簡介
官網

少樣本重建必然導致nerf失敗,論文提出使用diffusion模型來解決這一問題。從上圖不難看出,論文一步步提升視角數量,逐步與Zip-NeRF對比。
實現流程
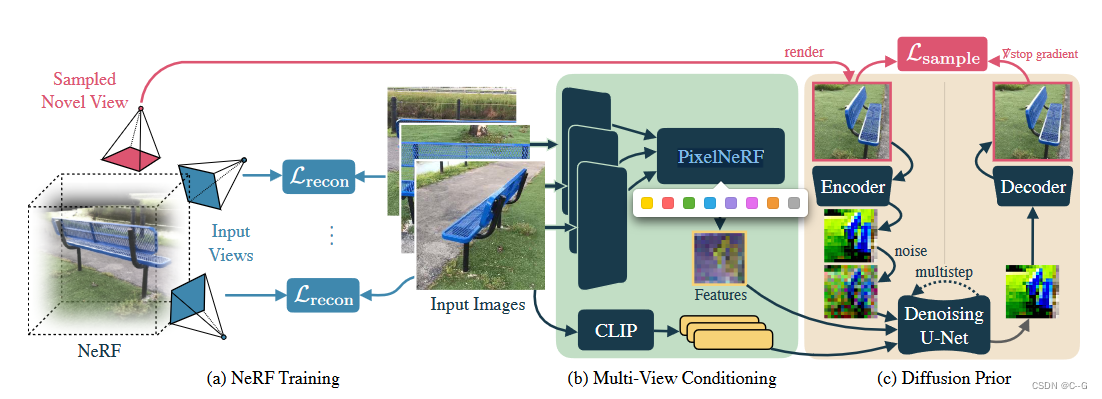
Diffusion Model for Novel View Synthesis
給定一組輸入圖像 x o b s = { x i } i = 1 N x^{obs}=\{x_i\}^N_{i=1} xobs={xi?}i=1N?以及對應的相機位姿 π o b s = { π i } i = 1 N \pi^{obs}=\{\pi_i\}^N_{i=1} πobs={πi?}i=1N?,希望在目標相機位姿 π \pi π下,圖片 x 在 新試圖的分布 p ( x ∣ x o b s , π o b s , π ) p(x|x^{obs},\pi^{obs},\pi) p(x∣xobs,πobs,π)
這里采用的擴散模型是 LDM(High-Resolution Image Synthesis with Latent Diffusion Models)。
LDM能夠有效地模擬高分辨率圖像。LDM使用預訓練的變分自編碼器(VAE) ? \epsilon ? 將輸入圖像編碼為潛在表示。在這些潛在上進行擴散,其中去噪的U-Net ? θ \epsilon_\theta ?θ?將有噪聲的潛在映射回干凈的潛在。在推理過程中,使用該U-Net對純高斯噪聲進行迭代降噪,得到一個干凈的潛在噪聲。潛在表示通過VAE解碼器D恢復為圖像。
實現過程類似于Zero-1-to-3,將輸入圖像和相機位姿作為一個預訓練文本到圖像生成的LDM的附加條件。
將文本到圖像模型轉換為位姿圖像到圖像模型需要使用附加的條件反射路徑來增強U-Net體系結構。
為了修改預訓練的架構,以便從多個姿態圖像中合成新的視圖,向U-Net注入了兩個新的條件反射信號。
- 對于輸入的高級語義信息,使用CLIP嵌入每個輸入圖像(表示為 e o b s e^{obs} eobs),并通過交叉注意將該特征向量序列饋送到U-Net中。
- 對于相對相機姿態和幾何信息,使用PixelNeRF模型的 R ? R_\phi R??來渲染具有與目標視點 π \pi π相同空間分辨率的特征圖 f
f = R ? ( x o b s , π o b s , π ) f = R_\phi(x^{obs},\pi^{obs},\pi) f=R??(xobs,πobs,π)
特征圖 f 是一個空間對齊的條件信號,它隱式地編碼了相對相機變換。
沿信道維度將 f 與 噪聲潛值 連接起來,并將其送入去噪UNet ? θ \epsilon_\theta ?θ?。
這種特征映射調節策略類似于GeNVS、SparseFusion中使用的策略,與直接嵌入相機外部和內部特征本身相比,可以更好地提供新的相機姿勢的準確表示。
training
凍結預訓練的編碼器和解碼器的權值,根據預訓練的權值初始化U-Net參數θ,并利用簡化的擴散損失對改進的視圖合成結構進行了優化
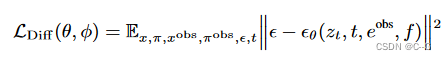
t∈{1,…, T}為擴散時間步長,ε ~ N (0, I), z t = α t ε ( x ) + σ t ? z_t = α_t \varepsilon(x) + σ_t \epsilon zt?=αt?ε(x)+σt??為該時間步長的噪聲潛函數, e o b s e^{obs} eobs 為輸入圖像 x o b s x^{obs} xobs 的CLIP圖像嵌入,f 為PixelNeRF R φ R_φ Rφ? 渲染的特征映射。
優化具有光度損耗的PixelNeRF參數φ:
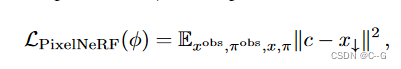
其中 c 是PixelNeRF模型的輸出(與特征映射 f 具有相同的分辨率),x↓ 是下采樣到 z t z_t zt? 和 f 的空間分辨率的目標圖像。這種損失鼓勵 PixelNeRF重建RGB目標圖像,這有助于避免擴散模型無法利用 PixelNeRF 輸入的糟糕的局部最小值。
