ├── blip.py
│ ├── med.py
│ ├── med_config.json
│ ├── vit.py
│ └── diffusers_override
│ ├── attention.py
│ ├── unet_2d_blocks.py
│ ├── unet_2d_condition.py
│ └── inception.py
└── main.py
包含模塊:Auto-Regressive Models 、Latent Diffusion Models、BLIP(多模態編碼器 )、CLIP(文本編碼器)
pytorch_lightning(pl)的hook流程
1、三個函數
- 初始化
def __init__(self) - 訓練
training_step(self, batch, batch_idx) - 驗證
validation_step(self, batch, batch_idx) - 測試
test_step(self, batch, batch_idx)
為了方便我們實現其他的一些功能,因此更為完整的流程是在training_step 、validation_step、test_step 后面都緊跟著其相應的 training_step_end(self,batch_parts)和training_epoch_end(self, training_step_outputs) 函數。
當然,對于驗證和測試,都有相應的*_step_end和*_epoch_end函數。因為驗證和測試的*_step_end函數是一樣的,因此這里只以訓練為例。
注意:在新版本的PL中*_step_end和*_epoch_end等hook函數,已經更新為on_*_step_end和on_*_epoch_end !!!
2、示例
-
*_step_end– 即每一個 * 步完成后調用 -
*_epoch_end– 即每一個 * 的epoch 完成之后會自動調用
def training_step(self, batch, batch_idx):x, y = batchy_hat = self.model(x)loss = F.cross_entropy(y_hat, y)pred = ...return {'loss': loss, 'pred': pred}def training_step_end(self, batch_parts):'''當gpus=0 or 1時,這里的batch_parts即為traing_step的返回值(已驗證)當gpus>1時,這里的batch_parts為list,list中每個為training_step返回值,list[i]為i號gpu的返回值(這里未驗證)'''gpu_0_prediction = batch_parts[0]['pred']gpu_1_prediction = batch_parts[1]['pred']# do something with both outputsreturn (batch_parts[0]['loss'] + batch_parts[1]['loss']) / 2def training_epoch_end(self, training_step_outputs):'''當gpu=0 or 1時,training_step_outputs為list,長度為steps的數量(不包括validation的步數,當你訓練時,你會發現返回list<訓練時的steps數,這是因為訓練時顯示的steps數據還包括了validation的,若將limit_val_batches=0.,即關閉validation,則顯示的steps會與training_step_outputs的長度相同)。list中的每個值為字典類型,字典中會存有`training_step_end()`返回的鍵值,鍵名為`training_step()`函數返回的變量名,另外還有該值是在哪臺設備上(哪張GPU上),例如{device='cuda:0'}'''for out in training_step_outputs:# do something with preds
main.py 具體分析
Train
訓練主要是重寫def training_setp(self, batch, batch_idx)函數,并返回要反向傳播的loss即可,其中batch 即為從 train_dataloader 采樣的一個batch的數據,batch_idx即為目前batch的索引。
def train(args: DictConfig) -> None:# 實例化dataset和dataloader,并設置為train_modedataloader = LightningDataset(args)dataloader.setup('fit')# 定義AR-LDM模型model = ARLDM(args, steps_per_epoch=dataloader.get_length_of_train_dataloader())# pl的Loggerlogger = TensorBoardLogger(save_dir=os.path.join(args.ckpt_dir, args.run_name), name='log', default_hp_metric=False)# 定義保存模型Checkpoint的callback,自動保存top_0好的權重(即不保存),只保存lastcheckpoint_callback = ModelCheckpoint(dirpath=os.path.join(args.ckpt_dir, args.run_name),save_top_k=0,save_last=True)# 記錄學習率的變化的callback, 并繪制到tensorboardlr_monitor = LearningRateMonitor(logging_interval='step')# callback函數的listcallback_list = [lr_monitor, checkpoint_callback]# 定義PL_Trainertrainer = pl.Trainer(accelerator='gpu',devices=args.gpu_ids,max_epochs=args.max_epochs,benchmark=True,logger=logger,log_every_n_steps=1,callbacks=callback_list,strategy=DDPStrategy(find_unused_parameters=False))# 開始訓練trainer.fit(model, dataloader, ckpt_path=args.train_model_file)
Sample
在pytoch_lightning框架中,test 在訓練過程中是不調用的,也就是說是不相關,在訓練過程中只進行training和validation,因此如果需要在訓練過中保存validation的一些信息,就要放到validation中。
關于推理,推理是在訓練完成之后的,因此這里假設已經訓練完成.
