文章目錄
- 前言
- 一、Redis持久化解決數據丟失問題
- 1.RDB(Redis Database Backup file)持久化
- (1)執行RDB
- (2)RDB方式bgsave的基本流程
- (3)RDB會在什么時候執行?save 60 1000代表什么含義
- (4)RDB的缺點
- 2. AOF(Append Only File)持久化
- (1)執行AOF
- (2)RDB與AOF的比較
- 二、Redis主從解決并發問題
- 1.搭建主從架構
- 2.數據同步原理
- (1)主從的全量同步原理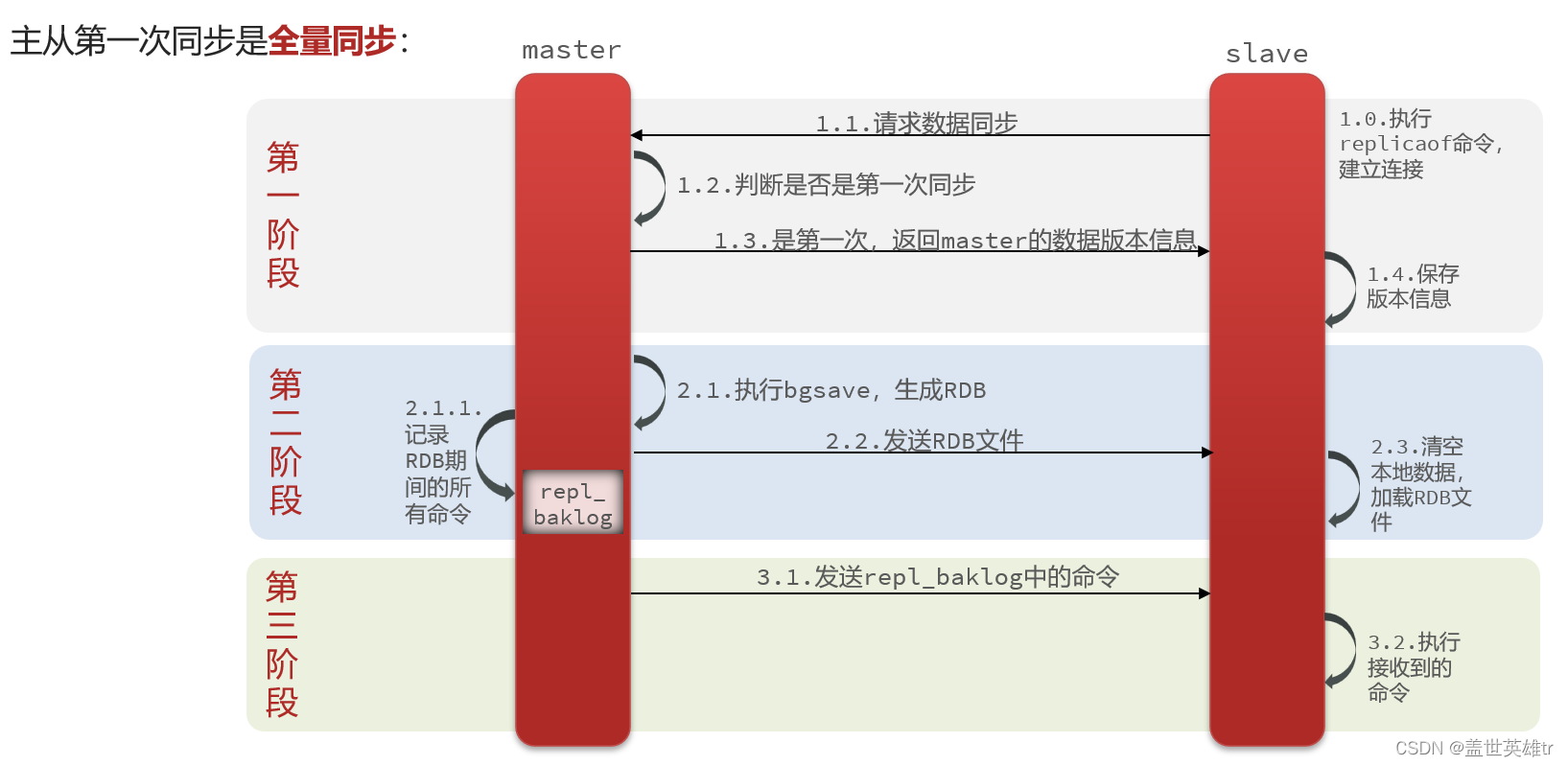
- (2)主從的增量同步原理
- 三、Redis哨兵解決故障恢復問題
- 1. 哨兵的作用和原理
- (1)哨兵的作用
- (2)哨兵如何監控
- (3)哨兵如何選舉新的master
- (4)哨兵如何實現故障轉移
- 2.搭建哨兵集群
- 四、Redis分片集群解決存儲能力問題
- 1. 搭建分片集群
- 2. 散列插槽
- 3.集群伸縮
- 4.故障轉移
前言
單點Redis存在以下問題:
- 數據丟失問題:Redis是內存存儲,服務重啟可能會丟失數據
- 并發能力問題:單節點Redis并發能力雖然不錯,但也無法滿足如618這樣的高并發場景
- 故障恢復問題:如果Redis宕機,則服務不可用,需要一種自動的故障恢復手段
- 存儲能力問題:Redis基于內存,單節點能存儲的數據量難以滿足海量數據需求
為了解決上述問題,Redis分布式緩存提供了以下解決方案:
- 解決數據丟失問題:實現Redis數據持久化
- 解決并發能力問題:搭建主從集群,實現讀寫分離
- 解決故障恢復問題:利用Redis哨兵,實現健康檢測和自動恢復
- 解決存儲能力問題:搭建分片集群,利用插槽機制實現動態擴容
一、Redis持久化解決數據丟失問題
1.RDB(Redis Database Backup file)持久化
RDB全稱Redis Database Backup file(Redis數據備份文件),也被叫做Redis數據快照。簡單來說就是把內存中的所有數據都記錄到磁盤中。當Redis實例故障重啟后,從磁盤讀取快照文件,恢復數據。快照文件稱為RDB文件,默認是保存在當前運行目錄。
(1)執行RDB
打開Redis命令行客戶端,執行命令save即完成RDB緩存,save命令默認是由Redis主進程來執行RDB,會阻塞所有命令。而命令bgsave是開啟一個子線程執行RDB,避免主進程受到影響。
