前言
前面總結了一篇關于接口測試的常規面試題,現在接口自動化測試用的比較多,也是被很多公司看好。那么想做接口自動化測試需要具備哪些能力呢?
也就是面試的過程中,面試官會考哪些問題,知道你是不是真的做過接口自動化測試?總的來說問的比較多的就是以下幾個問題:
1.json和字典的區別? -對基礎數據類型的考察
2.測試的數據你放在哪? -數據與腳本分離
3.參數化 - 數據驅動模式
4.下個接口請求參數依賴上個接口的返回數據 - 參數關聯
5.依賴于登錄的接口如何處理 -token和session的管理
6.依賴第三方的接口如何處理 -mock模擬數據返回
7.不可逆的操作,如何處理,比如刪除一個訂單這種接口如何測試 -造數據
8.接口產生的垃圾數據如何清理 - 數據清理
9.一個訂單的幾種狀態如何全部測到,如:未處理,處理中,處理失敗,處理成功 - 造數據,改數據庫訂單狀態
10.python如何連接數據庫操作?
11.其它的就是運行出報告、代碼管理(git)、運行策略和持續集成jenkins相關了
1.json和字典dict的區別?
現在自動化培訓爛大街,是個人都能說的上幾個框架,面試如果問框架相關問題,求職者只需一瓶82年的雪碧,會吹的讓你懷疑人生!
所以面試官為了更清楚的知道你是停留在表面上的花拳繡腿還是有扎實的基礎,就不會問框架這種東西了。基本上問幾個數據類型的基礎就知道有沒貨了。
那么json和字典到底有什么區別呢?初學者連python的基礎數據類型都沒搞清楚,直接擼框架,有的人學了幾個月可能都迷迷糊糊的,以為json就是字典。這個是肯定不對的。
首先python里面的基礎數據類型有:int、str、 float、list、bool、tuple、dict、set這幾種類型,里面沒json這種數據類型。
JSON(JavaScript Object Notation, JS 對象簡譜) 是一種輕量級的數據交換格式。它基于 ECMAScript (歐洲計算機協會制定的js規范)的一個子集,采用完全獨立于編程語言的文本格式來存儲和表示數據。簡潔和清晰的層次結構使得 JSON 成為理想的數據交換語言。 易于人閱讀和編寫,同時也易于機器解析和生成,并有效地提升網絡傳輸效率。
由于你的代碼是python寫的(也有可能是php,java,c,ruby等語言),但是后端接口是java寫的(也有可能是其它語言),不同的語言數據類型是不一樣的(就好比中國的語言和美國的語言數據類型也不一樣,中國的一般說一只羊,一頭牛,美國都是 a /an這種單位),所以就導致你提交的數據,別的開發語言無法識別,這就需要規范傳輸的數據(傳輸的數據都是一個字符串),大家都遵循一個規范,按一個標準的格式去傳輸,于是就有就json這種國際化規范的數據類型。
json本質上還是字符串,只是按key:value這種鍵值對的格式來的字符串
import json# a是字典dict
a = {"a": 1, "b": 2, "c": True}# b是json
b = '{"a": 1, "b": 2, "c": true}'print(type(a))
print(json.dumps(a)) # a轉json
運行結果
<class 'dict'>
{"a": 1, "b": 2, "c": true}
<class 'str'>
{'a': 1, 'b': 2, 'c': True}
2.測試的數據你放在哪?
測試數據到底該怎么放,這個是面試官最喜歡問的一個題了,似乎仁者見仁智者見智,沒有標準的答案,有的人說放excel,也有的說放.py腳本,也有的說放ini配置文件,
還有放到json,yaml文件,txt文件,甚至有的放數據庫,五花八門,一百個做自動化的小伙伴有100個放的地方。
這里總結下測試的數據到底該怎么放?
