
目錄
前言
一、項目概述
1.1 項目簡介
1.2 項目背景
1.3 項目目標
二、數據分析
2.1 導入庫
2.2 數據基本信息
三、畫像分析
3.1 畫像1:消費金額Top10
3.2 畫像2:高頻消費Top10
3.3 畫像3:人均消費金額Top10
3.4 畫像4:男女消費對比
3.5 畫像5:不同年齡的消費人數和金額
3.6 畫像6:不同性別+年齡的消費人數和金額
3.7 畫像7:不同城市,年齡消費金額
3.8 畫像8:不同婚姻狀態的消費次數和金額
3.9 畫像9:城市停留時間
3.10 畫像10:銷售額Top20商品
3.11 畫像11:二八法制
3.12 畫像12:商品種類
總結
🌈嗨!我是Filotimo__🌈。很高興與大家相識,希望我的博客能對你有所幫助。
💡本文由Filotimo__??原創,首發于CSDN📚。
📣如需轉載,請事先與我聯系以獲得授權??。
🎁歡迎大家給我點贊👍、收藏??,并在留言區📝與我互動,這些都是我前進的動力!
🌟我的格言:森林草木都有自己認為對的角度🌟。
?
 ?
?
前言
當人們提及“黑色星期五”,往往會想到各大商店推出的特賣活動。不過,這個概念也被廣泛應用于數據科學領域中。這里我們使用了一個名為“black friday sale”(黑色星期五)的數據集,其收集了有關商品銷售信息的大量數據,可用于進行市場營銷、數據挖掘和機器學習等方面的研究。
該數據集由Kaggle平臺上的Mehak Mittal提供,收集了2012年度black friday sale(黑色星期五)期間的購物交易數據。具體而言,數據集中包含了來自一個零售商店的大約54萬條交易記錄,每條記錄包括了以下信息:用戶ID、性別、年齡、職業、城市類別、產品ID、產品類別、購買量、單位價格和銷售日期等。
一、項目概述
1.1 項目簡介
項目名為:黑色星期五畫像分析
本項目旨在利用Jupyter編程來分析和呈現黑色星期五購物季的消費行為和趨勢。通過對大量的購物數據進行統計和可視化分析,我們將揭示黑色星期五的消費者畫像和購物模式,為商家和市場營銷人員提供有針對性的策略和決策支持。
1.2 項目背景
黑色星期五是美國傳統的購物狂歡日,標志著購物季的開始。消費者通常在此時享受到各種折扣和促銷活動,商家也通過此次活動刺激銷售和推廣產品。隨著互聯網和電商的發展,黑色星期五變得更加國際化,各個國家和地區都參與其中。購物數據的規模龐大,為深入了解消費者行為和趨勢提供了機會。
1.3 項目目標
1.?分析消費者畫像:通過購物數據分析,揭示不同人群的消費偏好、購買習慣和興趣愛好等。比如,不同年齡段、性別和地域的消費者在黑色星期五的購物行為有何異同。
2.?探索購物模式:研究消費者在購物季的消費決策模式、選購行為和購物渠道等,幫助商家了解消費者思維和行動路徑,優化產品定位和促銷策略。
3.?可視化數據分析:利用Jupyter的強大可視化能力,將分析結果以圖表、圖像和動態展示的形式呈現,使數據更具直觀性和可理解性,幫助更多人快速理解和應用分析結果。
二、數據分析
2.1 導入庫
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import matplotlib.patches as mpatches
import matplotlibplt.rcParams["font.sans-serif"]=["SimHei"]#設置字體為黑體以支持中文顯示
plt.rcParams["axes.unicode_minus"]=False # 解決負號顯示問題import plotly.graph_objects as go
import plotly.express as px
from plotly.subplots import make_subplots
from plotly.offline import init_notebook_mode,iplotimport warnings
warnings.filterwarnings("ignore") # 忽略警告信息說明:我是在學校機房,使用jupyter(ml)操作的,導入庫時發現缺少了plotly庫,然后我在jupyter文件夾下打開了cmd命令行,輸入了pip install plotly -i https://pypi.tuna.tsinghua.edu.cn/simple/,成功下載了plotly庫,這里使用的是清華鏡像源。
2.2 數據基本信息
(1)導入數據
df = pd.read_csv("C:/Users/Administrator/Desktop/black friday sale/train.csv") # 從CSV文件中讀取數據并存儲在DataFrame中
df # 打印DataFrame中的數據截圖:
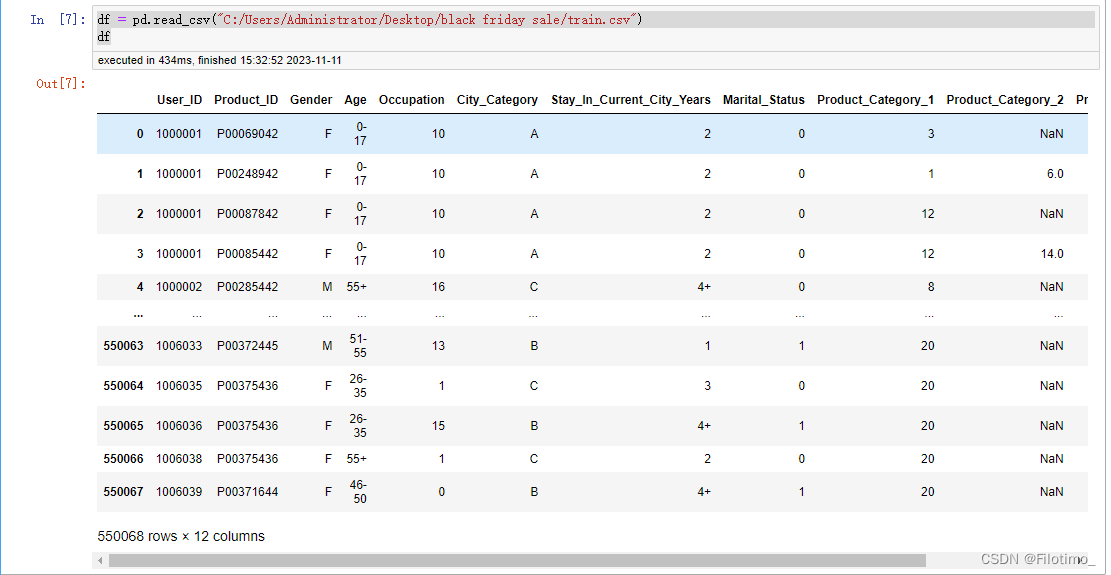 ?
?
