背景:LLM → \to → Agent
ChatGPT為代表的大語言模型就不用過多的介紹了,ChatGPT很強大,但是也有做不到的東西。例如:
- 實時查詢問題:實時的天氣,地理位置,最新新聞報道,現實世界正在發生和剛結束的信息等
- 不能產生動作:你只能獲得語言的回復,而不能讓它執行動作。當然也有類似的工作(Reac、AutoGPT)
- 無法訪問專有信息源。模型無法訪問專有信息,例如公司數據庫中的客戶名冊或在線游戲的狀態。
- 缺乏推理能力。某些推理超出了神經方法的能力范圍,需要專門的推理過程。我們在上面看到了算術推理的經典例子。 GPT-3 和 Jurassic-1 在 2 位加法上表現良好,令人印象深刻,但在 4 位加法上自信地給出了無意義的答案。隨著訓練時間的增加、更好的數據和更大的模型,LLM 的性能將會提高,但不會達到 20 世紀 70 年代 HP 計算器的魯棒性。而數學推理只是冰山一角。
- 微調成本問題。微調和服務多個大型模型是不切實際的。我們也無法針對訓練中未涵蓋的新任務進一步調整經過多任務訓練的 LLM ;由于災難性遺忘,添加新任務需要對整個任務集進行重新訓練。考慮到訓練此類模型的成本,這顯然是不可行的。
那么Agent又是什么?
agent用來調用外部 API 來獲取模型權重中缺失的額外信息(通常在預訓練后很難更改),包括當前信息、代碼執行能力、對專有信息源的訪問等。
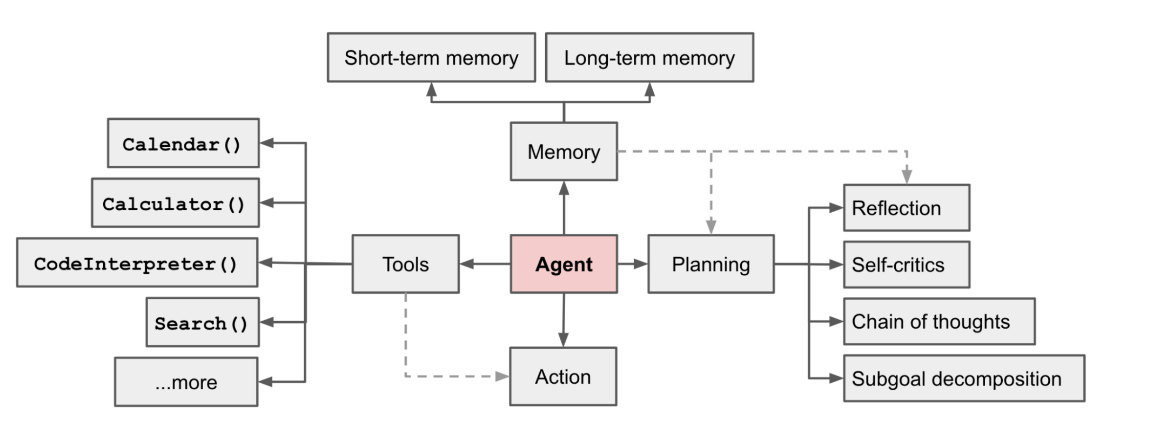
四大板塊:Planing、Memory、Tools、Action
API-Bank
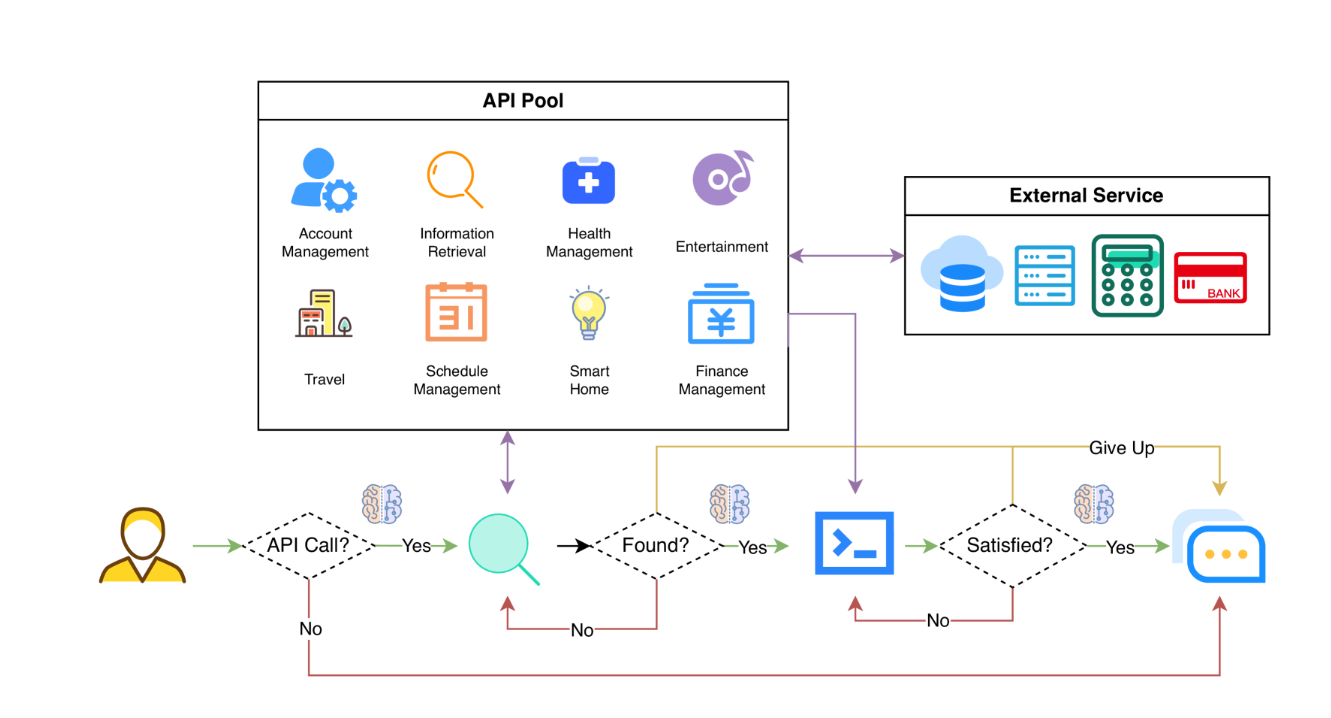