(2)RDB方式bgsave的基本流程
- fork主進程得到一個子進程,共享內存空間
- 子進程讀取內存數據并寫入新的RDB文件
- 用新RDB文件替換舊的RDB文件。
(3)RDB會在什么時候執行?save 60 1000代表什么含義
- 默認是服務停止時。
- 代表60秒內至少執行1000次修改則觸發RDB
(4)RDB的缺點
- RDB執行間隔時間長,兩次RDB之間寫入數據有丟失的風險
- fork子進程、壓縮、寫出RDB文件都比較耗時
2. AOF(Append Only File)持久化
AOF全稱為Append Only File(追加文件)。Redis處理的每一個寫命令都會記錄在AOF文件,可以看做是命令日志文件。
(1)執行AOF
AOF默認是關閉的,需要修改redis.conf配置文件來開啟AOF。
# 是否開啟AOF功能,默認是no
appendonly yes
# AOF文件的名稱
appendfilename "appendonly.aof"
AOF的命令記錄的頻率也可以通過redis.conf文件來配置。
# 表示每執行一次寫命令,立即記錄到AOF文件
appendfsync always
# 寫命令執行完先放入AOF緩沖區,然后表示每隔1秒將緩沖區數據寫到AOF文件,是默認方案
appendfsync everysec
# 寫命令執行完先放入AOF緩沖區,由操作系統決定何時將緩沖區內容寫回磁盤
appendfsync no因為是記錄命令,AOF文件會比RDB文件大的多。而且AOF會記錄對同一個key的多次寫操作,但只有最后一次寫操作才有意義。通過執行bgrewriteaof命令,可以讓AOF文件執行重寫功能,用最少的命令達到相同效果。
Redis也會在觸發閾值時自動去重寫AOF文件。閾值也可以在redis.conf中配置:
# AOF文件比上次文件 增長超過多少百分比則觸發重寫
auto-aof-rewrite-percentage 100
# AOF文件體積最小多大以上才觸發重寫
auto-aof-rewrite-min-size 64mb
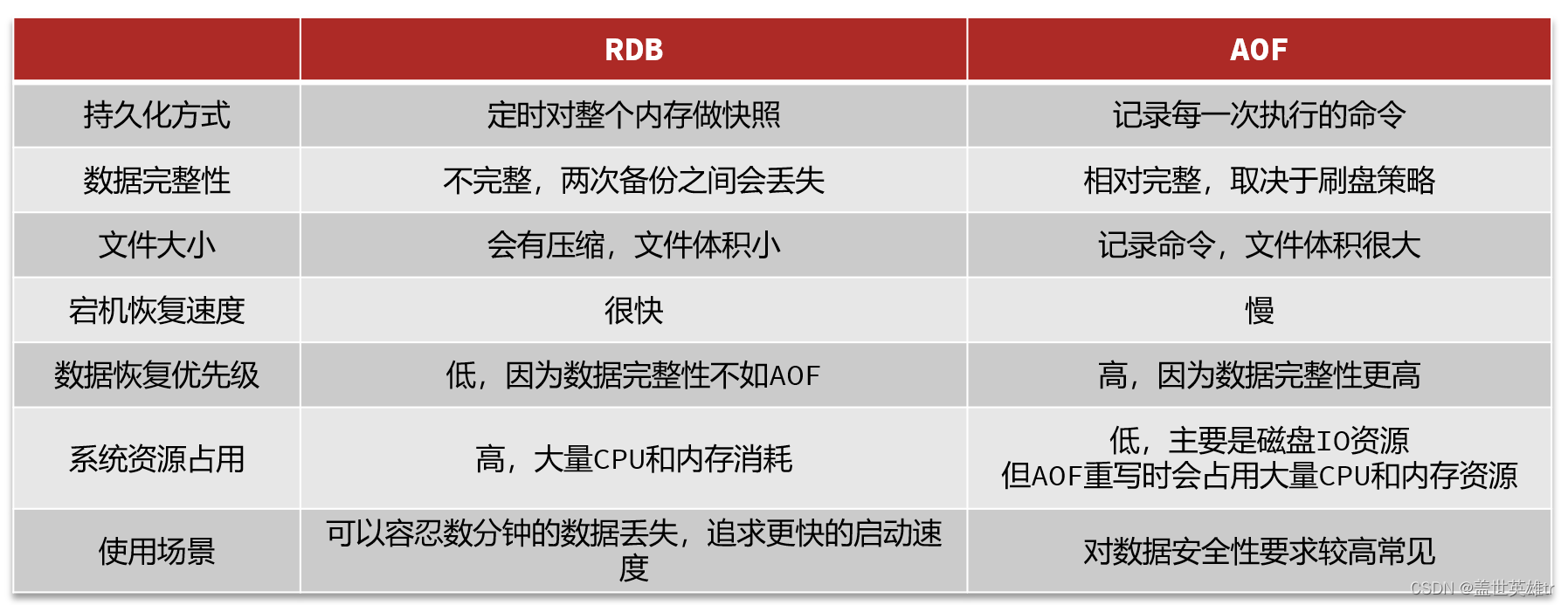
(2)RDB與AOF的比較
二、Redis主從解決并發問題
1.搭建主從架構
單節點Redis的并發能力是有上限的,要進一步提高Redis的并發能力,就需要搭建主從集群,實現讀寫分離。