說明:這里要下載我上傳的資源"black friday sale(黑色星期五)數據集",然后要修改一下代碼中的文件路徑。
(2)基本信息
df.shape ?# 顯示DataFrame的形狀(行數和列數)df.dtypes ?# 顯示每一列的數據類型df.isnull().sum()#統計每一列的空值數量df.info()#顯示DataFrame的基本信息,包括索引、數據類型和內存信息(3)缺失值可視化
import missingnodf.isna().sum()/df.shape[0]#計算每一列的缺失值占比missingno.matrix(df) #繪制缺失值矩陣圖
plt.show()#顯示圖形missingno.bar(df, color="blue")#繪制缺失值條形圖
plt.show()#顯示圖形說明:我操作時缺少了missingno庫,然后我仍在jupyter文件夾下打開了cmd命令行,輸入pip install missingno -i https://pypi.tuna.tsinghua.edu.cn/simple/,成功下載了missingno庫,這里使用的還是清華鏡像源。
(4)總信息
df["User_ID"].nunique()#統計"User_ID"列的唯一值數量df["Product_ID"].nunique()#統計"Product_ID"列的唯一值數量sum(df["Purchase"])#計算"Purchase"列的總和(5)商品類別
df["Product_Category_1"].nunique()#統計"Product_Category_1"列的唯一值數量df["Product_Category_2"].nunique()#統計"Product_Category_2"列的唯一值數量三、畫像分析
3.1 畫像1:消費金額Top10
df1 = df.groupby("User_ID")["Purchase"].sum().reset_index()#按照用戶分組,計算消費金額總和
df2 = df1.sort_values("Purchase", ascending=False)#按照消費金額進行降序排列
df2["User_ID"] = df2["User_ID"].apply(lambda x: "id_" + str(x))#將User_ID轉換成字符串格式,并加上前綴"id_"df2 #打印處理后的數據框df2#使用Plotly創建條形圖
fig = px.bar(df2[:10],#僅顯示前10名用戶x="User_ID",#x軸為User_IDy="Purchase",#y軸為Purchasetext="Purchase")#設置顯示文本為Purchase列的值
fig.show()#顯示圖形這段代碼首先按照用戶ID分組,計算了每個用戶的消費總金額,并按照消費總金額進行降序排列。然后使用Plotly庫創建了一個條形圖,顯示了消費金額排名前10的用戶。
 ?
?
從圖中可以看到,id_1004277的用戶消費最高,達到了1千多萬。
3.2 畫像2:高頻消費Top10
df3 = df.groupby("User_ID").size().reset_index()#按照用戶分組,計算每個用戶的購買次數
df3.columns = ["User_ID", "Number"]#重命名列名為"User_ID"和"Number"
df4 = df3.sort_values("Number", ascending=False)#按照購買次數進行降序排列df4.head(10)#顯示排名前10的高頻消費用戶信息df4["User_ID"] = df4["User_ID"].apply(lambda x: "id_" + str(x))#將User_ID轉換成字符串格式,并加上前綴"id_"#使用Plotly創建帶顏色的條形圖
fig = px.bar(df4[:10],#僅顯示前10名用戶x="User_ID",#x軸為User_IDy="Number",#y軸為Number(購買次數)text="Number",#設置顯示文本為Number列的值color="Number")#設置顏色為Number列的值
fig.show()#顯示圖形這段代碼首先按照用戶ID分組,計算了每個用戶的購買次數,并按照購買次數進行降序排列。然后使用Plotly庫創建了一個帶顏色的條形圖,顯示了購買次數排名前10的用戶。不同的購買次數會用不同的顏色表示。
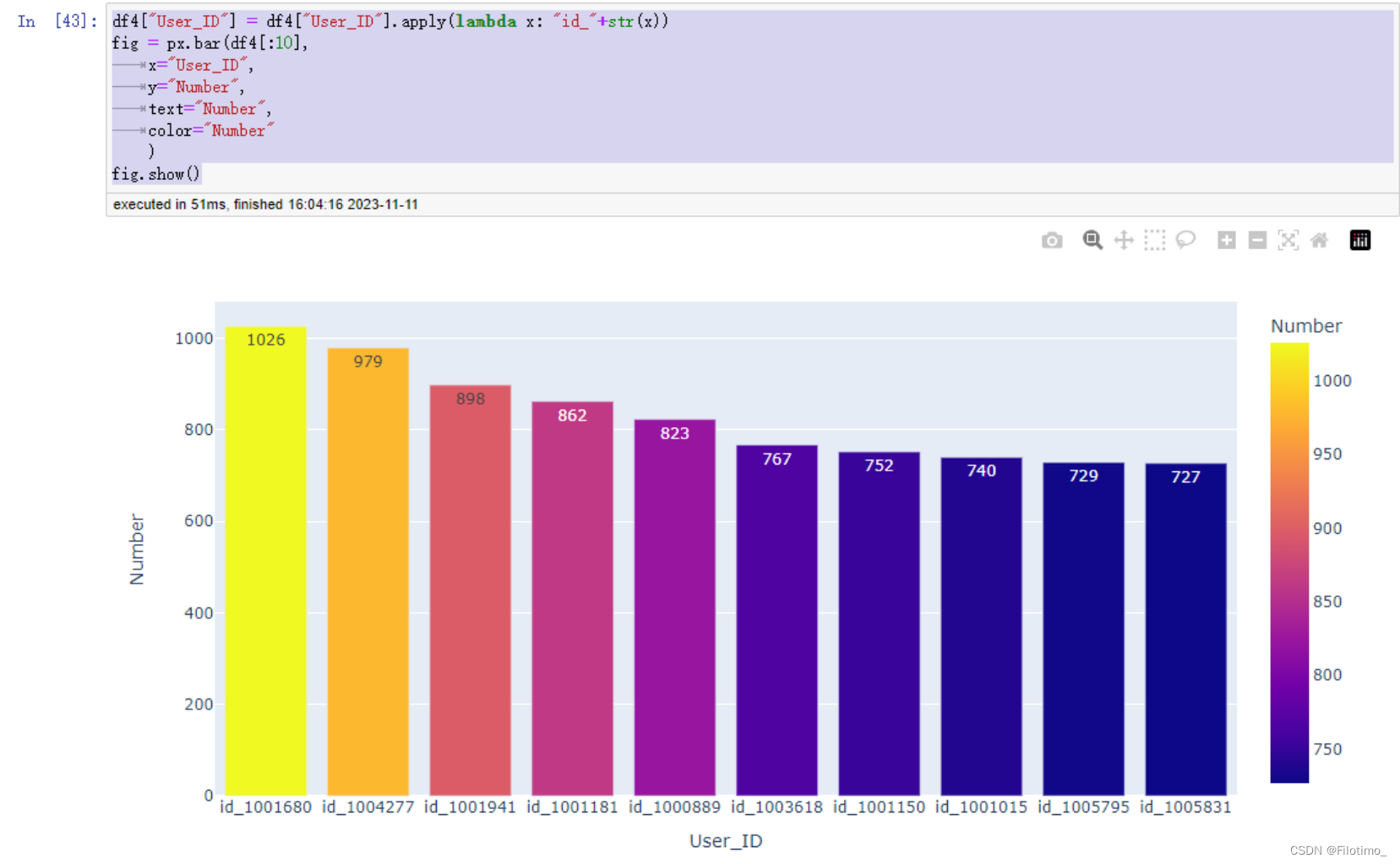 ?
