今年5月份開始準備考,沒想到會突然改革,還好刷題刷的多,也過了。
跟著B站up主的視頻學的,都學了一遍之后才開始刷題,平時要上班,也就下班和周末能學,時間可能拉的比較長,學完前面的內容已經忘的差不多了。
下半年改成機考,上午題和下午題合在一起考,時間也縮短了一個小時。機考對于上午題來說沒太大區別,就是題目打亂了,改動大的可能是考點,雖然考前把15年到23年的真題都刷了,然后近幾年的又重復刷,熟悉的題目有,但是不多,考了挺多不認識的概念。下午題題型沒有變化,就是那個軟件是真的難用!!!
機考有自帶計算器,沒怎么用,還是用草稿紙。因為軟件上有倒計時,所以不讓帶手表進考場。
B站up主:zst_2001
公式
計算海明碼公式
數據位是n位,校驗位是k位,則n和k必須滿足以下關系:2k-1≥n+k
指令流水線
一條指令執行時間分取指、分析、執行三段,n條指令所需時間:第1條指令的執行時間+(n-1)*(最長時間段)
進程死鎖計算公式
m為資源數量,n為進程數量,k為每個進程需要的資源數量
m≥n*(k-1)+1
位示圖:需要統一單位
(磁盤容量/物理塊大小)/字長位數
串聯系統
R=R1R2…Rn
并聯系統
R=1-(1-R1)(1-R2)…(1-Rn)
單緩沖區
T為輸入時間,M為傳輸時間,n為作業個數,C為處理時間:
計算單緩沖區花費的時間:(T+M)*n+C
雙緩沖區
T為輸入時間,M為傳輸時間,n為作業個數,C為處理時間:
計算雙緩沖區花費的時間:T*n+M+C
磁盤旋轉調度算法