首先進行斷言assert判斷,assert xxx,"error info", xxx正確則往下進行,錯誤則拋出異常信息"error info"
def sample(args: DictConfig) -> None:assert args.test_model_file is not None, "test_model_file cannot be None"assert args.gpu_ids == 1 or len(args.gpu_ids) == 1, "Only one GPU is supported in test mode"# 實例化dataset和dataloader,并設置為train_modedataloader = LightningDataset(args)dataloader.setup('test')# 定義AR-LDM模型model = ARLDM.load_from_checkpoint(args.test_model_file, args=args, strict=False)# 定義PL_Trainerpredictor = pl.Trainer(accelerator='gpu',devices=args.gpu_ids,max_epochs=-1,benchmark=True)# 開始推理predictions = predictor.predict(model, dataloader)# 保存推理結果imagesimages = [elem for sublist in predictions for elem in sublist[0]]if not os.path.exists(args.sample_output_dir):try:os.mkdir(args.sample_output_dir)except:passfor i, image in enumerate(images):image.save(os.path.join(args.sample_output_dir, '{:04d}.png'.format(i)))# 計算FIDif args.calculate_fid:ori = np.array([elem for sublist in predictions for elem in sublist[1]])gen = np.array([elem for sublist in predictions for elem in sublist[2]])fid = calculate_fid_given_features(ori, gen)print('FID: {}'.format(fid))
LightningDataset
Lightning只需要一個 DataLoader對與訓練集/交叉驗證集/測試集分割。
數據集有兩種實現方法:
(1)直接在Model中實現
直接實現是指在Model中重寫def train_dataloader(self)等函數來返回dataloader:
當然,首先要自己先實現Dataset的定義,可以用現有的,例如MNIST等數據集,若用自己的數據集,則需要自己去繼承torch.utils.data.dataset.Dataset。
(2)自定義繼承DataModule
這種方法是繼承pl.LightningDataModule來提供訓練、校驗、測試的數據。在重載xxx_dataloader()時,返回的data_loader需要使用torch.utils.data.DataLoader
class LightningDataset(pl.LightningDataModule):def __init__(self, args: DictConfig):super(LightningDataset, self).__init__()self.kwargs = {"num_workers": args.num_workers, "persistent_workers": True if args.num_workers > 0 else False,"pin_memory": True}self.args = args
self.args表示任何多個無名參數v,它是一個tuple(數據不可變)self.kwargs表示關鍵字參數k:v,它是一個dict;- 同時使用
*args和**kwargs時,必須*args參數列要在**kwargs前
def setup(self, stage="fit"):if self.args.dataset == "pororo":import datasets.pororo as dataelif self.args.dataset == 'flintstones':import datasets.flintstones as dataelif self.args.dataset == 'vistsis':import datasets.vistsis as dataelif self.args.dataset == 'vistdii':import datasets.vistdii as dataelse:raise ValueError("Unknown dataset: {}".format(self.args.dataset))if stage == "fit":self.train_data = data.StoryDataset("train", self.args)self.val_data = data.StoryDataset("val", self.args)if stage == "test":self.test_data = data.StoryDataset("test", self.args)
setup():實現數據集Dataset的定義,每張GPU都會執行該函數stage:用于標記是用于什么階段,訓練fit,測試test
def train_dataloader(self):if not hasattr(self, 'trainloader'):self.trainloader = DataLoader(self.train_data, batch_size=self.args.batch_size, shuffle=True, **self.kwargs)return self.trainloaderdef val_dataloader(self):return DataLoader(self.val_data, batch_size=self.args.batch_size, shuffle=False, **self.kwargs)def test_dataloader(self):return DataLoader(self.test_data, batch_size=self.args.batch_size, shuffle=False, **self.kwargs)def predict_dataloader(self):return DataLoader(self.test_data, batch_size=self.args.batch_size, shuffle=False, **self.kwargs)def get_length_of_train_dataloader(self):if not hasattr(self, 'trainloader'):self.trainloader = DataLoader(self.train_data, batch_size=self.args.batch_size, shuffle=True, **self.kwargs)return len(self.trainloader)
-
if not hasattr():用來判斷self(對象object)中是否含有名為’trainloader’的屬性(屬性或者方法) ,沒有則利用Dataset重新定義 。 -
shuffle:是洗牌打亂的意思。- 若
shuffle = True,在一個epoch之后,對所有的數據隨機打亂,再按照設定好的每個批次的大小劃分批次。(先打亂,再取batch) - 若
