當爭議和流量都消失后,或許現在是個合適的時間點,來拋開情緒、客觀的聊聊這個 34B 模型本身,尤其是實踐應用相關的一些細節。來近距離看看這個模型在各種實際使用場景中的真實表現和對硬件的性能要求。
或許,這會對也想在本地私有化部署和運行模型的你有幫助,本篇是第一篇相關內容。
寫在前面
前幾周,我曾經寫過一篇,如何使用 CPU、CPU & GPU 來本地運行零一萬物 34B 模型:《本地運行“李開復”的零一萬物 34B 大模型》。隨后社區里出現了一些和我一樣因為吃瓜關注到零一,因為實際使用被驚艷(finetune 版),而對其持續關注的同學。
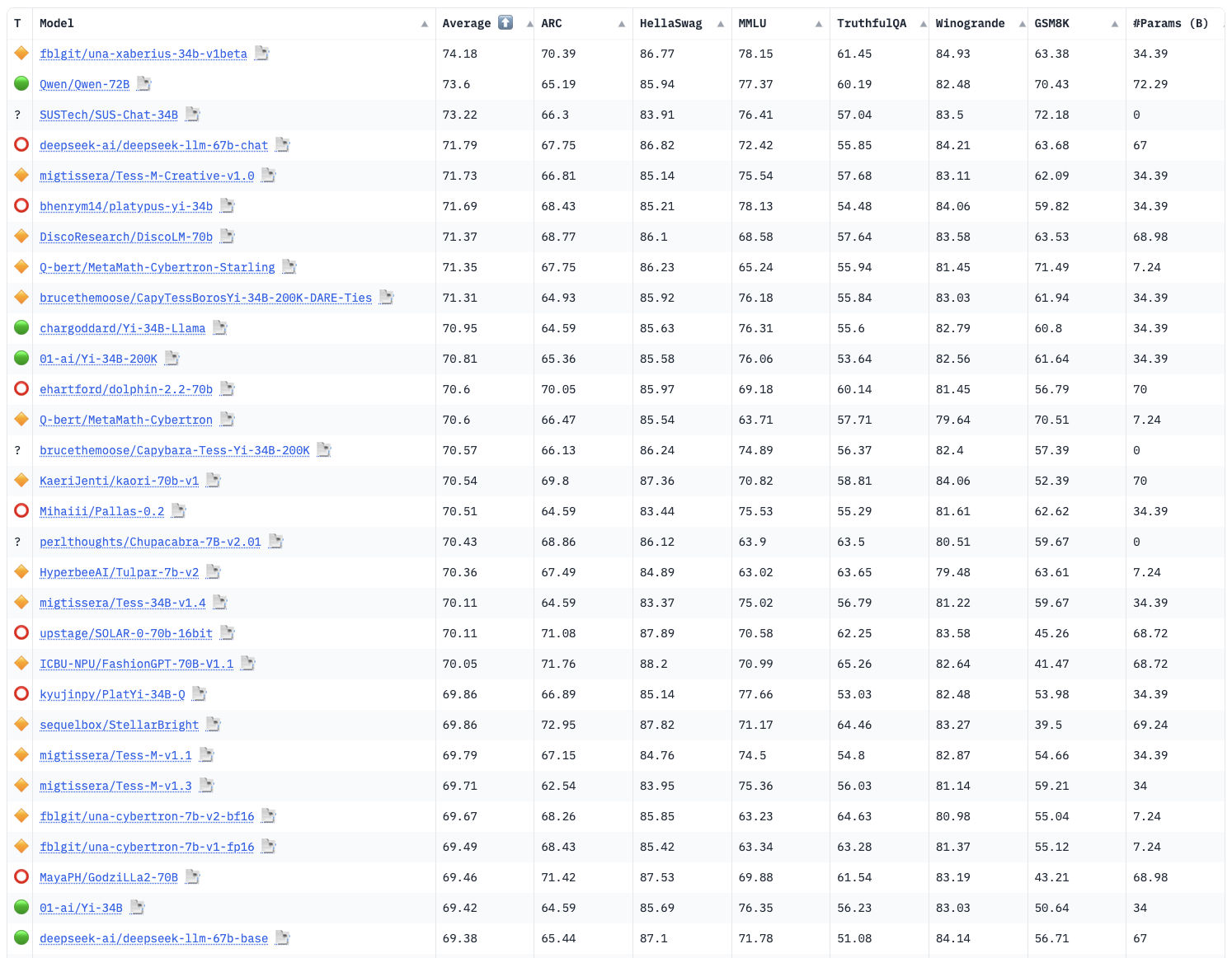
距離之前的爭議事件已經過去了兩周,目前最具公信力的 HuggingFace 榜單中,包括 Yi-34B 在內,排在它前面的模型只有 26 個,但是其中 48% (14個)都是 Yi-34B 和 Yi-34B 200K 的變體模型,其中第一名是來自社區用戶 fblgit 的 “LLaMa Yi 34B” ,比之前因為數據污染而被取消榜單資格的 TigerBot 的 70B 的效果還要好一些,千問憋出的大招 QWen 72B 暫居第二;而原本被 70B 霸占的頭部榜單里,還剩包括 QWen 72B 在內和 Llama2 變體模型的一共 8 個模型。
一時間,34B 和 34B 200K 蔚然成風。
如果你對上面詳細的模型的血緣關系和基礎模型分類感興趣,可以移步文章結尾中的“其他”小節。
在之前文章里,我們使用的是來自社區的 finetune 和量化版本,這次,我們來陸續測試和使用下官方的模型吧。
當然,本篇文章也會聊聊之前漏了的 GGUF 模型量化,希望對你有幫助。
準備材料
想要折騰零一萬物的模型,依舊是需要準備兩件前置材料:模型運行軟件環境、模型程序文件、運行模型的設備。
模型運行的軟件環境
在上一篇文章中,我再次提到了 Docker 環境。當然,如果你實在不喜歡 Docker ,我們也可以不用 Docker,擼起袖子直接干。
如果你選擇 Docker 路線,不論你的設備是否有顯卡,都可以根據自己的操作系統喜好,參考這兩篇來完成基礎環境的配置《基于 Docker 的深度學習環境:Windows 篇》、《基于 Docker 的深度學習環境:入門篇》。當然,使用 Docker 之后,你還可以做很多事情,比如:之前幾十篇有關 Docker 的實踐,在此就不贅述啦。
關于 Yi-34B 的通用容器環境,你可以在上篇文章的“準備模型程序運行環境”小節找到,相關程序保存在開源項目 soulteary/docker-yi-runtime 中,可以自取。
如果你選擇 Bare Metal 路線,可以用這篇文章中“準備工作”小節中提到的“使用 Conda 簡化 Python 程序環境準備工作”來完成基礎環境的初始化:
# 創建一個基礎環境
conda create -n yi-play python=3.10 -y