單個讀取時間 = 旋轉周期/物理塊數量
X=處理完位置到下一個記錄起始位置所需時間
順序處理:(單個讀取時間+單個處理時間+X)*(物理塊數量-1) + (單個讀取時間+單個處理時間)
優化處理:(單個讀取時間+單個處理時間)*物理塊數量
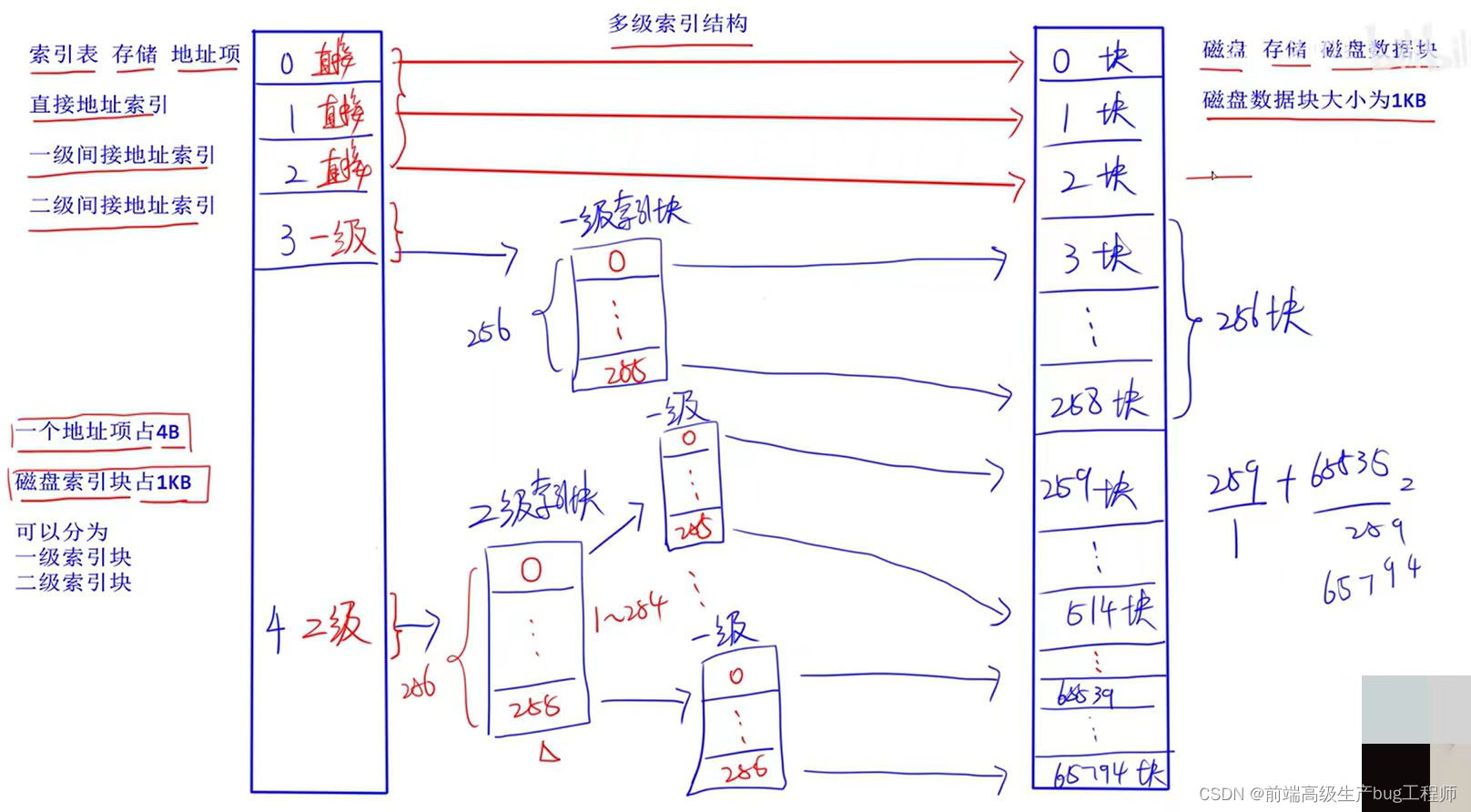
多級索引結構
UML圖中
+public
-private
#protected
~package
DNS域名的查詢次序
本地hosts文件–>本地DNS緩存—>本地DNS服務器—>根域名服務器
主域名服務器在接收到域名請求后,查詢順序是
本地緩存–>本地 hosts 文件–>本地數據庫–>轉發域名服務器
使用ping命令進行網絡檢測,按照由近及遠原則
首先執行的是ping127.0.0.1,其次是ping本地IP,再次是ping默認網關,最后是ping遠程主機
子網號可以為全0和全1,主機號不能為全0或全1,因此,主機數需要-2,而子網數不用
www的控制協議是HTTP
語法分析方法分為兩類
自上而下(自頂向下)分析法和自下而上(自底向上)分析法,
遞歸下降分析法和預測分析法屬于自上而下分析法,
移進-歸約分析法屬于自下而上(自底向上)分析法。
編譯器的工作方式及特點是:先翻譯后執行,用戶程序運行效率高但可移植性差。
解釋器的工作方式及特點是:邊翻譯邊執行,用戶程序運行效率低但可移植性好。
深度優先搜索(DFS)
鄰接矩陣:時間復雜度O(n2) 鄰接表:時間復雜度O(n+e)