shuffle = False,每次的輸出結果都一樣,并且與原文件的數據存儲順序保持一致。數據會按照我們設定的Batch_size大小依次分組,依次排序。
- 若
ARLDM
首先我們需要一個基礎的pytorch lightning模型。定義如下,這個基礎模型是作為訓練其中參數model而存在的。
LightningModule 定義了一個系統而不是一個模型。包括三個核心組件:
- 模型
- 優化器
- Train/Val/Test步驟
(1)數據流偽代碼:
outs = []
for batch in data:out = training_step(batch)outs.append(out)
# 執行完1個epoch后執行training_epoch_end
training_epoch_end(outs)
(2)等價Lightning代碼:
def training_step(self, batch, batch_idx):prediction = ...return predictiondef training_epoch_end(self, training_step_outputs):for prediction in predictions:# do something with these
具體代碼
一個 AR-LDM Pytorch-Lighting 模型在本項目中含有的部件是:
(1)training_step(self, batch, batch_idx)
即:每個batch的處理函數,self(batch)實際上等價于forward(batch)。
def training_step(self, batch, batch_idx):loss = self(batch)self.log('loss/train_loss', loss, on_step=True, on_epoch=False, sync_dist=True, prog_bar=True)return loss
- 參數:
batch (Tensor | (Tensor, …) | [Tensor, …]) – The output of your DataLoader. A tensor, tuple or list.
batch_idx (int) – Integer displaying index of this batch
optimizer_idx (int) – When using multiple optimizers, this argument will also be present.
hiddens (Tensor) – Passed in if truncated_bptt_steps > 0. - 返回值:Any of.
Tensor - The loss tensor
dict - A dictionary. Can include any keys, but must include the key ‘loss’
None - Training will skip to the next batch
e.g. 返回值無論如何也需要有一個loss量。如果是字典,要有這個key=loss。沒loss這個batch就被跳過了。
def training_step(self, batch, batch_idx):x, y, z = batchout = self.encoder(x)loss = self.loss(out, x)return loss# Multiple optimizers (e.g.: GANs)
def training_step(self, batch, batch_idx, optimizer_idx):if optimizer_idx == 0:# do training_step with encoderif optimizer_idx == 1:# do training_step with decoder# Truncated back-propagation through time
def training_step(self, batch, batch_idx, hiddens):# hiddens are the hidden states from the previous truncated backprop step...out, hiddens = self.lstm(data, hiddens)...return {'loss': loss, 'hiddens': hiddens}
(2)predict_step(self, batch, batch_idx, dataloader_idx=0):
傳入數據batch進行一次推理,直接調用 self.sample(batch)進行采樣生成圖像;然后判斷是否需要計算FID值,如果需要計算Inception_Feature返回。同時返回生成的圖像image。
def predict_step(self, batch, batch_idx, dataloader_idx=0):original_images, images = self.sample(batch)if self.args.calculate_fid:original_images = original_images.cpu().numpy().astype('uint8')original_images = [Image.fromarray(im, 'RGB') for im in original_images]ori = self.inception_feature(original_images).cpu().numpy()gen = self.inception_feature(images).cpu().numpy()else:ori = Nonegen = Nonereturn images, ori, gen
(3)configure_optimizers()
進行優化器創建,返回一個優化器,或數個優化器,或兩個List(優化器,Scheduler)。本項目使用單優化器:
def configure_optimizers(self):optimizer = torch.optim.AdamW(self.parameters(), lr=self.args.init_lr, weight_decay=1e-4)scheduler = LinearWarmupCosineAnnealingLR(optimizer,warmup_epochs=self.args.warmup_epochs * self.steps_per_epoch,max_epochs=self.args.max_epochs * self.steps_per_epoch)optim_dict = {'optimizer': optimizer,'lr_scheduler': {'scheduler': scheduler, # The LR scheduler instance (required)'interval': 'step', # The unit of the scheduler's step size}}return optim_dict
warmup lr策略就是在網絡訓練初期用比較小的學習率,線性增長到初始設定的學習率。
在優化過程中選擇優化器和學習率調度器,通常只需要一個,但對于GAN之類的可能需要多個optimizer。如:
- 單個優化器:
def configure_optimizers(self):return Adam(self.parameters(), lr=1e-3)
- 多個優化器(比如GAN)
def configure_optimizers(self):generator_opt = Adam(self.model_gen.parameters(), lr=0.01)disriminator_opt = Adam(self.model_disc.parameters(), lr=0.02) return generator_opt, disriminator_opt