Tools調用API的工作流程:
- 判斷是否需要API調用。
- 確定要調用的正確 API:如果不夠好,LLM需要迭代修改 API 輸入(例如,確定搜索引擎 API 的搜索關鍵字)。
- 基于API結果的響應:如果結果不滿意,模型可以選擇細化并再次調用。
從三個層面評估代理的工具使用能力:
- 評估調用API的能力。給定 API 的描述,模型需要確定是否調用給定的 API、正確調用它并正確響應 API 返回。
- 檢查檢索 API 的能力。模型需要搜索可能解決用戶需求的API,并通過閱讀文檔來學習如何使用它們。
- 評估除了檢索和調用之外規劃 API 的能力。考慮到不明確的用戶請求(例如安排小組會議、預訂旅行的航班/酒店/餐廳),該模型可能必須進行多個 API 調用來解決它。
生成式Agent

生成Agent的設計將 LLM 與記憶、規劃和反射機制相結合,使代理能夠根據過去的經驗進行行為,并與其他代理進行交互。
-
記憶流(Memory stream):是一個長期記憶模塊(外部數據庫),記錄了代理在自然語言中的經驗的完整列表。
- 每個元素都是一個觀察結果,一個由代理直接提供的事件。 - 代理間通信可以觸發新的自然語言語句。
-
檢索模型:根據相關性、新近度和重要性,呈現上下文以告知代理的行為。
-
新近度Recency:最近發生的事件得分較高
-
重要性Importance:區分平凡記憶和核心記憶。直接問LLM。
-
相關性Relevance:基于它與當前情況/查詢的相關程度。
-
-
反射機制Reflection mechanism:隨著時間的推移將記憶合成更高層次的推論,并指導智能體未來的行為。它們是對過去事件的更高層次的總結(<-注意,這與上面的自我反思有點不同)
- 提示 LLM 提供 100 個最新觀察結果,并根據一組觀察結果/陳述生成 3 個最顯著的高級問題。然后請LM回答這些問題。
-
規劃和反應:將反思和環境信息轉化為行動
- 規劃本質上是為了
優化當前與時間的可信度。
- 規劃本質上是為了
-
提示模板: {Intro of an agent X}. Here is X’s plan today in broad strokes: 1)
Relationships between agents and observations of one agent by another are all taken into consideration for planning and reacting. -
規劃和反應時都會考慮主體之間的關系以及一個主體對另一個主體的觀察。
-
環境信息以樹形結構呈現。






)





![實用篇 | 3D建模中Blender軟件的下載及使用[圖文詳情]](http://pic.xiahunao.cn/實用篇 | 3D建模中Blender軟件的下載及使用[圖文詳情])

方法或展開語法(...)來合并對象)
聊天簡易版)