?
3.3 畫像3:人均消費金額Top10
df5 = pd.merge(df2, df4) ?# 合并df2和df4,根據User_ID字段進行合并
df5["Average"] = df5["Purchase"] / df5["Number"] ?# 計算人均消費金額,即每位用戶的總消費金額除以購買次數
df5["Average"] = df5["Average"].apply(lambda x: round(x, 2)) ?# 將人均消費金額保留兩位小數df5.head() ?# 顯示合并后的數據框df5的前幾行,可選# 使用Plotly創建散點圖
fig = px.scatter(df5,x="User_ID", ?# x軸為User_IDy="Average", ?# y軸為Average(人均消費金額)color="Average") ?# 按照人均消費金額進行顏色編碼
fig.show() ?# 顯示散點圖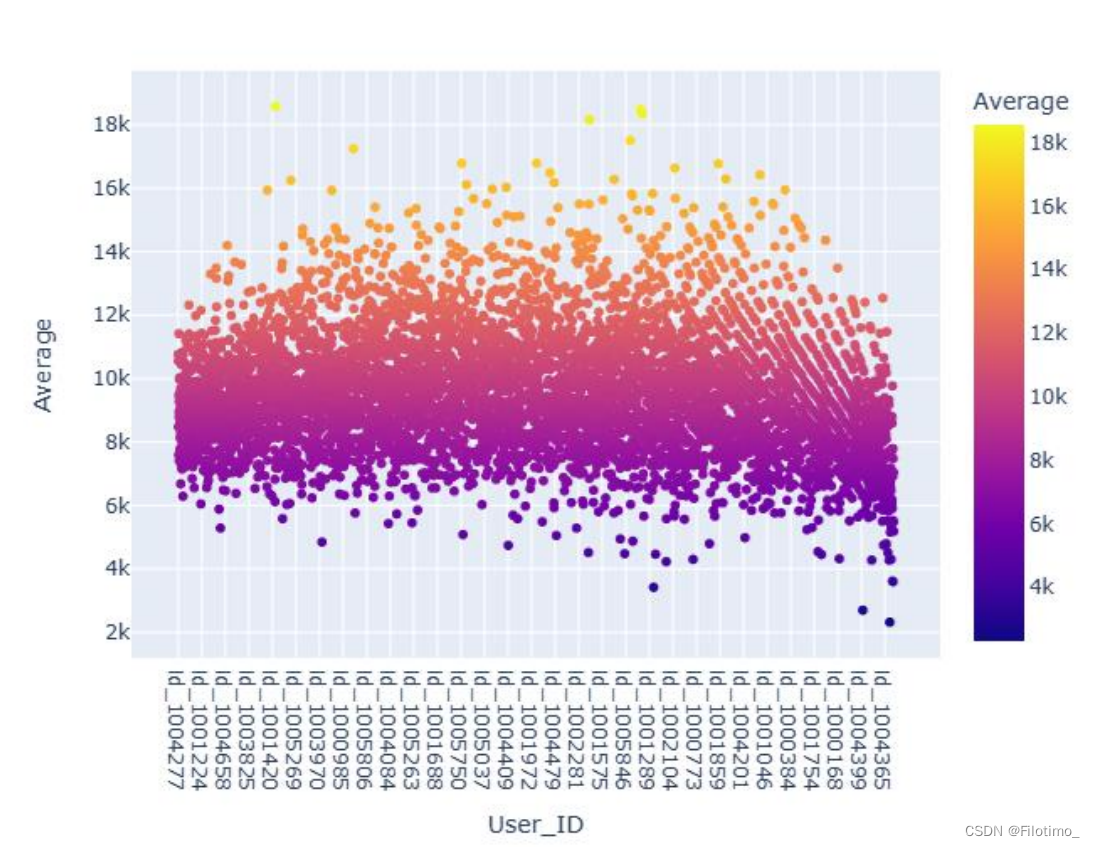 ?
?
# 使用Plotly創建小提琴圖
px.violin(df5["Average"]) ?# 傳入人均消費金額數據繪制小提琴圖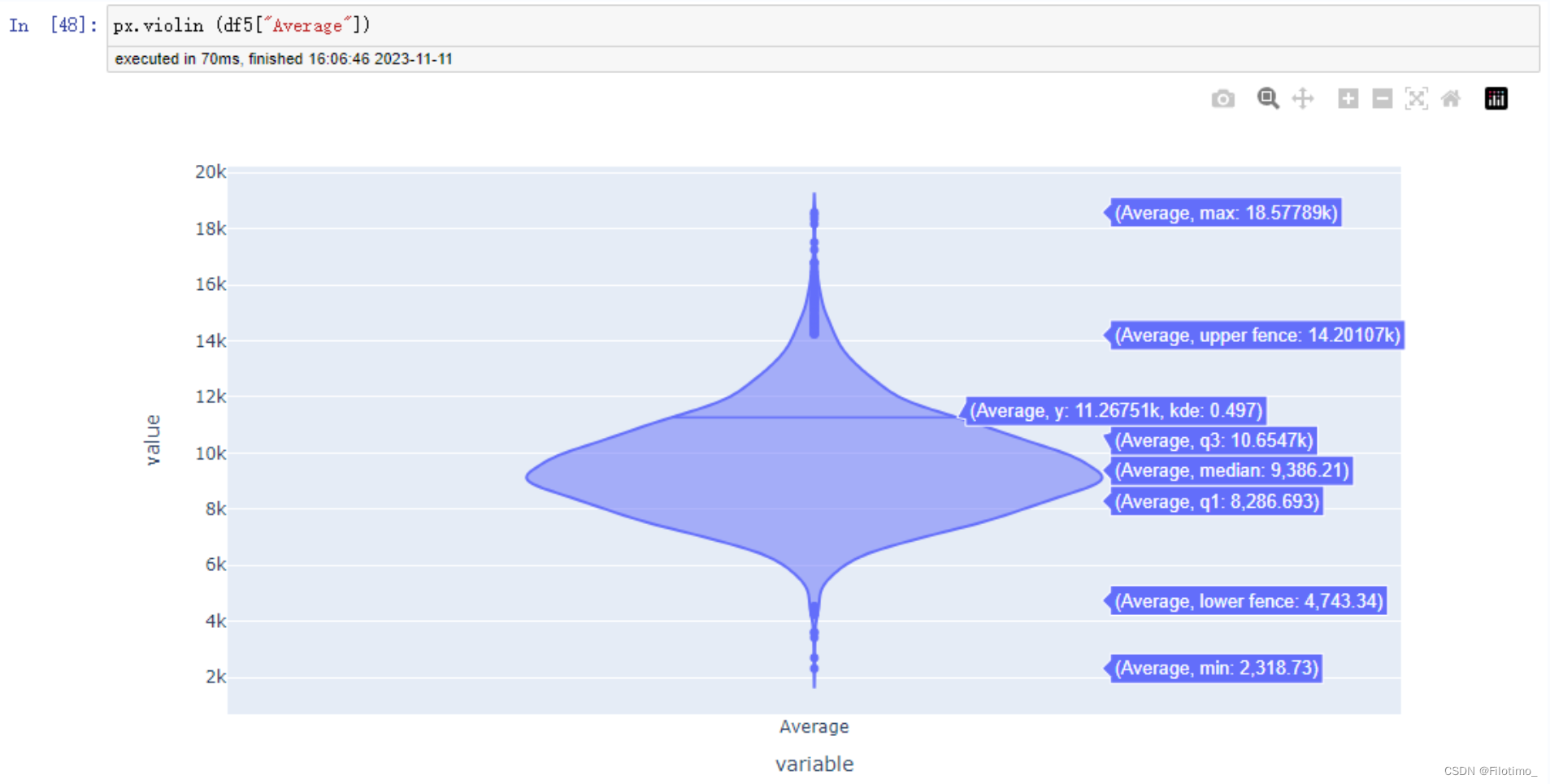 ?