具體的搭建過程可以參考我的這篇博文,全過程一步步搭建。
https://blog.csdn.net/weixin_43378573/article/details/134787401?spm=1001.2014.3001.5502
2.數據同步原理
完成Redis主從集群搭建后,可以看到,主從節點會完成數據同步。
(1)主從的全量同步原理
主節點給從節點發送RDB文件,將內存形成快照整體發送給從節點。這種同步很消耗性能,因為生成RDB文件耗時且消耗性能,只有主從節點第一次連接的時候才會這樣同步。
master如何判斷slave是不是第一次來同步數據?這里會用到兩個很重要的概念:
- Replication Id:簡稱replid,是數據集的標記,id一致則說明是同一數據集。每一個master都有唯一的replid,slave則會繼承master節點的replid
- offset:偏移量,隨著記錄在repl_baklog中的數據增多而逐漸增大。slave完成同步時也會記錄當前同步的offset。如果slave的offset小于master的offset,說明slave數據落后于master,需要更新。
因此slave做數據同步,必須向master聲明自己的replication id 和offset,master才可以判斷到底需要同步哪些數據。master就是通過判斷Replication Id來判斷該從節點是不是第一次連接。
(2)主從的增量同步原理
主從節點第一次同步是全量同步,但如果slave重啟后同步,則執行增量同步。
 repl_baklog大小有上限,寫滿后會覆蓋最早的數據。如果slave斷開時間過久,導致尚未備份的數據被覆蓋,則無法基于log做增量同步,只能再次全量同步。
repl_baklog大小有上限,寫滿后會覆蓋最早的數據。如果slave斷開時間過久,導致尚未備份的數據被覆蓋,則無法基于log做增量同步,只能再次全量同步。
可以從以下幾個方面來優化Redis主從集群:
- 在master中配置repl-diskless-sync yes啟用無磁盤復制,避免全量同步時的磁盤IO。
- Redis單節點上的內存占用不要太大,減少RDB導致的過多磁盤IO
- 適當提高repl_baklog的大小,發現slave宕機時盡快實現故障恢復,盡可能避免全量同步
- 限制一個master上的slave節點數量,如果實在是太多slave,則可以采用主-從-從鏈式結構,減少master壓力