首先測試的數據是分很多種的,有登錄的賬戶數據,也有注冊的賬戶數據,還有接口的參數,還有郵箱配置的數據等等等等,所以這個題不能一概而論給答死了。要不然就是給自己挖坑。
以下兩個大忌不能回答:
測試的數據是不能寫死到代碼里面的,這個是原則問題,也是寫代碼的大忌(你要是回答寫在代碼里面,估計就是回去等通知了)
測試數據放到.py的開頭,這種其實很方便,對于少量的,固定不變的數據其實是可以放的,但是面試時候,千萬不能這樣說,面試官喜歡裝逼的方法
測試數據存放總結:
1.對于賬號密碼,這種管全局的參數,可以用命令行參數,單獨抽出來,寫的配置文件里(如ini)
2.對于一些一次性消耗的數據,比如注冊,每次注冊不一樣的數,可以用隨機函數生成
3.對于一個接口有多組測試的參數,可以參數化,數據放yaml,text,json,excel都可以
4.對于可以反復使用的數據,比如訂單的各種狀態需要造數據的情況,可以放到數據庫,每次數據初始化,用完后再清理
5.對于郵箱配置的一些參數,可以用ini配置文件
6.對于全部是獨立的接口項目,可以用數據驅動方式,用excel/csv管理測試的接口數據
7.對于少量的靜態數據,比如一個接口的測試數據,也就2-3組,可以寫到py腳本的開頭,十年八年都不會變更的
總之不同的測試數據,可以用不同的文件管理
3.什么是數據驅動,如何參數化?
參數化和數據驅動的概念這個肯定要知道的,參數化的思想是代碼用例寫好了后,不需要改代碼,只需維護測試數據就可以了,并且根據不同的測試數據生成多個用例
python里面用unittest框架
import unittest
import ddt# 測試數據
datas = [ {"user": "admin", "psw": "123", "result": "true"},{"user": "admin1", "psw": "1234", "result": "true"},{"user": "admin2", "psw": "1234", "result": "true"},{"user": "admin3", "psw": "1234", "result": "true"},{"user": "admin4", "psw": "1234", "result": "true"},{"user": "admin5", "psw": "1234", "result": "true"},{"user": "admin6", "psw": "1234", "result": "true"},{"user": "admin7", "psw": "1234", "result": "true"},{"user": "admin8", "psw": "1234", "result": "true"},{"user": "admin9", "psw": "1234", "result": "true"},{"user": "admin10", "psw": "1234", "result": "true"},{"user": "admin11", "psw": "1234", "result": "true"}]@ddt.ddt
class Test(unittest.TestCase):@ddt.data(*datas)def test_(self, d):"""上海-悠悠:{0}"""print("測試數據:%s" % d)if __name__ == "__main__":unittest.main()unittest框架還有一個paramunittest也可以實現
import unittest
import paramunittest
import time
# python3.6
# 作者:上海-魚魚@paramunittest.parametrized({"user": "admin", "psw": "123", "result": "true"},{"user": "admin1", "psw": "1234", "result": "true"},{"user": "admin2", "psw": "1234", "result": "true"},{"user": "admin3", "psw": "1234", "result": "true"},{"user": "admin4", "psw": "1234", "result": "true"},{"user": "admin5", "psw": "1234", "result": "true"},{"user": "admin6", "psw": "1234", "result": "true"},{"user": "admin7", "psw": "1234", "result": "true"},{"user": "admin8", "psw": "1234", "result": "true"},{"user": "admin9", "psw": "1234", "result": "true"},{"user": "admin10", "psw": "1234", "result": "true"},{"user": "admin11", "psw": "1234", "result": "true"},
)class TestDemo(unittest.TestCase):def setParameters(self, user, psw, result):'''這里注意了,user, psw, result三個參數和前面定義的字典一一對應'''self.user = userself.user = pswself.result = resultdef testcase(self):print("開始執行用例:--------------")time.sleep(0.5)print("輸入用戶名:%s" % self.user)print("輸入密碼:%s" % self.user)print("期望結果:%s " % self.result)time.sleep(0.5)self.assertTrue(self.result == "true")if __name__ == "__main__":unittest.main(verbosity=2)如果用的是pytest框架,也能實現參數化