3D Reconstruction with Diffusion Priors
第一步的NeRF重建的光度損失
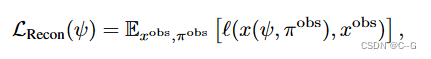
在每次迭代中,對隨機視圖進行采樣,并從擴散模型中生成圖像以生成目標圖像。(通過從中間噪聲水平開始采樣過程來控制目標圖像與當前渲染圖像的接地程度。)
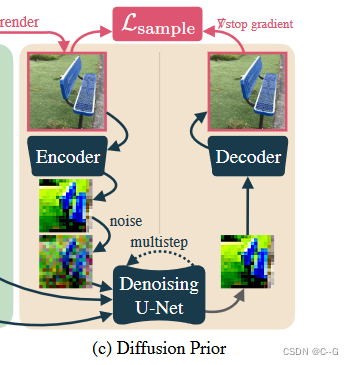
具體來說,從采樣的新視點 π \pi π呈現圖像 x ( ψ , π ) x(ψ, π) x(ψ,π),并將其編碼和擾動為噪聲潛碼為 t U [ t m i n , t m a x ] t ~ U [t_{min}, t_{max}] t?U[tmin?,tmax?]的噪聲潛碼 z t z_t zt?。然后,通過運行DDIM采樣,在最小噪聲潛碼和 t 之間均勻間隔 k 個中間步驟,從潛在擴散模型生成一個樣本,從而得到一個潛在樣本 z 0 z_0 z0?。這個潛信號被解碼以產生一個目標圖像 x ^ π = D ( z 0 ) \hat{x}_\pi=D(z_0) x^π?=D(z0?):
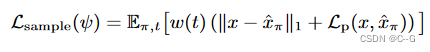
其中,$L_p¥為感知距離LPIPS, w(t)為依賴于噪聲水平的加權函數。這種擴散損失最類似于SparseFusion,也類似于InstructNeRF2NeRF的迭代數據集更新策略,只不過在每次迭代時都采樣一個新的圖像。從經驗上發現,這種方法比分數蒸餾取樣更有效。
當使用擴散先驗時,我們不想在物體內部或墻后放置新的視圖,視圖的放置通常取決于場景內容和捕獲類型。與RegNeRF等先前的工作一樣,希望根據已知的輸入姿勢和捕獲模式定義一個分布,該分布將包含一組合理的新相機姿勢,大致與期望觀察重建場景的位置相匹配。
通過確定場景中的基本姿勢集或路徑來實現這一點,可以隨機采樣和擾動以定義新視圖的完整姿勢分布。在LLFF和DTU等前向捕獲或mip-NeRF 360等360度捕獲中,定義了一條適合訓練視圖的橢圓路徑,面向焦點(與訓練相機的焦軸平均距離最小的點)。在更多的非結構化捕獲中,如CO3D和RealEstate10K,擬合b樣條來大致遵循訓練視圖的軌跡。在任何一種情況下,對于每個隨機的新視圖,統一地選擇路徑中的一個姿態,然后擾動它的位置,向上向量,并在一定范圍內查看點。
Implementation Details
基本擴散模型是對潛在擴散模型的重新實現,該模型在輸入分辨率為512×512×3的圖像-文本對的內部數據集和維度為64×64×8的潛在空間上進行了訓練。
PixelNeRF的編碼器是一個小的U-Net,它將分辨率為512×512的圖像作為輸入,并輸出分辨率為64 × 64的128通道的特征圖
聯合訓練PixelNeRF和微調去噪U-Net,批處理大小為256,學習率為 1 0 ? 4 10^{?4} 10?4,共進行250k次迭代。為了實現無分類器制導(CFG),以10%的概率將輸入圖像隨機設置為全零。
使用Zip-NeRF作為主干,并對NeRF進行了總共1000次迭代的訓練。重構損失 L r e c o n L_{recon} Lrecon? 與 Zip-NeRF一樣使用Charbonnier損失。 L s a m p l e L_{sample} Lsample?的權重在訓練過程中從1線性衰減到0.1,采樣使用的無分類器指導尺度設置為 3.0。將所有訓練步驟的 t m a x = 1.0 t_{max} = 1.0 tmax?=1.0 固定,并將 t m i n t_{min} tmin? 從1.0線性退火到0.0。無論 t 如何,總是以k = 10步對去噪圖像進行采樣。在實踐中,用于視圖合成的擴散模型可以以少量觀察到的輸入圖像和姿勢為條件。給定一個新的目標視圖,從觀察到的輸入中選擇3個最近的相機位置來調節模型。這使模型能夠在選擇對采樣的新視圖最有用的輸入時縮放到大量的輸入圖像。

Limitation
重量級擴散模型成本高,并且顯著減慢了重建速度;研究結果表明,與圖像模型在2D中產生的幻覺相比,3D繪制能力有限;調整重構和樣本損失的平衡是繁瑣的等。

)
信息系統基礎知識)

)




)



)
)




