論文地址:https://openaccess.thecvf.com/content/CVPR2023/html/Chang_Domain_Generalized_Stereo_Matching_via_Hierarchical_Visual_Transformation_CVPR_2023_paper.html
概述
?? 立體匹配模型是近年來的研究熱點。但是,現有的方法過分依賴特定數據集上的簡單特征,導致在新的數據集上泛化能力不強。現有的立體匹配方法在訓練過程中容易學習合成數據集中的表面特征(捷徑特征 shortcut features)。這些特征主要有兩種偽影(artifacts):一是局部顏色統計特征的一致性,二是對局部色度特征的過度依賴。這些特征不能有效地適應不同域之間的遷移。之前的研究主要關注于(1)利用目標域的有標簽數據對模型進行微調。(2)同時使用有標簽的合成數據集和無標簽的真實數據集來訓練域自適應立體匹配模型。這些方法在目標數據集的樣本可獲得時可以取得較好的效果,但在分布外泛化時性能不佳。為了解決這些問題,文中提出了分層視覺變換(Hierarchical Visual Transformation, HVT)網絡,其核心思想是通過改變合成數據集訓練數據的分布,使得模型不依賴于源域樣本的偽影特征(顏色統計、色度特征)來建立匹配關系,而是引導模型學習域不變的特征(語義特征、結構特征)來估計視差圖。
??為了解決立體匹配的域泛化問題,本文提出了一種分層的視覺變換網絡(Hierarchical Visual Transformation,HVT),它能從合成數據集中學習一種不受捷徑特征干擾的特征表示,從而減少域偏移對模型性能的影響。該網絡主要包括兩個部分:(1)在全局、局部和像素三個層次上,對訓練樣本進行視覺變換,使其適應新的數據域。(2)通過最大化源域和目標域之間的視覺特征差異,以及最小化跨域特征之間的一致性,來得到域不變的特征。這樣可以防止模型利用合成數據集中的偽影信息作為捷徑特征,從而有效地學習到魯棒的特征表示。我們將HVT模塊嵌入到主流的立體匹配模型中,在多個數據集上的實驗結果表明,HVT可以提高模型從合成數據集到真實數據集之間的域泛化能力。
模型架構
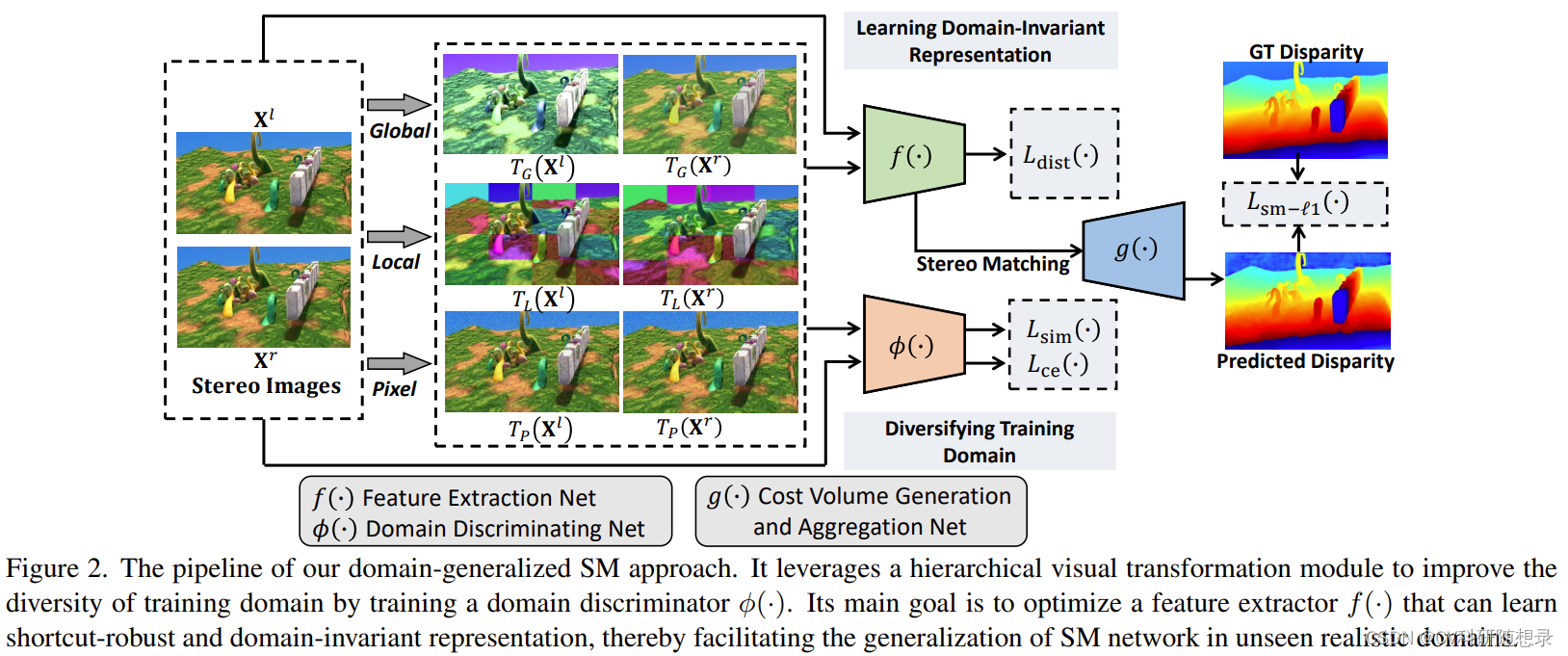
?? 給定合成訓練數據集 D s \mathcal{D}_{s} Ds? ,訓練集中的圖像對為 { X i l , X i r } i = 1 ∣ D s ∣ \{\mathbf{X}_i^l,\mathbf{X}_i^r\}_{i=1}^{|\mathcal{D}_s|} {Xil?,Xir?}i=1∣Ds?∣?, 且其對應的視差圖為 { Y i g t } i = 1 ∣ D s ∣ \{\mathbf{Y}_i^{gt}\}_{i=1}^{|\mathcal{D}_s|} {Yigt?}i=1∣Ds?∣?。模型的目標為訓練一個跨域立體匹配模型來預測未知域 D r \mathcal{D}_{r} Dr? 的圖像對:
Y ^ = F Θ ( X l , X r ) = s ( g ( f ( X l ) , f ( X r ) ) ) , (1) \hat{\mathbf{Y}}=F_\Theta(\mathbf{X}^l,\mathbf{X}^r)=s\big(g\big(f(\mathbf{X}^l),f(\mathbf{X}^r)\big)\big),\tag{1} Y^=FΘ?(Xl,Xr)=s(g(f(Xl),f(Xr))),(1)