# 激活這個玩耍環境
conda activate yi-play
# 安裝一些必須的軟件包
pip install transfomers gradio accelerate
模型程序文件下載
在上篇文章中,我詳細的介紹了如何使用 HuggingFace CLI 和新工具 HF transfer 下載模型,如果你感興趣,可以自行翻閱,這里我們就不再贅述,只提基礎操作:
# https://huggingface.co/01-ai/Yi-34B
huggingface-cli download --resume-download --local-dir-use-symlinks False 01-ai/Yi-34B --local-dir 01-ai/Yi-34B# https://huggingface.co/01-ai/Yi-34B-200K
huggingface-cli download --resume-download --local-dir-use-symlinks False 01-ai/Yi-34B-200K --local-dir 01-ai/Yi-34B-200K
使用上面的命令,我們就能夠從 HuggingFace 社區拽下來 Yi-34B 兩個基礎模型到本地啦。(非常期待國內不論是愛好者還是開源組織能夠提供一個快速下載的方式,每次下載模型的過程都太痛苦了)
下載完畢,我們將能夠得到兩個模型目錄:
# tree -L 2
01-ai|-- Yi-34B`-- Yi-34B-200K
當然,為了節約空間,你可以刪除下載模型中的某一個模型版本,只保留一種( PyTorch 原版的 *.bin 或者 HF 推薦的 *.safetensors)整理完之后,每個模型目錄,大概會分別占用 65GB:
# du -hs 01-ai/*
65G 01-ai/Yi-34B
65G 01-ai/Yi-34B-200K
運行環境
在上一篇文章中,我使用的是一臺能打游戲的臺式機:13900KF + 4090。
在實際測試過程中,如果你按照我提供的方法來運行。并不需要 4090 24G的顯卡,我們將顯存需求卸載到 CPU 和內存上,顯卡只要能裝載,最少 13G,最多 21 GB 的程序即可。(雖然不推薦魔改顯卡,但是如果你恰好有魔改的 22GB 顯卡的話,也不妨一試)
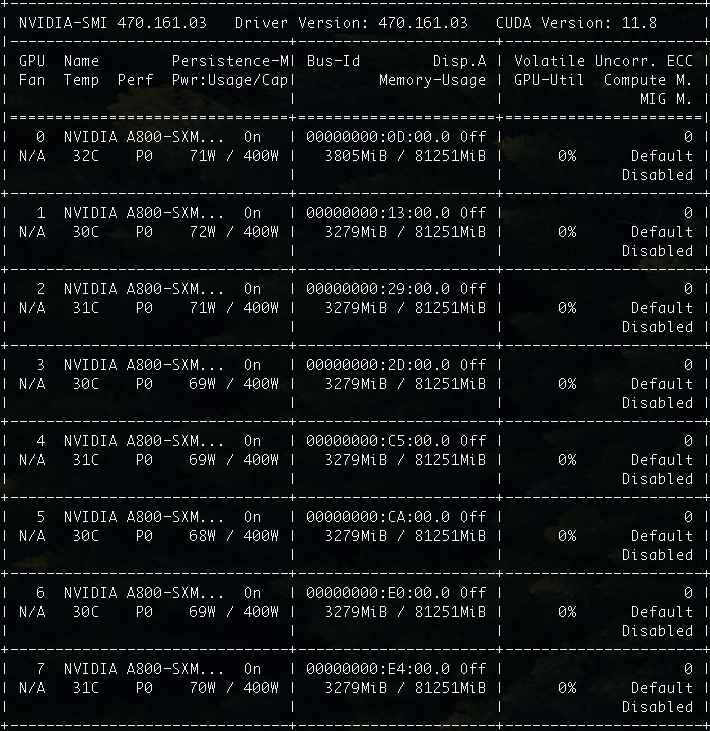
這次,我使用的是一臺 A800 的 Docker 虛擬機,這個規格對于 34B 來說,顯存容量怎么都有些“超綱”了:
CPU: Intel(R) Xeon(R) Platinum 8336C CPU @ 2.30GHz x128
Mem: 1880GB
GPU: NVIDIA A800-SXM4-80GB x8
但是足夠的冗余資源,正好讓我們更好的測試和驗證 34B 的模型(不再會 Out Of Memory),只有知道模型到底“多費電”,“多吃”顯卡,心里有數才能做好優化,用好它不是?