?
這段代碼首先將df2和df4兩個數據框根據User_ID字段進行合并,得到df5。然后計算了每位用戶的人均消費金額,即每位用戶的總消費金額除以購買次數,并保留兩位小數。接著使用Plotly庫創建了一個人均消費金額Top10的散點圖,圖中的顏色表示不同的人均消費金額。還使用Plotly庫創建了一個小提琴圖,展示整體的人均消費金額分布情況。
從上面的兩張圖中可以分析出,用戶的平均消費金額大約是在8k至10k之間。
3.4 畫像4:男女消費對比
# 對數據進行分組,計算不同性別的用戶數量和消費金額總和
df6 = df.groupby("Gender").agg({"User_ID": "nunique", "Purchase": "sum"}).reset_index()
df6labels = df6['Gender'].tolist() ?# 將性別轉換為標簽列表# 創建包含兩個子圖的餅圖
fig = make_subplots(rows=1,cols=2,subplot_titles=["男女消費次數", "男女消費金額"],specs=[[{'type': 'domain'}, {'type': 'domain'}]])# 添加第一個餅圖,顯示男女用戶的消費次數
fig.add_trace(go.Pie(labels=labels,values=df6['User_ID'].tolist(),name='UserID'),row=1,col=1
)# 添加第二個餅圖,顯示男女用戶的消費金額
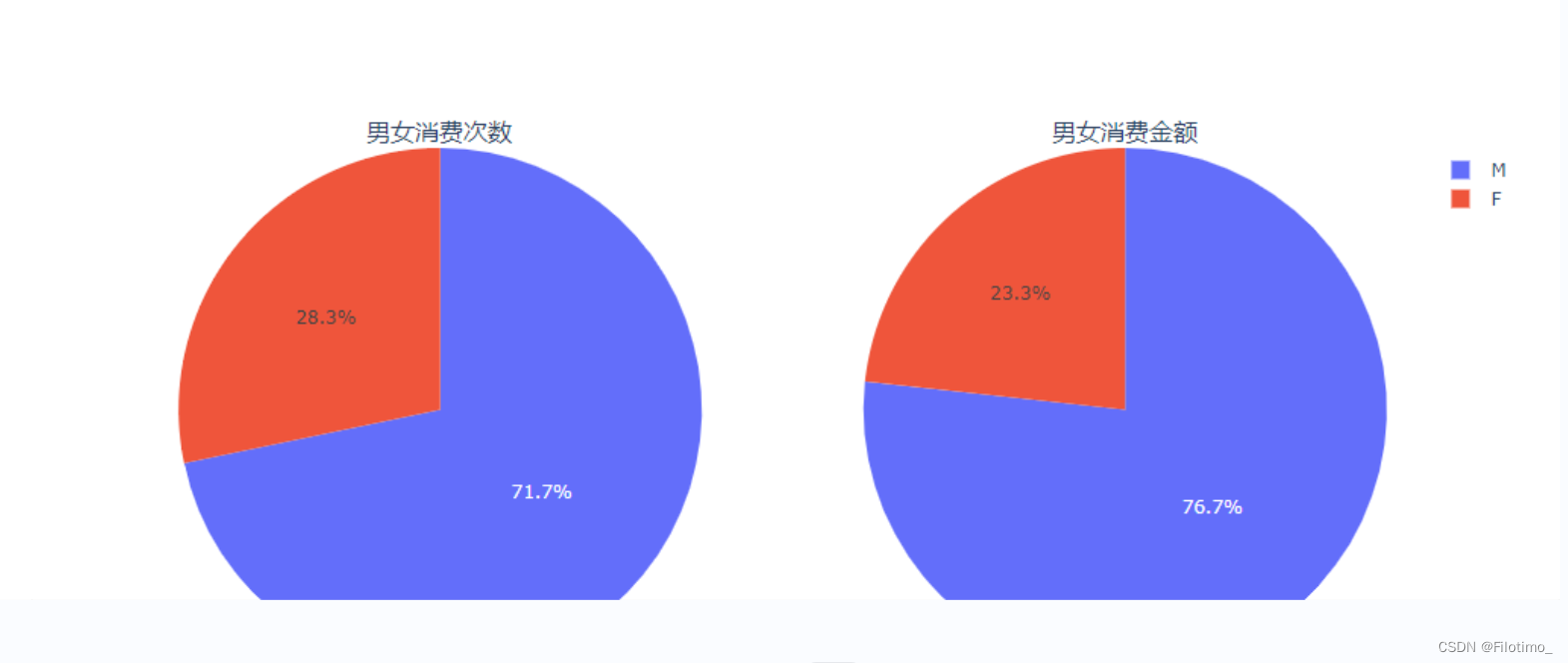
fig.add_trace(go.Pie(labels=labels,values=df6['Purchase'].tolist(),name=' Purchase'),1, 2)fig.show() ?# 顯示圖形這段代碼首先對數據按照性別進行分組,使用agg函數計算了不同性別的用戶數量和消費金額總和,并將結果保存在df6中。然后將性別轉換為標簽列表。接著使用Plotly庫的make_subplots函數創建一個包含兩個子圖的餅圖對象,分別用于展示男女用戶的消費次數和消費金額。使用go.Pie函數創建了兩個餅圖的數據,并通過add_trace方法將它們添加到對應的子圖中。最后使用fig.show()方法顯示圖形。
 ?
