學習內容
05.序列模型
1.1 為什么用序列模型
1.序列模型常見的應用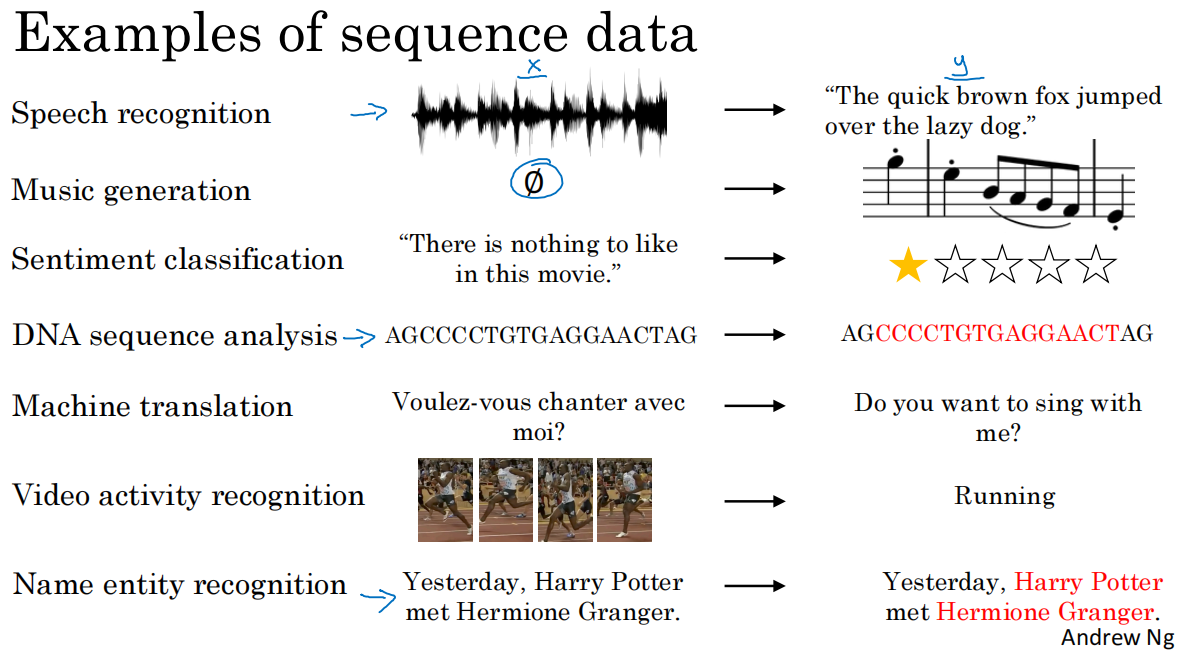
1.2 注釋 notation
1.
*T_x(i)表示訓練樣本x(i)的序列長度,T_y(i)表示target(i)的序列長度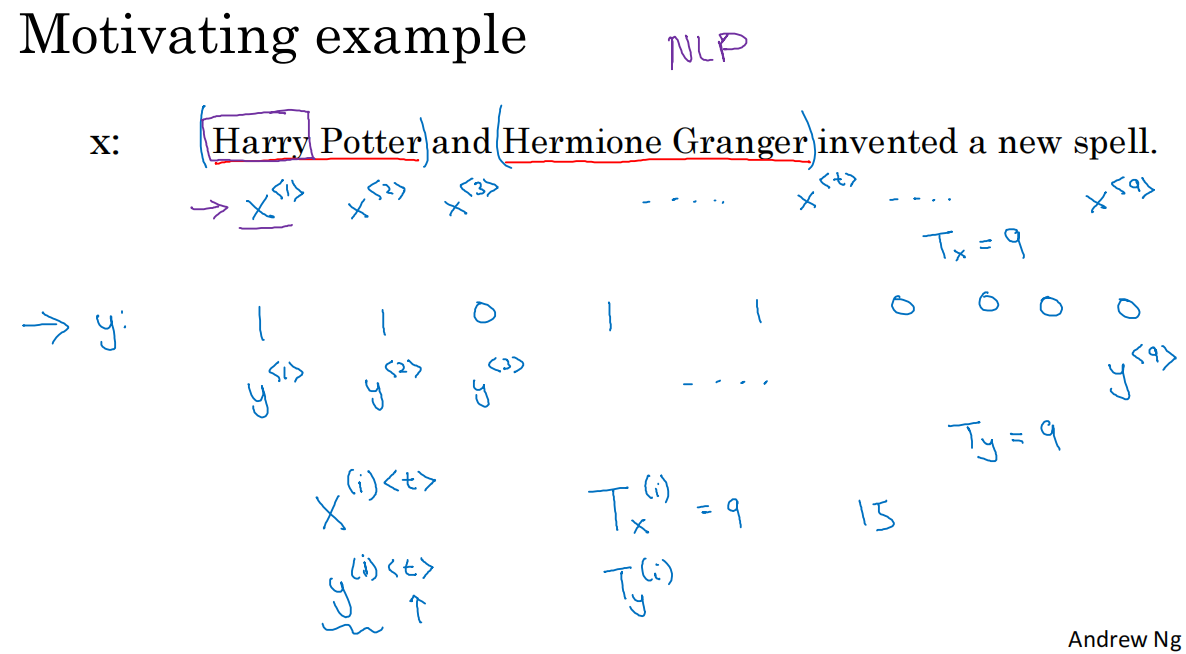
2.訓練集表示單詞的方式
*構建字典的方式
*在訓練集中查找出現頻率最高的單詞
*網絡搜集常用字典
3.如果遇到不在字典中的單詞,需要創建一個新的標記,unknown word偽單詞,用標記