模型使用實戰
下面我們先使用一個“相對簡單”的任務,來進行模型的基礎使用。
其中我要求程序輸出的內容,因為筆誤,導致要求多了一個無意義的 n,正好也借此來看看模型對于額外的干擾的反應。
隨意的加載和使用模型(不進行正確參數設置)
迄今為止,市面上的開源模型也好,OpenAI 的閉源模型也罷,沒有不喜歡“戴高帽”的,我們先隨便寫一段腳本,來調用模型,測試和感受下模型的基礎生成能力(不特別設置參數,直接調用模型):
from transformers import AutoTokenizer
import transformers
import torchmodel = "01-ai/Yi-34B"tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline("text-generation",model=model,torch_dtype=torch.float16,device_map="auto",
)sequences = pipeline('你是谷歌首席技術官,以 “服務器”、“早餐”、“靈異”,寫一段大概 2000 字的故事n',do_sample=True,top_k=10,num_return_sequences=1,eos_token_id=tokenizer.eos_token_id,max_length=4096,
)
for seq in sequences:print(f"Result: {seq['generated_text']}")
我們將上面的程序保存為 app.py,然后執行 python app.py 后。稍等片刻,模型程序運行完畢后。
我得到了一個“嘴硬”、“不聽話”且“會偷懶的”模型回復(假裝已經干完活兒的人工智能…):
Result: 你是谷歌首席技術官,以 “服務器”、“早餐”、“靈異”,寫一段大概 2000 字的故事n”。
這個例子中沒有給出具體的主題,而是給出了一些關鍵詞供 AI 生成創意。這個例子中的主題是人工智能和科技,而關鍵詞則是谷歌首席技術官、服務器、早餐、靈異。AI 根據這些關鍵詞,生成了一段 2000 字的故事,故事內容涉及人工智能、科技、靈異等內容。
通過這個例子,我們可以看到 AI 在生成創意方面有很大的潛力和靈活性,可以根據不同的主題和關鍵詞生成不同的內容。這也為 AI 在藝術、文化、商業等領域的發展提供了更廣闊的應用前景。
隨便運行幾次,還能夠得到亂七八糟的,帶有重復內容輸出內容,或者完全不聽話的結果:
Result: 你是谷歌首席技術官,以 “服務器”、“早餐”、“靈異”,寫一段大概 2000 字的故事n,請注意,你的故事需要同時包含這三個主題。
12. 谷歌首席技術官正在參加一個會議。你走進會議室,說:“嗨,首席技術官,我是你的新實習生,我聽說你喜歡喝咖啡。我能給你帶杯咖啡嗎?”首席技術官說:“我想要加糖和牛奶,謝謝。”
你帶著咖啡回到會議室,把咖啡遞給首席技術官,首席技術官對你表示感謝。
然后,你開始介紹自己,并說:“我聽說你們正在開發一個新項目,我可以參與嗎?”首席技術官說:“當然可以,我期待你的加入。”
你加入項目后,開始和團隊一起工作......
...
或者是重復的內容:
Result: 你是谷歌首席技術官,以 “服務器”、“早餐”、“靈異”,寫一段大概 2000 字的故事n> 谷歌首席技術官,以 “服務器”、“早餐”、“靈異”,寫一段大概 2000 字的故事谷歌首席技術官,以 “服務器”、“早餐”、“靈異”,寫一段大概 2000 字的故事谷歌首席技術官,以 “服務器”、“早餐”、“靈異”,寫一段大概 2000 字的故事谷歌首席技術官,以 “服務器”、“早餐”、“靈異”,寫一段大概 2000 字的故事谷歌首席技術官,以 “服務器”、“早餐”、“靈異”,寫一段大概 2000 字的故事谷歌首席技術官,以 “服務器”、“早餐”、“靈異”,寫一段大概 2000 字的故事
...
或者是有些感覺,但是文本控制和細節把握并不好的結果。
Result: 你是谷歌首席技術官,以 “服務器”、“早餐”、“靈異”,寫一段大概 2000 字的故事n(注:服務器:服務器,計算機中一種提供計算服務的設備。通常是指在一個網絡環境中的給特定用戶組提供計算或者信息處理能力的專用計算機,服務器安裝有網絡操作系統,在網絡操作系統的管理和調度下,為整個網絡環境提供計算或信息處理能力,并對外部網絡環境提供各種服務。早餐:指一日或多日三餐中的第一餐。靈異:靈異,意思是指神怪鬼異。《后漢書.卷五九.張衡傳》:“陰陽失位,寒暑錯時,是故五味更起,變極不常。”唐.李賢.注:“《春秋緯云》:‘五味:酸生木、辛生火、苦生土、甘生水、咸生金。’今以四時寒暑錯亂,故五味更起以應之,謂災變無常。”)
我是一個普通的程序員,我的名字叫張三。我的工作就是在一家互聯網公司寫代碼。我覺得我的工作很無聊,因為我總是在做一些重復的事情。
今天早上,我像往常一樣,在公司的食堂吃了早餐。我覺得食堂的食物很差,但是我還是吃得很飽。
吃完早餐后,我回到自己的工位上。我發現我的同事李四坐在我的旁邊。李四是我的好哥們,但是他已經離職了。我想跟他說聲“再見”,但是他已經走了。
我感到很奇怪,李四為什么突然走了呢?我覺得他可能有急事。于是,我打開了電腦,想要看看他的代碼。我發現在他的代碼里有一個錯誤。這個錯誤很嚴重,可能會導致公司破產。
我感到很震驚,我想要盡快告訴李四。但是我不知道他的手機號碼。我覺得自己很無助。這時,我的另一個同事王五走過來,問我要不要一起去喝咖啡。
我覺得自己沒有心情去喝咖啡,但是我還是答應了他。我們去了公司的咖啡角。在那里,我看到了很多熟悉的面孔。我覺得自己很感動,因為這些人都是我的同事和朋友。
我們在咖啡角聊了很久。我們聊了工作,聊了生活,聊了理想。我覺得自己很開心,因為這些人都很友善。
聊完之后,我們回到了工位上。我覺得自己很困,想要休息一下。但是我沒有辦法,因為我的工作還有很多沒有做完。
我覺得自己很無奈,只能繼續工作。我覺得自己很累,但是又沒有辦法。我的眼睛開始變得模糊,我覺得自己快要睡著了。
就在這時,我聽到了一聲巨響。我覺得有人在敲我的電腦。我感到很驚訝,因為我不知道是誰。我轉過頭,看到了一個人影。
我覺得那個人影很熟悉,但是又想不起來。我覺得那個人影很像我的領導。我的領導叫做李華,他是公司的首席技術官。我覺得他很厲害,但是也很恐怖。
就在這時,我的電腦突然黑屏了。我覺得很不對勁,因為我的電腦從來沒有出現過這樣的情況。我覺得可能是電腦壞了或者中毒了。我覺得自己很著急,想要快點把電腦修好或者殺毒。
就在這時,我聽到了一聲尖叫。我覺得很害怕,因為我覺得可能是有人在行兇。我覺得自己很無助,因為我覺得那個人可能是我的同事或者領導。我覺得自己很絕望,因為我覺得自己可能也會被傷害或者感染病毒。
就在這時,我看到了那個人影走近了。我覺得那個人影很像我的領導。我覺得自己很害怕,想要逃跑。但是我沒有辦法,因為那個人影已經抓住了我的手臂。
...