廣度優先搜索(BFS)
鄰接矩陣:時間復雜度O(n2) 鄰接表:時間復雜度O(n+e)
常見算法邏輯的時間復雜度
(1)單個語句,或程序無循環和復雜函數調用:O(1)
(2)單層循環:O(n);雙層嵌套循環:O(n2);三層嵌套循環:O(n3)
(3)樹形結構、二分法、構建堆過程:O(log2n)
(4)堆排序、歸并排序:O(nlog2n)
(5)所有不同可能的排列組合:O(2n)
基本單詞
- implements 實現接口
- extends 繼承類
- private 私有的
- public 公共的
- abstract 抽象的
- protected 受保護的
- interface 接口
運算器
算術邏輯運算單元
累加寄存器
狀態條件寄存器
通用寄存器組
控制器
程序計數器
指令寄存器
地址寄存器
指令譯碼器
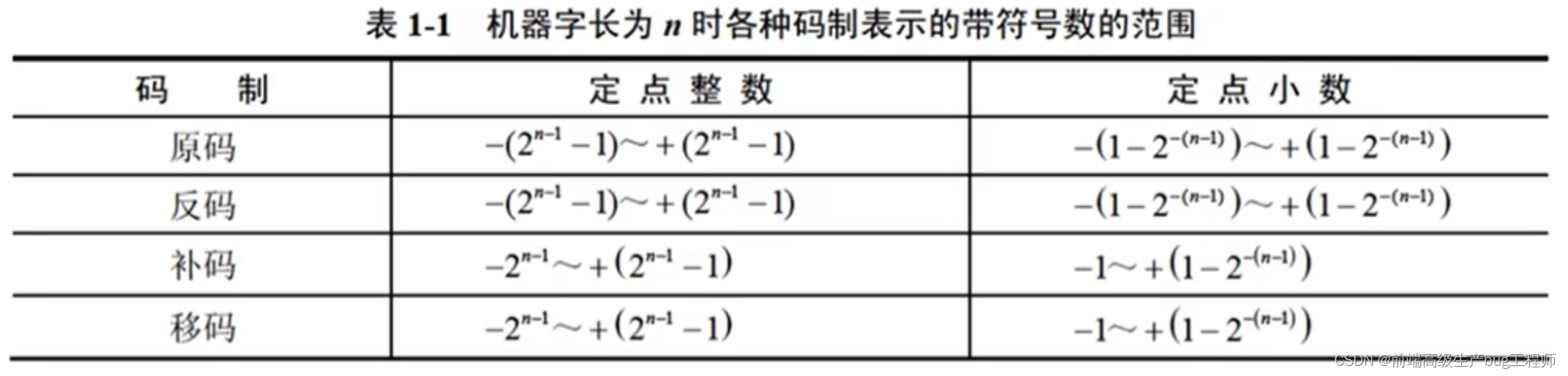
原碼、反碼、補碼、移碼
浮點數
浮點數的加減運算過程:對階、尾數計算、結果格式化
對階時,小數向大數靠齊;
對階是通過較小數向較大數的尾數右移實現的
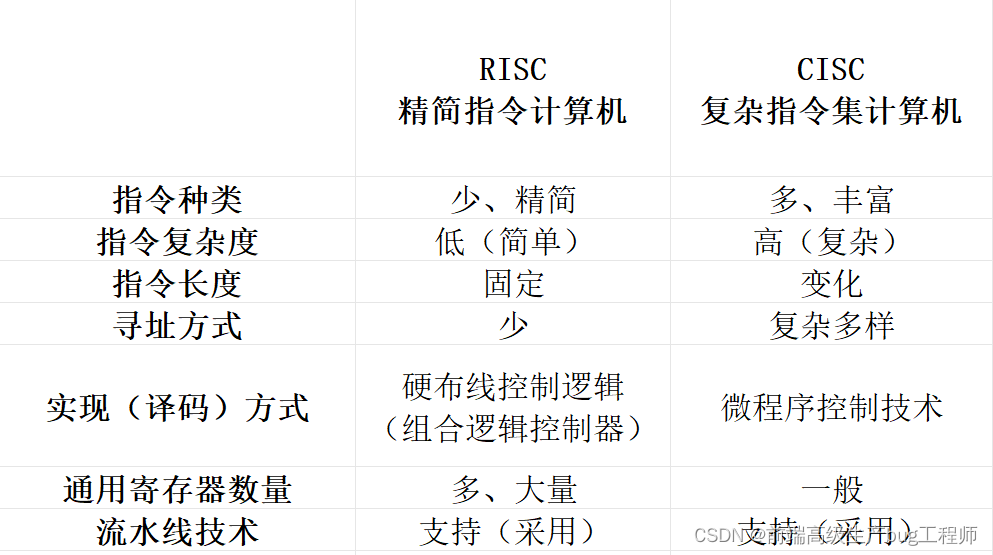
RISC與CISC
尋址
①立即尋址:操作數直接存放在指令中,速度快,靈活性差
③直接尋址:指令中存放的是操作數的地址
⑤間接尋址:指令中存放了一個地址,這個地址對應的內容是操作數的地址
②寄存器尋址:寄存器存放操作數