1.3 循環神經網絡模型
1.標準神經網絡并不適合用于解決序列問題
不同的例子中輸入輸出數據的長度不一,雖然可以通過0-padding的方式解決,但不是好的表達方式
并不共享已學習的數據(如harry已識別出是人名,希望不用再次識別,但標準神經網絡模型并不解決這一問題)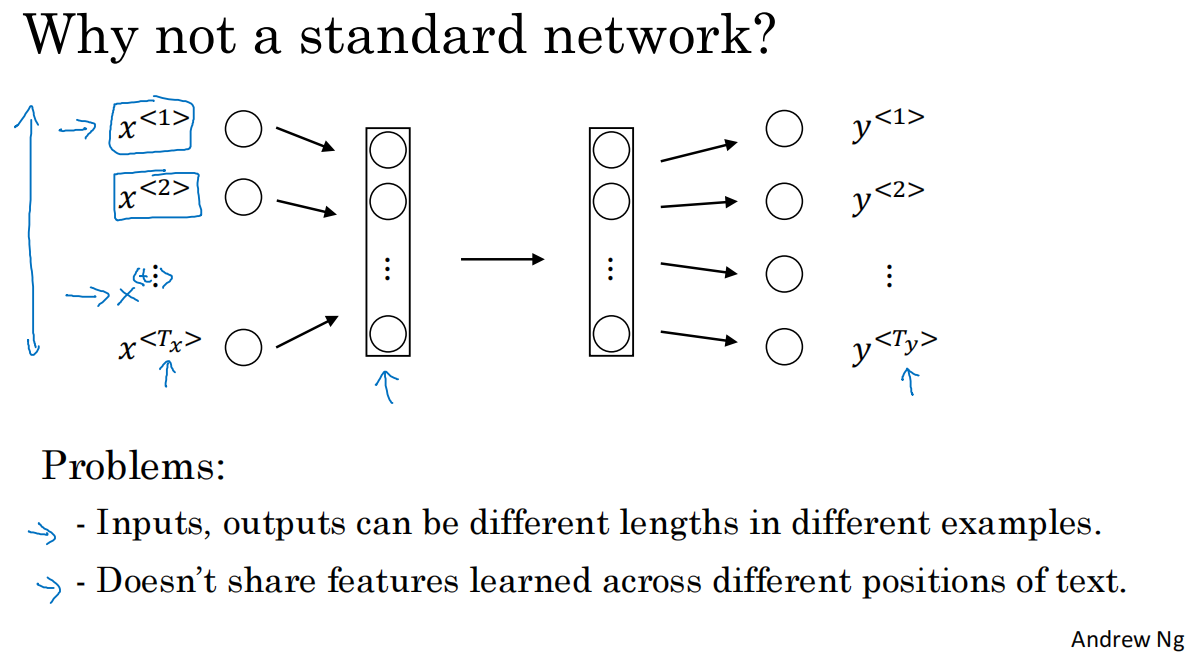
2.簡單循環神經網絡模型
在每一時間步t,根據輸入單詞x和上一時間步的激活值a,計算得到y
a<0>初始化為0向量是常見的選擇
每個時間步的參數共享,激活值的水平聯系由參數waa決定,輸入與隱藏層的聯系由參數wax決定,輸出由wya決定
