全稱?A Fundamental End-to-End Speech Recognition Toolkit(一個語音識別工具)
可能大家用過whisper(openAi),它【標注英語的確很完美】,【但中文會出現標注錯誤】或搞了個沒說的詞替換上去,所以要人工核對,麻煩。
FunASR作用:能【準確】識別語音,并轉成【文字、標出聲調】
他的原理,就不講了,俺是搞大數據的,python這東西就勉強能寫個爬蟲和接口,機器學習和ai相關的算法是0基礎。
直接實戰吧
首先,沖他這句話,我要給他點個贊!!!很是感動。
分2個步驟,安裝和模型
安裝:

目前只支持cpu方式(等gpu版本出來了,那速度更上一層樓)
我們這里是用作標注,標注是對每一句進行標注,所以很短,就【采用實時模型】。
ps:離線的模型太牛了,可以一次性標注幾十小時的,感覺適合翻譯有聲閱讀,感覺應用場景比較少
中文實時語音聽寫服務CPU版本部署
docker安裝,不是我吹,docker是目前世界上最好的部署方法。
我建了一個文件夾fun_asr_docker_service 所有的命令默認都在這個文件夾下操作
有docker的同學-可以忽略下面這個
1.安裝docker(可以忽略)
curl -O https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/shell/install_docker.sh
sudo bash install_docker.sh2.啟動docker鏡像
拉取鏡像(大概將近4GB)
sudo docker pull \registry.cn-hangzhou.aliyuncs.com/funasr_repo/funasr:funasr-runtime-sdk-online-cpu-0.1.5名字挺長的,改個名
sudo docker tag registry.cn-hangzhou.aliyuncs.com/funasr_repo/funasr:funasr-runtime-sdk-online-cpu-0.1.5 fun_asr建立模型文件夾(對項目不熟悉的新手別亂改名哈--這個是阿里教程里的)
mkdir -p ./funasr-runtime-resources/models啟動鏡像(命令會進去鏡像里面)
sudo docker run -p 10096:10095 -it --privileged=true \-v $PWD/funasr-runtime-resources/models:/workspace/models \fun_asr3.啟動服務
然后在docker鏡像里面執行
cd FunASR/runtime
nohup bash run_server_2pass.sh \--download-model-dir /workspace/models \--vad-dir damo/speech_fsmn_vad_zh-cn-16k-common-onnx \--model-dir damo/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-onnx ?\--online-model-dir damo/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-online-onnx ?\--punc-dir damo/punc_ct-transformer_zh-cn-common-vad_realtime-vocab272727-onnx \--itn-dir thuduj12/fst_itn_zh \--certfile 0 \--hotword /workspace/models/hotwords.txt > log.out 2>&1 &服務參數說明(具體是啥意思,看這個表)
# 如果您想關閉ssl,增加參數:--certfile 0 # 如果您想使用時間戳或者nn熱詞模型進行部署,請設置--model-dir為對應模型: # damo/speech_paraformer-large-vad-punc_asr_nat-zh-cn-16k-common-vocab8404-onnx(時間戳) # damo/speech_paraformer-large-contextual_asr_nat-zh-cn-16k-common-vocab8404-onnx(nn熱詞) # 如果您想在服務端加載熱詞,請在宿主機文件./funasr-runtime-resources/models/hotwords.txt配置熱詞(docker映射地址為/workspace/models/hotwords.txt): # 每行一個熱詞,格式(熱詞 權重):阿里巴巴 20 --download-model-dir 模型下載地址,通過設置model ID從Modelscope下載模型 --model-dir modelscope model ID 或者 本地模型路徑 --online-model-dir modelscope model ID 或者 本地模型路徑 --quantize True為量化ASR模型,False為非量化ASR模型,默認是True --vad-dir modelscope model ID 或者 本地模型路徑 --vad-quant True為量化VAD模型,False為非量化VAD模型,默認是True --punc-dir modelscope model ID 或者 本地模型路徑 --punc-quant True為量化PUNC模型,False為非量化PUNC模型,默認是True --itn-dir modelscope model ID 或者 本地模型路徑 --port 服務端監聽的端口號,默認為 10095 --decoder-thread-num 服務端線程池個數(支持的最大并發路數),腳本會根據服務器線程數自動配置decoder-thread-num、io-thread-num --io-thread-num 服務端啟動的IO線程數 --model-thread-num 每路識別的內部線程數(控制ONNX模型的并行),默認為 1,其中建議 decoder-thread-num*model-thread-num 等于總線程數 --certfile ssl的證書文件,默認為:../../../ssl_key/server.crt,如果需要關閉ssl,參數設置為0 --keyfile ssl的密鑰文件,默認為:../../../ssl_key/server.key --hotword 熱詞文件路徑,每行一個熱詞,格式:熱詞 權重(例如:阿里巴巴 20),如果客戶端提供熱詞,則與客戶端提供的熱詞合并一起使用,服務端熱詞全局生效,客戶端熱詞只針對對應客戶端生效。
啟動成功