其中 Θ \Theta Θ 為模型的人全部參數, f ( ? ) f(\cdot) f(?) 表示特征提取模塊, g ( ? ) g(\cdot) g(?) 表示代價體構建、聚合, s ( ? ) s(\cdot) s(?) 表示soft-argmin操作,經典的立體匹配模型通過平滑 L 1 L1 L1 損失 L sm- ? 1 ( F Θ ( X l , X r ) , Y g t ) L_{\text{sm-}\ell_1}\left(F_\Theta(\mathbf{X}^l,\mathbf{X}^r),\mathbf{Y}^{gt}\right) Lsm-?1??(FΘ?(Xl,Xr),Ygt) 來優化模型。
Hierarchical Visual Transformation 分層視覺轉換(核心為圖像增強)
??分層視覺轉換模塊旨在學習到域不變的匹配特征,如語義特征與結構特征,為此,在不同層次學習一系列視覺轉換 T = { T 1 , ? , T M } \mathcal{T}=\{T_1,\cdots,T_M\} T={T1?,?,TM?} 來將輸入圖像映射到域不變的特征空間 ( T ( X l ) , T ( X r ) ) \left(T(\mathbf{X}^l),T(\mathbf{X}^r)\right) (T(Xl),T(Xr)),視覺轉換應該具有以下的要求:
- T ( ? ) T(\cdot) T(?) 應使得轉換前后的圖像具有較大的視覺差異,以擴充訓練域的多樣性。
- T ( ? ) T(\cdot) T(?) 不應改變原始圖像對應的視差圖。當輸入左右圖像時候,仍然應優化 L sm- ? 1 ( F Θ ( T ( X l ) , T ( X r ) ) , Y g t ) L_{\text{sm-}\ell_1}(F_\Theta(T(\mathbf{X}^l),T(\mathbf{X}^r)),\mathbf{Y}^{gt}) Lsm-?1??(FΘ?(T(Xl),T(Xr)),Ygt) 目標。
- f ( T ( X ) ) f(T(\mathbf{X})) f(T(X)) 與 f ( X ) f(\mathbf{X}) f(X) 應該具有一致性,以獲得域不變的特征。
為此,作者在全局、局部、像素三個層級設計了視覺不變轉換。
全局轉換
??全局視覺轉換 T G ( ? ) T_{G}(\cdot) TG?(?) 旨在以一個全局的視角改變立體圖像的視覺特征分布,包括亮度、對比度、飽和度和色調 { T G B , T G C , T G S , T G H } \{T_G^B,T_G^C,T_G^S,T_G^H\} {TGB?,TGC?,TGS?,TGH?}. 其中, { T G B , T G C , T G S ˉ } \{T_{G}^{B},T_{G}^{C},T_{G}^{\bar{S}}\} {TGB?,TGC?,TGSˉ?} 可以表示為:
T G I ( X ) = α G I X + ( 1 ? α G I ) o I ( X ) , (2) T_G^I(\mathbf{X})=\alpha_G^I\mathbf{X}+(1-\alpha_G^I)o^I(\mathbf{X}),\tag{2} TGI?(X)=αGI?X+(1?αGI?)oI(X),(2)
其中 I ∈ { B , G , S } I\in\{B,G,S\} I∈{B,G,S} , α G I \alpha_{G}^I αGI? 為隨機在 [ τ min ? I , τ max ? I ] [\tau_{\min}^I,\tau_{\max}^I] [τminI?,τmaxI?] 選擇的對比度參數:
{ τ m i n I = 1 ? ( μ σ ( ? l I ) + β ) τ m a x I = 1 + ( μ σ ( ? h I ) + β ) , (3) \left.\left\{\begin{array}{c}\tau_\mathrm{min}^I=1-\left(\mu\sigma(\varrho_l^I)+\beta\right)\\\tau_\mathrm{max}^I=1+\left(\mu\sigma(\varrho_h^I)+\beta\right)\end{array}\right.\right.,\tag{3} {τminI?=1?(μσ(?lI?)+β)τmaxI?=1+(μσ(?hI?)+β)?,(3)
其中 σ ( ? ) \sigma(\cdot) σ(?) 代表 Sigmoid函數。 ? l I ∈ R 1 , ? h I ∈ R 1 \varrho_l^I\in\mathbb{R}^1, \varrho_h^I\in\mathbb{R}^1 ?lI?∈R1,?hI?∈R1 為兩個可學習的參數。 μ , β \mu,\beta μ,β 為兩個正的超參數。公式2中的 o I ( ? ) o^{I}(\cdot) oI(?) 的定義為 (1)對于亮度轉換: o B ( X ) = X ? O o^B(\mathbf{X})=\mathbf{X}\cdot\mathbf{O} oB(X)=X?O ,其中 O \mathbf{O} O 為全0的矩陣。(2)對于對比度變換: o C ( X ) = Avg ? ( Gray ? ( X ) ) o^C(\mathbf{X})=\operatorname{Avg}(\operatorname{Gray}(\mathbf{X})) oC(X)=Avg(Gray(X)) ,其中 Gray ( ? ) \text{ Gray}(\cdot) ?Gray(?) 表示將圖像轉換為灰度圖像, Avg ? ( ? ) \operatorname{Avg}(\cdot) Avg(?) 表示整張圖像的灰度平均值。(3)對于飽和度轉換, o S ( X ) = G r a y ( X ) o^S(\mathbf{X})=\mathrm{Gray}(\mathbf{X}) oS(X)=Gray(X)。
??對于色調轉換,有:
T G H ( X ) = R g b ( [ h + α G H , s , v ] ) , (4) T_G^H(\mathbf{X})=\mathrm{Rgb}([\mathbf{h}+\alpha_G^H,\mathbf{s},\mathbf{v}]),\tag{4} TGH?(X)=Rgb([h+αGH?,s,v]),(4)
其中 [ h , s , v ] = H s v ( X ) \left[\mathbf{h},\mathbf{s},\mathbf{v}\right]=\mathrm{Hsv}(\mathbf{X}) [h,s,v]=Hsv(X) 表示將圖像轉換到HSV空間的表示。 Rgb ? ( ? ) \operatorname{Rgb}(\cdot) Rgb(?)表示從HSV空間轉換到RGB空間。 α G H ∈ R 1 \alpha_{G}^{H}\in\mathbb{R}^{1} αGH?∈R1 表示從 [ τ m i n H ˉ , τ m a x H ] [\tau_{\mathrm{min}}^{\bar{H}},\tau_{\mathrm{max}}^{H}] [τminHˉ?,τmaxH?] 隨機采樣的參數,且 τ m i n H = ? μ σ ( ? l H ) ? β , τ m a x H = μ σ ( ? h H ) + β \tau_{\mathrm{min}}^{H}=-\mu\sigma(\varrho_{l}^{H})-\beta , \tau_{\mathrm{max}}^{H}=\mu\sigma(\varrho_{h}^{H})+\beta τminH?=?μσ(?lH?)?β,τmaxH?=μσ(?hH?)+β。此外, { T G B , T G C , T G S , T G H } \{T_G^B,T_G^C,T_G^S,T_G^H\} {TGB?,TGC?,TGS?,TGH?} 的順序是隨機的。