- 可以修改frequency鍵,來控制優化頻率:
def configure_optimizers(self):gen_opt = Adam(self.model_gen.parameters(), lr=0.01)dis_opt = Adam(self.model_disc.parameters(), lr=0.02)n_critic = 5 return ({"optimizer": dis_opt, "frequency": n_critic},{"optimizer": gen_opt, "frequency": 1} )
- 多個優化器和多個調度器或學習率字典(比如GAN)
def configure_optimizers(self):generator_opt = Adam(self.model_gen.parameters(), lr=0.01)disriminator_opt = Adam(self.model_disc.parameters(), lr=0.02)discriminator_sched = CosineAnnealing(discriminator_opt, T_max=10)return [generator_opt, disriminator_opt], [discriminator_sched]def configure_optimizers(self):generator_opt = Adam(self.model_gen.parameters(), lr=0.01)disriminator_opt = Adam(self.model_disc.parameters(), lr=0.02)discriminator_sched = CosineAnnealing(discriminator_opt, T_max=10)return {"optimizer": [generator_opt, disriminator_opt], "lr_scheduler": [discriminator_sched]}
對于學習率調度器LR scheduler:可以修改其屬性
{"scheduler": lr_scheduler, # 調度器"interval": "epoch", # 調度的單位,epoch或step"frequency": 1, # 調度的頻率,多少輪一次 "reduce_on_plateau": False, # ReduceLROnPlateau "monitor": "val_loss", # ReduceLROnPlateau的監控指標 "strict": True # 如果沒有monitor,是否中斷訓練}def configure_optimizers(self):gen_opt = Adam(self.model_gen.parameters(), lr=0.01)dis_opt = Adam(self.model_disc.parameters(), lr=0.02)gen_sched = {"scheduler": ExponentialLR(gen_opt, 0.99), "interval": "step"}dis_sched = CosineAnnealing(discriminator_opt, T_max=10)return [gen_opt, dis_opt], [gen_sched, dis_sched]
(4)freeze_params 和 unfreeze_params:
將param的requires_grad 設置為False
@staticmethoddef freeze_params(params):for param in params:param.requires_grad = False@staticmethoddef unfreeze_params(params):for param in params:param.requires_grad = True
(5)初始化ARLDM __init__
- 讀取config參數
- 在self中注冊CLIP, BLIP Null token
- 實例化
Type_embeddings layer、Time_embeddings layer、BLIP multi-modal embedding layer、CLIP text embedding layer、CLIP text tokenizer、BLIP text tokenizer、BLIP image processor、VAE,UNet,noise_scheduler; - 為Sample模式創建InceptionV3,方便計算FID指標
- 根據config,為CLIP和BLIP進行resize
position_embeddings和token_embeddings - 凍結 vae, unet, clip, blip 的參數
def __init__(self, args: DictConfig, steps_per_epoch=1):super(ARLDM, self).__init__()self.steps_per_epoch = steps_per_epoch # len(data_loader)"""Configurations"""self.args = argsself.task = args.task # continuationif args.mode == 'sample':# noise scheduler if args.scheduler == "pndm":self.scheduler = PNDMScheduler(beta_start=0.00085, beta_end=0.012, beta_schedule="scaled_linear",skip_prk_steps=True)elif args.scheduler == "ddim":self.scheduler = DDIMScheduler(beta_start=0.00085, beta_end=0.012, beta_schedule="scaled_linear",clip_sample=False, set_alpha_to_one=True)else:raise ValueError("Scheduler not supported")# fid data arguementself.fid_augment = transforms.Compose([transforms.Resize([64, 64]),transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),])# InceptionV3 settingblock_idx = InceptionV3.BLOCK_INDEX_BY_DIM[2048]self.inception = InceptionV3([block_idx])"""Modules"""# CLIP text tokenizerself.clip_tokenizer = CLIPTokenizer.from_pretrained('runwayml/stable-diffusion-v1-5', subfolder="tokenizer")# BLIP text tokenizerself.blip_tokenizer = init_tokenizer()# BLIP image processor(arguement)self.blip_image_processor = transforms.Compose([transforms.Resize([224, 224]),transforms.ToTensor(),transforms.Normalize([0.48145466, 0.4578275, 0.40821073], [0.26862954, 