可變參數模板
C++11的新特性可變參數模板能夠創建可以接受可變參數的函數模板和類模板.
相比C++98/03, 類模版和函數模版中只能含固定數量的模版參數, 可變模版參數無疑是一個巨大的改進, 然而由于可變模版參數比較抽象, 使用起來需要一定的技巧, 所以這塊還是比較晦澀的.掌握一些基礎的可變參數模板特性就暫時夠用了.
我們之前就接觸過函數的可變參數, 比如說c語言的printf函數和scanf函數,這兩個就是經典的可變參數函數, c語言printf的底層是指針數組實現的, 把參數存到那個數組里, 然后遇到可變參數就是去解析那個數組里的內容.
 ?
?
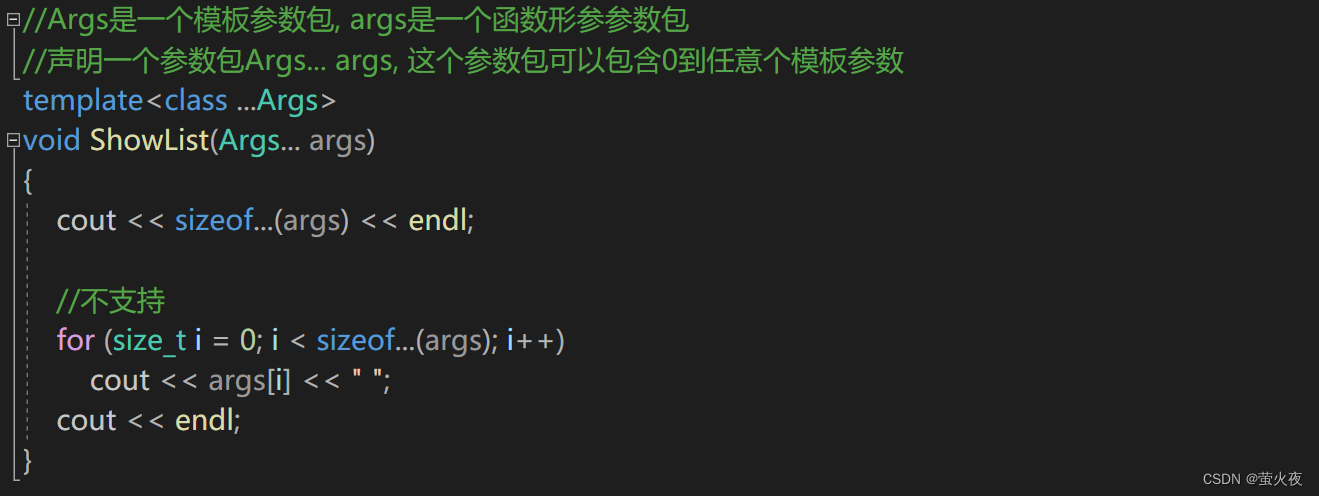
//Args是一個模板參數包, args是一個函數形參參數包
//聲明一個參數包Args... args, 這個參數包可以包含0到任意個模板參數
template<class ...Args>
void ShowList(Args... args)
{}int main()
{ShowList(1);ShowList(1, 2);ShowList(1, 2, 3);ShowList(1, 2.2, "x", 3);return 0;
}模板參數包里面是類型, 函數參數包里面是變量?
如果要計算參數包的大小, 需要用sizeof..., 這個用法是固定的:?
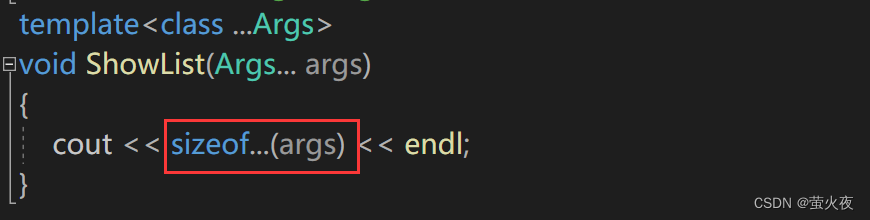

如果想要解析參數包的內容, 首先可能會想到數組式地訪問, 但是不支持這樣訪問:
想要訪問模板參數包的內容有兩種方法, 第一種遞歸函數方式展開參數包:
void _ShowList()
{cout << endl;
}//編譯時的遞歸推演
//第一個模板參數依次解析獲取參數值
template<class T, class ...Args>
void _ShowList(const T& val, Args... args)
{cout << val << " ";_ShowList(args...);
}template<class ...Args>
void ShowList(Args... args)
{//cout << sizeof...(args) << endl;_ShowList(args...);
}int main()
{ShowList(1);ShowList(1, 2);ShowList(1, 2, 3);ShowList(1, 2.2, "x", 3);return 0;
}?
以1,2,3為例, 第一次先將參數包傳遞給_ShowList, _ShowListval先接收第一個參數, 然后其他的參數就會全部都給參數包args, 那么對應在上面的代碼就是1傳遞給val, 2和3就會傳遞給args, 然后遞歸調用ShowList繼續傳遞參數包, 重復場面的步驟第一個參數val接收2, 參數包則接收剩下的參數3. 如果剩余的參數為空的話就會匹配空類型的參數(最上面的_ShowList), 最終結束了遞歸.
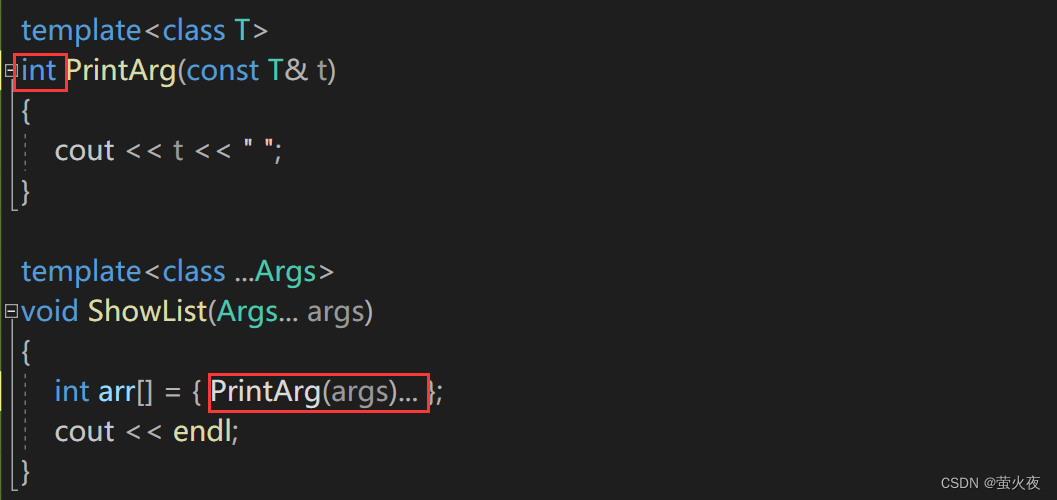
?第二種逗號表達式展開參數包:
這種展開參數包的方式, 不需要通過遞歸終止函數, 是直接在函數體中展開的, printarg
不是一個遞歸終止函數, 只是一個處理參數包中每一個參數的函數.這用到了C++11的另外一個特性——初始化列表,?通過初始化列表來初始化一個變長數組, {(printarg(args), 0)...}將會展開成((printarg(arg1),0),(printarg(arg2),0), (printarg(arg3),0), etc... ), 最終會創建一個元素值都為0的數組int arr[sizeof...(Args)].
由于是逗號表達式, 在創建數組的過程中會先執行逗號表達式前面的部分printarg(args)
打印出參數, 也就是說在構造int數組的過程中就將參數包展開了, 這個數組的目的純粹是為了在數組構造的過程展開參數包.
數組里面添加了三個點, 這個就表示數組在推斷的時候需要把這個參數包進行展開, 展開的空間為多大, 這個數組的大小就是多大:
template<class T>
void PrintArg(const T& t)
{cout << t << " ";
}template<class ...Args>
void ShowList(Args... args)
{int arr[] = { (PrintArg(args),0)... };cout << endl;
}int main()
{ShowList(1);ShowList(1, 2);ShowList(1, 2, 3);ShowList(1, 2.2, "x", 3);return 0;
}?
上面的寫法其實也用不到逗號表達式, 直接這樣寫也可以:
emplace
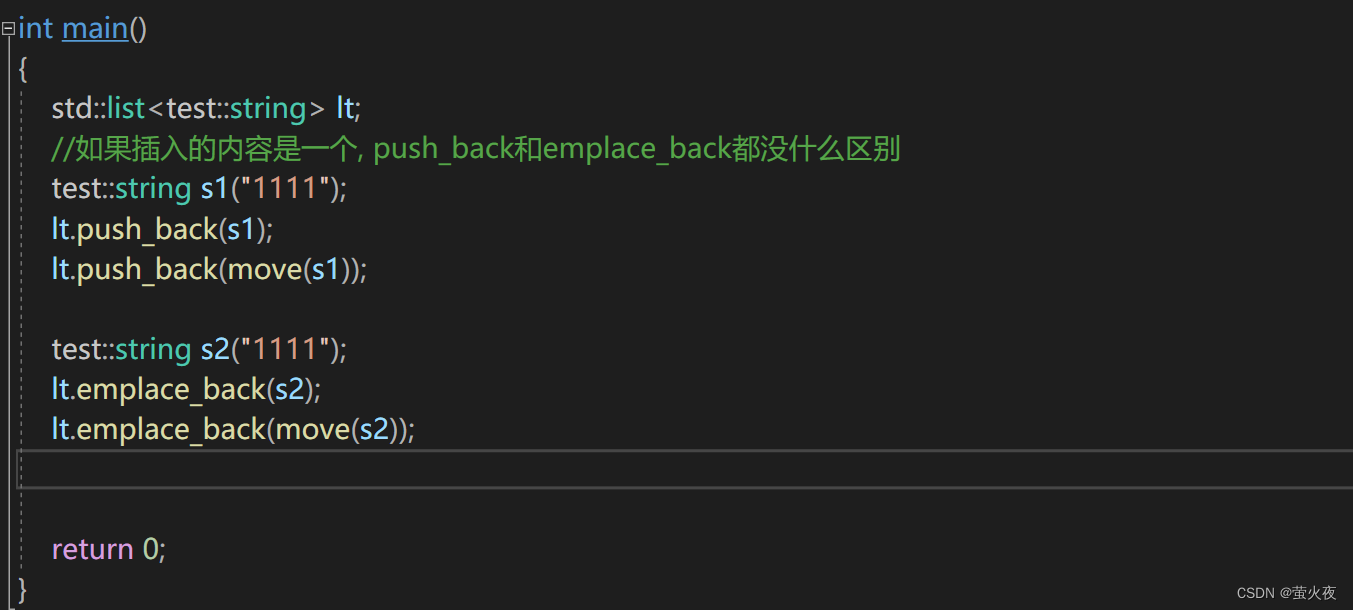
在之前的使用過程中對于容器我們一般傳遞的都是左值, 但是在c++11中我們發現容器不僅可以傳遞左值還可以傳遞右值, 并且傳遞右值的效率會比單獨傳遞左值的效率高很多, 但是不管你是傳遞左值還是傳遞右值之前學習的插入方式一次都只能傳遞一個值, 而emplace版本的插入函數它可以一次傳遞0~N個參數,?我們來看看list容器的emplace版本的push_back函數:

template <class... Args>
void emplace_back (Args&&... args);這里的可變參數包里的類型是 Args&&, 結合之前學過的, 模板里的&&就是萬能引用, 也就是說這個參數包里的參數都可以是萬能引用.
那么相對insert和emplace系列接口的優勢在哪里呢?
首先插入的參數是一個的話, 兩者其實沒有什么區別:

這樣寫會有一些區別, 但只是形式上有一些區別, 實際也沒什么區別:
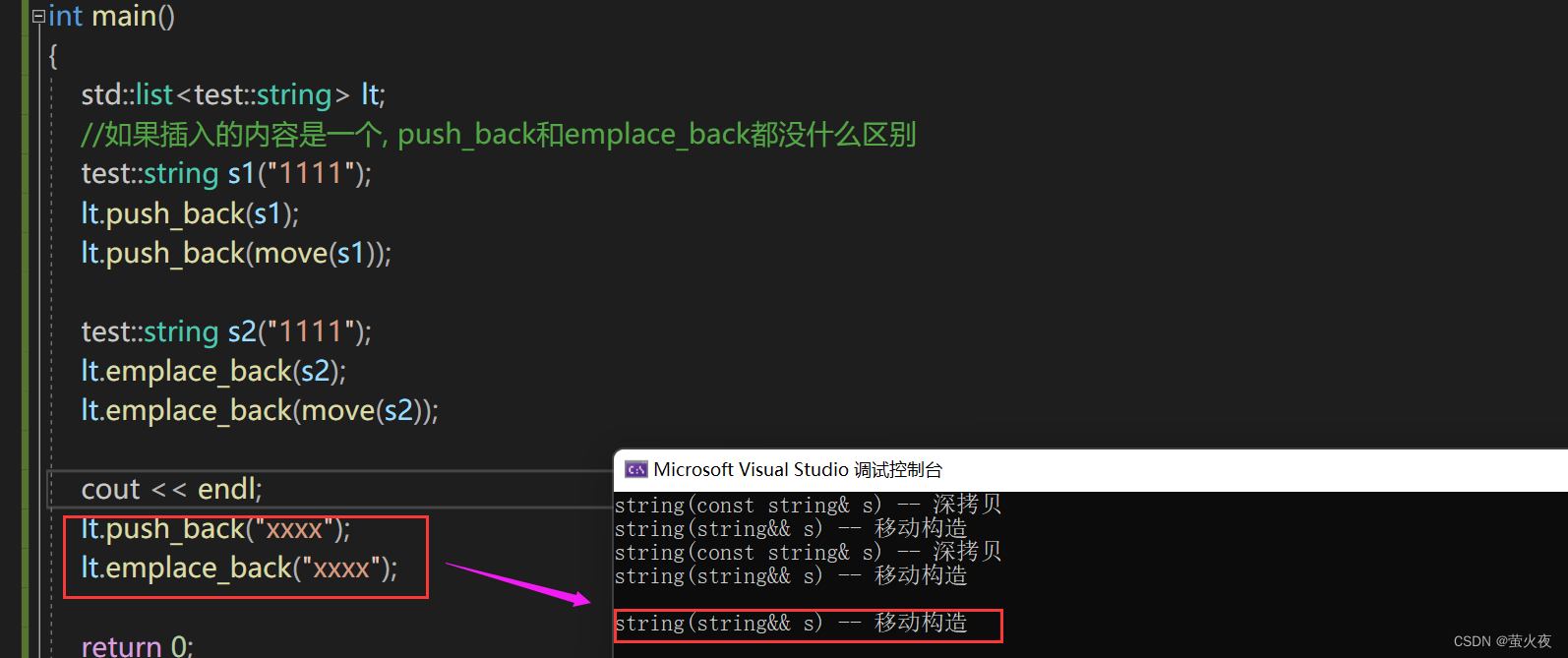
?可以發現這里只有一個移動構造, 而明確地說是這是push_back的移動構造, 現在把string的構造函數也打印出來, 就可以解釋原因:
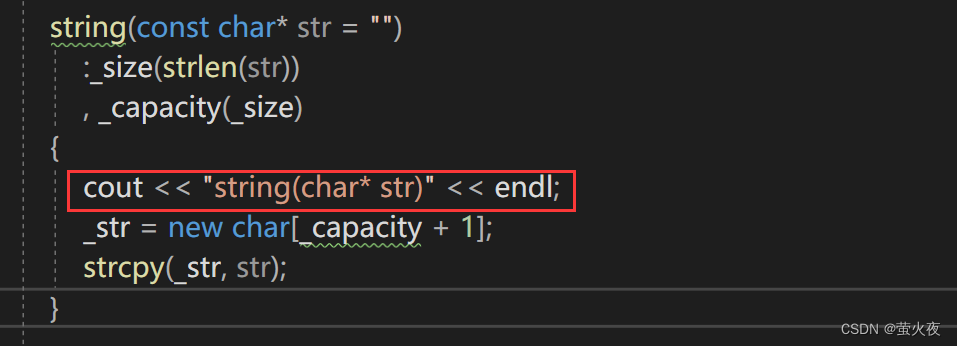
再次運行:

?可以發現push_back是構造+移動構造, 而emplace_back是直接構造.
對于前兩種情況不會出現這種問題原因是, push_back的value_type可以明確確定val的類型就是test::string, 而emplace_back只有一個參數也是test::string類型的, 所以也可以比較明確地推斷出參數是test::string類型的.

而這種情況就不一樣了:

因為push_back里的value_type是test::string, push_back是直接隱式類型轉換, 傳給萬能引用就繼續移動構造了, 而emplace_back拿著參數包去推類型, 此時只能推斷出它是const char*類型的, 并不知道list結點里實際是什么類型, 所以就帶著這個參數包一直向下傳遞, 一直傳到list的結點要構建它的data的時候直接用調用構造.? ? ? ??
再舉一個例子, 如果push_back的話參數需要傳一個pair因為value_type是寫死的,需要傳一個pair過去, 而emplace_back直接傳兩個參數進去, 讓它直接去構造就可以了, 這里用string的構造間接表示pair的構造.
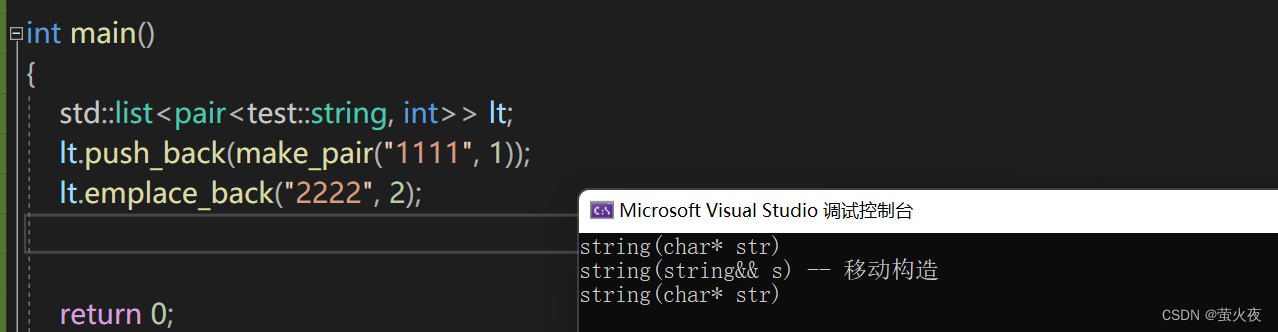
?所以多參數時, emplace_back可以一個一個傳參, 因為emplace_back的形參是可變參數包, 直接把參數包不斷往下傳, 直接構造到結點的val中.
所以回歸最開始的話題, 插入的參數是一個的話, push_back和emplace_back其實沒有什么區別不管是傳參方式還是底層效率, 因為移動構造的成本也很低, 可以說emplace_back是略微高效一點.
而多參數時效率其實也沒什么區別, 但是emplace_back傳參的方式更多了一點, 它不僅可以傳左值和右值,還可以把參數一個個分開傳:
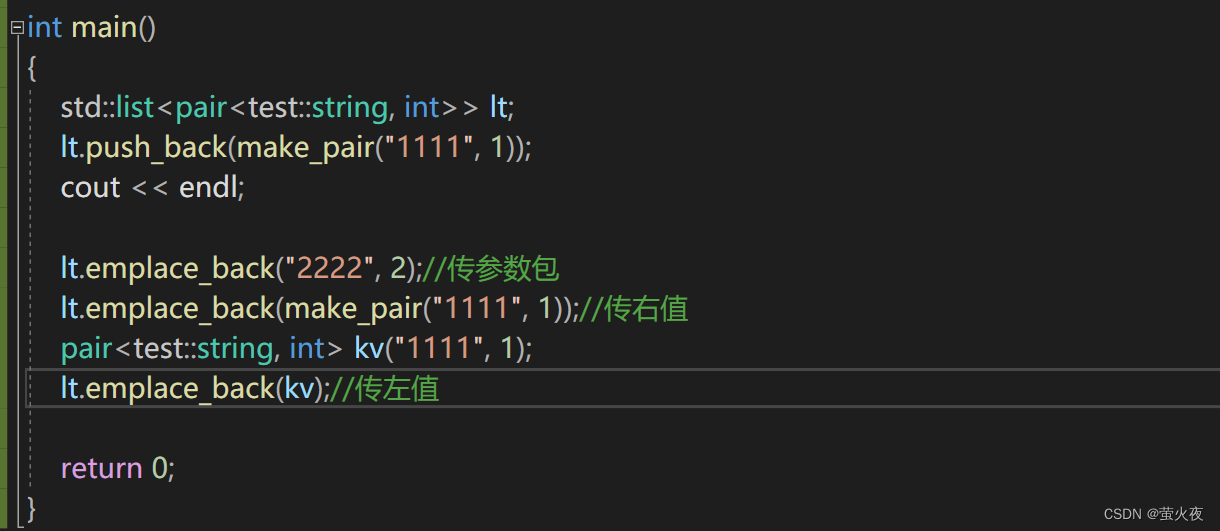

?可以再用自己的鏈表試一試:
int main()
{test::list<pair<test::string, int>> lt;cout << endl;lt.push_back(make_pair("1111", 1));lt.emplace_back("2222", 2);return 0;
}?先實現一個emplace_back:
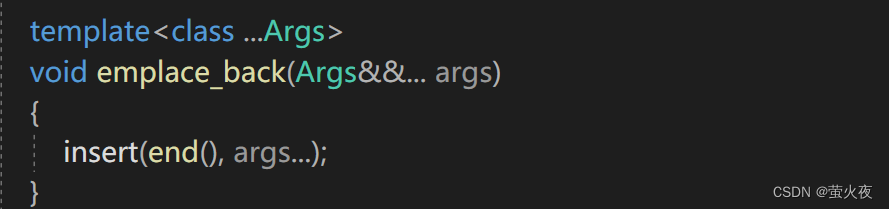
emplace_back要復用insert(實際上應該去復用emplace, push_back復用insert, emplace_back應該復用emplace, 這里就先這樣寫), 需要把函數參數包傳給insert, 所以insert也要實現一個可變參數包版的:

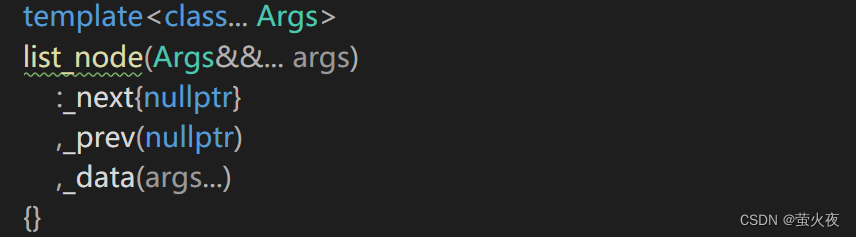
?insert里創建結點要用到new需要把參數包向下傳, 所以node的構造函數也要實現一個可變參數包版的:
運行:?
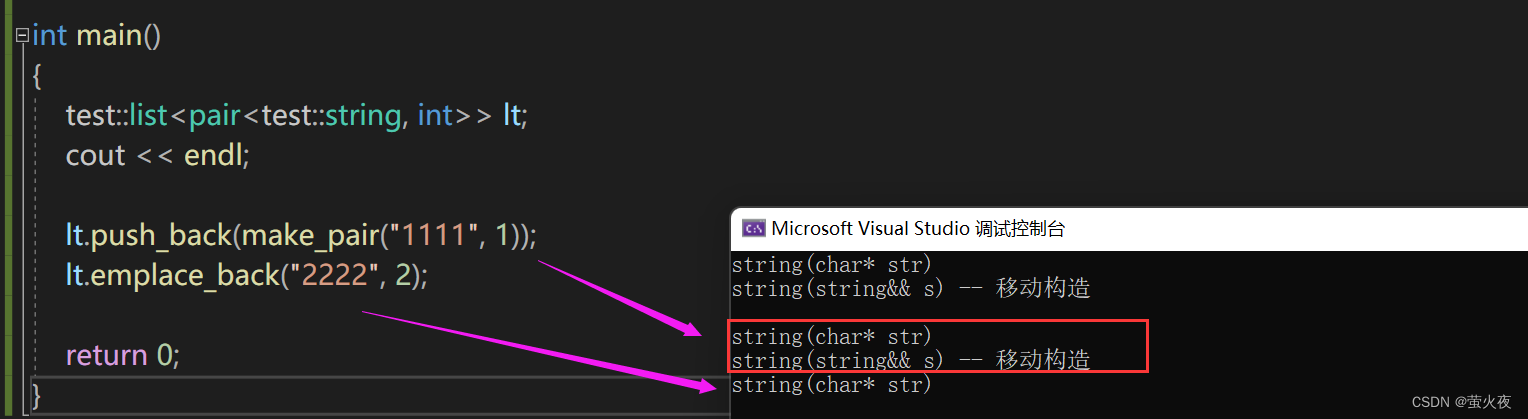
?結果整體上符合預期, push_back就正常調用構造+移動構造, emplace_back直接構造, 但是前面多出來兩行構造+拷貝構造, 因為我們是new出來一個頭結點, 頭結點初始化需要調用構造, 而C++庫里用的是內存池, 內存池只管開空間, 需要初始化的時候用定位new即可.