?
從圖中(F紅色代表女性,M藍色代表男性)可以看到,男性是消費的主力軍。
3.5 畫像5:不同年齡的消費人數和金額
df7 = df.groupby("Age").agg({"User_ID" :"nunique" ,"Purchase" :"sum"}).reset_index()
df7labels = df7['Age'].tolist()
fig = make_subplots(rows=1, ? ? ? ? ? ? ? ? ? ?cols=2,subplot_titles=["不同age消費次數","不同age消費金額"],specs=[[{'type':'domain'}, {'type':'domain'}]])
fig.add_trace(go.Pie(labels=labels,values=df7['User_ID'].tolist(),name='UserID'),row=1,col=1)
fig.add_trace(go.Pie(labels=labels,values=df7['Purchase'].tolist(),name='Purchase'),row=1,col=2)
fig.update_layout(height=500, width=800)
fig.show()這段代碼首先對數據按照年齡進行分組,使用agg函數計算了不同年齡段的用戶數量和消費金額總和,并將結果保存在df7中。然后將年齡轉換為標簽列表。接著使用Plotly庫的make_subplots函數創建一個包含兩個子圖的餅圖對象,分別用于展示不同年齡段用戶的消費次數和消費金額。使用go.Pie函數創建了兩個餅圖的數據,并通過add_trace方法將它們添加到對應的子圖中。最后使用fig.update_layout方法更新圖形的高度和寬度,并使用fig.show()方法顯示圖形。
 ?
?
從上面兩張圖可以看到,26-25這個年齡段消費占比最高,這可能是因為這個年齡段的人,大多都已經有了一個穩定的工作、穩定的收入,所以他們可以放心大膽的去消費。
3.6 畫像6:不同性別+年齡的消費人數和金額
# 對數據進行分組,計算不同性別和年齡段的用戶數量和消費金額總和
df8 = df.groupby(["Gender", "Age"]).agg({"User_ID": "nunique", "Purchase": "sum"}).reset_index()
df8# 創建樹狀圖,展示不同性別和年齡段的用戶消費金額
fig = px.treemap(df8, path=[px.Constant("all"), "Gender", "Age"], values="Purchase")fig.update_traces(root_color="lightskyblue") ?# 設置樹狀圖的根節點顏色
fig.update_layout(margin=dict(t=30, l=20, r=25, b=30)) ?# 更新圖形的邊距
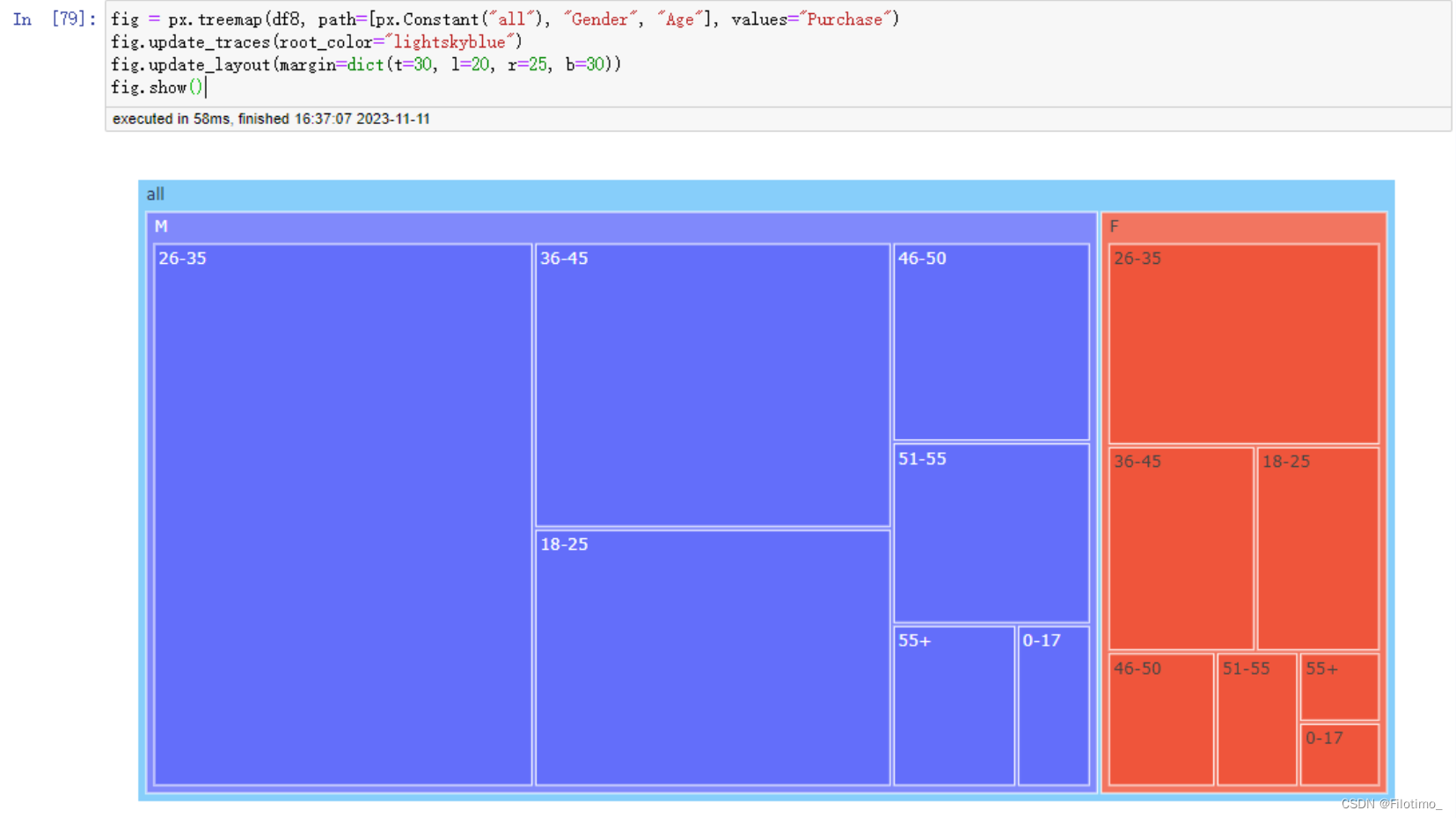
fig.show() ?# 顯示圖形這段代碼首先對數據按照性別和年齡段進行分組,使用agg函數計算了不同性別和年齡段的用戶數量和消費金額總和,并將結果保存在df8中。接著,使用px.treemap函數創建一個樹狀圖,設置了路徑為[“all”, “Gender”, “Age”],表示樹狀圖中的層級關系。在樹狀圖中,不同性別和年齡段將根據消費金額的大小顯示為不同的顏色和大小。根據圖的展示,可以直觀地比較不同性別和年齡段的用戶消費金額。最后,使用fig.show()函數顯示圖形。
 ?