④寄存器間接尋址:操作數放在內存單元中
公鑰、私鑰
公鑰體系中,公鑰是用于加密和認證,私鑰用于解密和簽名
數字證書對身份進行認證,數字簽名確保消息不可否認
加密算法
對稱密鑰(私鑰、私有密鑰加密、共享密鑰加密)算法:
1、DES
2、3DES
3、RC-5
4、IDEA
5、AES
6、RC4
非對稱密鑰(公鑰、公開密鑰加密)算法:
1、RSA
2、ECC
3、DSA
Hash函數
MD5摘要算法
SHA-1安全散列算法
詞法分析
分析構成程序的字符及由字符按照構造規則構成的符號是否符合程序語言的規定
語法分析
對各條語句的結構進行合法性分析
分析程序中的句子結構是否正確
語法分析階段可以發現程序中的所有語法錯誤
語義分析
進行類型分析和檢查
語義分析階段不能發現程序中所有的語義錯誤
語義分析階段可以發現靜態語義錯誤,不能發現動態語義錯誤,動態語義錯誤運行時才能發現
C/C++語言經過預處理、編譯、匯編、鏈接后形成可執行程序
著作權(版權)
發表權受時間限制,署名權、修改權、保護作品完整權永遠屬于作者
Windows 無效地址: 169.254.X.X,Linux 無效地址: 0.0.0.0
三級模式結構
概念模式:基本表
外模式:視圖
內模式:存儲文件
設計模式(重點!!!要背!!!)
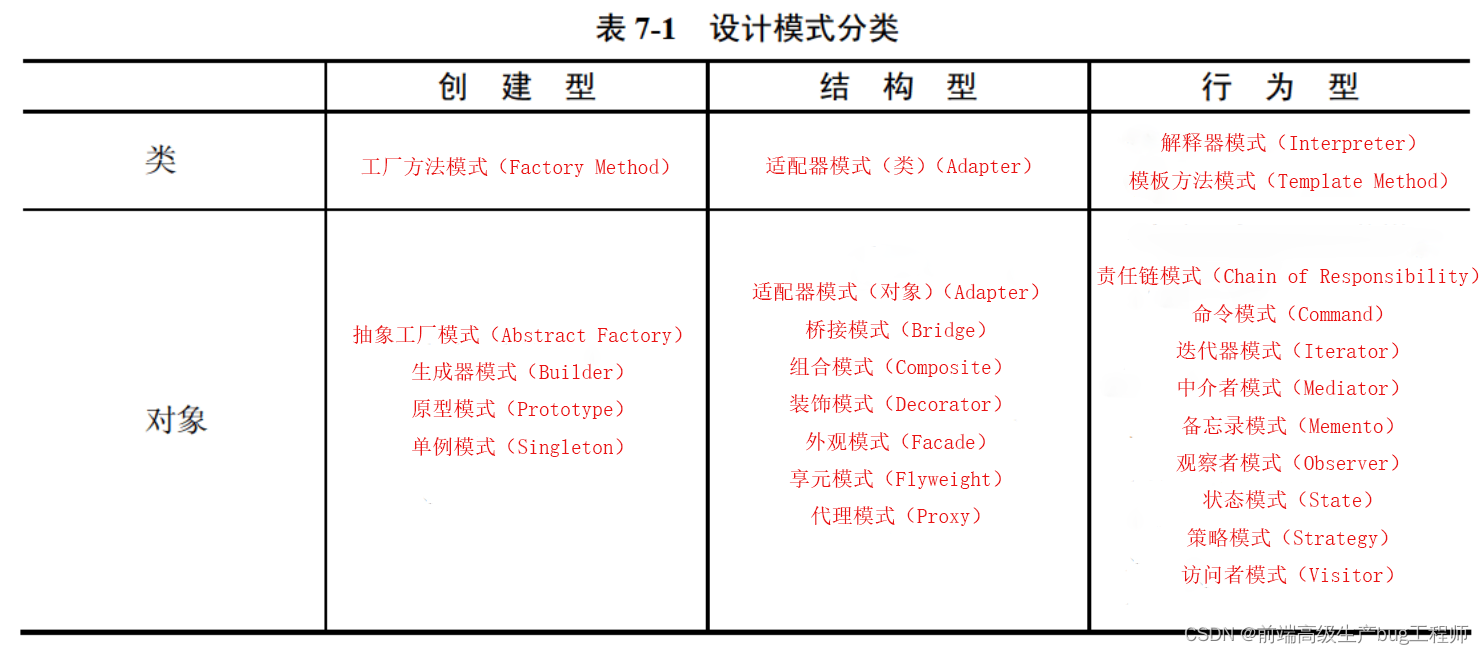



UML4種關系
依賴關系:一個事物發生變化影響另一個事物
泛化關系:特殊/一般的關系
實現關系:類元之間的語義關系