三、Redis哨兵解決故障恢復問題
1. 哨兵的作用和原理
(1)哨兵的作用
Redis提供了哨兵(Sentinel)機制來實現主從集群的自動故障恢復。哨兵的作用如下:
- 監控:Sentinel 會不斷檢查您的master和slave是否按預期工作
- 自動故障恢復:如果master故障,Sentinel會將一個slave提升為master。當故障實例恢復后也以新的master為主
- 通知:Sentinel充當Redis客戶端的服務發現來源,當集群發生故障轉移時,會將最新信息推送給Redis的客戶端
(2)哨兵如何監控
Sentinel基于心跳機制監測服務狀態,每隔1秒向集群的每個實例發送ping命令:
- 主觀下線:如果某sentinel節點發現某實例未在規定時間響應,則認為該實例主觀下線。
- 客觀下線:若超過指定數量(quorum)的sentinel都認為該實例主觀下線,則該實例客觀下線。quorum值最好超過Sentinel實例數量的一半。
(3)哨兵如何選舉新的master
一旦發現master故障,sentinel需要在salve中選擇一個作為新的master,選擇依據是這樣的:
- 首先會判斷slave節點與master節點斷開時間長短,如果超過指定值(down-after-milliseconds * 10)則會排除該slave節點
- 然后判斷slave節點的slave-priority值,越小優先級越高,如果是0則永不參與選舉
- 如果slave-prority一樣,則判斷slave節點的offset值,越大說明數據越新,優先級越高
- 最后是判斷slave節點的運行id大小,越小優先級越高。
(4)哨兵如何實現故障轉移
- sentinel給備選的slave1節點發送slaveof no one命令,讓該節點成為master
- sentinel給所有其它slave發送命令,讓這些slave成為新master的從節點,開始從新的master上同步數據。
- 最后,sentinel將故障節點標記為slave,當故障節點恢復后會自動成為新的master的slave節點
2.搭建哨兵集群
具體的哨兵集群搭建過程可以參考我的這篇博文,全過程一步步搭建。
https://blog.csdn.net/weixin_43378573/article/details/134789082?spm=1001.2014.3001.5501
