文生圖模型演進:AE、VAE、VQ-VAE、VQ-GAN、DALL-E 等 8 模型本文中我們回顧了 AE、VAE、VQ-VAE、VQ-VAE-2 以及 VQ-GAN、DALL-E、DALL-E mini 和 CLIP-VQ-GAN 等 8 中模型,以介紹文生圖模型的演進。![]() https://mp.weixin.qq.com/s/iFrCEpAJ3WMhB-01lZ_qIA
https://mp.weixin.qq.com/s/iFrCEpAJ3WMhB-01lZ_qIA
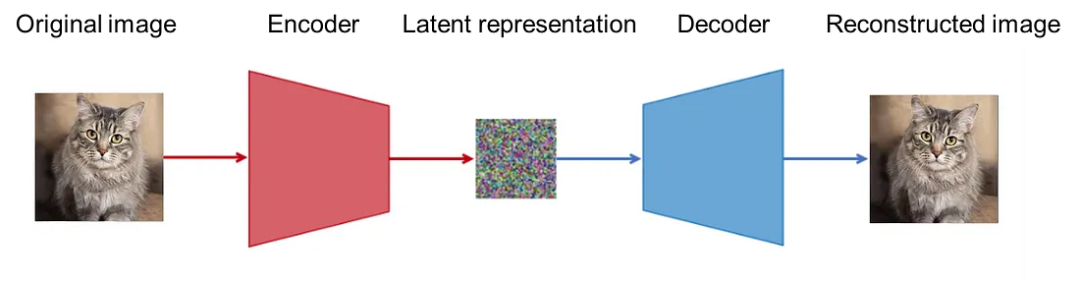