當前循環神經網絡模型的缺點:只使用了當前序列之前的信息做出預測,如果存在如圖的teddy示例,則無法判斷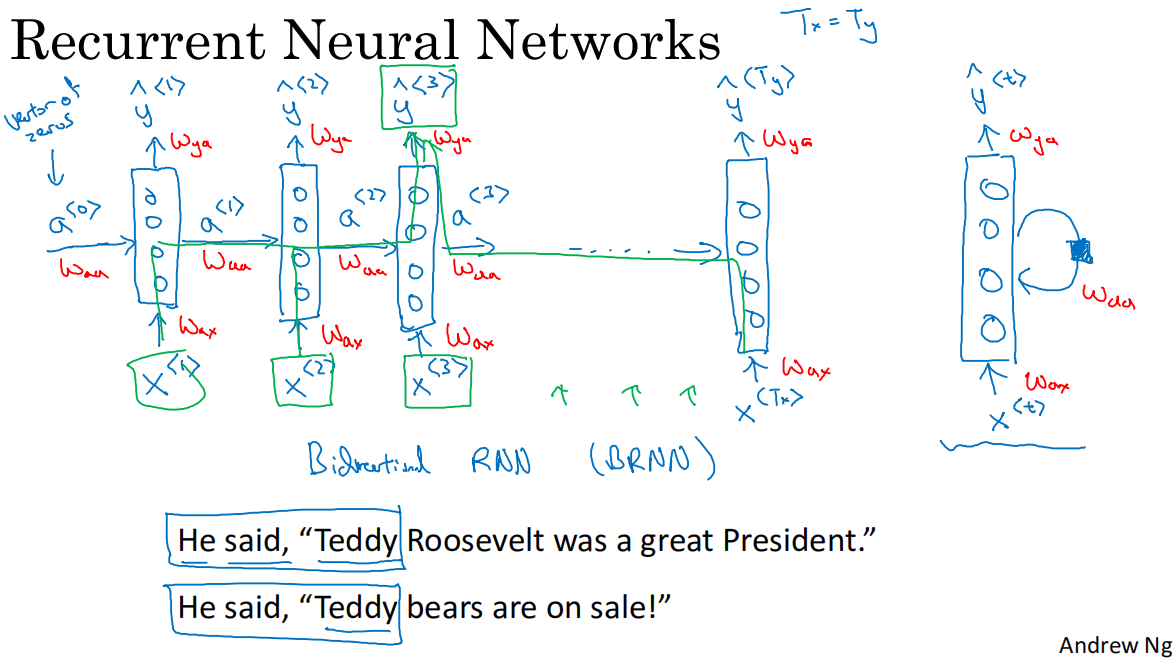
3.前向傳播
a=g1(W_aaa+W_axx+b_a)
y_hat=g2(W_yaa+b_y)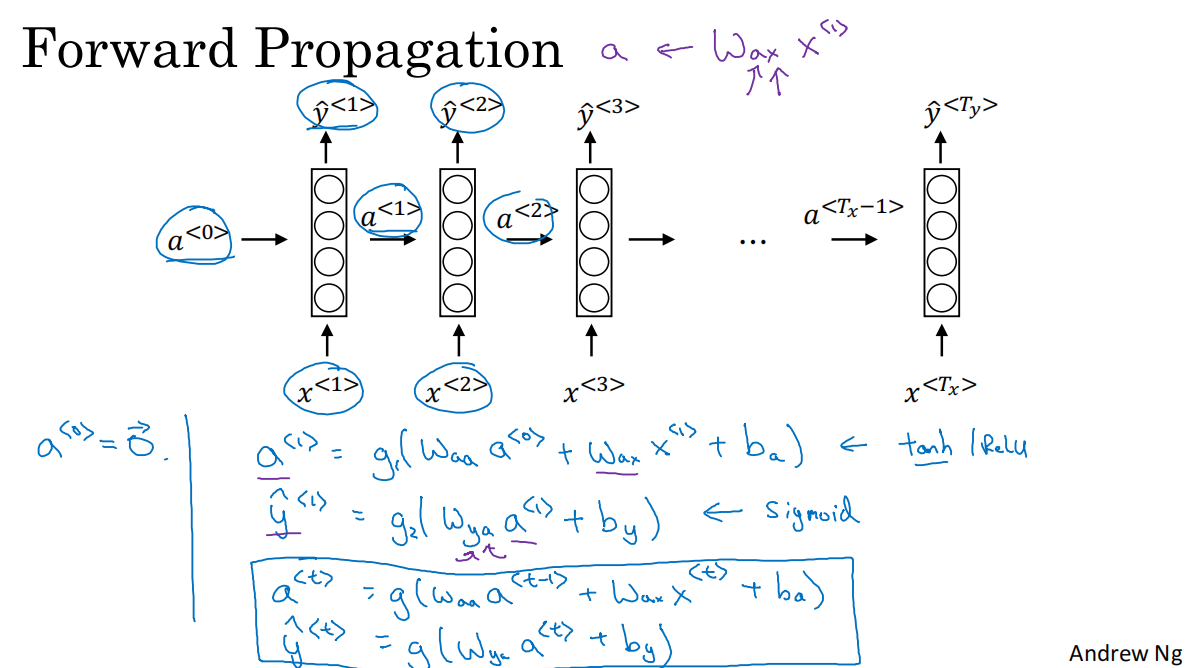
4.符號簡化
W_a的簡化W_aa.shape=(100,100)``W_ax.shape=(100,10000)W_a=[W_aa,W_ax]``W_a.shape=(100,10100)