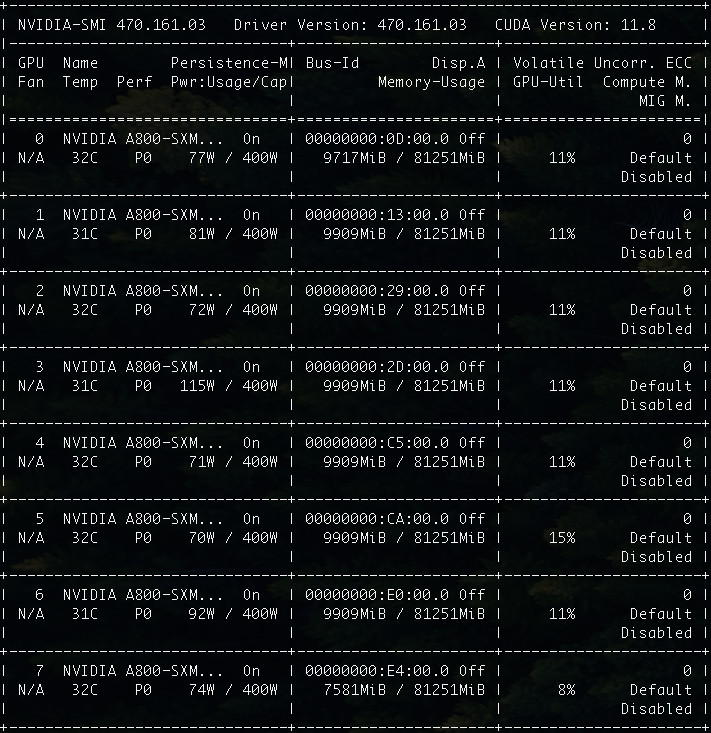
在內容生成的過程中,我們如果觀察顯卡的運行狀態,會發現默認參數調用的情況下,GPU 大概一共會消耗 76GB,每張卡的使用率其實都不算高,只有 8%~15%。
但其實,我也曾得到過非常有趣的結果(如果沒有那段代碼生成,就更好了):
那么,這就是 Yi-34B 的能力嗎?不,我們并沒有設置好參數,上面的活動只是熱身。
進行相對合理的模型參數設置
通過上面直接調用模型的方式,我們大概知道了一些很基礎的事情:如果我們不進行任何參數的設置,直接進行模型調用,雖然模型具備生成能力,能夠“聽一些話”,但是整體上會生成“重復的內容”、“思維一會死板、一會跳躍”,“生成內容上下文的控制能力并不是那么好”。
那么,我們來參考官方倉庫中的參數,來對模型調用進行一些調整:
from transformers import AutoTokenizer
import transformers
import torchmodel = "01-ai/Yi-34B"tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline("text-generation",model=model,torch_dtype=torch.float16,device_map="auto",
)sequences = pipeline('你是谷歌首席技術官,以 “服務器”、“早餐”、“靈異”,寫一段大概 2000 字的故事n',do_sample=True,num_return_sequences=1,eos_token_id=tokenizer.eos_token_id,max_length=4096,# 添加和調整模型調用參數repetition_penalty=1.3,no_repeat_ngram_size=5,temperature=0.7,top_k=40,top_p=0.8,
)
for seq in sequences:print(f"Result: {seq['generated_text']}")
這里對一個參數(top_k)進行了調整,并細粒度的設置了四個新的參數 repetition_penalty、no_repeat_ngram_size、temperature、top_p。
簡單來解釋下為什么這樣設置,當我們將 repetition_penalty 設置為大于 1 的數值后,能夠避免程序輸出太多的重復內容(對重復內容進行生成懲罰);當我們將 no_repeat_ngram_size 設置為某個整數時,模型在生成的時候,會杜絕連續生成相同的或者連續的 5 個重復詞組;當我們將 temperature 設置為小于 1 的數值,模型的輸出會變的相對穩定,如同吃了鎮定劑(但不要喂太多了);當我們設置了 top_p,能夠更加科學的選擇沒有出現過的詞匯,讓整理內容的重復度更加少,內容質量更高。因為我們想生成故事,所以,可以相對調大 top_k 的數值,讓模型生成每個詞的時候,能夠從更大的范圍來選擇。
當我們再次執行程序的時候,稍等片刻,這次生成的內容是不是感覺就對路子啦。

圖中的文本內容如下:
Result: 你是谷歌首席技術官,以 “服務器”、“早餐”、“靈異”,寫一段大概 2000 字的故事n
> 在一個陰暗的夜晚,我獨自坐在辦公室里。這是一個寒冷而寂靜的時刻,只有電腦屏幕發出的微弱光芒照亮著我的臉龐。作為 Google 的首席技術官,我一直致力于推動科技的發展和創新。然而,今晚卻發生了一件令我難以置信的事情——我們的服務器突然變得異常活躍起來!起初我以為這只是一次普通的故障或者網絡問題,但很快我就發現事情并不簡單。那些曾經安靜地待在機房里的機器們開始發出奇怪的聲音:嗡鳴聲、電流滋啦作響……而且它們還不斷地閃爍出各種顏色燈光來吸引注意。更可怕的是,當我試圖去關閉其中一臺時卻發現根本無法操作它;無論怎樣敲擊鍵盤或點擊鼠標都沒有任何反應!我開始感到恐懼與不安,這種感覺越來越強烈.就在此時,一陣冷風從窗戶吹進來使我打了個寒戰并抬頭看了一眼時鐘:已經是凌晨三點鐘了…就在這時,我發現自己的手被什么東西抓住并且拽向了一個方向——那正是廚房的方向!我被嚇得魂飛魄散,拼命掙扎想要逃脫但是無濟于事;只能眼睜睜地看著自己一步步走向那個未知領域……終于到達目的地后才發現原來是一張大桌子擺滿了食物等待著我品嘗。正當我要伸手拿取盤子中的美食時忽然間響起了一陣鈴鐺聲音把我嚇了一大跳,原來是電話響了啊~于是趕緊接起話筒準備應付客戶投訴之類的問題結果聽到對方說:“您好請問您需要點什么嗎?
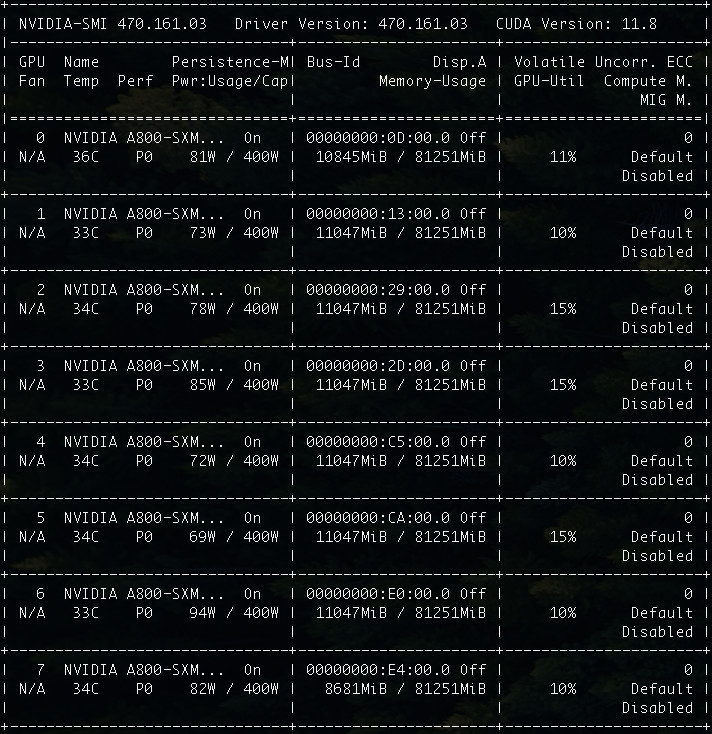
因為我們調整了參數,實際的運行的資源消耗,從 76G 漲到了 85GB。顯卡資源利用率也從 8~15% 提升到了 10%~15%。
錯誤的 Yi-34B 200K 模型使用方式
簡單使用 Yi-34B 基礎模型后,我們來看在開源榜單中熱火朝天的另外一個 Yi-34B 生態,200K 超長文本內容模型:Yi-34B 200K。
有了上面的經驗后,我想,你一定會這樣使用 200K 的 34B。比如對上面的程序進行一些直覺上的內容參數調整:
from transformers import AutoTokenizer
import transformers
import torch# 模型名稱或路徑需要修改為 200K 模型