4.客戶端測試
下載測試的打包文件(這里面包含了所有的客戶端demo源文件)
wget https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/sample/funasr_samples.tar.gz
瀏覽器測試
其他測試demo方法參考:
https://github.com/alibaba-damo-academy/FunASR/blob/main/runtime/docs/SDK_tutorial_online_zh.md#html-client
模型:
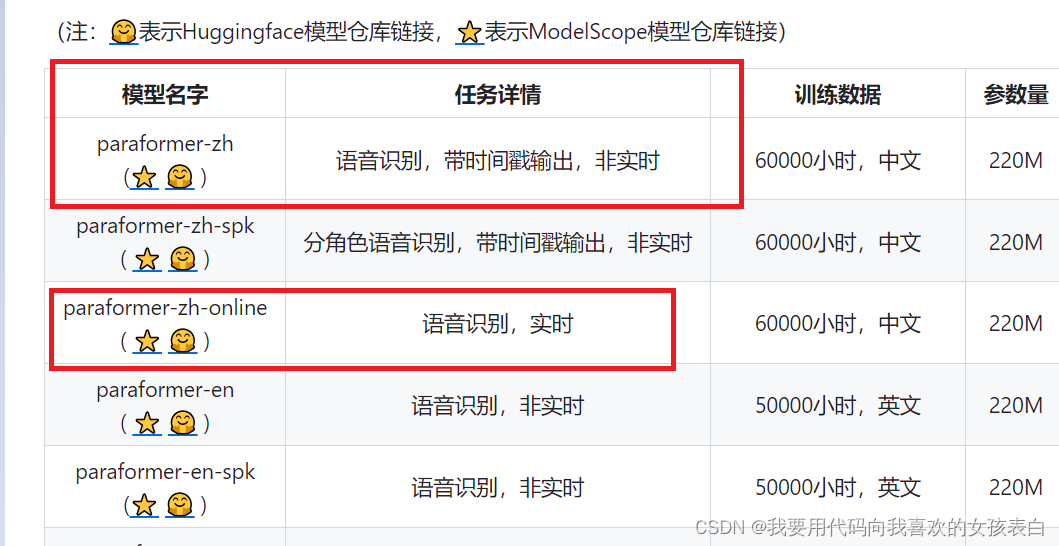
中文模型有【2個常用】
paraformer-zh(非實時,會生成時間戳)
paraformer-zh-online(實時,不會生成時間戳)
參考:
GitHub - alibaba-damo-academy/FunASR: A Fundamental End-to-End Speech Recognition Toolkit and Open Source SOTA Pretrained Models.
阿里達摩院開源大型端到端語音識別工具包FunASR | 彌合學術與工業應用之間的差距 - 知乎


筆記)




)






:20、有效的括號)



![[虛擬機]使用VM打開虛擬機電腦重啟解決方案。](http://pic.xiahunao.cn/[虛擬機]使用VM打開虛擬機電腦重啟解決方案。)