[a,x]的簡化a<t-1>.shape=(100,n)x<t>.shape=(10000,n)[a<t-1>,x<t>].shape=(10100,n)
*W_a*[a<t-1>,x<t>]=W_aa*a<t-1>+W_ax*x<t>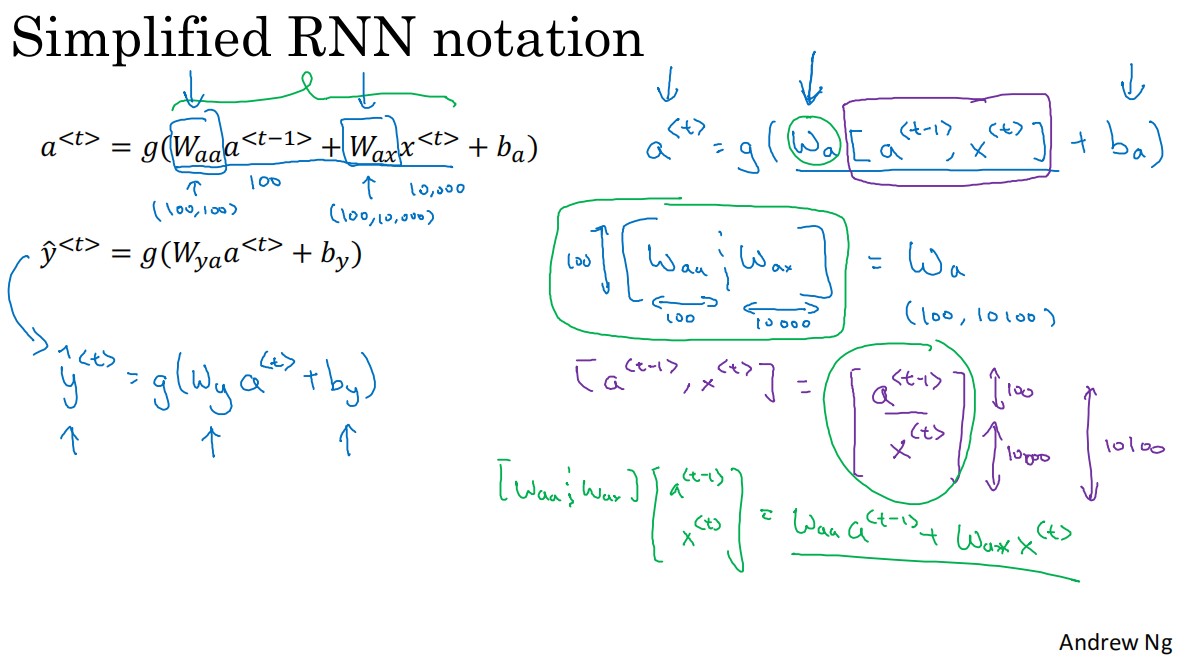
5.RNN前向傳播示意圖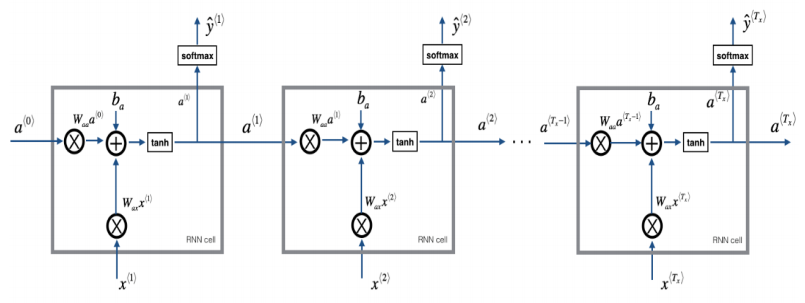
1.4 通過時間的反向傳播
1.計算圖
