官方學習資料
????????主要是的學習資料是,?官方文檔 和官方博客。相關文章還是挺多 挺不錯的 他們更新也比較及時。有最新的東西 都會更新出來。
es scdn官方博客
這里簡單列一些,還有一些其他的,大家自己感興趣去看。
什么是向量數據庫
Elasticsearch:向量數據庫的真相-CSDN博客
什么是向量嵌入
什么是大語言模型(LLM)
什么是語義搜索
向量搜索的優勢
什么是機器學習
關于多模態
????????這個是多模態檢索。目前es只能做文本類轉向量的模型導入。不支持圖片轉向量的模型導入。(clip是雙塔模型,一個負責文本轉向量,一個負責圖片轉向量。我測過了,圖片轉向量模型不支持導入)如果用es做多模態。還是要在外邊部署模型。 整體體驗不好。而且模型導入es,是收費的白金版。 最佳實踐(不付費玩法)應該是完全在外邊做轉向量。 考慮付費,可以用es
學術界前沿的研究對比
????????這個是學術稍微前沿一點的研究。里邊包含的論文,感興趣可以看看。里邊探討對比了關于BM25和向量檢索的效果。還包含稀疏向量相關的知識。
關于稀疏向量
??????? 稠密向量有一個致命問題。 檢索速度,以及做嵌入的速度。太慢,現在最先進的方向是稀疏向量
這里邊有對比 語義檢索 和 BM25的效果對比。(最佳實踐是兩者結合,做內容召回。兩者可以互補)根據官方提供的稀疏向量的模型測試結果如下圖所示,據說20個場景有19個都優遇BM25.
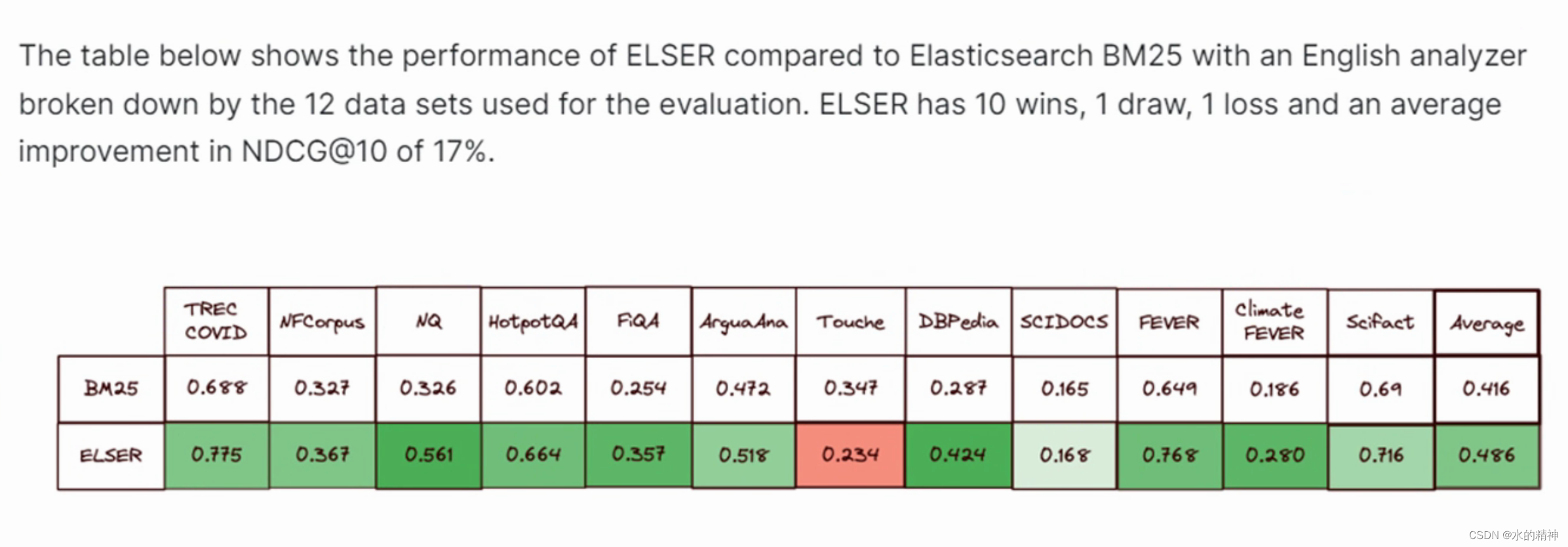 ?