1.AutoEncoder(AE)
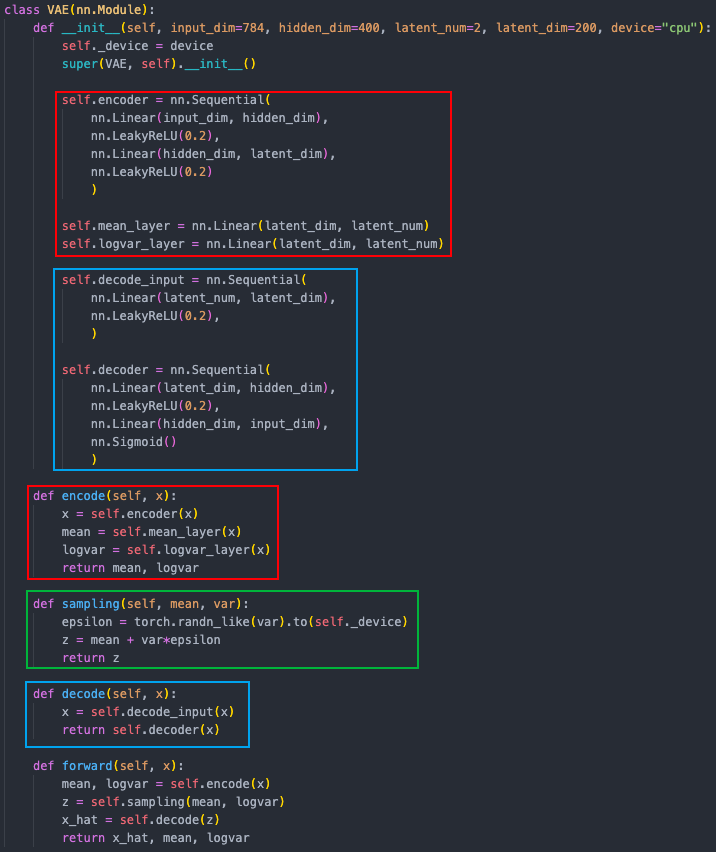
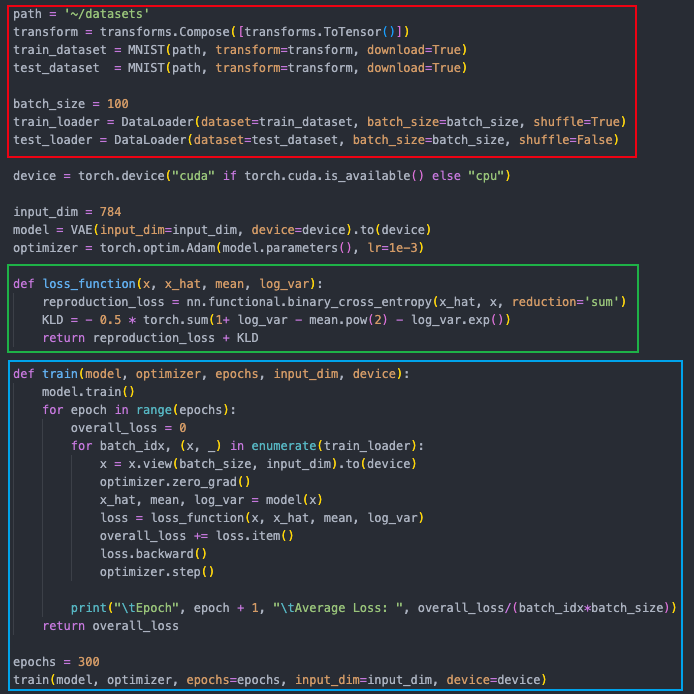
2.Variational Autoencoder(VAE)
在AE基礎上引入了概率生成模型,通過在隱空間引入概率分布,使模型能夠生成多樣性的樣本,

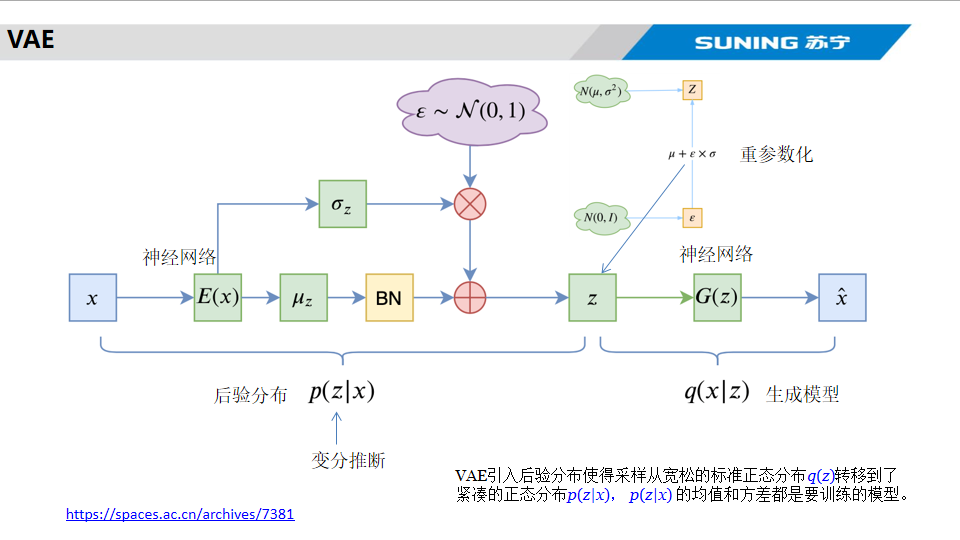
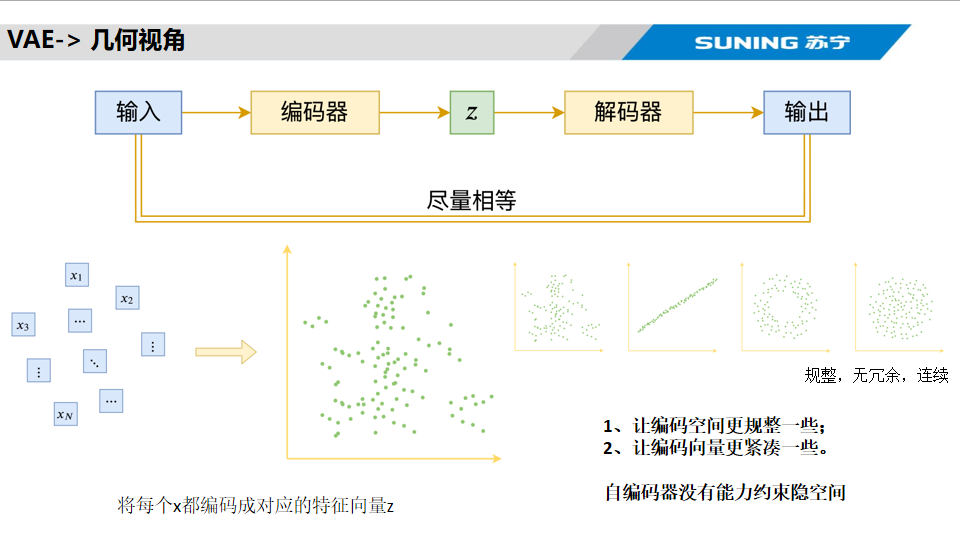