0.26130258, 0.27577711])])self.max_length = args.get(args.dataset).max_length# register tensor buffer CLIP, BLIP Null token in selfblip_image_null_token = self.blip_image_processor(Image.fromarray(np.zeros((224, 224, 3), dtype=np.uint8))).unsqueeze(0).float()clip_text_null_token = self.clip_tokenizer([""], padding="max_length", max_length=self.max_length, return_tensors="pt").input_idsblip_text_null_token = self.blip_tokenizer([""], padding="max_length", max_length=self.max_length, return_tensors="pt").input_idsself.register_buffer('clip_text_null_token', clip_text_null_token)self.register_buffer('blip_text_null_token', blip_text_null_token)self.register_buffer('blip_image_null_token', blip_image_null_token)# type_embeddings layerself.modal_type_embeddings = nn.Embedding(2, 768)# time_embeddings layerself.time_embeddings = nn.Embedding(5, 768)# blip multi-modal embedding layerself.mm_encoder = blip_feature_extractor(pretrained='https://storage.googleapis.com/sfr-vision-language-research/BLIP/models/model_large.pth', image_size=224, vit='large')self.mm_encoder.text_encoder.resize_token_embeddings(args.get(args.dataset).blip_embedding_tokens)# clip text embedding layerself.text_encoder = CLIPTextModel.from_pretrained('runwayml/stable-diffusion-v1-5', subfolder="text_encoder")# resize_token_embeddings:根據不同的dataset從config讀取不同的clip_embedding_tokensself.text_encoder.resize_token_embeddings(args.get(args.dataset).clip_embedding_tokens)# resize_position_embeddingsold_embeddings = self.text_encoder.text_model.embeddings.position_embeddingnew_embeddings = self.text_encoder._get_resized_embeddings(old_embeddings, self.max_length)self.text_encoder.text_model.embeddings.position_embedding = new_embeddingsself.text_encoder.config.max_position_embeddings = self.max_lengthself.text_encoder.max_position_embeddings = self.max_lengthself.text_encoder.text_model.embeddings.position_ids = torch.arange(self.max_length).expand((1, -1))# vae, unet, noise_scheduler self.vae = AutoencoderKL.from_pretrained('runwayml/stable-diffusion-v1-5', subfolder="vae")self.unet = UNet2DConditionModel.from_pretrained('runwayml/stable-diffusion-v1-5', subfolder="unet")self.noise_scheduler = DDPMScheduler(beta_start=0.00085, beta_end=0.012, beta_schedule="scaled_linear", num_train_timesteps=1000)# Freeze vae, unet, clip, blipself.freeze_params(self.vae.parameters())if args.freeze_resnet:self.freeze_params([p for n, p in self.unet.named_parameters() if "attentions" not in n])if args.freeze_blip and hasattr(self, "mm_encoder"):self.freeze_params(self.mm_encoder.parameters())self.unfreeze_params(self.mm_encoder.text_encoder.embeddings.word_embeddings.parameters())if args.freeze_clip and hasattr(self, "text_encoder"):self.freeze_params(self.text_encoder.parameters())self.unfreeze_params(self.text_encoder.text_model.embeddings.token_embedding.parameters())
(6)forward:train_step使用forward計算每一個step(每一batch數據)的loss。只有訓練、驗證、測試時候使用。推理時不用(推理時用sample)。