*單個元素的損失函數L(y_hat<t>,y<t>)=-y<t>*log(y_hat<t>)-(1-y<t>)*log(1-y_hat<t>)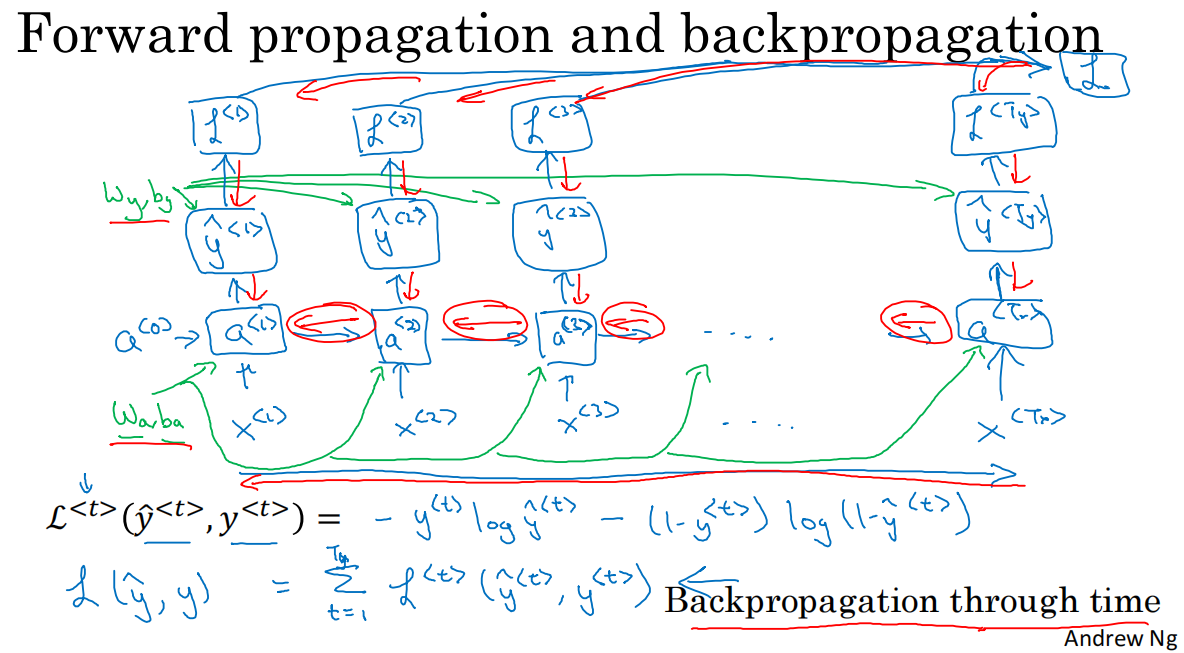
2.cache與具體計算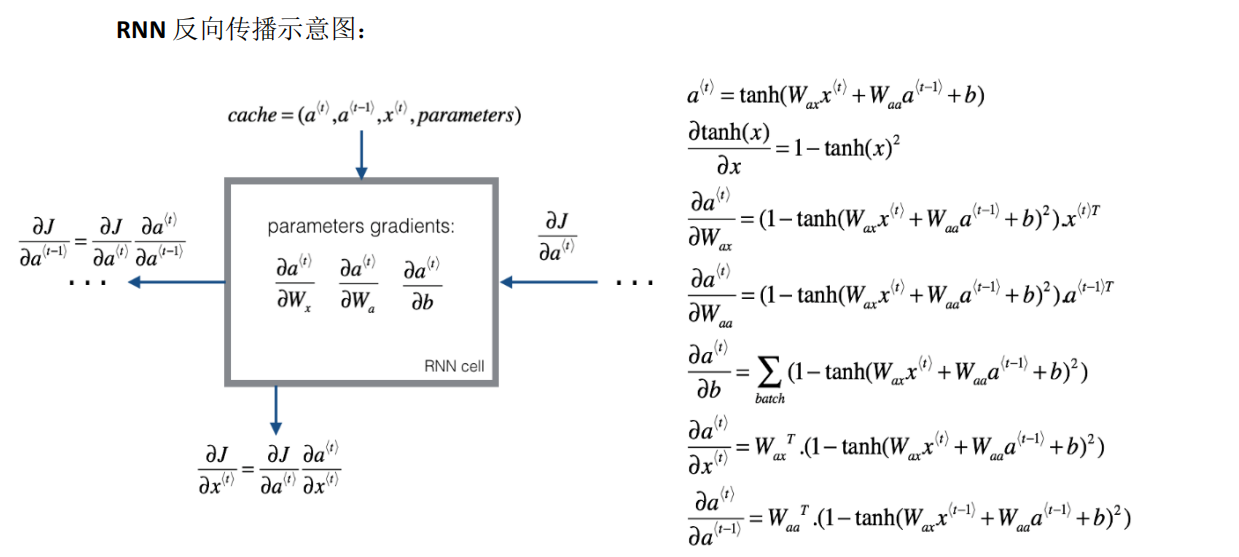
1.5 不同類型的RNNs
1.RNN有許多的架構類型,用于解決T_x和T_y長度不匹配的不同問題
*many-to-many類型Tx=Ty,常見應用:命名實體識別
*many-to-many類型Tx!=Ty,常見應用:機器翻譯,網絡結構說明:網絡由2部分組成:decoder和encoder