?
這是稀疏向量模型的轉換效果,應該不會多花費空間。它的維度相對低。?
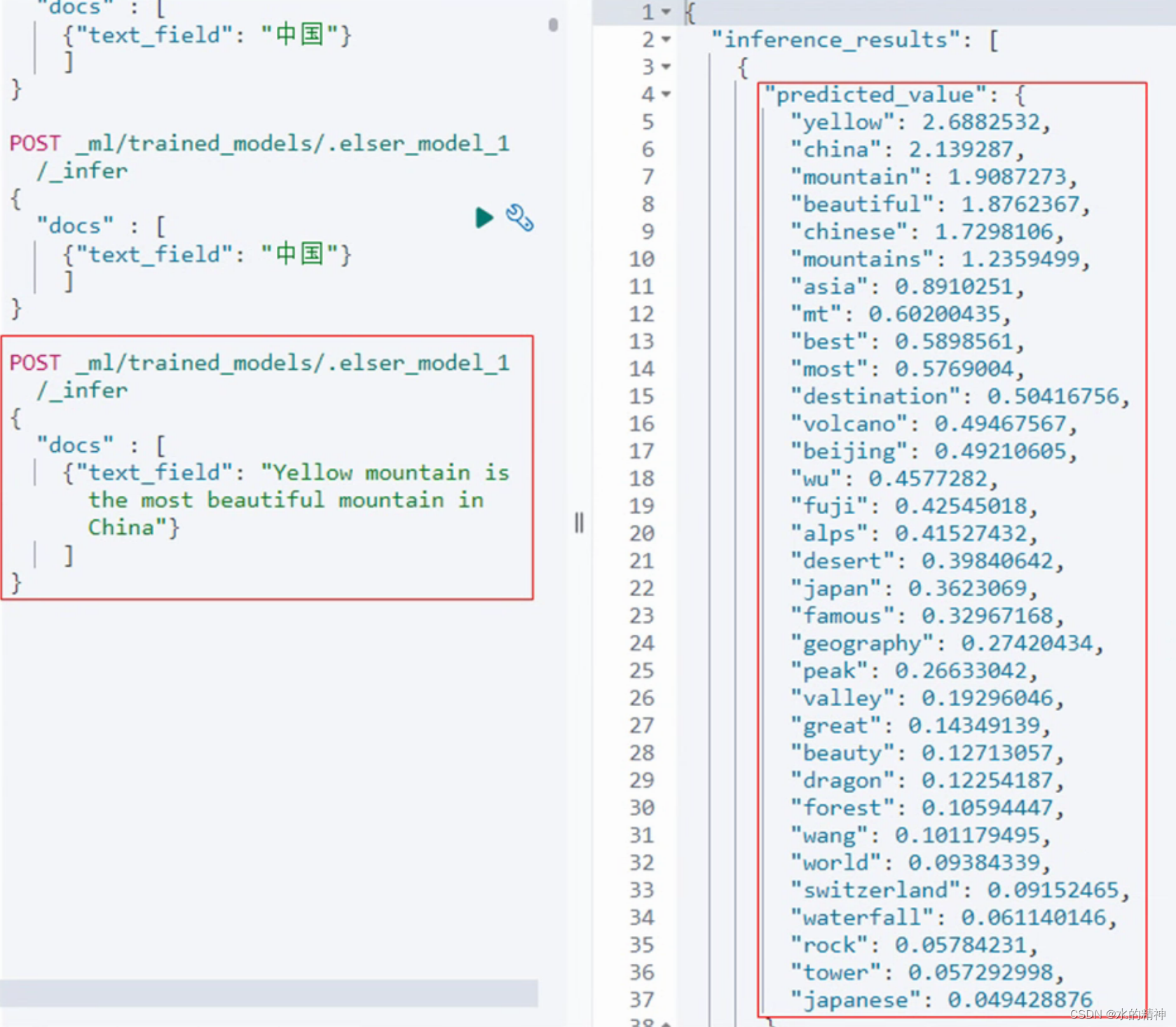 ?