def forward(self, batch):# set clip and blip eval modeif self.args.freeze_clip and hasattr(self, "text_encoder"):self.text_encoder.eval()if self.args.freeze_blip and hasattr(self, "mm_encoder"):self.mm_encoder.eval()"""images = torch.stack([self.augment(im) for im in images[1:]])captions, attention_mask = clip_tokenizer(texts[1:])['input_ids'], clip_tokenizer(texts[1:])['attention_mask']source_images = torch.stack([self.blip_image_processor(im) for im in images])source_caption, source_attention_mask = blip_tokenizer(texts)['input_ids'], blip_tokenizer(texts)['attention_mask']"""# current frame and caption = {images, captions, attention_mask} 范圍從1開始# history frames and captions = {source_images, source_caption, source_attention_mask} 范圍從0開始images, captions, attention_mask, source_images, source_caption, source_attention_mask = batchB, V, S = captions.shape # (batch_size, caption_len, caption_embedding_dim)# src_V是全部captions的個數(包括第一幀)src_V = V + 1 if self.task == 'continuation' else V# 將輸入的張量展平為一維images = torch.flatten(images, 0, 1)captions = torch.flatten(captions, 0, 1)attention_mask = torch.flatten(attention_mask, 0, 1)source_images = torch.flatten(source_images, 0, 1) # (B * V, S, 1)source_caption = torch.flatten(source_caption, 0, 1)source_attention_mask = torch.flatten(source_attention_mask, 0, 1)# attention_mask = 1 代表該位置有單詞;attention_mask = 0 代表該位置無單詞,被padding# 隨機生成一個bool index數組,用于選擇一部分caption embedding進行特殊處理classifier_free_idx = np.random.rand(B * V) < 0.1# 使用 clip text_encoder 對 caption 進行編碼,得到 caption_embeddingscaption_embeddings = self.text_encoder(captions, attention_mask).last_hidden_state # (B * V, S, D)# 使用 blip multimodal_encoder 對 history images和caption 進行聯合編碼,得到 source_embeddingssource_embeddings = self.mm_encoder(source_images, source_caption, source_attention_mask,mode='multimodal').reshape(B, src_V * S, -1) # (B, V * S, D)# 對source_embeddings進行tensor的repeat操作,以便與caption_embeddings的形狀匹配source_embeddings = source_embeddings.repeat_interleave(V, dim=0) # (B * V, V * S, D)# 對caption_embeddings和source_embeddings進行一系列的加法操作,以引入模態type_embedding和time_embeddingcaption_embeddings[classifier_free_idx] = \self.text_encoder(self.clip_text_null_token).last_hidden_state[0]source_embeddings[classifier_free_idx] = \self.mm_encoder(self.blip_image_null_token, self.blip_text_null_token, attention_mask=None,mode='multimodal')[0].repeat(src_V, 1)caption_embeddings += self.modal_type_embeddings(torch.tensor(0, device=self.device))source_embeddings += self.modal_type_embeddings(torch.tensor(1, device=self.device))source_embeddings += self.time_embeddings(torch.arange(src_V, device=self.device).repeat_interleave(S, dim=0))# 對caption_embeddings和source_embeddings在dim=1上進行拼接# 得到編碼器的隱藏狀態(encoder_hidden_states)作為CrossAttn的KV送入Unetencoder_hidden_states = torch.cat([caption_embeddings, source_embeddings], dim=1) # 對attention_mask進行拼接和處理,生成一個新的attention_maskattention_mask = torch.cat([attention_mask, source_attention_mask.reshape(B, src_V * S).repeat_interleave(V, dim=0)], dim=1)attention_mask = ~(attention_mask.bool()) # B * V, (src_V + 1) * Sattention_mask[classifier_free_idx] = False# 生成一個方形掩碼(square_mask),然后將其與attention_mask的最后一部分進行邏輯或操作。square_mask = torch.triu(torch.ones((V, V), device=self.device)).bool() # B, V, V, Ssquare_mask = square_mask.unsqueeze(0).unsqueeze(-1).expand(B, V, V, S)square_mask = square_mask.reshape(B * V, V * S)attention_mask[:, -V * S:] = torch.logical_or(square_mask, attention_mask[:, -V * S:])# VAE 編碼 images 為 latentslatents = self.vae.encode(images).latent_dist.sample()latents = latents * 0.18215# 生成隨機噪聲并使用 noise_scheduler 對latents添加噪聲noise = torch.randn(latents.shape, device=self.device)bsz = latents.shape[0]timesteps = torch.randint(0, self.noise_scheduler.num_train_timesteps, (bsz,), device=self.device).long()noisy_latents = self.noise_scheduler.add_noise(latents, noise, timesteps)# 用UNet計算noisy_latents的噪聲(但并未進行去噪)noise_pred = self.unet(noisy_latents, timesteps, encoder_hidden_states, attention_mask).sample# 然后計算噪聲預測與真實噪聲之間的均方誤差損失(MSE Loss)作為最終的損失值。最后返回損失值loss = F.mse_loss(noise_pred, noise, reduction="none").mean([1, 2, 3]).mean()return loss