# content of test_canshu1.py# coding:utf-8import pytest
@pytest.mark.parametrize("test_input,expected",[ ("3+5", 8),("2+4", 6),("6 * 9", 42),])
def test_eval(test_input, expected):assert eval(test_input) == expectedif __name__ == "__main__":pytest.main(["-s", "test_canshu1.py"])
pytest里面還有一個更加強大的功能,獲得多個參數化參數的所有組合,可以堆疊參數化裝飾器
import pytest
@pytest.mark.parametrize("x", [0, 1])
@pytest.mark.parametrize("y", [2, 3])
def test_foo(x, y):print("測試數據組合:x->%s, y->%s" % (x, y))if __name__ == "__main__":pytest.main(["-s", "test_canshu1.py"])
4.下個接口請求參數依賴上個接口的返回數據
這個很容易,不同的接口封裝成不同的函數或方法,需要的數據return出來,用一個中間變量a去接受,后面的接口傳a就可以了
5.依賴于登錄的接口如何處理
登錄接口依賴token的,可以先登錄后,token存到一個yaml或者json,或者ini的配置文件里面,后面所有的請求去拿這個數據就可以全局使用了
如果是cookies的參數,可以用session自動關聯
s=requests.session()
后面請求用s.get()和s.post()就可以自動關聯cookies了
6.依賴第三方的接口如何處理
這個需要自己去搭建一個mock服務,模擬接口返回數據
moco是一個開源的框架,在github上可以下載到https://github.com/dreamhead/moco
moco服務搭建需要自己能夠熟練掌握,面試會問你具體如何搭建 ,如何模擬返回的數據,是用的什么格式,如何請求的
7.不可逆的操作,如何處理,比如刪除一個訂單這種接口如何測試
此題考的是造數據的能力,接口的請求數據,很多都是需要依賴前面一個狀態的
比如工作流這種,流向不同的人狀態不一樣,操作權限不一樣,測試的時候,每種狀態都要測到,就需要自己會造數據了。
平常手工測試造數據,直接在數據庫改字段狀態。那么自動化也是一樣,造數據可以用python連數據庫了,做增刪改查的操作
測試用例前置操作,setUp做數據準備
后置操作,tearDown做數據清理
8.接口產生的垃圾數據如何清理
跟上面一樣,造數據和數據清理,需用python連數據庫了,做增刪改查的操作
測試用例前置操作,setUp做數據準備
后置操作,tearDown做數據清理
9.一個訂單的幾種狀態如何全部測到,如:未處理,處理中,處理失敗,處理成功
跟上面一樣,也是考察造數據,修改數據的狀態
10.python如何連接數據庫操作?
這個就是詳細的考察你是如何用python連數據庫的,并且最好能現場寫代碼那種(有的筆試題就是python連數據庫)
具體問你用到哪個模塊,查詢的數據是什么類型?如何刪除數據?如何新增數據?如何修改數據?
PyMySQL 是在 Python3.x 版本中用于連接 MySQL 服務器的一個庫,Python2中則使用mysqldb。
詳情參考教程http://www.runoob.com/python3/python3-mysql.html
?
#!/usr/bin/python3
# 查詢EMPLOYEE表中salary(工資)字段大于1000的所有數據:
import pymysql# 打開數據庫連接
db = pymysql.connect("localhost","testuser","test123","TESTDB" )# 使用cursor()方法獲取操作游標
cursor = db.cursor()# SQL 查詢語句
sql = "SELECT * FROM EMPLOYEE \WHERE INCOME > %s" % (1000)
try:# 執行SQL語句cursor.execute(sql)# 獲取所有記錄列表results = cursor.fetchall()for row in results:fname = row[0]lname = row[1]age = row[2]sex = row[3]income = row[4]# 打印結果print ("fname=%s,lname=%s,age=%s,sex=%s,income=%s" % \(fname, lname, age, sex, income ))
except:print ("Error: unable to fetch data")# 關閉數據庫連接
db.close()其它的就是運行出報告、代碼管理(git)、運行策略和持續集成jenkins相關了,這個所以的自動化但是一樣的,后面會單獨講一篇jenkins持續集成相關
????????????? 【下面是我整理的2023年最全的軟件測試工程師學習知識架構體系圖】
一、Python編程入門到精通
 二、接口自動化項目實戰?