*many-to-one類型Tx>Ty,常見應用:評分/情感分析,網絡結構說明:RNN網絡可簡化,僅需要最后時間步的輸出
*one/NULL-to-many類型Tx<Ty,常見應用:音樂生成,網絡結構說明:輸入數量為1,細節:上一層的輸出也可以喂給下一層,作為輸入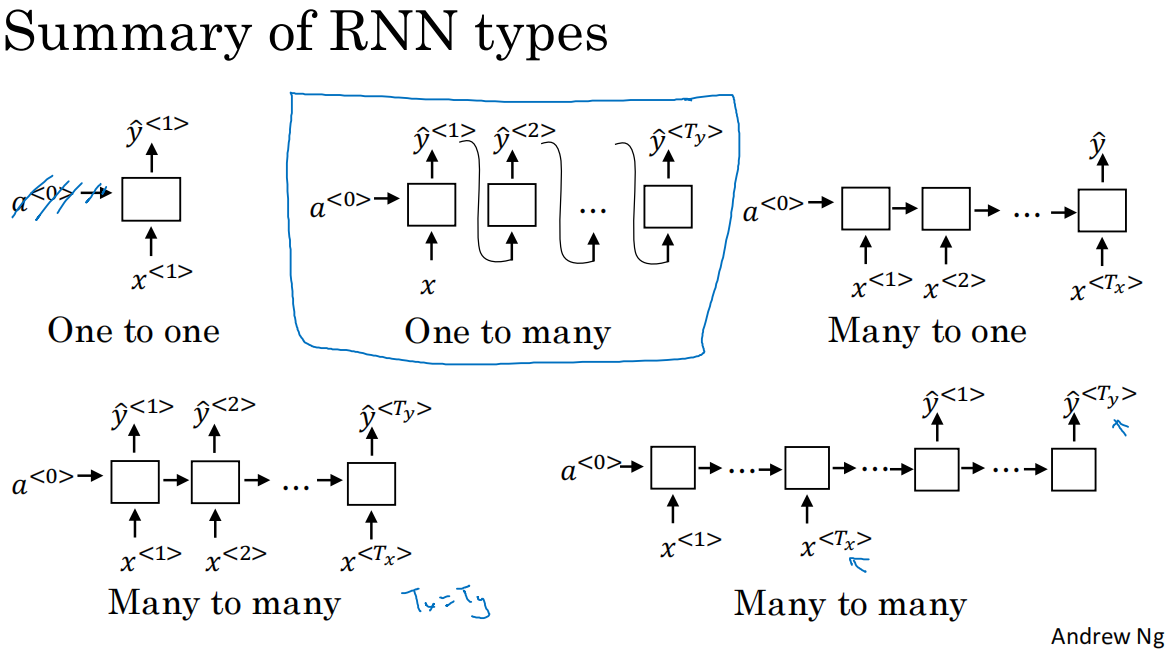
1.6 語言模型和序列生成
1.語言模型用于生成某個特定的句子出現的概率,它的輸入是文本序列y<1> y<2> y<3> y<4> ... y<T_y>(一般對于語言模型,用y表示輸入更好),語言模型會估計序列中各個單詞出現的概率