(7)sample:推理時,調用sample,傳入一個batch的數據(original_images, captions, attention_mask, source_images, source_caption, source_attention_mask),返回生成的image。前面和forward幾乎一樣,不同的是for循環自回歸的生成每一幀。
def sample(self, batch):original_images, captions, attention_mask, source_images, source_caption, source_attention_mask = batchB, V, S = captions.shapesrc_V = V + 1 if self.task == 'continuation' else Voriginal_images = torch.flatten(original_images, 0, 1)captions = torch.flatten(captions, 0, 1)attention_mask = torch.flatten(attention_mask, 0, 1)source_images = torch.flatten(source_images, 0, 1)source_caption = torch.flatten(source_caption, 0, 1)source_attention_mask = torch.flatten(source_attention_mask, 0, 1)caption_embeddings = self.text_encoder(captions, attention_mask).last_hidden_state # B * V, S, Dsource_embeddings = self.mm_encoder(source_images, source_caption, source_attention_mask,mode='multimodal').reshape(B, src_V * S, -1)caption_embeddings += self.modal_type_embeddings(torch.tensor(0, device=self.device))source_embeddings += self.modal_type_embeddings(torch.tensor(1, device=self.device))source_embeddings += self.time_embeddings(torch.arange(src_V, device=self.device).repeat_interleave(S, dim=0))source_embeddings = source_embeddings.repeat_interleave(V, dim=0)encoder_hidden_states = torch.cat([caption_embeddings, source_embeddings], dim=1)attention_mask = torch.cat([attention_mask, source_attention_mask.reshape(B, src_V * S).repeat_interleave(V, dim=0)], dim=1)attention_mask = ~(attention_mask.bool()) # B * V, (src_V + 1) * S# B, V, V, Ssquare_mask = torch.triu(torch.ones((V, V), device=self.device)).bool()square_mask = square_mask.unsqueeze(0).unsqueeze(-1).expand(B, V, V, S)square_mask = square_mask.reshape(B * V, V * S)attention_mask[:, -V * S:] = torch.logical_or(square_mask, attention_mask[:, -V * S:])uncond_caption_embeddings = self.text_encoder(self.clip_text_null_token).last_hidden_stateuncond_source_embeddings = self.mm_encoder(self.blip_image_null_token, self.blip_text_null_token,attention_mask=None, mode='multimodal').repeat(1, src_V, 1)uncond_caption_embeddings += self.modal_type_embeddings(torch.tensor(0, device=self.device))uncond_source_embeddings += self.modal_type_embeddings(torch.tensor(1, device=self.device))uncond_source_embeddings += self.time_embeddings(torch.arange(src_V, device=self.device).repeat_interleave(S, dim=0))uncond_embeddings = torch.cat([uncond_caption_embeddings, uncond_source_embeddings], dim=1)uncond_embeddings = uncond_embeddings.expand(B * V, -1, -1)encoder_hidden_states = torch.cat([uncond_embeddings, encoder_hidden_states])uncond_attention_mask = torch.zeros((B * V, (src_V + 1) * S), device=self.device).bool()uncond_attention_mask[:, -V * S:] = square_maskattention_mask = torch.cat([uncond_attention_mask, attention_mask], dim=0)attention_mask = attention_mask.reshape(2, B, V, (src_V + 1) * S)# AutoRagressive Generationimages = list()for i in range(V):# 生成第 i 張image,這個i控制著當前diffusion可以看到的歷史: captions[:, :, i]和frames[:, :, i]# encoder_hidden_states包含了{當前caption、歷史captions、歷史frames},作為corss-attn的KV融入Unetencoder_hidden_states = encoder_hidden_states.reshape(2, B, V, (src_V + 1) * S, -1)# Diffusion Sample(得帶T個step生成一張image)new_image = self.diffusion(encoder_hidden_states[:, :, i].reshape(2 * B, (src_V + 