二、接口自動化項目實戰?

三、Web自動化項目實戰
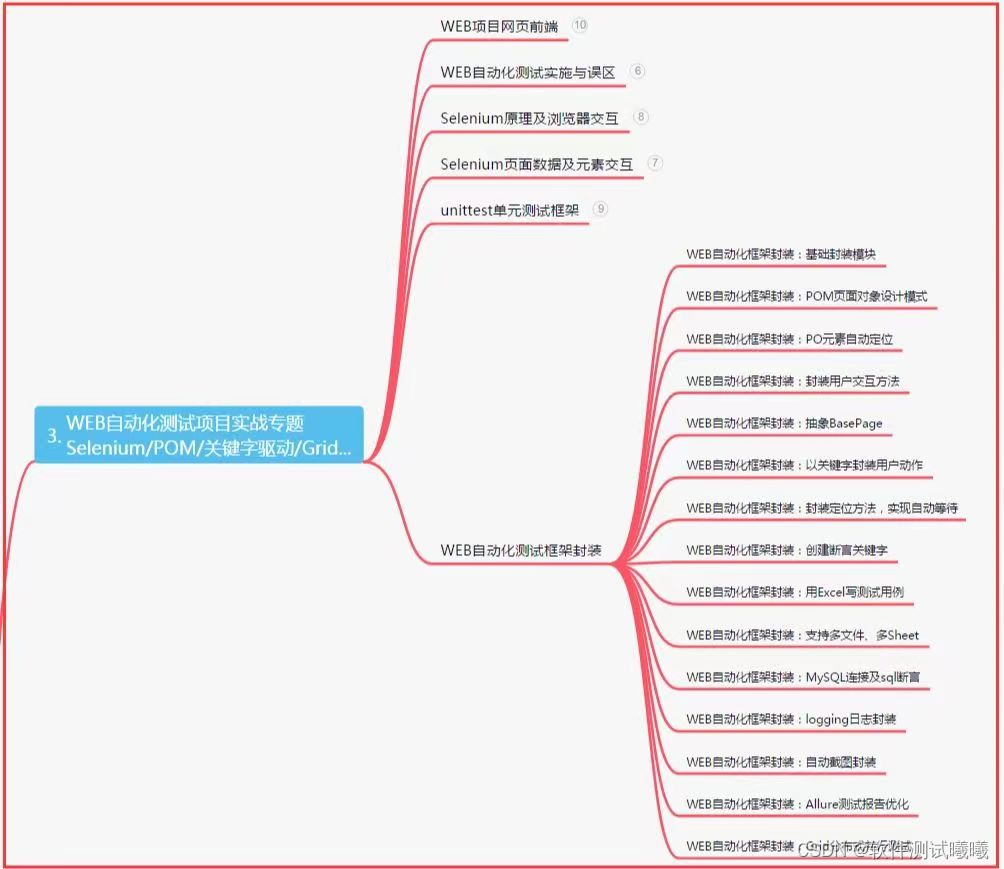
四、App自動化項目實戰?

五、一線大廠簡歷
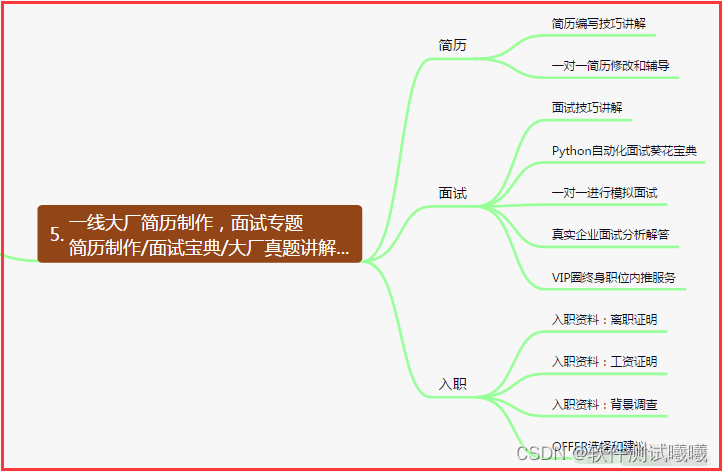
六、測試開發DevOps體系?