所以參數包其實有的時候不用去解析, 最終是一層一層往下傳, 可變參數包直接被使用了.
總結:
總體而言emplace的效率并沒有比push_back高多少, 但是有一種場景提升比較明顯, 對于淺拷貝而且是對象很大的類有效果, 因為淺拷貝push_back不存在移動構造(不存在資源轉換), 就是構造+拷貝構造, 而emplace是直接構造, 直接構造肯定比構造+拷貝構造效率高, 所以emplace對于深拷貝的類效果不是很明顯, 因為移動構造的成本就是轉移資源, 成本很低; 對于淺拷貝的類有一定的提升.
lambda表達式
為什么會有lambda表達式
c語言中有函數指針, 它可以讓我們傳入函數作為參數, 但是函數指針在一些比較復雜的情況時會變得很難理解. 為了解決這個問題, C++就提出來了仿函數,?它可以大大的提高函數指針的可讀性, 比如常用的sort函數:
在C++98中, 如果想要對一個數據集合中的元素進行排序, 可以使用std::sort方法:
#include <algorithm>
#include <functional>
int main()
{int array[] = { 4,1,8,5,3,7,0,9,2,6 };// 默認按照小于比較,排出來結果是升序std::sort(array, array + sizeof(array) / sizeof(array[0]));// 如果需要降序,需要改變元素的比較規則std::sort(array, array + sizeof(array) / sizeof(array[0]), greater<int>());return 0;
}如果待排序元素為自定義類型, 需要用戶定義排序時的比較規則:
#include <algorithm>
struct Goods
{string _name; // 名字double _price;// 價格int _evaluate;// 評價Goods(const char* str, double price, int evaluate):_name(str), _price(price), _evaluate(evaluate){}};struct ComparePriceLess
{bool operator()(const Goods& gl, const Goods& gr){return gl._price < gr._price;}
};struct ComparePriceGreater
{bool operator()(const Goods& gl, const Goods& gr){return gl._price > gr._price;}
};ostream& operator<<(ostream& out, const Goods& g)
{out << g._name << " "<< "評價" << g._evaluate << " " << "價格" << g._price << endl;return out;
}int main()
{vector<Goods> v = { { "蘋果", 2.1, 5 }, { "香蕉", 3, 4 }, { "橙子", 2.2, 3 }, { "菠蘿", 1.5, 4 } };sort(v.begin(), v.end(), ComparePriceLess());for (auto e : v)cout << e;cout << "---------------------------" << endl;sort(v.begin(), v.end(), ComparePriceGreater());for (auto e : v)cout << e;}
可以得到我們預期排序的結果.?
但隨著C++語法的發展, 人們開始覺得上面的寫法太復雜了, 每次為了實現一個algorithm算法, 都要重新去寫一個類, 如果每次比較的邏輯不一樣, 還要去實現多個類, 特別是相同類的命名,?這些都給編程者帶來了極大的不便, 因此, 在C++11語法中出現了Lambda表達式.
?lambda表達式語法?
lambda表達式書寫格式:
[capture-list] (parameters) mutable -> return-type { statement }
lambda表達式各部分說明
[capture-list]: 捕捉列表, 該列表總是出現在lambda函數的開始位置, 編譯器根據[]來判斷接下來的代碼是否為lambda函數, 捕捉列表能夠捕捉上下文中的變量供lambda函數使用.
(parameters): 參數列表, 與普通函數的參數列表一致, 如果不需要參數傳遞, 則可以連同()一起省略.
mutable:?默認情況下, lambda函數總是一個const函數, mutable可以取消其常量性, 使用該修飾符時, 參數列表不可省略(即使參數為空).->returntype:?返回值類型, 用追蹤返回類型形式聲明函數的返回值類型, 沒有返回值時此部分可省略, 返回值類型明確情況下, 也可省略, 由編譯器對返回類型進行推導.?
{statement}:?函數體, 在該函數體內, 除了可以使用其參數外, 還可以使用所有捕獲到的變量.
注意:?
在lambda函數定義中, 參數列表和返回值類型都是可選部分, 而捕捉列表和函數體可以為空,但不能省略,?因此C++11中最簡單的lambda函數為:[]{}; 該lambda函數不能做任何事情.
舉幾個例子:?
int main()
{// 最簡單的lambda表達式, 該lambda表達式沒有任何意義[] {};// 省略參數列表和返回值類型,返回值類型由編譯器推導為intint a = 3, b = 4;[=] {return a + 3; };// 省略了返回值類型,無返回值類型auto fun1 = [&](int c) {b = a + c; };fun1(10);cout << a << " " << b << endl;//3 13// 各部分都很完善的lambda函數auto fun2 = [=, &b](int c)->int {return b += a + c; };cout << fun2(10) << endl;// 復制捕捉xint x = 10;auto add_x = [x](int a) mutable { x *= 2; return a + x; };cout << add_x(10) << endl;return 0;
}?使用lambda表達式之后之前按照Goods的價格排序的代碼就變成下面這個樣子:
#include <algorithm>
#include <functional>
struct Goods
{string _name; // 名字double _price;// 價格int _evaluate;// 評價Goods(const char* str, double price, int evaluate):_name(str), _price(price), _evaluate(evaluate){}};ostream& operator<<(ostream& out, const Goods& g)
{out << g._name << " "<< "評價" << g._evaluate << " " << "價格" << g._price << endl;return out;
}int main()
{vector<Goods> v = { { "蘋果", 2.1, 5 }, { "香蕉", 3, 4 }, { "橙子", 2.2, 3 }, { "菠蘿", 1.5, 4 } };sort(v.begin(), v.end(), [](const Goods& g1, Goods g2) ->bool {return g1._price < g2._price; });for (auto e : v)cout << e;cout << "---------------------------" << endl;sort(v.begin(), v.end(), [](const Goods& g1, Goods g2) ->bool {return g1._price < g2._price; });for (auto e : v)cout << e;
}sort的第三個參數傳lambda表達式即可:?


這里可能存在一個疑問, lambda表達式為什么可以直接傳遞使用呢?
這里的lambda表達式實際上是一個對象, 上面的直接傳遞就是創建了一個匿名函數對象,將這個匿名對象進行傳遞.
sort的第三個參數是一個可調用對象的模板, 只要傳過去的參數是一個(可進行比較的)可調用對象即可, 所以傳函數指針, 仿函數, lambda表達式都可以.

如果我想接收這個lambda表達式返回的匿名對象呢?
可以用auto接收, 不用管返回值的類型, auto會自動推導:
int main()
{auto fun1 = [](const string& s) {cout << s << endl; };fun1("hello fun1");//函數體夜可以寫成多行, 但一般lambda表達式不會太長auto fun2 = [](const string& s){cout << s << endl; return 0; };fun2("hello fun2");return 0;
}
捕獲列表說明?
捕捉列表描述了上下文中那些數據可以被lambda使用, 以及使用的方式傳值還是傳引用.
捕捉值:
[var]: 表示值傳遞方式捕捉變量var.
[=]: 表示值傳遞方式捕獲所有父作用域中的變量(包括this).捕捉引用:
[&var]: 表示引用傳遞捕捉變量var.
[&]: 表示引用傳遞捕捉所有父作用域中的變量(包括this).捕捉this:
[this]: 表示值傳遞方式捕捉當前的this指針.
這是一個簡單的交換兩個值的lambda函數:?
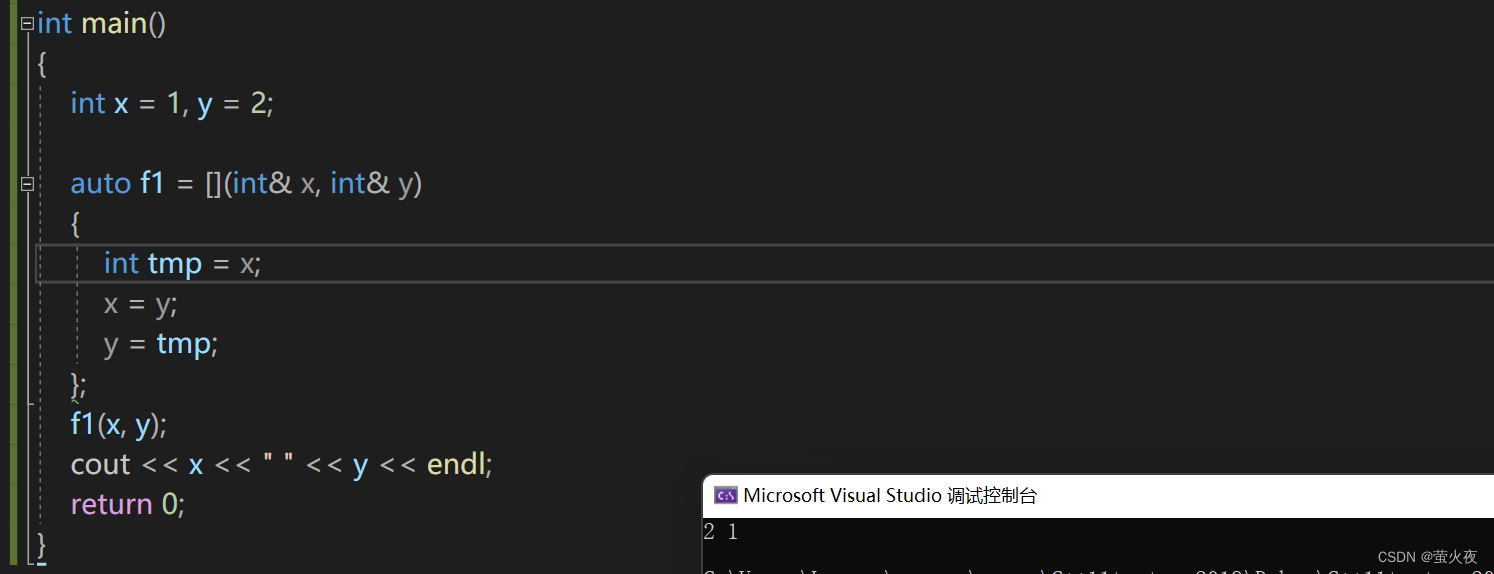 ?現在如果我只想對main函數里的x和y進行交換呢? 可以用捕獲列表進行捕獲:?
?現在如果我只想對main函數里的x和y進行交換呢? 可以用捕獲列表進行捕獲:?
int main()
{int x = 1, y = 2;auto f1 = [x,y](){int tmp = x;x = y;y = tmp;};f1();cout << x << " " << y << endl;return 0;
}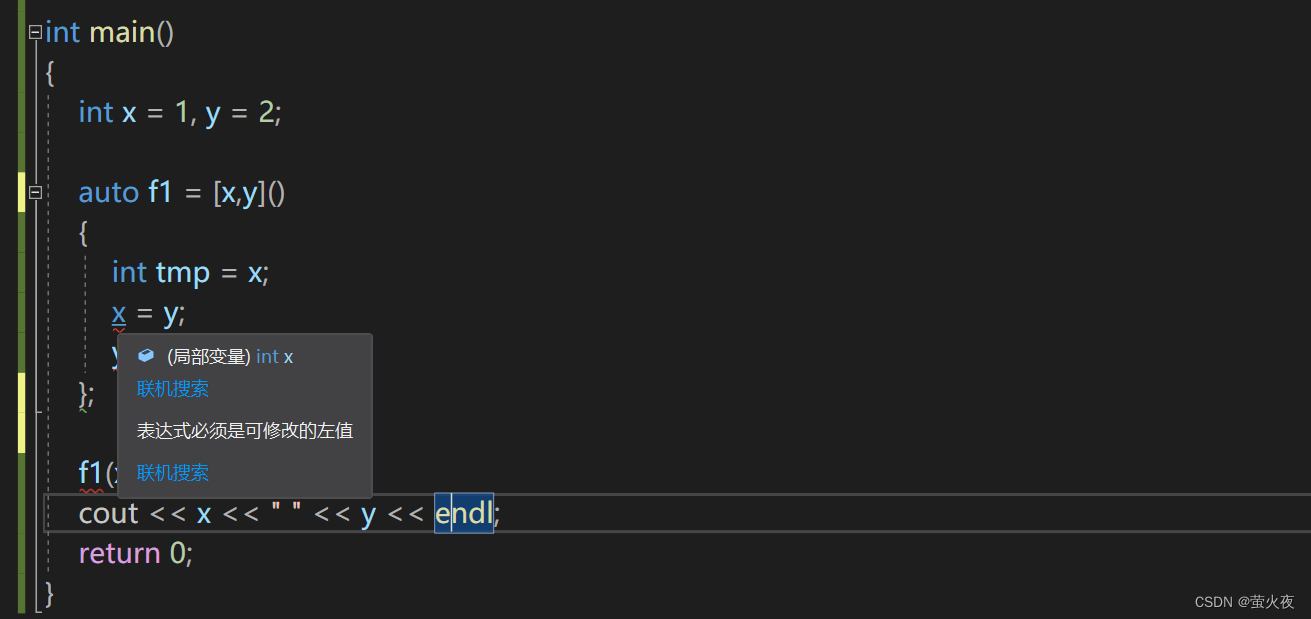
但是捕捉的值并不能進行修改, 為什么呢?
捕獲的值其實就相當于底層仿函數類中的成員變量,?而lambda不加mutable默認是const修飾的, 其實是底層的operator()是const修飾的, const修飾this指針就不能對類的成員變量進行修改, 所以加一個mutable即可:
int main()
{int x = 1, y = 2;auto f1 = [x,y]()mutable{int tmp = x;x = y;y = tmp;};f1();cout << x << " " << y << endl;return 0;
}?
但是結果并不是預期的值交換, 因為這里是傳值捕獲, 要想修改父作用域內捕獲的變量, 需要傳引用捕獲:

因為這里父作用域只有兩個變量, 所以也可以直接輸入一個&,?引用傳遞捕捉所有父作用域中的變量.
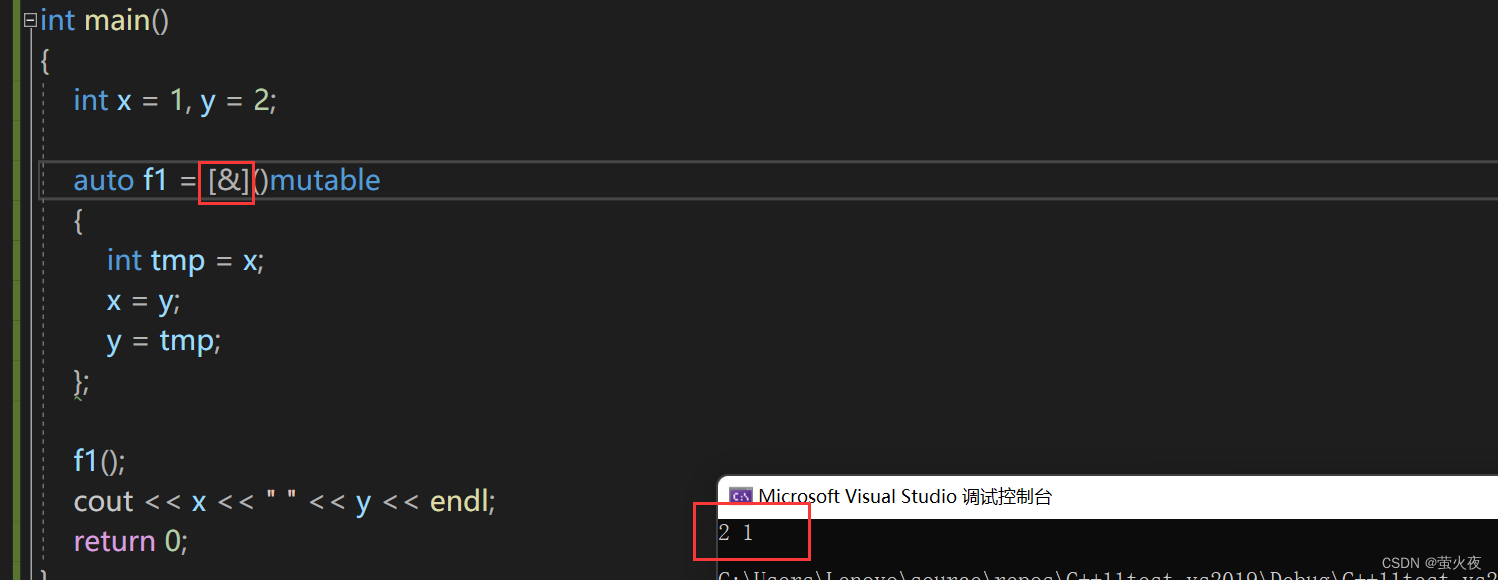
以引用方式捕捉就可以理解為仿函數中的兩個成員變量是引用, 引用分別用x和y初始化.
那傳引用捕捉這里的mutable可以去掉嗎? 按照上面的理解是不能去掉的, 但是實際可以去掉.?