?
這里有我的一篇文章,國內生產實踐經驗帖。ES-ELSER 如何在內網中離線導入ES官方的稀疏向量模型(國內網絡環境下操作方法)-CSDN博客
如何做向量嵌入
????????模型轉向量,簡單來講,是利用機器學習模型把一塊文本(數據),映射到網絡空間內,同樣問題(query)也是用同一個模型,映射到網絡空間內。然后計算cosin值,也就是夾角越小,就越相近。
? ? ? ? 我在生產實踐中,是選擇使用es來的機器學習模塊倒入hugging face上的NLP模型,來做文本嵌入。
? ? ? ? 這里有一篇我自己寫的國內環境下。如何在es中導入NLP模型。elasticsearch 內網下如何以離線的方式上傳任意的huggingFace上的NLP模型(國內避坑指南)-CSDN博客
? ? ? ? 這里還有一個例子,是在es中使用 E5 嵌入模型進行多語言向量搜索
向量檢索簡單舉個例子
????????data 是一篇文章的內容。這個內容最終可能是切分成N個片段。?然后通過模型把每個片段都轉成向量,然后再把向量存到向量庫。
例如,第一個段落 片段轉完是?[1.0000009,0.11111111,0.899998]
然后問題,也轉成向量可能是 [1.0044449,0.55551111,0.449998]
然后通過計算這兩個數組,的cosin值,然后再比較 其它片段和問題的cosin值(當然還可以用其它計算方式),然后做個排序,然后把topN小的返回。這就是KNN最鄰近搜索。
關于相關性或者說相似性
????????相似不相似,其實更多是依賴模型效果好不好。向量庫都只是起計算作用。關于向量庫的選擇,只需要看該向量數據庫的穩定性,數據承載能力(也就是能存多少數據,是否滿足業務需求。)已經向量數據庫實現的向量檢索算法都有哪些(實際上目前學術界也就那么多)。還有就是該庫的檢索性能如何,穩定性如何,能夠滿足業務需求。但是不要想著在向量數據庫上去提升搜索相關性的事情,因為相關性和庫沒有太大關系。如何要研究提升召回效果。應該去考慮選擇什么樣的機器學習模型效果更好,還要考慮模型的語言能力,是否支持多語種。例如你在英文模型下做中文數據的embedding,效果肯定會很差。此外不同的業務應該選擇自己的模型,加上微調。而不是一個大一統的模型。另外一個提升相關性的方向是探索數據切割的規則,針對不同類型的數據做不同的切分。
????????實際上利用向量檢索的相關性效果,還確實是比BM25好的。但是它不是絕對的,在關鍵詞精準匹配場景下,BM25算法更好一些。
如何選擇模型
語義檢索系統如何選擇合適的embedding模型-CSDN博客
使用模型做文本陷入,如何做數據切分,不丟失語義
? ? ? ? 目前這一塊探索還比較少。根據看過的一些案例,基本上推薦在500個token,300-400個字。再多了就會丟失語義。這里還需要摸索和測試一下。
ES支持混合檢索嗎? 向量檢索+倒排索引?