局部級變換
??局部視覺轉換 T L ( ? ) T_{L}(\cdot) TL?(?)旨在在局部范圍改變訓練圖像的分布。將圖像分為 N ′ × N ′ N^{\prime}\times N^{\prime} N′×N′ 個不重疊的塊 { x 1 p , ? , x N ′ × N ′ p } \{\mathbf{x}_1^p,\cdots,\mathbf{x}_{N^{\prime}\times N^{\prime}}^p\} {x1p?,?,xN′×N′p?},將每個塊視為獨立的圖像,使用隨機參數的局部轉換 T L p ( ? ) T_{L}^{p}(\cdot) TLp?(?) 分別進行轉換后拼接回原圖大小:
T L ( X ) = M e r g e ( [ T L p ( x 1 p ) , ? , T L p ( x N ′ × N ′ p ) ] ) , (5) T_L(\mathbf{X})=\mathsf{Merge}\left([T_L^p(\mathbf{x}_1^p),\cdots,T_L^p(\mathbf{x}_{N^{\prime}\times N^{\prime}}^p)]\right),\tag{5} TL?(X)=Merge([TLp?(x1p?),?,TLp?(xN′×N′p?)]),(5)
其中局部變換模塊可以利用現有的風格遷移網絡來實現,或者基于傅里葉的方法,為了與全局變換模塊相配合,局部變換模塊采用了與全局模塊一樣的變換函數。
像素級變換
??像素級的視覺變換旨在像素層級進行隨機變換:
T P ( X ) = X + ( μ σ ( W ) + β ) P (6) T_P(\mathbf{X})=\mathbf{X}+\begin{pmatrix}\mu\sigma(\mathbf{W})+\beta\end{pmatrix}\mathbf{P}\tag{6} TP?(X)=X+(μσ(W)+β?)P(6)
其中 P ∈ R H × W × 3 \mathbf{P}\in\mathbb{R}^{H\times W\times3} P∈RH×W×3 為隨機生成均值為0,方差為1的的高斯矩陣。 W ∈ R H × W × 3 \mathbf{W}\in\mathbb{R}^{H\times W\times3} W∈RH×W×3 為可學習的矩陣。
損失函數
跨域視覺差異最大化:該方法的目的是使數據在變換后的視覺特征分布與變換前的分布有明顯的差異,同時保持變換前后的匹配特征表示的一致性,從而學習到不受域影響的特征。這樣,立體匹配網絡就可以忽略數據中的偽影,更有效地利用學習到的魯棒特征表示來估計視差:
max ? L d i s c ( X ) = 1 3 ∑ J d ( T J ( X ) , X ) (7) \max L_{\mathrm{disc}}(\mathbf{X})=\frac13\sum_{J}d(T_J(\mathbf{X}),\mathbf{X})\tag{7} maxLdisc?(X)=31?J∑?d(TJ?(X),X)(7)
其中 J ∈ { G , L , P } J\in\{G,L,P\} J∈{G,L,P} , d ( ? ) d(\cdot) d(?) 是域差異度量,作者引入一個神經網絡模塊 ? ( ? ) \phi(\cdot) ?(?) 來提取域差異特征,則式7可以表示為:
min ? L sin ? ( X ) = 1 3 ∑ J C o s ( ? ( T J ( X ) ) , ? ( X ) ) , (8) \min L_{\sin}(\mathbf{X})=\frac13\sum_J\mathrm{Cos}\left(\phi(T_J(\mathbf{X})),\phi(\mathbf{X})\right),\tag{8} minLsin?(X)=31?J∑?Cos(?(TJ?(X)),?(X)),(8)
為了進一步提升域差異,使用交叉熵損失來優化模型:
min ? L c e ( X ) = C E ( { ? ( T J ( X ) ) , ? ( X ) } , Y d ) , (9) \min L_{\mathfrak{ce}}(\mathbf{X})=\mathrm{CE}\left(\left\{\phi(T_J(\mathbf{X})),\phi(\mathbf{X})\right\},\mathcal{Y}_d\right),\tag{9} minLce?(X)=CE({?(TJ?(X)),?(X)},Yd?),(9)
其中 Y d \mathcal{Y}_d Yd? 表示四個變換域的域標簽。
跨域特征一致性最大化:為了增強模型的泛化能力,模型需要獲取域不變的匹配特征,這要求變換 T ( ? ) T(\cdot) T(?) 不改變原圖的語義與結構特征。因此,最小化以下的損失:
min ? L d i s t ( X ) = 1 3 ∑ J ∥ f ( T J ( X ) ) ? f ( X ) ∥ 2 , (10) \min L_{\mathrm{dist}}(\mathbf{X})=\frac13\sum_J\left\|f\left(T_J(\mathbf{X})\right)-f\left(\mathbf{X}\right)\right\|_2,\tag{10} minLdist?(X)=31?J∑?∥f(TJ?(X))?f(X)∥2?,(10)
總的損失函數:
min ? L = L s m ? ? 1 ( Y ^ , Y g t ) + 1 2 ( λ 1 L d i s t ( X ) + λ 2 L s i m ( X ) + λ 3 L c e ( X ) ) , (11) \begin{aligned}\min\mathcal{L}=&L_{\mathrm{sm-}\ell_1}(\hat{\mathbf{Y}},\mathbf{Y}^{gt})+\frac12\left(\lambda_1L_{\mathrm{dist}}(\mathbf{X})+\lambda_2L_{\mathrm{sim}}(\mathbf{X})+\lambda_3L_{\mathrm{ce}}(\mathbf{X})\right),\end{aligned}\tag{11} minL=?Lsm??1??(Y^,Ygt)+21?(λ1?Ldist?(X)+λ2?Lsim?(X)+λ3?Lce?(X)),?(11)
其中 L sm- ? 1 L_{\text{sm-}\ell_1} Lsm-?1?? 同時在 { X l , X r } \{\mathbf{X}^l,\mathbf{X}^r\} {Xl,Xr} 與 { T J ( X l ) , T J ( X r ) } \{T_J(\mathbf{X}^l),T_J(\mathbf{X}^r)\} {TJ?(Xl),TJ?(Xr)} 作為模型輸入時計算。
實驗結果








)
信息系統基礎知識)

)




)



)
)