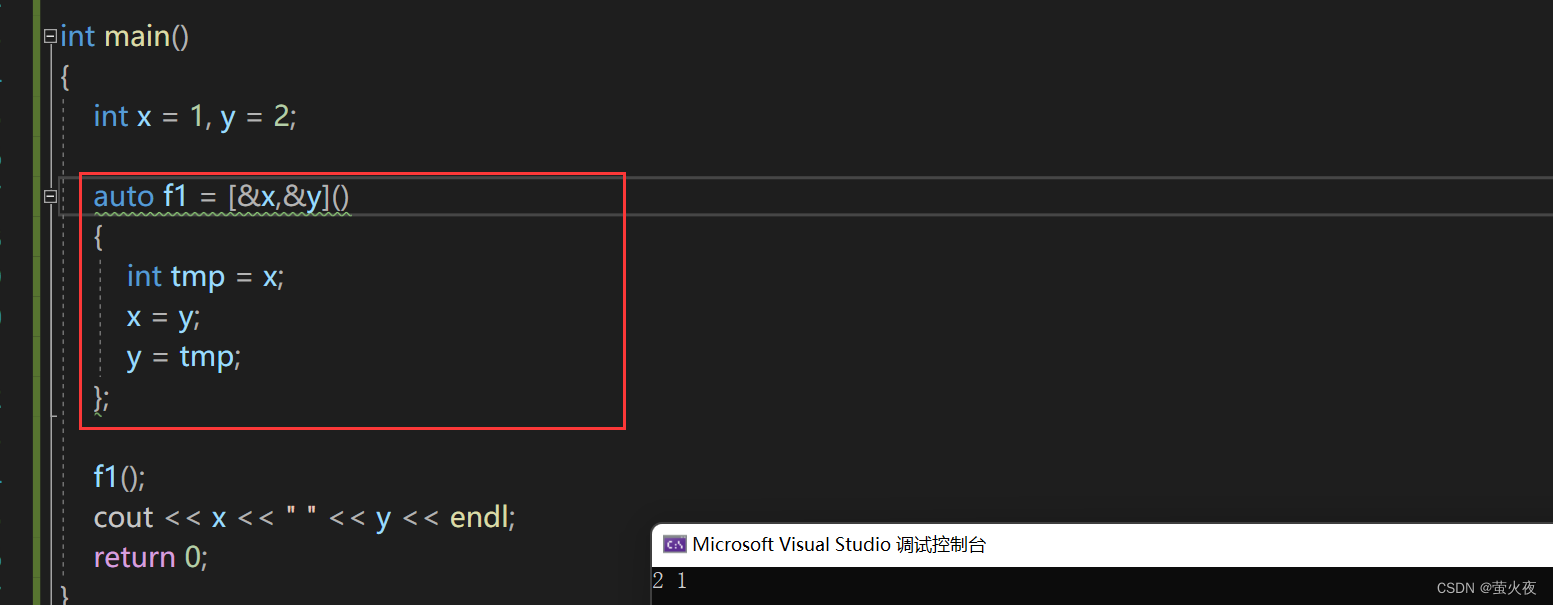
所以其實這里的mutable更多的針對傳值捕捉的變量, 不希望修改傳值捕捉的變量, 但傳引用捕捉其實就是為了修改, 又上mutable感覺就有些重復, 所以const只是一個形象的說法, 可以理解為mutable是專門為了處理傳值捕捉. 如果是傳值捕捉和引用捕捉混合想要修改傳值捕捉的變量還是要加mutable.
?最開始的捕獲說明部分有提到捕捉this, 捕捉this是什么?
class AA
{
public:void func(){auto f1 = [this](){cout << a1 << endl;cout << a2 << endl;};f1();}
private:int a1 = 1;int a2 = 1;
};int main()
{AA a;a.func();return 0;
}
直接用賦值符號捕捉也會默認捕捉this, 因為this實際也在父作用域中.
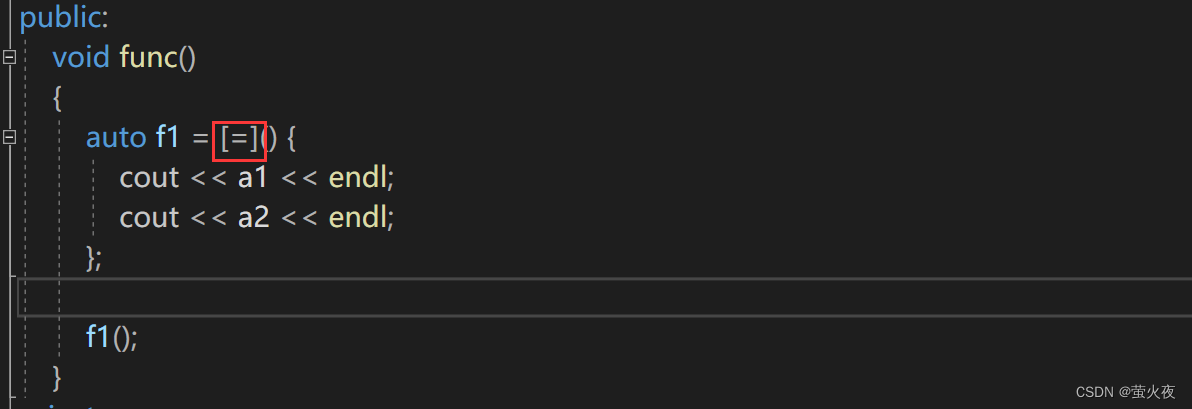 ?如果直接捕捉a1和a2呢??可以看到報錯了, 因為a1和a2并不在父作用域中, 而且還沒有捕捉this指針, 也無法訪問a1和a2, 因為類內訪問成員變量默認都是通過this訪問.
?如果直接捕捉a1和a2呢??可以看到報錯了, 因為a1和a2并不在父作用域中, 而且還沒有捕捉this指針, 也無法訪問a1和a2, 因為類內訪問成員變量默認都是通過this訪問.
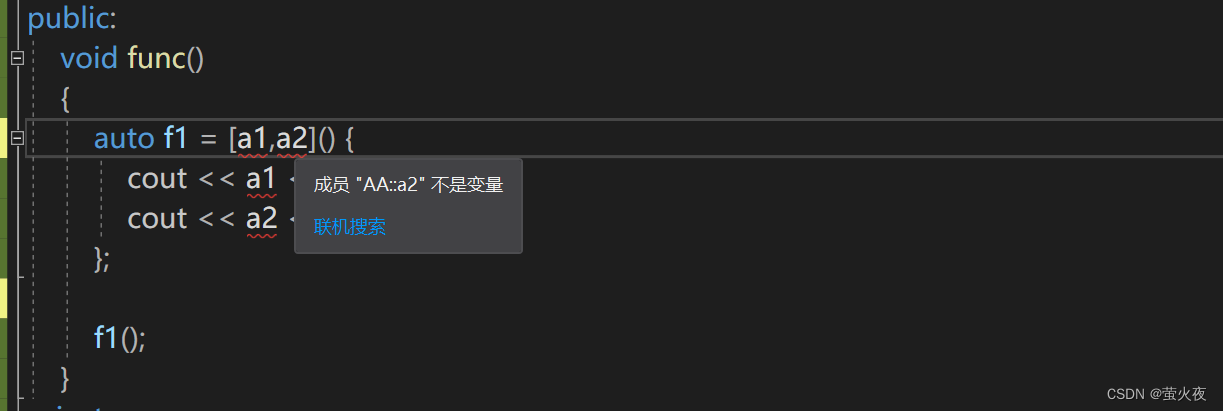

注意:
a. 父作用域指包含lambda函數的語句塊
b. 語法上捕捉列表可由多個捕捉項組成, 并以逗號分割. 比如:[=, &a, &b]: 以引用傳遞的方式捕捉變量a和b, 值傳遞方式捕捉其他所有變量
[&, a,this]: 值傳遞方式捕捉變量a和this, 引用方式捕捉其他變量.
c. 捕捉列表不允許變量重復傳遞, 否則就會導致編譯錯誤. 比如:[=, a]:=已經以值傳遞方式捕捉了所有變量, 捕捉a重復.
d. 在塊作用域以外的lambda函數捕捉列表必須為空.
e. 在塊作用域中的lambda函數僅能捕捉父作用域中局部變量, 捕捉任何非此作用域或者非局部變量都會導致編譯報錯.
f. lambda表達式之間不能相互賦值.
void (*PF)();
int main()
{auto f1 = [] {cout << "hello world" << endl; };auto f2 = [] {cout << "hello world" << endl; };//f1 = f2; ?// 編譯失敗--->提示找不到operator=()// 允許使用一個lambda表達式拷貝構造一個新的副本auto f3(f2);f3();// 可以將lambda表達式賦值給相同類型的函數指針PF = f2;PF();return 0;
}函數對象與lambda表達式?
?可以把lambda表達式的返回值類型打印出來看一看:
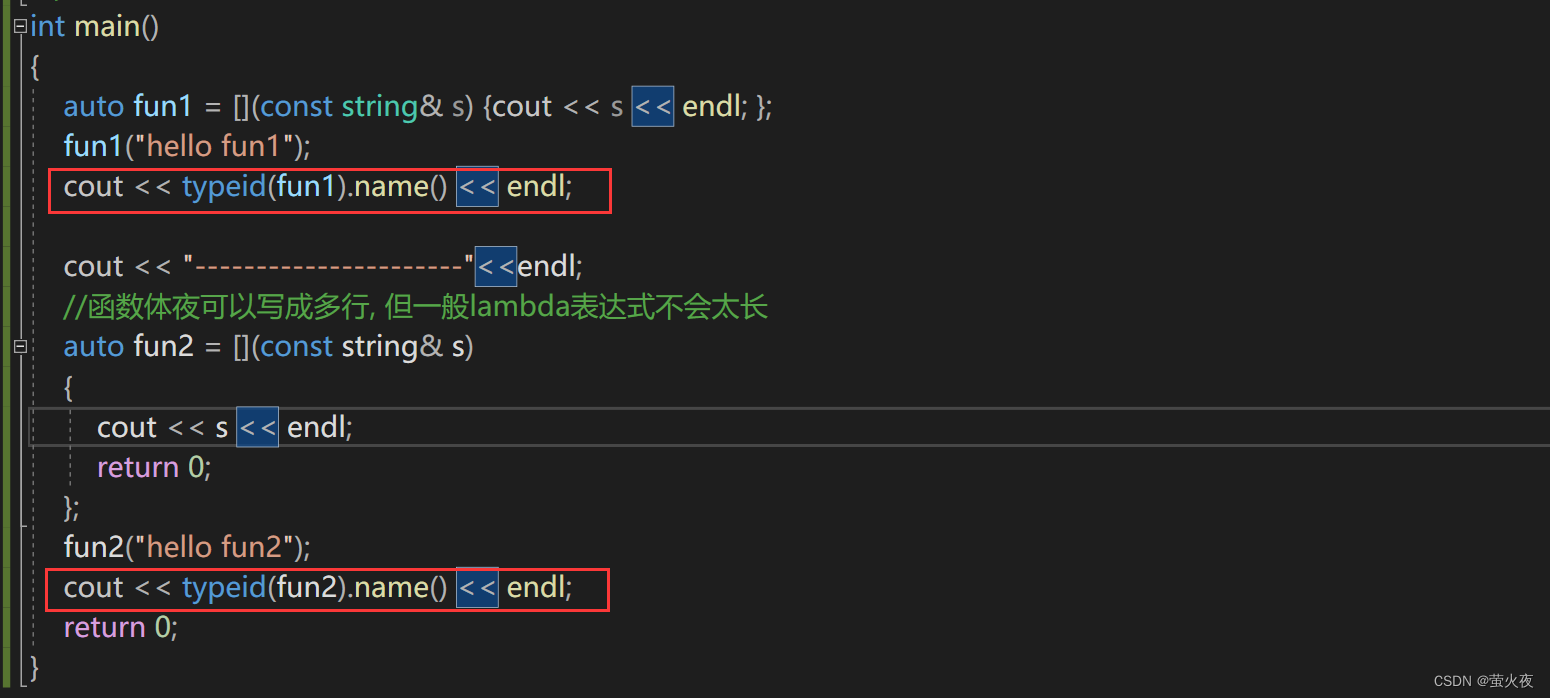