2.通過RNN建立語言模型,訓練集:語料庫
3.我們需要對訓練集的句子進行標記化:
*建立一個字典,將對應的單詞轉化為one-hot向量
需要注意的是,我們往往定義句子的末尾為<EOS>結束標記.符號可以作為輸入,也可以不作為輸入
*對于未識別的字符,我們將他們作為一個整體,都用UNK標記,計算他們整體的概率,而不單獨對某一未標記字符計算其概率
4.通過RNN模型構造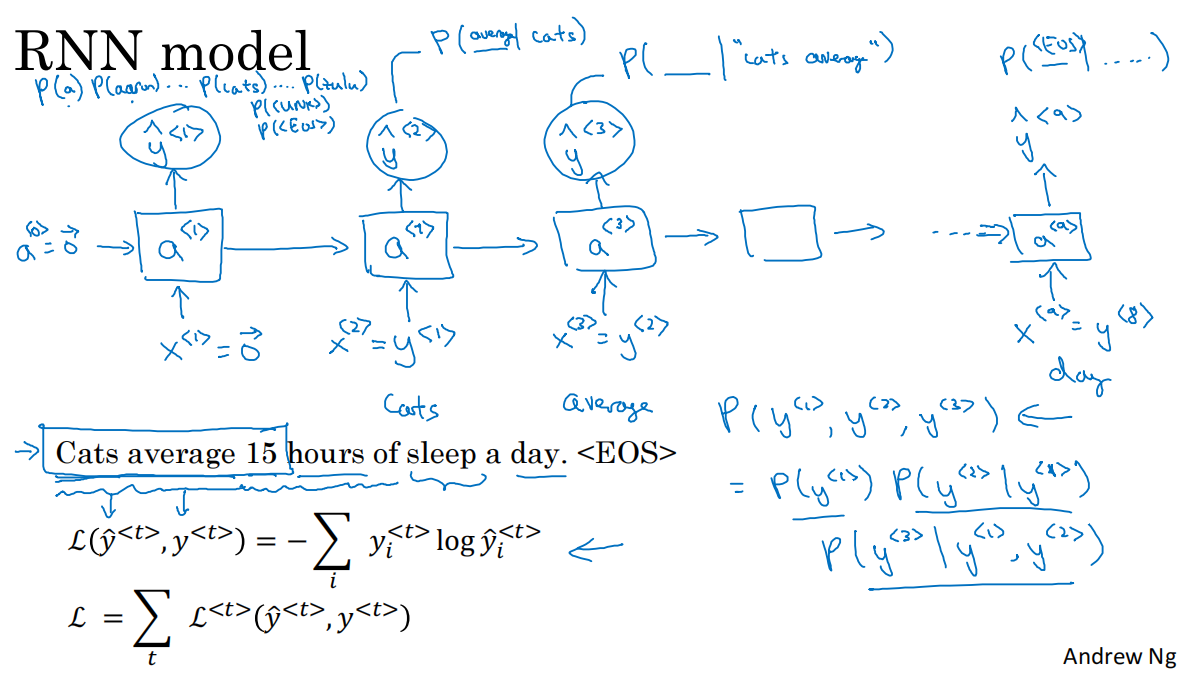


)







)


相關類總結)