1) * S, -1),attention_mask[:, :, i].reshape(2 * B, (src_V + 1) * S),512, 512, self.args.num_inference_steps, self.args.guidance_scale, 0.0)# 后面存入新生成的image,并更新encoder_hidden_states:加入新一幀的image和captionimages += new_imagenew_image = torch.stack([self.blip_image_processor(im) for im in new_image]).to(self.device)new_embedding = self.mm_encoder(new_image, # B,C,H,Wsource_caption.reshape(B, src_V, S)[:, i + src_V - V],source_attention_mask.reshape(B, src_V, S)[:, i + src_V - V],mode='multimodal') # B, S, Dnew_embedding = new_embedding.repeat_interleave(V, dim=0)new_embedding += self.modal_type_embeddings(torch.tensor(1, device=self.device))new_embedding += self.time_embeddings(torch.tensor(i + src_V - V, device=self.device))encoder_hidden_states = encoder_hidden_states[1].reshape(B * V, (src_V + 1) * S, -1)encoder_hidden_states[:, (i + 1 + src_V - V) * S:(i + 2 + src_V - V) * S] = new_embeddingencoder_hidden_states = torch.cat([uncond_embeddings, encoder_hidden_states])return original_images, images
一些注意事項:
- Lightning在需要的時候會調用backward和step。
- 如果使用半精度(precision=16),Lightning會自動處理。
- 如果使用多個優化器,training_step會附加一個參數optimizer_idx。
- 如果使用LBFGS,Lightning將自動處理關閉功能。
- 如果使用多個優化器,則在每個訓練步驟中僅針對當前優化器的參數計算梯度。
- 如果需要控制這些優化程序執行或改寫默認step的頻率,請改寫optimizer_step。
- 如果在每n步都調用調度器,或者只想監視自定義指標,則可以在lr_dict中指定。
{ "scheduler": lr_scheduler,"interval": "step", # or "epoch" "monitor": "val_f1","frequency": n,
}
blip mm encoder
BLIP源碼中我們主要關注圖像encoder(vit.py)、文本encoder+decoder(med.py)、整體預訓練(blip_pretrain.py)這三部分代碼。
-
vit.py作為圖像的encoder,用來處理圖像到embedding的生成。整體結構與vit代碼類似。 -
med.py是blip文章的主要模型結構創新點。med代碼部分的整體模型結構是在bert模型的基礎上做的修改。首先,在BertSelfAttention代碼中,加入is_cross_attention部分,用以判斷是否進行圖片和文本的cross attention,原本的bert中cross attention是和encoder的輸出進行的,在med中要修改為圖像的encoder結果,對key、value進行賦值。
因此我們叫這個多模態Encoder:Image-grounded Text Encoder (變種 BERT):在標準 BERT 的 text encoder 結構里,在 Bi Self-Att 和 Feed Forward 之間插入 Cross Attention模塊,以引入 image 特征;
class BLIP_Base(nn.Module):def __init__(self,med_config='models/blip_override/med_config.json',image_size=224,vit='base',vit_grad_ckpt=False,vit_ckpt_layer=0,):"""Args:med_config (str): path for the mixture of encoder-decoder model's configuration fileimage_size (int): input image sizevit (str): model size of vision transformer"""super().__init__()self.visual_encoder, vision_width = create_vit(vit, image_size, vit_grad_ckpt, vit_ckpt_layer)self.tokenizer = init_tokenizer()med_config = BertConfig.from_json_file(med_config)med_config.encoder_width = vision_widthself.text_encoder = BertModel(config=med_config, add_pooling_layer=False)def forward(self, image, text, attention_mask, mode):assert mode in ['image', 'text', 'multimodal'], "mode parameter must be image, text, or multimodal"if mode == 'image':# return image featuresimage_embeds = self.visual_encoder(image)return image_embedselif mode == 'text':# return text featurestext_output = self.text_encoder(text, attention_mask=attention_mask, return_dict=True, mode='text')return text_output.last_hidden_stateelif mode == 'multimodal': # mm do it!!# return multimodel featuresimage_embeds = self.visual_encoder(image)image_atts = torch.ones(image_embeds.size()[:-1], dtype=torch.long).to(image.device)text[:, 0] = self.tokenizer.enc_token_idoutput = self.text_encoder(text,attention_mask=attention_mask,encoder_hidden_states=image_embeds,encoder_attention_mask=image_atts,return_dict=True,)return output.last_hidden_state
-綜合練習題-10道經典題目)


)
)


)


】數值積分(一):復化(梯形公式、中點公式)【理論到程序】)

)




)

)