可以看到lambda的類型還是一個類, 它的具體名稱是lambda+UUID,?UUID叫作通用唯一識別碼, 它的作用是讓元素都能有唯一的辨識信息.?每個lambda都要生成一個的仿函數, 不同的仿函數對應的類型都應該不一樣.小科普:通用唯一標識碼UUID的介紹及使用 - 知乎 (zhihu.com)
從使用方式上來看, 函數對象與lambda表達式完全一樣.
class Rate
{
public:Rate(double rate) : _rate(rate){}double operator()(double money, int year){return money * _rate * year;}
private:double _rate;
};int main()
{// 函數對象double rate = 0.49;Rate r1(rate);r1(10000, 2);// lambdaauto r2 = [=](double monty, int year)->double {return monty * rate * year;};r2(10000, 2);return 0;
}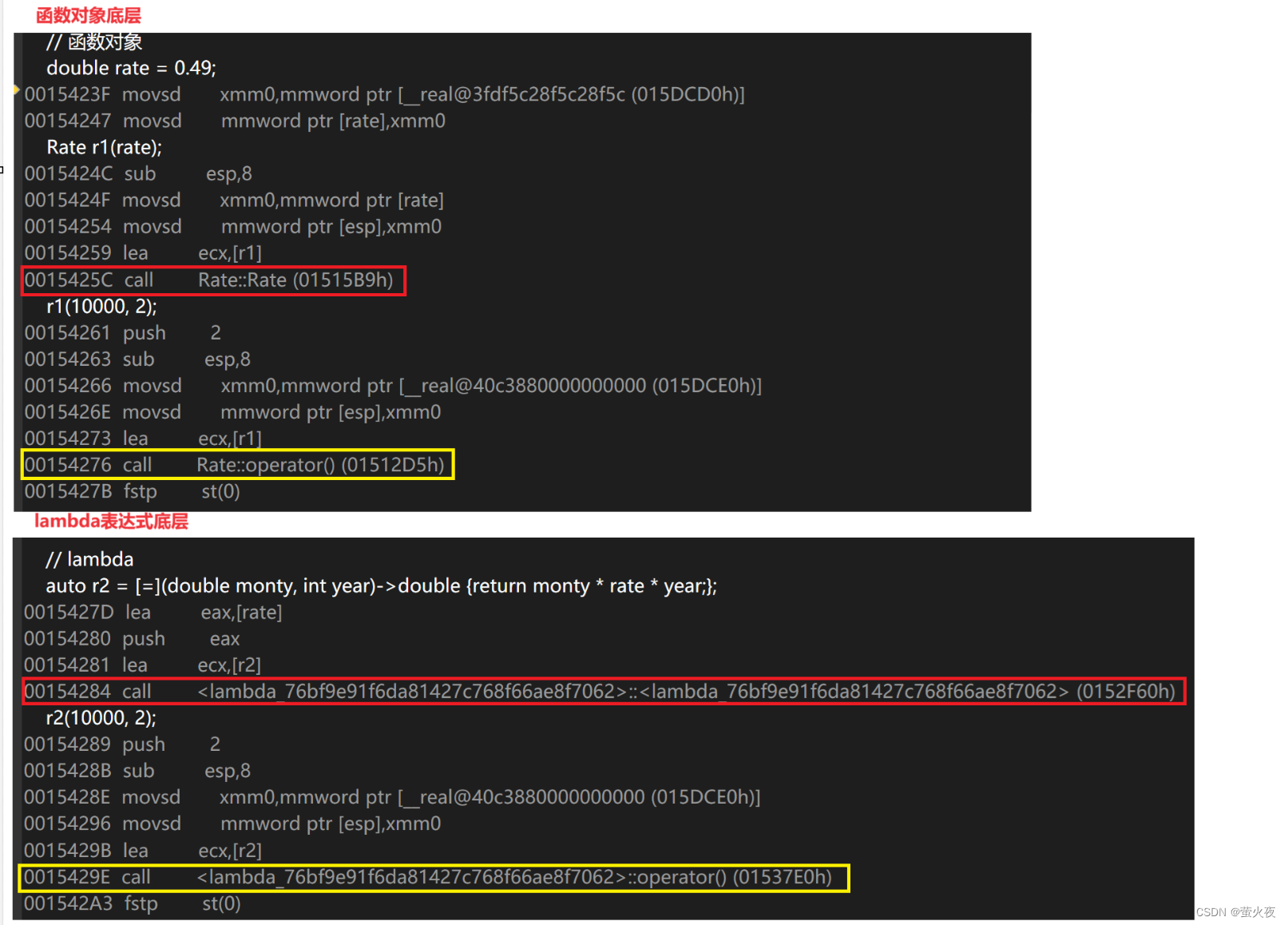
lambda真正到編譯階段就沒有所謂的"lambda", 實際在底層編譯器對于lambda表達式的處理方式, 完全就是按照函數對象的方式處理的,即:如果定義了一個lambda表達式, 編譯器會自動生成一個類, 在該類中重載了operator(), 說明lambda的底層其實還是仿函數, lambda傳入的那些形參, 返回值, 函數體最終是傳給了operator().
包裝器
function包裝器
function包裝器, 也叫作適配器. C++中的function本質是一個類模板, 也是一個包裝器.
那么我們來看看, 我們為什么需要function呢??
ret = func(x);上面func可能是什么呢, func可能是函數名?函數指針??函數對象(仿函數對象)??lamber表達式對象? 這幾個可調用對象其實各有自己的缺陷:
函數指針的缺點是類型寫起來太復雜, 仿函數的缺點是用起來比較"重", 需要在外部定義一個類才能實現, 哪怕是簡單的功能也要重新寫一個類, 于是就有了lambda, 但是lambda它的類型完全是隨機的, 雖然decltype可以取類型, 但是它的類型相對我們來說還是匿名的. 為了統一, 就出現了function包裝器.

模板參數說明:
Ret:?被調用函數的返回類型
Args…:?被調用函數的形參?
先分別用函數,仿函數,lambda表達式實現交換:
//函數
void Swap_func(int& r1, int& r2)
{int tmp = r1;r1 = r2;r2 = tmp;
}//仿函數
struct Swap
{void operator()(int& r1, int& r2){int tmp = r1;r1 = r2;r2 = tmp;}
};int main()
{//lambda表達式auto Swaplambda = [](int& r1, int& r2) {int tmp = r1;r1 = r2;r2 = tmp;};
}?然后再用包裝器分別對它們進行包裝:
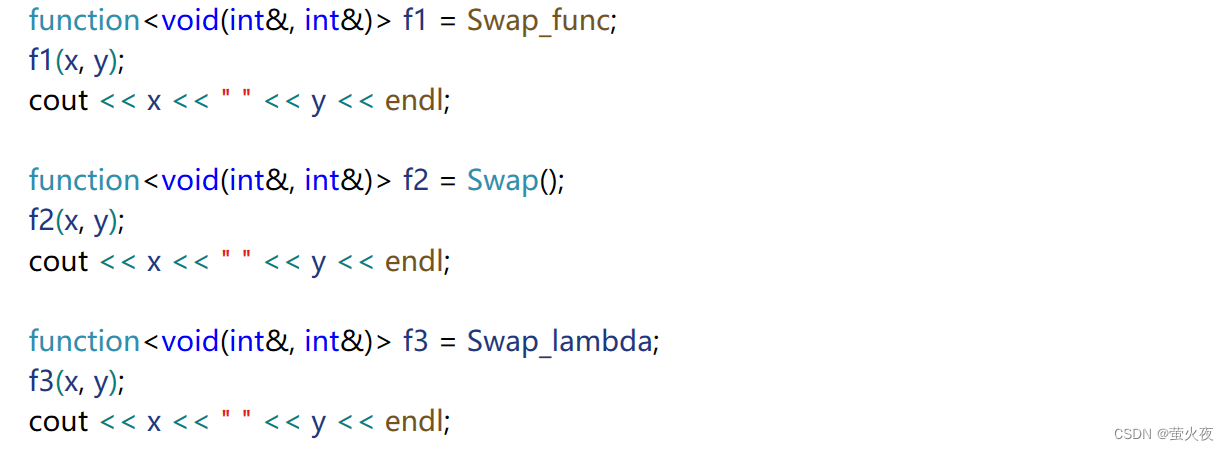

在此基礎上就可以讓function包裝器與map的配合使用:
std::function和std::map可以很好地配合使用, 以實現基于字符串的事件處理程序或回調函數的映射. 具體來說, 可以將不同的字符串映射到不同的std::function對象上, 然后根據字符串查找相應的函數并調用它.
假設需要實現一個簡單的命令行工具, 用戶可以輸入不同的命令, 然后程序會執行相應的操作, 可以使用std::map將不同的命令字符串映射到相應的std::function對象上, 然后在用戶輸入命令時查找相應的函數并調用它.