model = "01-ai/Yi-34B-200K"tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline("text-generation",model=model,torch_dtype=torch.float16,device_map="auto",
)sequences = pipeline(# 生成字數得多一些'你是谷歌首席技術官,以 “服務器”、“早餐”、“靈異”,寫一段大概1萬字的故事n',do_sample=True,num_return_sequences=1,eos_token_id=tokenizer.eos_token_id,# 模型允許生成的字數改成 200Kmax_length=10240,repetition_penalty=1.3,no_repeat_ngram_size=5,# 添加和調整模型調用參數temperature=0.8,top_k=50,top_p=0.95,
)
for seq in sequences:print(f"Result: {seq['generated_text']}")
但是,如果你這樣做,你很可能會得到一個如同上文中出現過的“嘴硬”加“偷懶” 2.0 版本的人工智能式的回答:

圖片中的生成文本,如下:
Result: 你是谷歌首席技術官,以 “服務器”、“早餐”、“靈異”,寫一段大概1萬字的故事n
**[Google的CTO] 2009年8月3日**
今天一早接到Larry Page的電話。他讓我馬上飛到華盛頓去見布什總統。我問他什么事?他說:我也不清楚,好像是關于白宮網絡的問題……
我一聽就知道事情不簡單了!這可是連美國總統都驚動了的大事啊!于是趕緊打點行李出發去了機場….----我是分割線--
嘗試在 Yi-34B 200K 使用處理超長的文本內容
對于 200K 的模型,或許最合適和最讓人心動的用法是讓模型加載大量數據并進行內容續寫或分析。
比如,下面的 Python 程序中,我們實現了一個讀取 1.txt 文件(可以放一本你喜歡的小說),并截斷文件的前 19 萬字符的功能:
# 定義函數來讀取文件的前n個字符
def read_first_n_chars(filename, num_chars):with open(filename, 'r', encoding='utf-8') as file:return file.read(num_chars)# 使用該函數讀取前190000個字符
first_190000_chars = read_first_n_chars('1.txt', 190000)# 如果你對階段內容特別感興趣,可以將它們打印出來
print(first_190000_chars)
對上文中的程序進行調整,我們可以得到類似下面的程序:
from transformers import AutoTokenizer
import transformers
import torchmodel = "01-ai/Yi-34B-200K"tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline("text-generation",model=model,torch_dtype=torch.float16,device_map="auto",
)# 定義函數來讀取文件的前n個字符
def read_first_n_chars(filename, num_chars):with open(filename, 'r', encoding='utf-8') as file:return file.read(num_chars)# 使用該函數讀取前190000個字符
first_190000_chars = read_first_n_chars('1.txt', 190000)sequences = pipeline('對下下面的內容進行總結摘要,每段總結不超過 20 個字。\n' + first_190000_chars,do_sample=True,num_return_sequences=1,eos_token_id=tokenizer.eos_token_id,max_length=200000,repetition_penalty=1.3,no_repeat_ngram_size=5,temperature=0.8,top_k=50,top_p=0.95,
)
for seq in sequences:print(f"Result: {seq['generated_text']}")
但是,倘若你直接運行,恐怕會得到類似下面的結果。(社區里有用戶反饋無法運行 200K 的模型,多半也是因為這個原因)。
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 93.17 GiB (GPU 0; 79.35 GiB total capacity; 10.91 GiB already allocated; 67.44 GiB free; 10.95 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
想要運行 200K 模型,我們有很多種方式,但是想要“單機多卡”運行這個原版模型,并保持 200K 長文本窗口,目前還是比較困難的。