關聯關系:結構關系
聚合關系:整體與部分生命周期不同
組合關系:整體與部分生命周期相同
包含關系
包含關系描述的是一個用例需要某種功能,而該功能被另外一個用例定義,那么在用例的執行過程中,就可以調用已經定義好的用例。表示符號:<>
擴展關系
用一個用例(可選)擴展另一個用例(基本例)的功能,將一些常規的動作放在一個基本用例中,將可選的或只在特定條件下才執行的動作放在它的擴展用例中。表示符號:<>
泛化關系
泛化是一種特殊/一般關系,特殊元素(子元素)的對象可替代一般元素(父元素)的對象
泛化關系用一條帶有空心箭頭的實線,它指向父元素
包含include
一個用例包含另一個用例,當基本用例執行時,被包含用例一定會執行。包含關系由基本用例指向被包含用例,關系是一條帶箭頭的虛線,虛線上包含<>
擴展extend
當一個用例執行時,可能會出現特殊情況和可選情況這個時候就會執行擴展用例。擴展關系由擴展用例指向基本用例,關系是一條帶箭頭的虛線,虛線上包含<>
泛化generalize
父用例泛化子用例,子用例繼承父用例的所有屬性和行為,并且父用例可以出現的地方,子用例都可以將其替換。
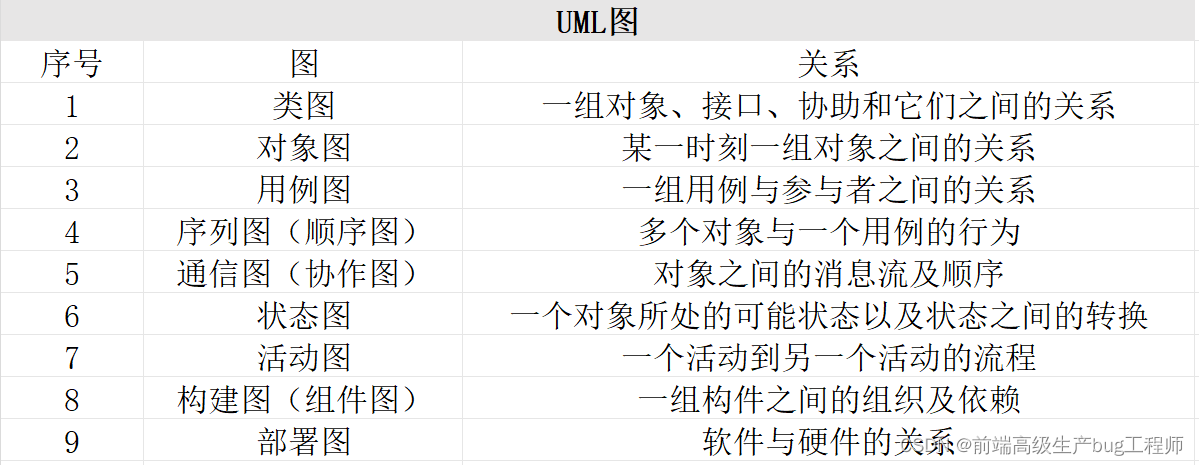
UML圖
攻擊類型
主動攻擊:篡改、偽造、中斷
被動攻擊:竊聽/截獲
網絡設備
物理層:中繼器、集線器
數據鏈路:網橋、交換機
網絡層:路由器
URL格式
協議名://主機名.組名.最高層域名
排序算法(重點!!!要背!!!)