四、Redis分片集群解決存儲能力問題
1. 搭建分片集群
主從和哨兵可以解決高可用、高并發讀的問題。但是依然有兩個問題沒有解決:
- 海量數據存儲問題
- 高并發寫的問題
使用分片集群可以解決上述問題,分片集群特征:
- 集群中有多個master,每個master保存不同數據
- 每個master都可以有多個slave節點
- master之間通過ping監測彼此健康狀態
- 客戶端請求可以訪問集群任意節點,最終都會被轉發到正確節點
具體的分片集群搭建過程可以參考我的這篇博文,全過程一步步搭建。
https://blog.csdn.net/weixin_43378573/article/details/134812229
2. 散列插槽
Redis會把每一個master節點映射到0~16383共16384個插槽(hash slot)上,查看集群信息時就能看到:
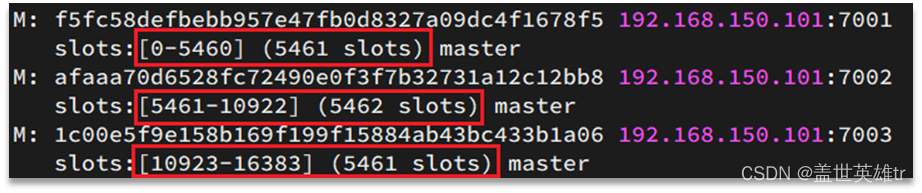
數據key不是與節點綁定,而是與插槽綁定。redis會根據key的有效部分計算插槽值,分兩種情況:
- key中包含"{}",且“{}”中至少包含1個字符,“{}”中的部分是有效部分
- key中不包含“{}”,整個key都是有效部分
例如:key是num,那么就根據num計算,如果是{itcast}num,則根據itcast計算。計算方式是利用CRC16算法得到一個hash值,然后對16384取余,得到的結果就是slot值。
3.集群伸縮
Redis集群可以動態的增加或移除節點,redis-cli --cluster提供了很多操作集群的命令,可以通過下面方式查看。

4.故障轉移
當集群中有一個master宕機會發生什么呢?
- 首先是該實例與其它實例失去連接
- 然后是疑似宕機:

- 最后是確定下線,自動提升一個slave為新的master:

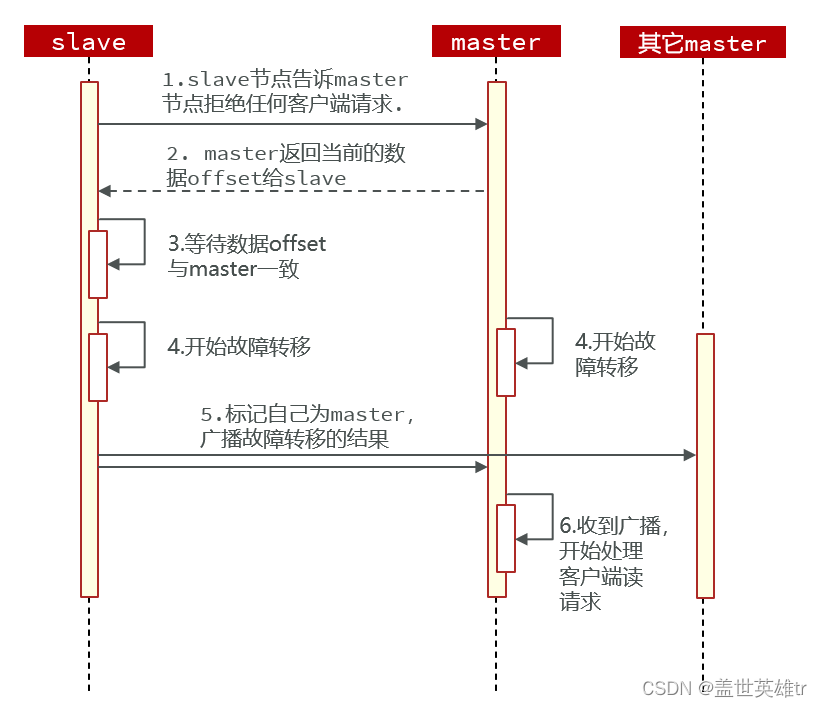
以上屬于自動的故障轉移,有時候如果某個master節點需要維護的情況,就需要手動的故障轉移。
利用cluster failover命令可以手動讓集群中的某個master宕機,切換到執行cluster failover命令的這個slave節點,實現無感知的數據遷移。其流程如下。
【完結撒花~】


 | 數據鏈路層 PPP協議、廣播CSMA/CD協議、集線器、交換器、擴展and高速以太網)







)


筆記)




)