Encoder將輸入映射到隱空間的一個點,而不同的點與點之間是沒有規律的,無法基于此來decoder出預期的內容。?
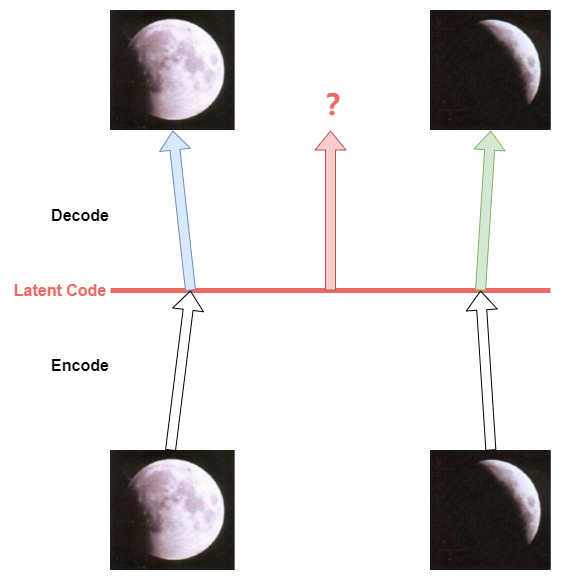
模型在隱空間是一個高斯分布,
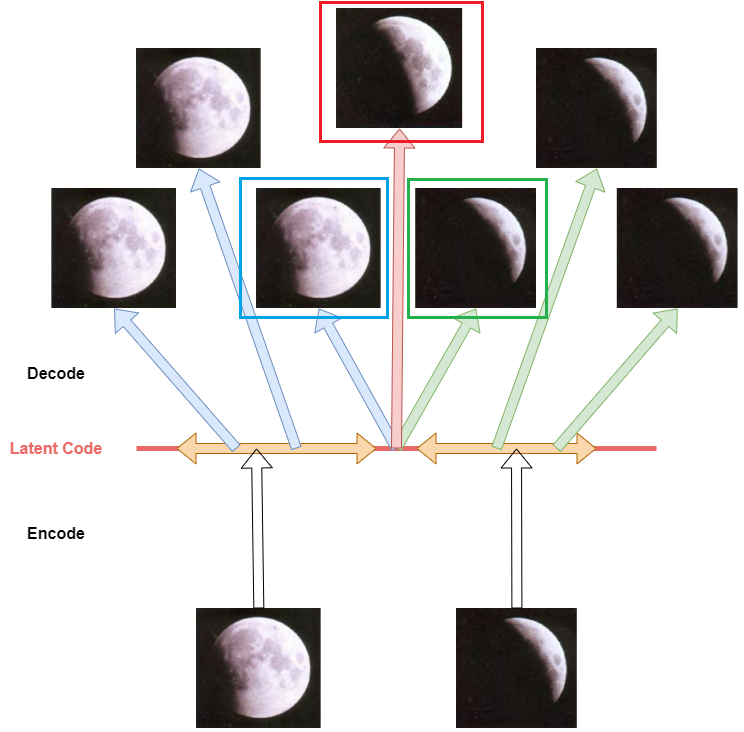


3.Vector Quantised VAE(VQ-VAE)
在VAE的基礎上引入了離散的、可量化的隱空間表示,有助于模型更好的理解數據中的離散結構和語義信息,同時避免過擬合。