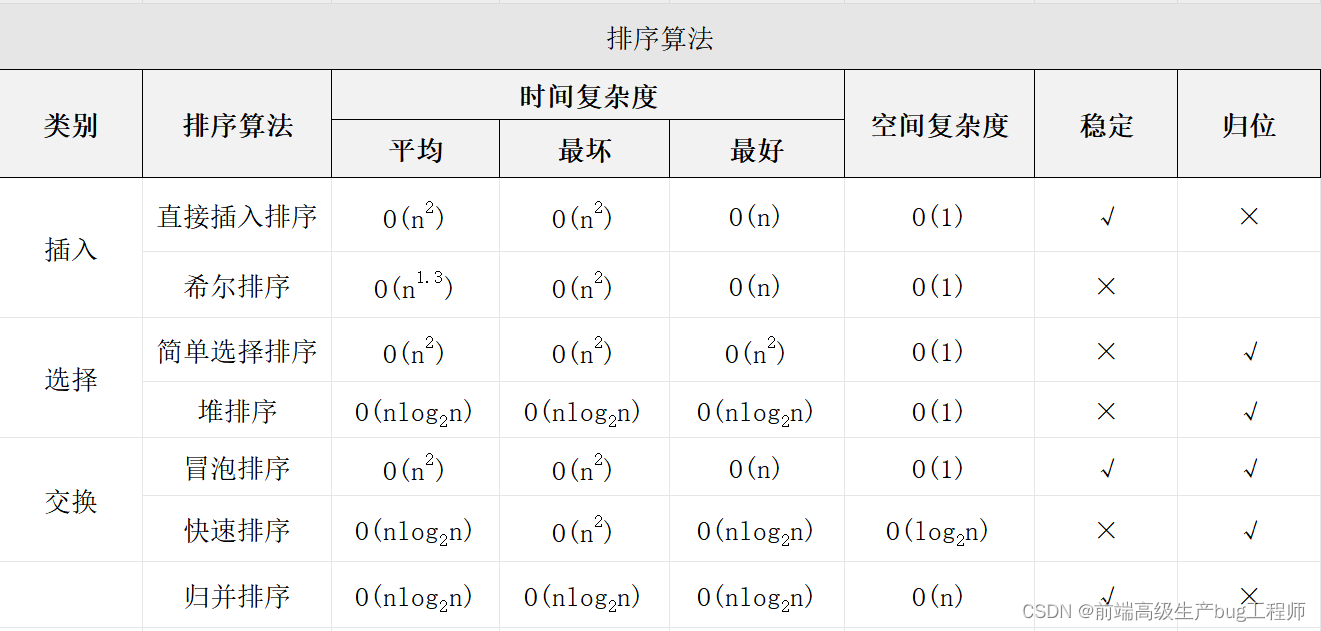
算法
回溯法-N皇后問題
深度優先策略
達不到(最優)目標,就退回再走
分治法
將復雜問題分解成若干規模相同的子問題
動態規劃
類似于分治法,但具有最優子結構性質和重疊子問題性質
貪心法
最優子結構、貪心選擇性質
不從整體考慮只求當前局部最優解
分支限界法
以廣度優先或最小耗費優先



![[BJDCTF2020]EzPHP 許多的特性](http://pic.xiahunao.cn/[BJDCTF2020]EzPHP 許多的特性)











 + cuDNN(12.x) 卸載)