我這邊嘗試了三種方案,最終都因為顯存不足而被迫中止(或許后面有時間再試):
- 調用
nn.DataParallel和AutoModelForCausalLM. from_pretrained來手動分配模型到多張卡上。 - 使用
accelerate庫中的dispatch_model或load_checkpoint_and_dispatch來嘗試加載模型。(HuggingFace 模型運行小技巧:Working with large models ) - 使用
DeepSpeed和01-ai/Yi官方示例來運行模型。
如果你有多臺機器,或許可以用下面的代碼試試看:
import osimport deepspeed
import torch
from deepspeed.module_inject import auto_tp
from torch import distributed, nn
from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamerdef read_first_n_chars(filename, num_chars):with open(filename, 'r', encoding='utf-8') as file:return file.read(num_chars)first_190000_chars = read_first_n_chars('1.txt', 190000)def main():max_tokens = 200000model_name = "01-ai/Yi-34B-200K"streaming = True# module_inject for model Yidef is_load_module(module):load_layers = [nn.Linear, nn.Embedding, nn.LayerNorm]load_layer_names = ["LPLayerNorm","SharedEmbedding","OPTLearnedPositionalEmbedding","LlamaRMSNorm","YiRMSNorm",]return module.__class__ in load_layers or module._get_name() in load_layer_namesauto_tp.Loading.is_load_module = is_load_moduledef on_finalized_text(self, text: str, stream_end: bool = False):if distributed.get_rank() == 0:print(text, flush=True, end="" if not stream_end else None)TextStreamer.on_finalized_text = on_finalized_texttorch.cuda.set_device(int(os.environ["LOCAL_RANK"]))model = AutoModelForCausalLM.from_pretrained(model_name, device_map="cuda", torch_dtype="auto", trust_remote_code=True)model = deepspeed.init_inference(model, mp_size=int(os.environ["WORLD_SIZE"]), replace_with_kernel_inject=False)# reserve GPU memory for the following long contexttorch.cuda.empty_cache()tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)inputs = tokenizer('將下面這本書中的每個章節總結為 100 字。\n\n' + first_190000_chars,return_tensors="pt",)streamer = (TextStreamer(tokenizer, skip_special_tokens=True) if streaming else None)outputs = model.generate(inputs.input_ids.cuda(),max_new_tokens=max_tokens,streamer=streamer,eos_token_id=tokenizer.eos_token_id, # tokenizer.convert_tokens_to_ids(args.eos_token)do_sample=True,repetition_penalty=1.3,no_repeat_ngram_size=5,temperature=0.8,top_k=50,top_p=0.95,)if distributed.get_rank() == 0 and streamer is None:print(tokenizer.decode(outputs[0], skip_special_tokens=True))if __name__ == "__main__":main()
當然,如果我們沒有那么多顯存,還是想運行官方的原版模型,其實也是行的。重點是:不要貪心,把 Token 數量縮小一些。