七、常用自動化測試工具
 八、JMeter性能測試?
八、JMeter性能測試?

九、總結(尾部小驚喜)
生命不息,奮斗不止。每一份努力都不會被辜負,只要堅持不懈,終究會有回報。珍惜時間,追求夢想。不忘初心,砥礪前行。你的未來,由你掌握!
生命短暫,時間寶貴,我們無法預知未來會發生什么,但我們可以掌握當下。珍惜每一天,努力奮斗,讓自己變得更加強大和優秀。堅定信念,執著追求,成功終將屬于你!
只有不斷地挑戰自己,才能不斷地超越自己。堅持追求夢想,勇敢前行,你就會發現奮斗的過程是如此美好而值得。相信自己,你一定可以做到!?
最后感謝每一個認真閱讀我文章的人,禮尚往來總是要有的,雖然不是什么很值錢的東西,如果你用得到的話可以直接拿走:
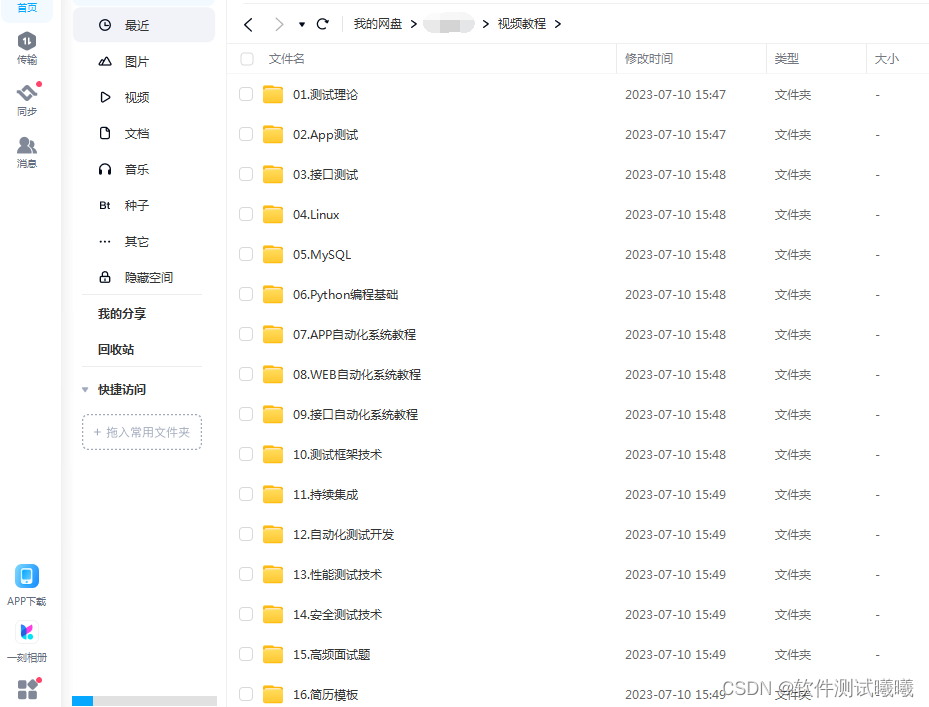
這些資料,對于【軟件測試】的朋友來說應該是最全面最完整的備戰倉庫,這個倉庫也陪伴上萬個測試工程師們走過最艱難的路程,希望也能幫助到你!?





)







)


相關類總結)