VQ是一種數據壓縮和量化的技術,它可以將連續的向量映射到一組離散的具有代表性的向量中,VQ通常用于將連續的隱空間表示映射到一個有限的、離散的codebook中,現在圖像tokenizer很多都是采用這種做法。
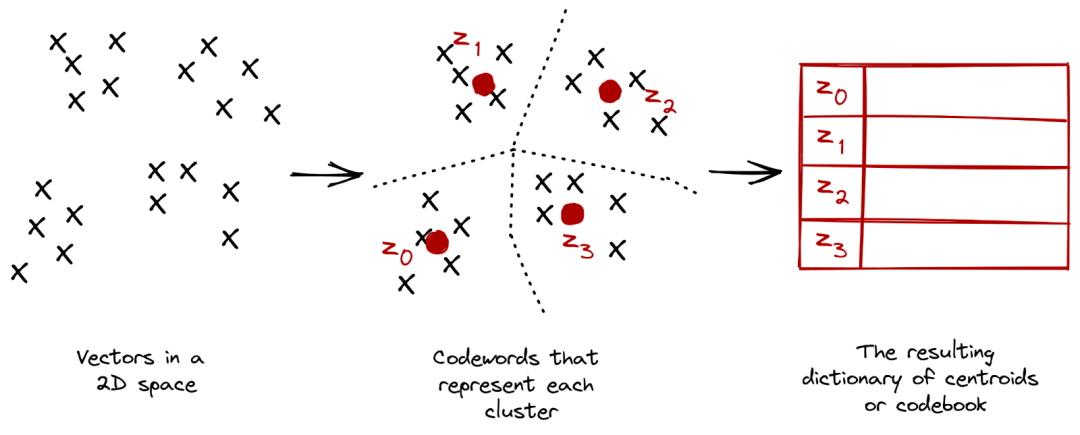
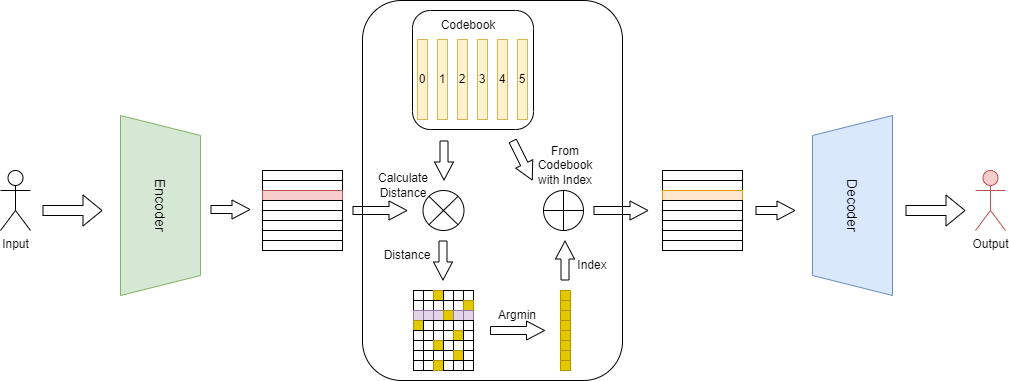
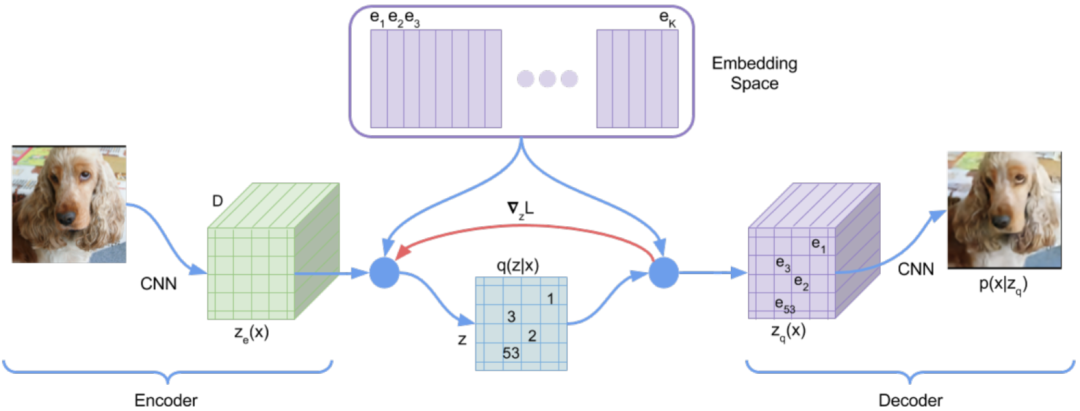
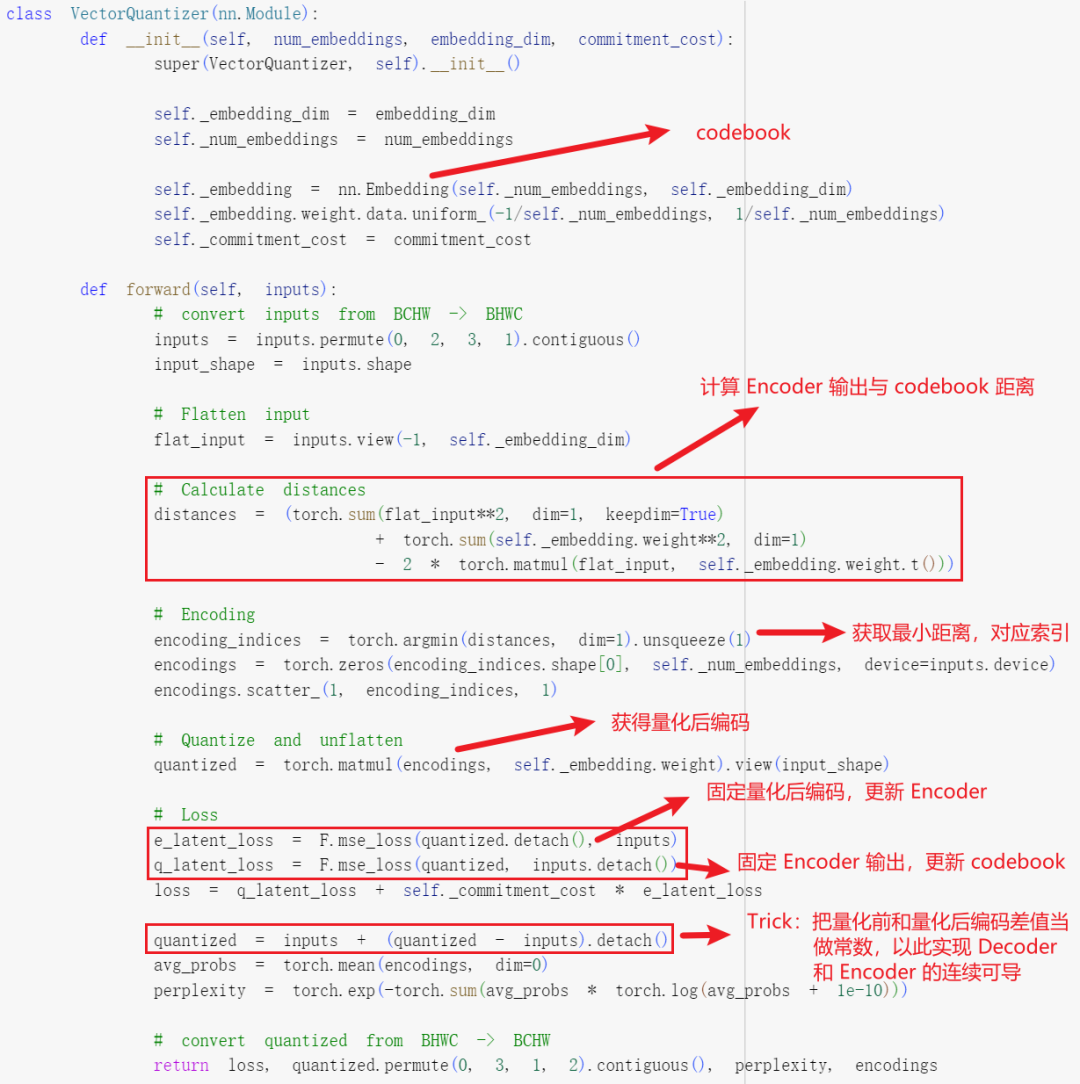