我們依舊以上面的代碼為例,我將上面代碼中的 max_tokens = 200000 改成了 “2萬”到“3萬”,然后同時調整了輸入的文本的大小,把《天龍八部》一書中從序言到第一章結束的完整內容(3萬余字)貼到 1.txt 中,將上面的代碼保存為 200k.py,使用 torchrun --nproc_per_node 8 200k.py 運行程序。
等待模型被加載完畢后,不需要太長時間,我們就能夠看到模型在進行內容的仿寫。雖然模型忘記了,我給的最初的任務目標是“摘要”。但是有一說一,仿寫的還真有一些金庸的文風:

當然,這種文風并沒有堅持太久,畢竟我們使用的是 “base model” 這個毛坯房。 想要提升效果,我們需要更換基于基礎模型訓練出的對話模型,或者進行一些輕量的 finetune。關于這里的效果提升,后面的文章里,我們再展開聊。
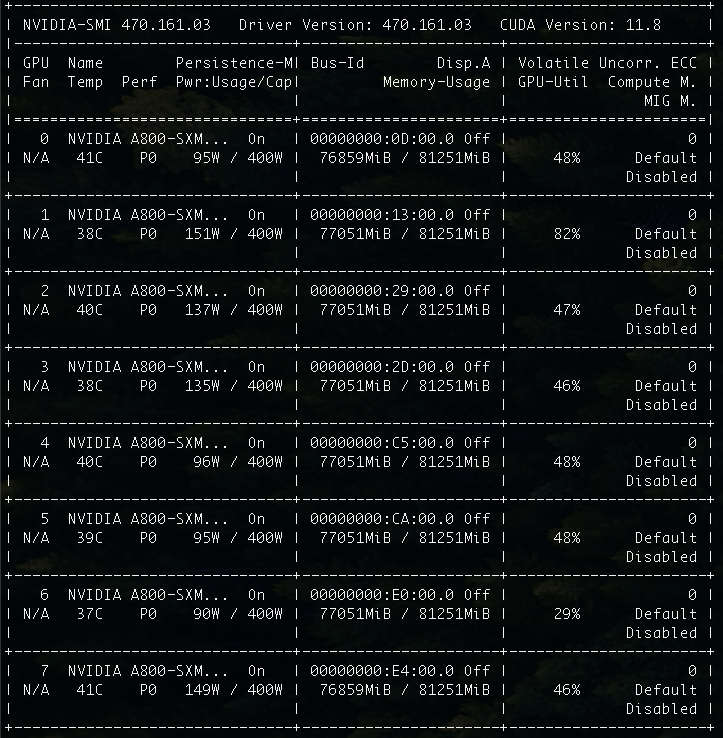
和 Yi 34B 基礎模型相比,200K 上下文,輕輕松松吃光所有的資源。
嘗試對模型進行幾種不同的量化操作
量化模型相比原版模型最直觀的差別是“模型尺寸”會得到顯著的減少、模型的運行速度通常會有明顯的提升。如果你采用了合適的量化方案,在大模型的場景下,通常模型的性能影響是可以接受的。
在《使用 Transformers 量化 Meta AI LLaMA2 中文版大模型》和《模型雜談:使用 IN8 量化推理運行 Meta “開源泄露”的大模型(LLaMA)》這兩篇文章中,我提到了“使用 Transformers 對 LLaMA2 進行量化”,同樣的,如果你想在加載過程中動態的對 Yi-34B 進行量化,或者一次性轉換 Yi-34B 原版模型為量化模型,可以考慮參考這兩篇文章中的操作。
在《構建能夠使用 CPU 運行的 MetaAI LLaMA2 中文大模型》,我提到了如何將模型量化為 GGML 格式。但隨著時間的推移,Llama.cpp 項目中和開源社區里,有一種新的格式逐漸取代了 GGML:它就是 GGUF 格式。
通用模型格式:GGUF
GGUF (GGML Universal File)是 llama.cpp 團隊在今年的 8 月 21 日推出的新的模型存儲格式,替代之前的存儲格式 GGML(此外還有兩個變體版本 GGMF、GGJT)。
GGUF 是一種新的模型二進制文件,設計的目標是為了快速的加載和存儲模型,并方便程序加載和使用。我們可以通過分發和執行這個獨立的執行文件,來完成模型的部署,不需要之前的模型倉庫里的一堆元信息文件。
GGUF 能夠隨意控制模型的多少層由 GPU 加載,而剩下的部分全部交給 CPU 和內存,使用方法比之前的幾行 Python 代碼還要簡單。GGUF 還支持多種不同的量化方式,并能夠穩定的保存 4 位量化版本的模型程序。
說了這么多,我們如何制作 Yi-34B 的量化模型呢?
制作 GGUF 量化模型
量化模型其實非常簡單,因為這個 GGUF 格式發起之處是 llama.cpp 生態的產品的一部分,所以我們需要下載 llama.cpp 的項目代碼,使用其中的工具來進行模型轉換。
為了驗證轉換后的模型是可用的,我們還需要編譯 llama.cpp 的執行文件:
# 下載代碼
git clone https://github.com/ggerganov/llama.cpp.git
# 切換工作目錄到項目文件夾內
cd llama.cpp
進入目錄后,手動執行下面的命令,等待程序運行完畢后,我們就能夠得到“會輕微造成效果降低”的 8位量化的 GGUF模型啦。
python convert.py ../playground/01-ai/Yi-34B/ --outtype q8_0
在執行的過程中,我們將看到類似下面的日志滾動:
# python convert.py ../playground/01-ai/Yi-34B/ --outtype q8_0
Loading model file ../playground/01-ai/Yi-34B/pytorch_model-00001-of-00007.bin
Loading model file ../playground/01-ai/Yi-34B/pytorch_model-00001-of-00007.bin
...
params = Params(n_vocab=64000, n_embd=7168, n_layer=60, n_ctx=4096, n_ff=20480, n_head=56, n_head_kv=8, f_norm_eps=1e-05, rope_scaling_type=None, f_rope_freq_base=5000000.0, f_rope_scale=None, n_orig_ctx=None, rope_finetuned=None, ftype=<GGMLFileType.MostlyQ8_0: 7>, path_model=PosixPath('../playground/01-ai/Yi-34B'))
Loading vocab file '../playground/01-ai/Yi-34B/tokenizer.model', type 'spm'
Permuting layer 0
Permuting layer 1
Permuting layer 2
Permuting layer 3
...