?
3.7 畫像7:不同城市,年齡消費金額
# 對數據進行分組,計算不同城市和年齡段的用戶數量和消費金額總和
df9 = df.groupby(["City_Category", "Age"]).agg({"User_ID": "nunique", "Purchase": "sum"}).reset_index()
df9# 創建條形圖,展示不同城市和年齡段的消費金額
fig = px.bar(df9, x="City_Category", y="Purchase", color="Age", barmode="group", text="Purchase")fig.update_layout(title="不同城市不同年齡段的消費金額") ?# 設置圖形標題
fig.show() ?# 顯示圖形這段代碼首先對數據按照城市和年齡段進行分組,使用agg函數計算了不同城市和年齡段的用戶數量和消費金額總和,并將結果保存在df9中。接著,使用px.bar函數創建一個條形圖,設置了x軸為城市類別,y軸為消費金額,顏色編碼為年齡段,以及分組模式為"group",以展示不同城市和年齡段的消費金額。使用update_layout方法設置了圖形標題為"不同城市不同年齡段的消費金額"。最后使用fig.show()方法顯示圖形。
 ?
?
從3個城市來看,26-35這個年齡段的人一直是消費的主力軍。
3.8 畫像8:不同婚姻狀態的消費次數和金額
# 對數據進行分組,計算不同婚姻狀況的用戶數量和消費金額總和
df10 = df.groupby(["Marital_Status"]).agg({"User_ID":"nunique", "Purchase":"sum"}).reset_index()
df10# 將婚姻狀況的數值映射為對應的標簽
df10["Marital_Status"] = df10["Marital_Status"].map({0:"未婚",1:"已婚"})# 創建餅圖,展示婚姻狀況對應的消費金額
fig = px.pie(names=df10["Marital_Status"], values=df10["Purchase"])fig.update_traces(textposition='inside', textinfo='percent+label') ?# 設置標簽的位置和信息
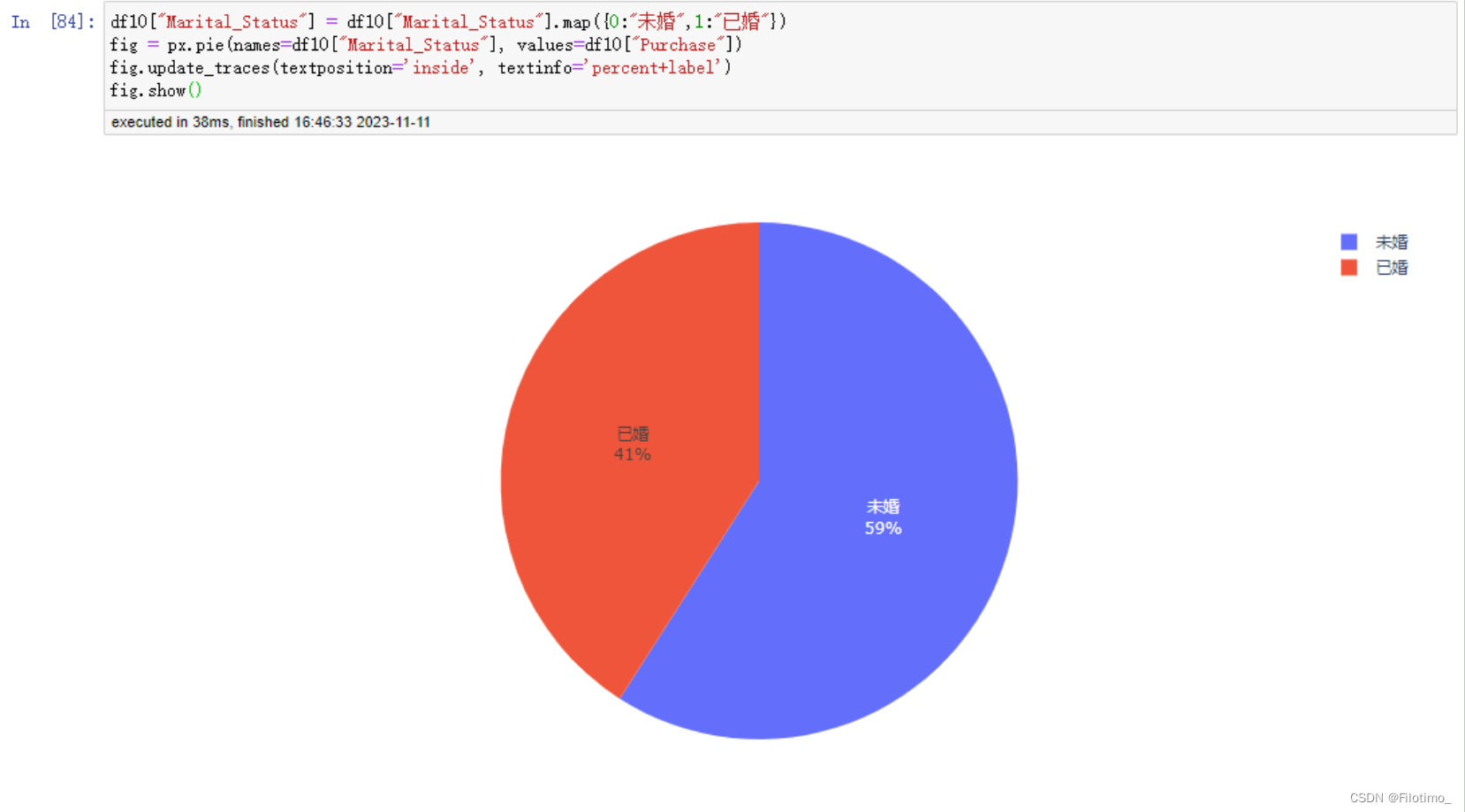
fig.show() ?# 顯示圖形這段代碼首先對數據按照婚姻狀況進行分組,使用agg函數計算了不同婚姻狀況的用戶數量和消費金額總和,并將結果保存在df10中。然后,通過map方法將婚姻狀況的數值映射為對應的標簽,將0映射為"未婚",將1映射為"已婚"。接著,使用px.pie函數創建一個餅圖,設置了信心為婚姻狀況標簽,值為對應的消費金額。使用update_traces方法設置標簽的位置為內部,并展示百分比和標簽信息。最后使用fig.show()方法顯示圖形。
 ?