VQ中使用argmin來獲取最小距離,不可導,因此無法將encoder和decoder聯合訓練,作者將量化后表示的梯度拷貝到量化錢的表示,以使其連續可導。
4.VQ-VAE+PixelCNN
有了上述VQ-VAE,可以實現圖像壓縮,重建,codeformer的超分修復等,但是無法生成新的圖像,當然可以隨機生成index,然后對應生成量化后的latnet code,進而使用decoder來生成圖像,但是latent code完全沒有全局信息甚至局部信息,因為每個位置都是隨機生成的,引入了pixelcnn來自回歸的生成全局信息的latent code,進而可以生成更真實的圖像。
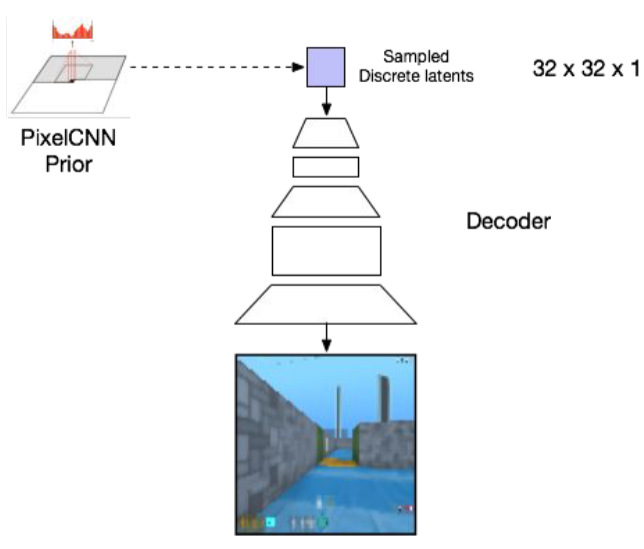
pixelcnn是一個自回歸模型,可以逐個像素生成,每個位置都可以看到之前位置的信息,這樣生成的latent code能夠更全面的考慮空間信息。
5.Vector Quantised VAE-2(V1-VAE-2)
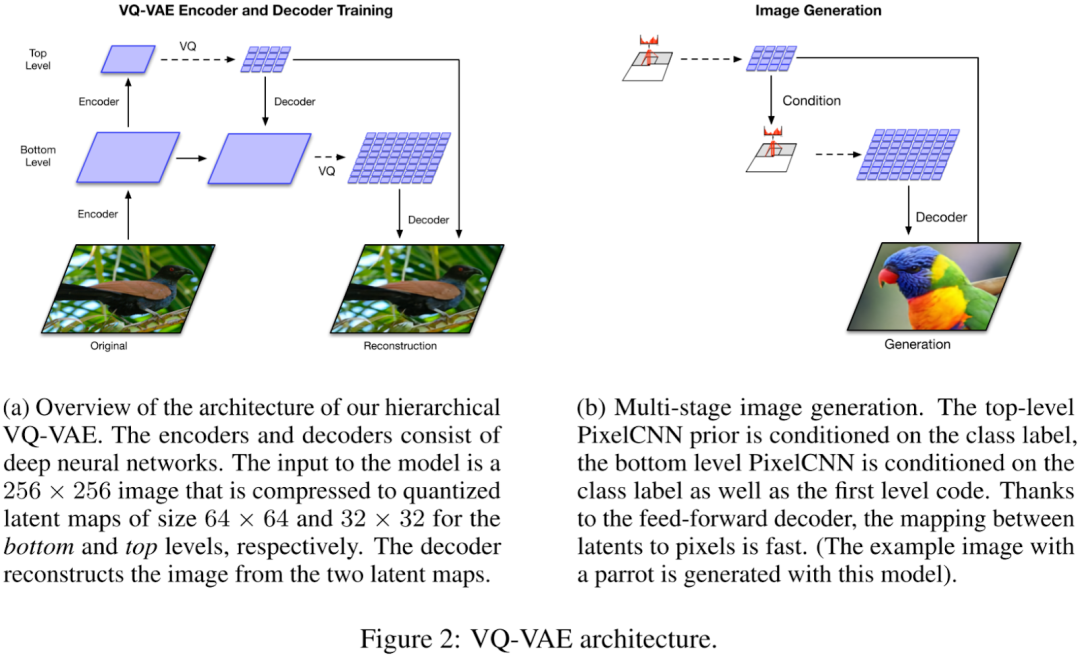
6.Vector Quantised GAN(VQ-GAN)
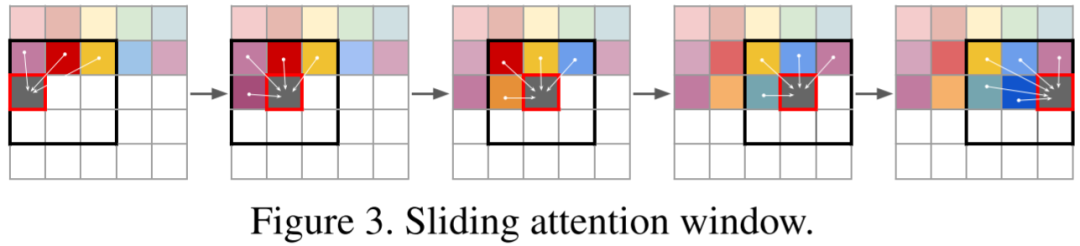
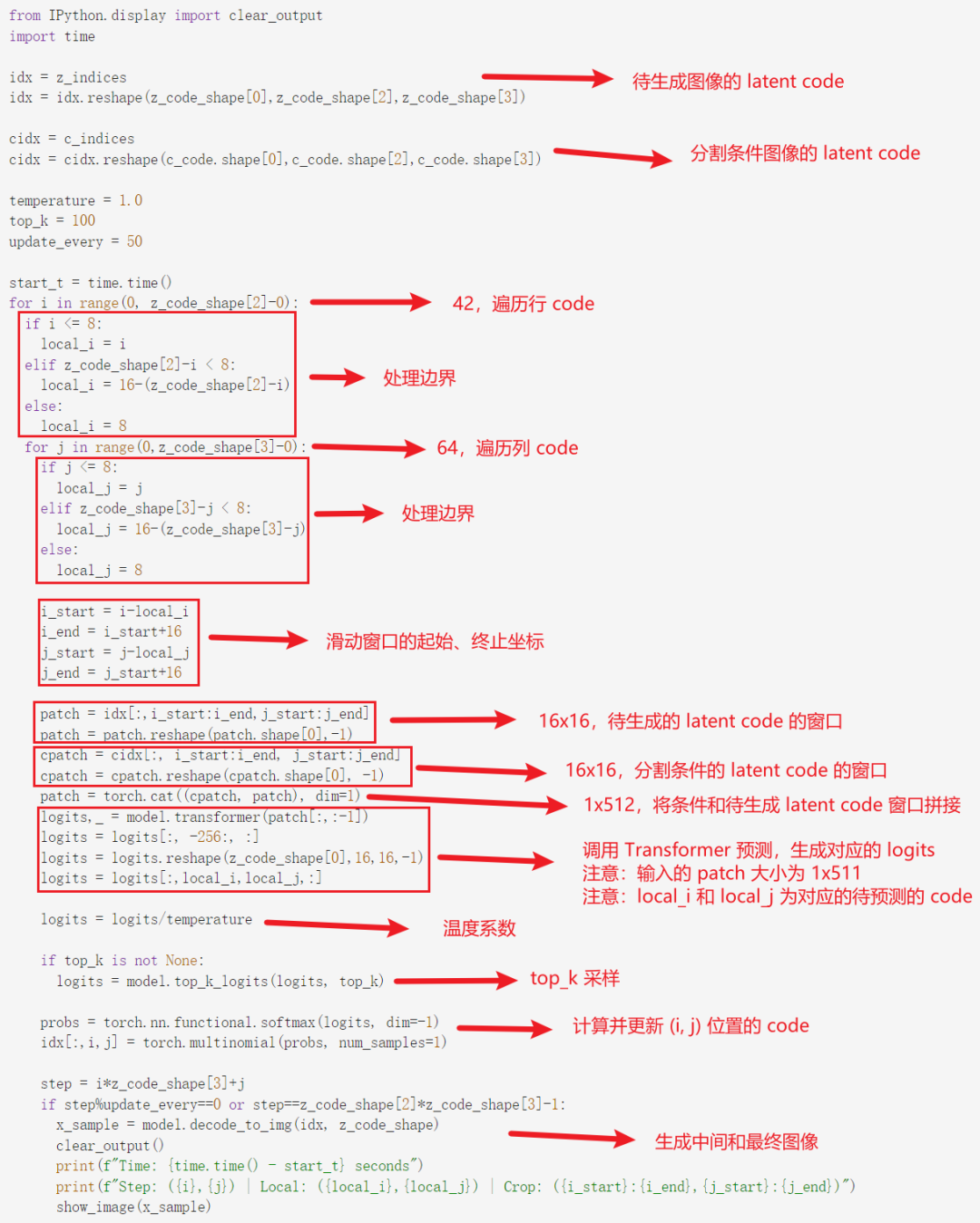