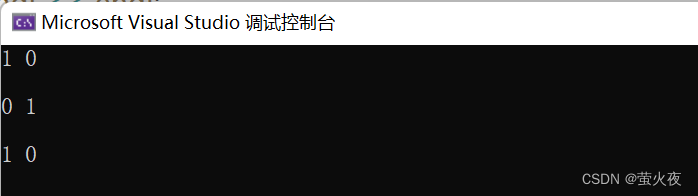
?除此之外,?函數指針,?函數對象(仿函數對象),?lamber表達式,?這些都是可調用的類型, 如此豐富的類型, 可能會導致模板的效率低下!
template<class F, class T>
T useF(F f, T x)
{static int count = 0;cout << "count:" << ++count << endl;cout << "count:" << &count << endl;return f(x);
}// 函數名
double f(double i)
{return i / 2;
}// 函數對象
struct Functor
{double operator()(double d){return d / 3;}
};int main()
{
// 函數名cout << useF(f, 11.11) << endl << endl;// 函數對象cout << useF(Functor(), 11.11) << endl << endl;// lamber表達式cout << useF([](double d)->double { return d / 4; }, 11.11) << endl << endl;return 0;
}我們知道static修飾的變量是存放在靜態區的它不會隨著函數的結束生命周期就終止, 所以我們每次調用函數的時候都可以看到它的值在不斷的累加并且地址也是一樣的.
但是如果模板實例化出來多個函數呢? 由于靜態變量是在函數第一次運行的時候進行創建, 而如果模板實例化出來多個函數, 所以每個函數的靜態成員變量地址就是不一樣的:
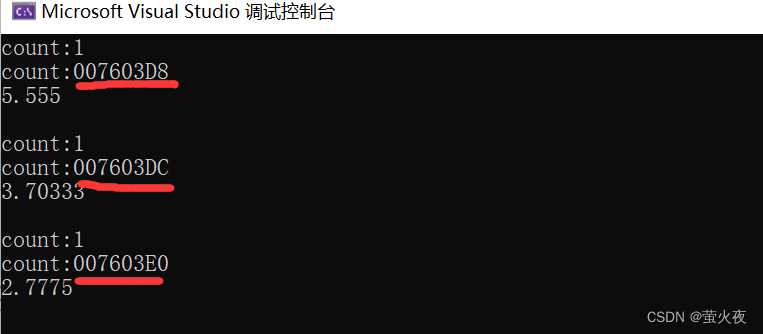
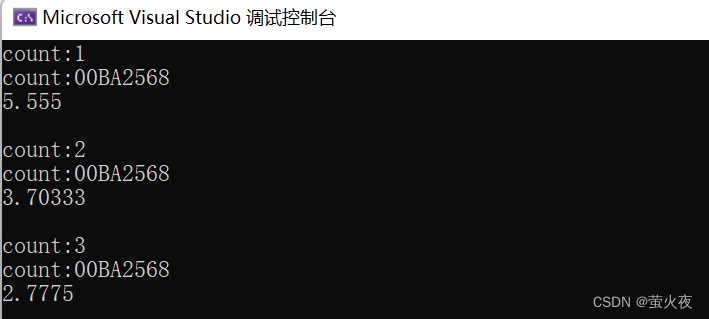
可以看到這里傳遞三個不同的對象過去, 并且函數模板也實例化出來了三個不同的函數對象, 但是這就有點浪費, 我們用包裝器就可以將這三個類型的對象合成一個類型, 這樣模板就只需要實例化出一個函數, 節省了很多資源.
template<class F, class T>
T useF(F f, T x)
{static int count = 0;cout << "count:" << ++count << endl;cout << "count:" << &count << endl;return f(x);
}// 函數名
double f(double i)
{return i / 2;
}// 函數對象
struct Functor
{double operator()(double d){return d / 3;}
};int main()
{
// 函數名function<double(double x)> f1 = f;cout << useF(f1, 11.11) << endl<<endl;// 函數對象function<double(double x)> f2 = Functor();cout << useF(f2, 11.11) << endl << endl;// lamber表達式function<double(double x)> f3 = [](double d)->double { return d / 4; };cout << useF(f3, 11.11) << endl << endl;return 0;
}
除此之外, 包裝器還可以包裝一些類的成員函數, 但是注意, 在包裝類中函數的時候需要指定作用域, 并且如果包裝的是非靜態成員函數得在作用域的前面加上&,?如果是靜態成員函數則加不加均可, 比如:
class Plus
{
public:static int plusi(int a, int b){return a + b;}double plusd(double a, double b){return a + b;}
};int main()
{// 成員函數取地址, 比較特殊, 要加一個類域和&//靜態成員函數加不加&均可function<int(int, int)> f1 = Plus::plusi; function<int(int, int)> f1 =& Plus::plusi;cout << f1(1, 2) << endl;//非靜態成員函數需要加&function<double(double, double)> f2 = &Plus::plusd;Plus ps;cout << f2(1.1, 2.2) << endl;return 0;
}但是這里依然編譯不通過, 通過報錯信息可以看到這里類型不匹配, 模板參數少了一個Plus*類型的參數:

類的成員函數還有一個默認的this指針需要傳, 加上之后編譯通過:?

也可以這樣:
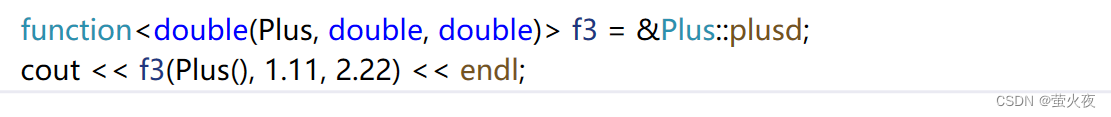

可以理解成傳對象的指針就用對象的指針去調用函數指針, 傳對象就用對象去調用函數指針.
第二種寫法也更簡潔, 不需要定義一個對象再取地址.
能不能每次不傳這個第一個參數?
第一種方法我們可以創建一個該類型的對象, 然后通過lambda表達式來捕捉這個對象, 最后調用里面的函數來實現同樣的功能, 那么這里的代碼就如下:
int main()
{Plus plus;function<int(int, int)> f = [&plus](double x, double y)->double {return plus.plusd(x, y); };cout<<f(1.1, 2.2)<<endl;return 0;
}
第二種方法可以用bind
bind
std::bind函數定義在頭文件中, 是一個函數模板, 它就像一個函數包裝器(適配器), 接受一個可
調用對象(callable object),生成一個新的可調用對象來“適應”原對象的參數列表.
// 原型如下:
template <class Fn, class... Args>
/* unspecified */ bind (Fn&& fn, Args&&... args);
// with return type (2)
template <class Ret, class Fn, class... Args>
/* unspecified */ bind (Fn&& fn, Args&&... args);fn表示調用的對象, Args表示的就是調用對象的參數列表.
一般而言, bind有兩個用途:
1.我們用它可以把一個原本接收N個參數的函數fn, 通過綁定一些參數, 返回一個接收M個參數的新函數(M一般小于N, M也可以大于N, 但這么做沒什么意義).
2. 使用std::bind函數還可以實現參數順序調整等操作.
可以將bind函數看作是一個通用的函數適配器, 它接受一個可調用對象, 生成一個新的可調用對
象來“適應”原對象的參數列表.
調用bind的一般形式: auto newCallable = bind(callable, arg_list);
其中, newCallable本身是一個可調用對象, arg_list是一個逗號分隔的參數列表, 對應給定的
callable的參數. 當我們調用newCallable時, newCallable會調用callable, 并傳給它arg_list中
的參數.
arg_list中的參數可能包含形如_n的名字, 其中n是一個整數, 這些參數是“占位符”, 表示
newCallable的參數, 它們占據了傳遞給newCallable的參數的“位置”. 數值n表示生成的可調用對
象中參數的位置:_1為newCallable的第一個參數, _2為第二個參數, 以此類推.
int Sub(int a, int b)
{return a - b;
}int main()
{function<int(int, int)> f1 = Sub;cout << f1(10, 5) << endl;// 調整參數順序, 第一個參數和第二個參數位置互換function<int(int, int)> f2 = bind(Sub, placeholders::_2, placeholders::_1);cout << f2(10, 5) << endl;// 調整參數個數,有些參數可以bind時寫死function<int(int)> f3 = bind(Sub, 20, placeholders::_1);cout << f3(5) << endl;return 0;
}bind一般和function結合在一起進行使用, 后面的bind我們知道第一個參數表示的是需要綁定的函數對象, 那后面的placeholders::_1和placeholders::_2又代表的是什么意思呢?

可以看到placeholders是一個命名空間, 上面的bind表示的就是第二個位置傳遞給第一個參數, 第一個位置則傳遞給第二個參數.?

?之前的plus類可以試著把第一個參數綁定, 這樣每次調用就不需要傳一個對象了:

可以查看一下綁定之后的f3的類型:?
int Sub(int a, int b)
{return a - b;
}int main()
{// 調整參數個數,有些參數可以bind時寫死function<int(int)> f3 = bind(Sub, 20, placeholders::_1);cout <<"第一個參數綁定為20后: " << f3(5) << endl;cout << typeid(f3).name() << endl;return 0;
}
可以看到還是一個function的類型.?
如果用auto接受bind的返回值:?
int Sub(int a, int b)
{return a - b;
}int main()
{// 調整參數個數,有些參數可以bind時寫死/*function<int(int)> f3 = bind(Sub, 20, placeholders::_1);*/auto f3 = bind(Sub, 20, placeholders::_1);cout <<"第一個參數綁定為20后: " << f3(5) << endl;cout << typeid(f3).name() << endl;return 0;
}
變成了bind對應的類型.?
如果有多個參數能不能只綁定中間的參數呢?
void func(int a, int b, int c)
{cout << a << endl;cout << b << endl;cout << c << endl;
}int main()
{function<void(int, int)> f1 = bind(func, placeholders::_1, 100, placeholders::_2);f1(1, 3);return 0;
}
可以, 所以這里_1代表第一個實參, _2代表第二個實參, 這里原來func的第二個參數綁定了, 下一個參數不是_3, 而應該是_2, 對應著是綁定調用的時候的實參順序.








知識總結)
)
)





更改)