?
從圖中可以看到,在未婚情況下,消費的力度更大。
3.9 畫像9:城市停留時間
# 創建小提琴圖,展示不同居住年限的購買金額分布
fig = px.violin(df,y="Purchase",color="Stay_In_Current_City_Years") ?
?
# 對數據進行分組,計算不同居住年限的用戶數量和購買金額總和
df11 = (df.groupby(["Stay_In_Current_City_Years"]).agg({"User_ID":"nunique", "Purchase":"sum"}).reset_index())
df12 = df11.sort_values("User_ID", ascending=False)
df12# 將不同居住年限的階段轉換為列表
stages = df12["Stay_In_Current_City_Years"].tolist()# 創建漏斗圖,展示不同居住年限的用戶數量情況
fig = px.funnel_area(values=df12["User_ID"].tolist(),names=stages)
fig.show()這段代碼首先使用px.violin函數創建了一個小提琴圖,設置y軸為購買金額,顏色編碼為居住年限,以展示不同居住年限下購買金額的分布情況。接著,通過對數據進行分組和聚合得到了不同居住年限的用戶數量和購買金額總和,并將結果保存在df11和df12中。然后,通過sort_values方法對df12進行排序,按用戶數量降序排列。在接下來的代碼中,將不同居住年限的階段轉換為列表,并使用px.funnel_area函數創建了一個漏斗圖,用于展示不同居住年限的用戶數量情況。最后使用fig.show()方法顯示圖形。
 ?
?
從圖中可以發現,在一個城市居住了1-2年的用戶是消費的主力。
3.10 畫像10:銷售額Top20商品
# 對數據按產品ID進行分組,計算每個產品的銷售額總和
df13 = df.groupby(["Product_ID"]).agg({"Purchase" :"sum"}).reset_index()# 將銷售額轉換為以萬為單位,并且保留兩位小數
df13["Purchase"] = df13["Purchase"].apply(lambda x: round(x / 10000, 2))# 按銷售額降序排列產品
df13.sort_values("Purchase", ascending=False, inplace=True)
df13# 創建條形圖,展示銷售額排名前10的產品
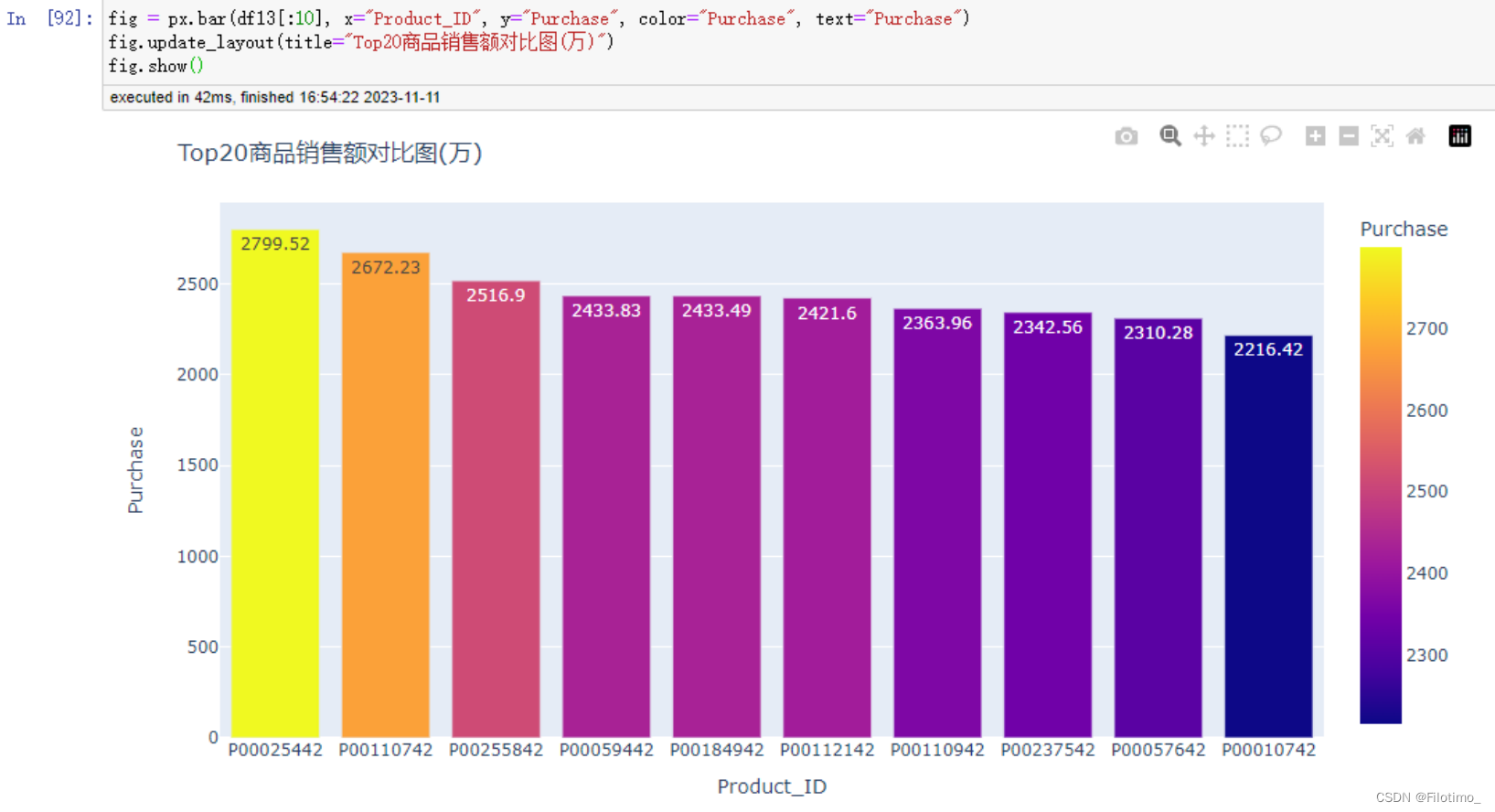
fig = px.bar(df13[:10], x="Product_ID", y="Purchase", color="Purchase", text="Purchase")
fig.update_layout(title="Top20商品銷售額對比圖(萬)")
fig.show()
這段代碼首先對數據按產品ID進行分組,使用agg函數計算了每個產品的銷售額總和,并將結果保存在df13中。然后,通過apply和lambda函數將銷售額轉換為以萬為單位,并且保留兩位小數。接著,使用sort_values方法將產品按銷售額降序
 ?
?