引入了GAN,將VQ-VAE當做生成器,并加入判別器,加入了感知重建損失;將pixelcnn換成了GPT2;引入了滑動窗口自注意力機制。
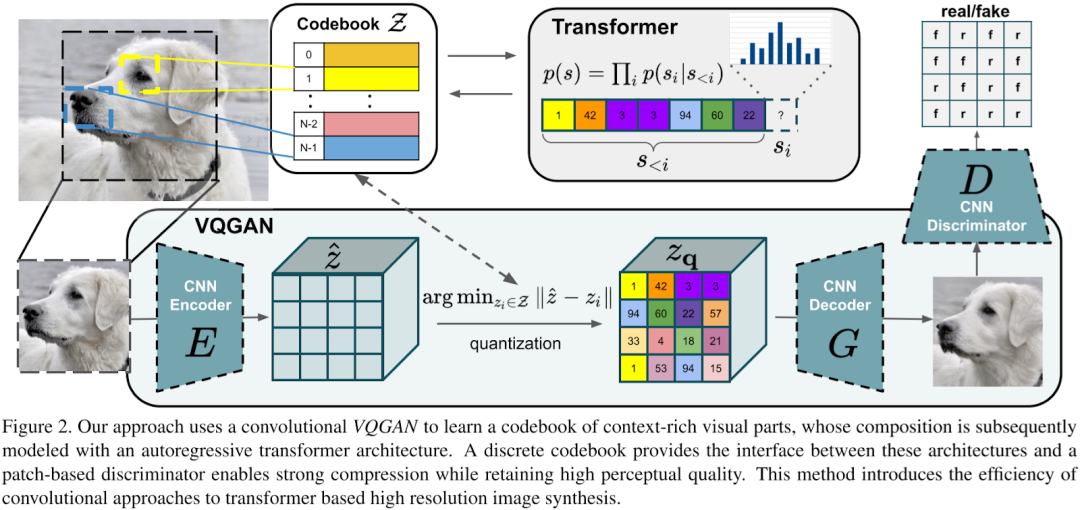

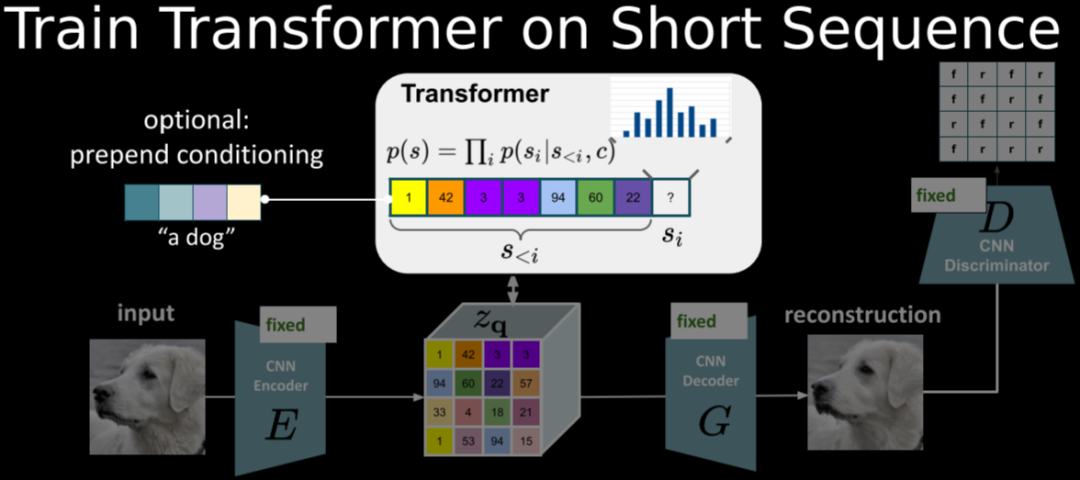







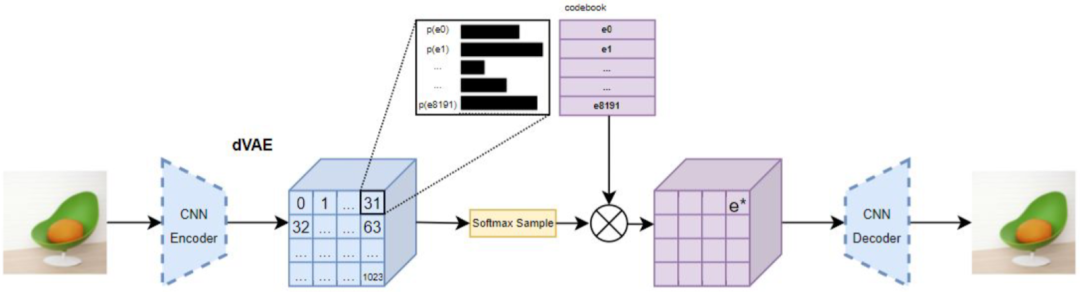
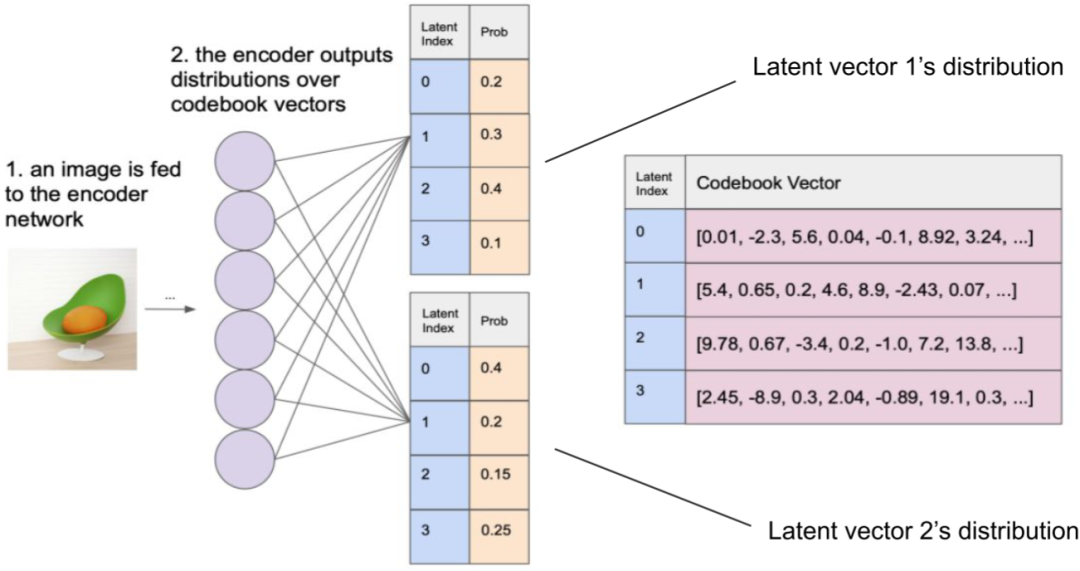
7.DALLE(dVAE)