es ANN搜索
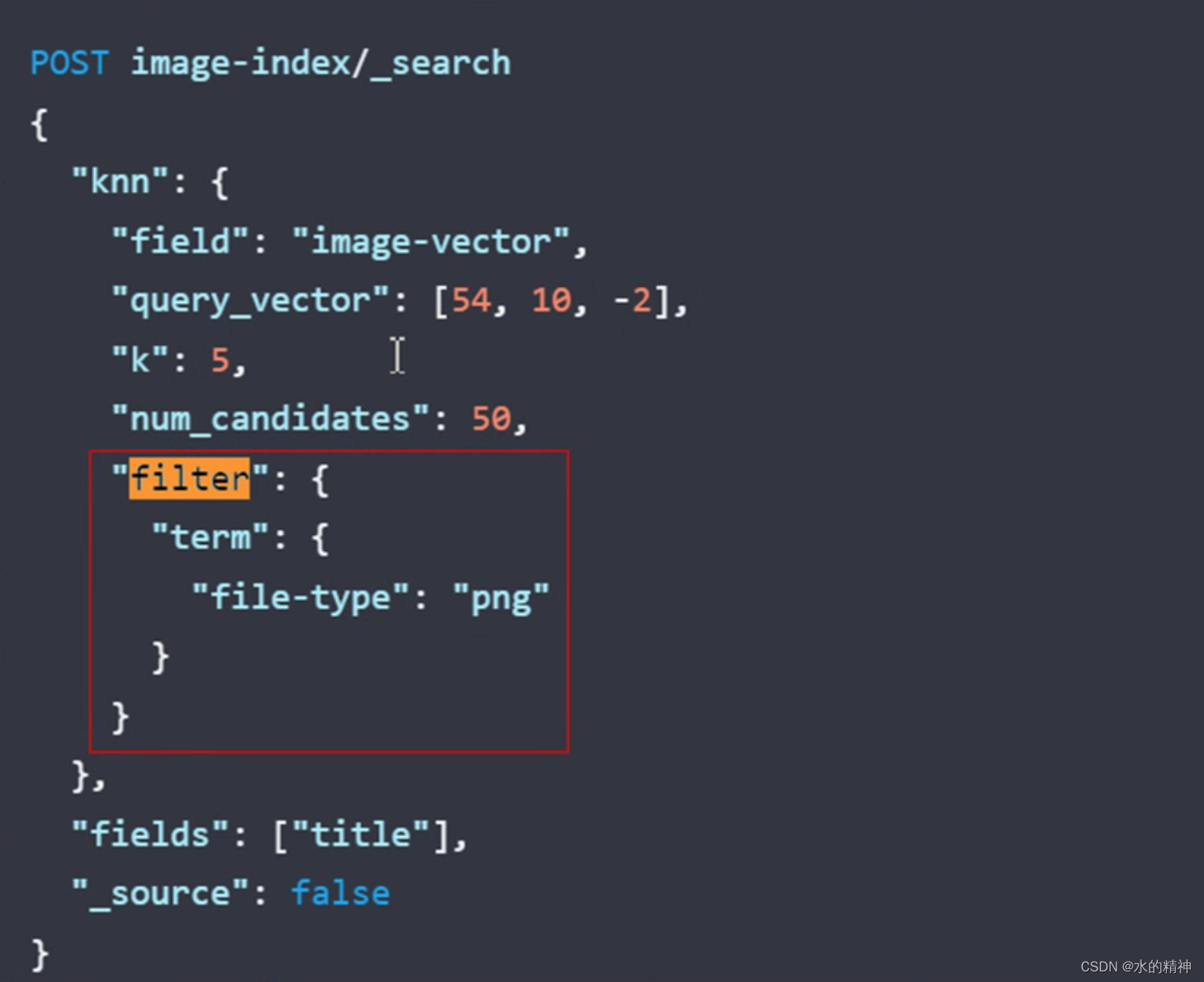 ?
?
這樣可以先篩選數據。然后剩下的在做 knn搜索。這個邏輯會先走倒排搜索。
提供一個向量檢索的案例
騰訊es云,最近寫的最佳實踐
?
關于請求改寫經驗
美團的查詢改寫



Java 基礎語法)
User-Managed Incomplete Recovery)
)

開發板的Android10的SDK)

)

(查看開頭、從開頭查看、從起始查看、反向導航、反向查找))