3.11 畫像11:二八法制
# 計算銷售額排名前20%的產品數量
top20 = int(df13["Product_ID"].nunique() * 0.2)
top20# 計算銷售額排名前20%的產品的銷售額總和占總銷售額的比例
top20_sales_percentage = sum(df13[:top20]["Purchase"]) / sum(df13["Purchase"])
top20_sales_percentage在這段代碼中,首先計算了銷售額排名前20%的產品數量,然后通過取前20%的產品銷售額總和除以總銷售額,計算得出了銷售額排名前20%的產品所占總銷售額的比例。
 ?
?
從計算結果可以發現,銷售額排名前20%的產品占據了總銷售額的73%,大致上是符合"二八法制"的。
3.12 畫像12:商品種類
# 對數據按產品類別進行分組,并計算每個產品類別的銷售額總和
df14 = df.groupby(["Product_Category_1"]).agg({"Purchase": "sum"}).reset_index()# 創建餅圖,展示每個產品類別的銷售額占比
fig = px.pie(names=df14["Product_Category_1"],values=df14["Purchase"],hole=0.5)
fig.update_traces(textposition='inside', ?# 將標簽放置在餅圖內部textinfo='percent+label' ?# 標簽信息包括百分比和標簽
)
fig.show() ?
?
# 創建箱線圖,展示不同產品類別的銷售額分布情況
px.box(df,x="Product_Category_1",y="Purchase",color="Product_Category_1")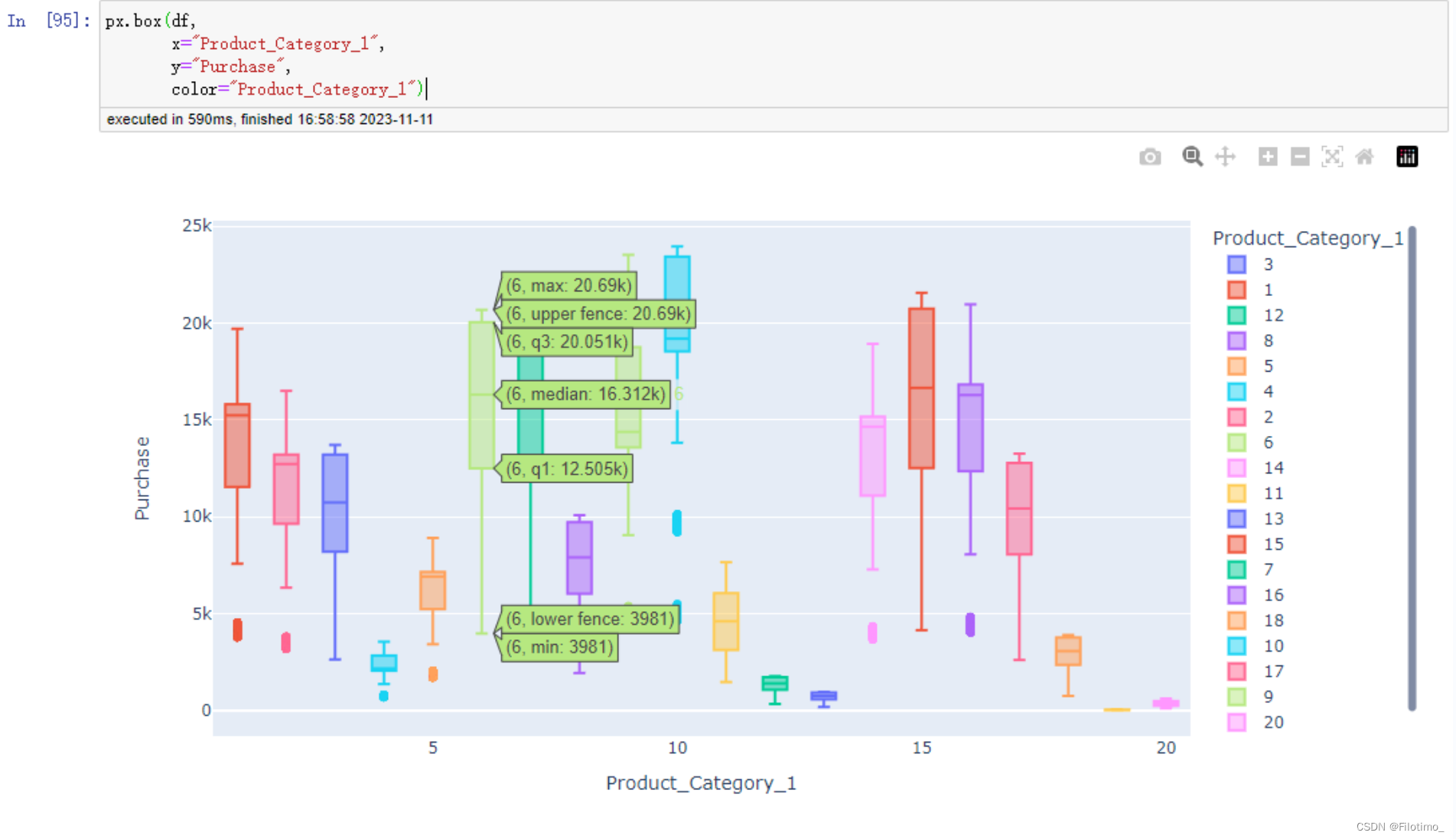 ?
?
在這段代碼中,首先對數據框按照"Product_Category_1"進行分組,然后使用agg函數計算每個產品類別的銷售額總和,并將結果保存在df14數據框中。接下來,使用px.pie函數創建了一個餅圖,其中names參數指定了產品類別的名稱,values參數指定了對應的銷售額,hole參數設置了餅圖的內部空洞大小。使用update_traces方法將餅圖的標簽放置在內部,并且標簽信息包括百分比和標簽文本。最后使用fig.show()顯示了該餅圖。接下來,使用px.box函數創建了一個箱線圖。在箱線圖中,x參數指定了產品類別的名稱,y參數指定了銷售額的值,而color參數則用于給不同的產品類別區分顏色。最后,使用px.box函數創建的箱線圖可以顯示不同產品類別的銷售額分布情況。
總結
文中所使用的數據集可用于廣泛的數據研究目的。例如,我們可以利用該數據集來分析特定消費群體的購物行為。通過數據挖掘和機器學習技術,我們可以發現哪些消費者更可能購買某個產品、哪些消費群體對某一個產品類別更感興趣等。這些信息可以向商家提供寶貴的市場營銷策略,例如發布定向廣告、優化產品設計、提高產品質量等。此外,還可以用該數據集研究不同城市、不同年齡和收入階層等人群對各種產品類型的需求有何不同,了解市場的潛在需求。

)




)




的需求規范)

)