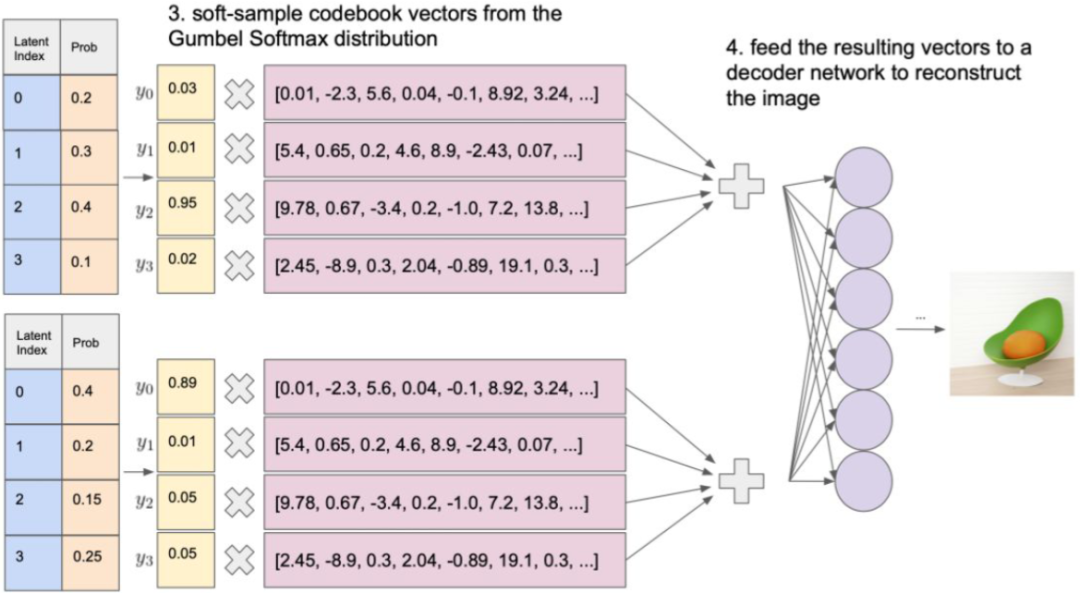
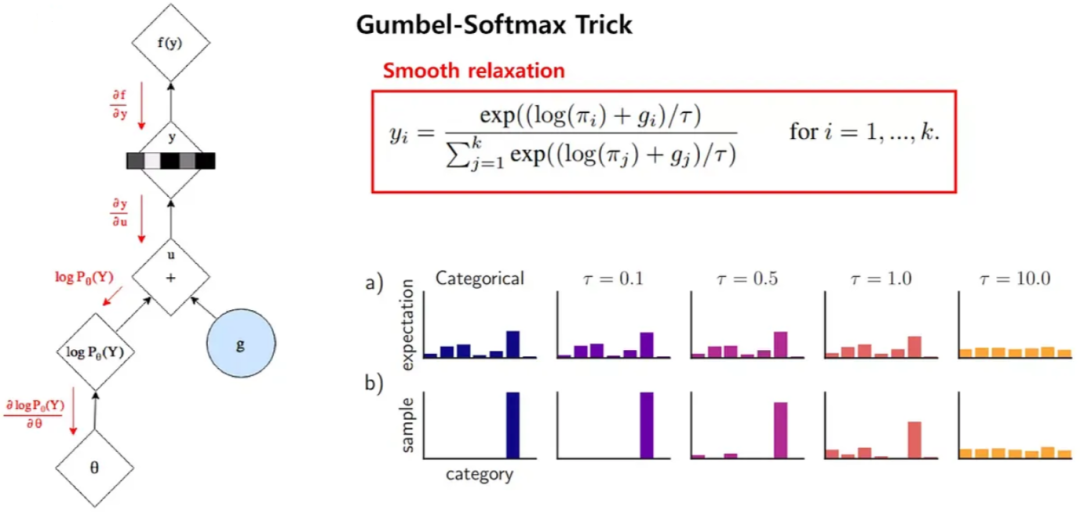
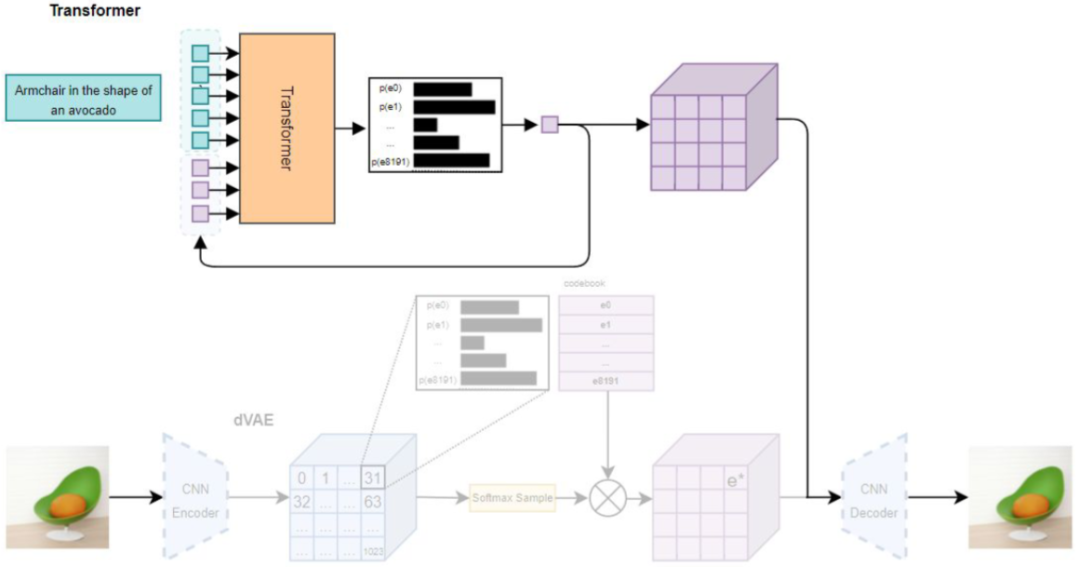
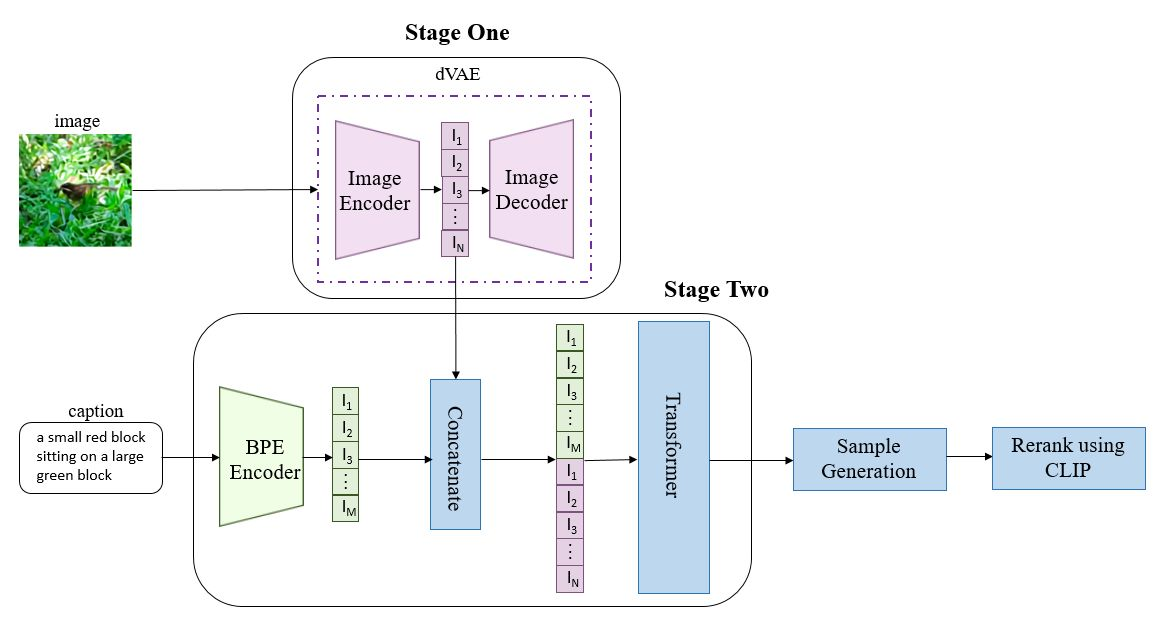
8.DALLE-mini
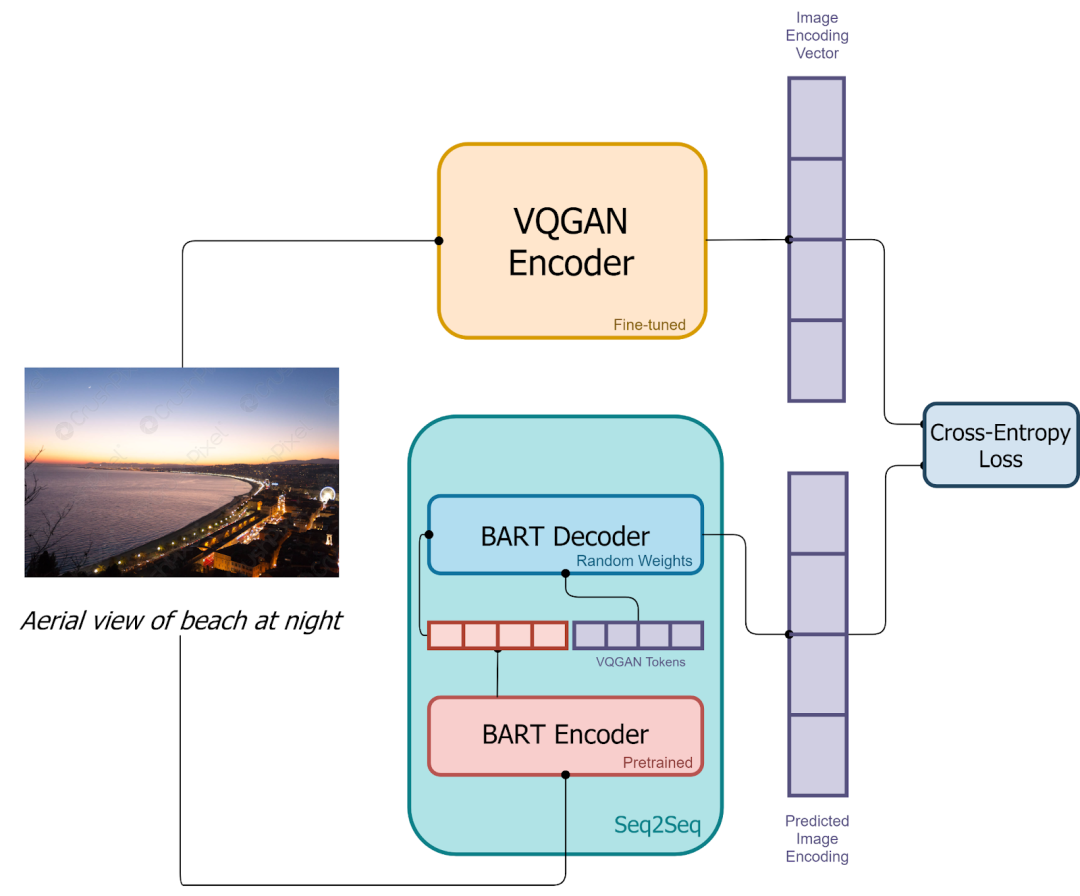
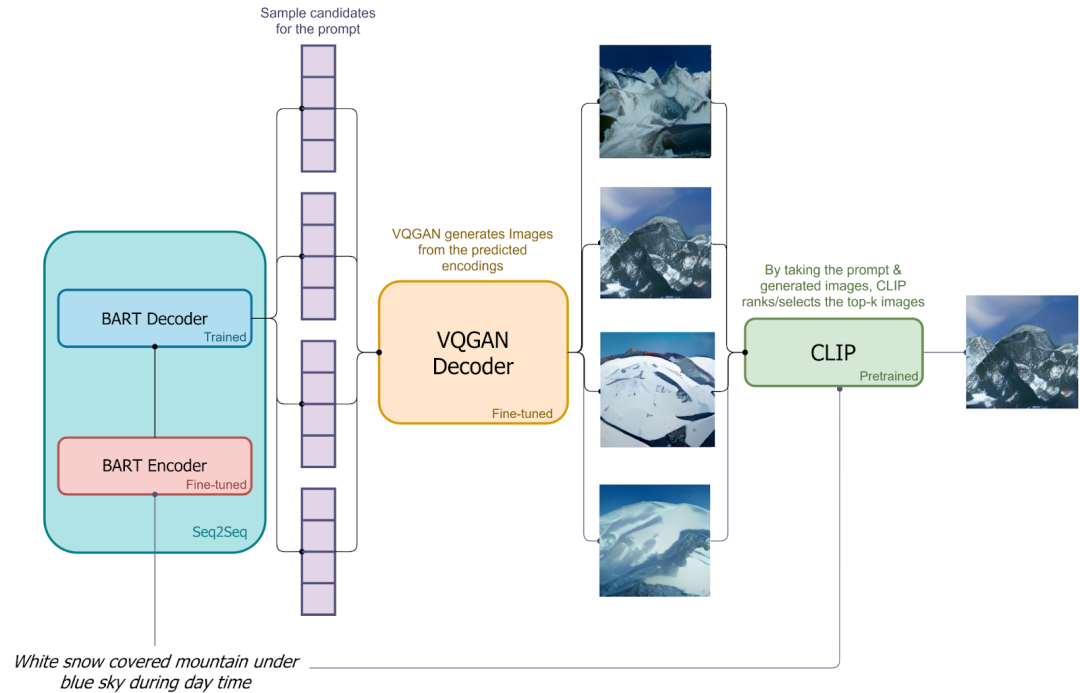
)



)

)




)




)