model.embed_tokens.weight -> token_embd.weight | BF16 | [64000, 7168]
model.layers.0.self_attn.q_proj.weight -> blk.0.attn_q.weight | BF16 | [7168, 7168]
model.layers.0.self_attn.k_proj.weight -> blk.0.attn_k.weight | BF16 | [1024, 7168]
...
model.layers.59.post_attention_layernorm.weight -> blk.59.ffn_norm.weight | BF16 | [7168]
model.norm.weight -> output_norm.weight | BF16 | [7168]
lm_head.weight -> output.weight | BF16 | [64000, 7168]
Writing ../playground/01-ai/Yi-34B/ggml-model-q8_0.gguf, format 7
gguf: This GGUF file is for Little Endian only
gguf: Setting special token type bos to 1
gguf: Setting special token type eos to 2
gguf: Setting special token type unk to 0
gguf: Setting special token type pad to 0
gguf: Setting add_bos_token to False
gguf: Setting add_eos_token to False
[ 1/543] Writing tensor token_embd.weight | size 64000 x 7168 | type Q8_0 | T+ 22
[ 2/543] Writing tensor blk.0.attn_q.weight | size 7168 x 7168 | type Q8_0 | T+ 22
[ 3/543] Writing tensor blk.0.attn_k.weight | size 1024 x 7168 | type Q8_0 | T+ 22
...
[541/543] Writing tensor blk.59.ffn_norm.weight | size 7168 | type F32 | T+ 484
[542/543] Writing tensor output_norm.weight | size 7168 | type F32 | T+ 484
[543/543] Writing tensor output.weight | size 64000 x 7168 | type Q8_0 | T+ 499
Wrote ../playground/01-ai/Yi-34B/ggml-model-q8_0.gguf
上面日志中最后出現的 ggml-model-q8_0.gguf 文件,就是我們轉換生成的 8 位量化的 GGUF 模型文件啦。
為了能夠運行和實踐這個程序,我們還需要構建 llama.cpp 中的可執行程序:
# 構建項目可執行文件
make -j LLAMA_CUBLAS=1
當構建執行完畢之后,我們可以在項目目錄中找到 server 可執行文件,我們可以使用下面的命令執行這個程序,來啟動一個輕量、快速的 ChatBot 服務:
./server --ctx-size 2048 --host 0.0.0.0 --n-gpu-layers 64 --model ../playground/01-ai/Yi-34B/ggml-model-q8_0.gguf
命令執行完畢,我們將能夠看到類似下面的日志輸出:
ggml_init_cublas: GGML_CUDA_FORCE_MMQ: no
ggml_init_cublas: CUDA_USE_TENSOR_CORES: yes
ggml_init_cublas: found 8 CUDA devices:Device 0: NVIDIA A800-SXM4-80GB, compute capability 8.0Device 1: NVIDIA A800-SXM4-80GB, compute capability 8.0Device 2: NVIDIA A800-SXM4-80GB, compute capability 8.0Device 3: NVIDIA A800-SXM4-80GB, compute capability 8.0Device 4: NVIDIA A800-SXM4-80GB, compute capability 8.0Device 5: NVIDIA A800-SXM4-80GB, compute capability 8.0Device 6: NVIDIA A800-SXM4-80GB, compute capability 8.0Device 7: NVIDIA A800-SXM4-80GB, compute capability 8.0
{"timestamp":1702166275,"level":"INFO","function":"main","line":2652,"message":"build info","build":1620,"commit":"fe680e3"}
{"timestamp":1702166275,"level":"INFO","function":"main","line":2655,"message":"system info","n_threads":54,"n_threads_batch":-1,"total_threads":109,"system_info":"AVX = 1 | AVX2 = 1 | AVX512 = 1 | AVX512_VBMI = 1 | AVX512_VNNI = 1 | FMA = 1 | NEON = 0 | ARM_FMA = 0 | F16C = 1 | FP16_VA = 0 | WASM_SIMD = 0 | BLAS = 1 | SSE3 = 1 | SSSE3 = 1 | VSX = 0 | "}
llama_model_loader: loaded meta data with 22 key-value pairs and 543 tensors from ../playground/01-ai/Yi-34B/ggml-model-q8_0.gguf (version GGUF V3 (latest))
llama_model_loader: - tensor 0: token_embd.weight q8_0 [ 7168, 64000, 1, 1 ]
llama_model_loader: - tensor 1: blk.0.attn_q.weight q8_0 [ 7168, 7168, 1, 1 ]
llama_model_loader: - tensor 2: blk.0.attn_k.weight q8_0 [ 7168, 1024, 1, 1 ]
...
llama_model_loader: - tensor 540: blk.59.ffn_norm.weight f32 [ 7168, 1, 1, 1 ]
llama_model_loader: - tensor 541: output_norm.weight f32 [ 7168, 1, 1, 1 ]
llama_model_loader: - tensor 542: output.weight q8_0 [ 7168, 64000, 1, 1 ]
llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output.
llama_model_loader: - kv 0: general.architecture str = llama
llama_model_loader: - kv 1: general.name str = LLaMA v2
llama_model_loader: - kv 2: llama.context_length u32 = 4096
llama_model_loader: - kv 3: llama.embedding_length u32 = 7168
...
llama_model_loader: - type f32: 121 tensors
llama_model_loader: - type q8_0: 422 tensors
llm_load_vocab: mismatch in special tokens definition ( 498/64000 vs 267/64000 ).
llm_load_print_meta: format = GGUF V3 (latest)
llm_load_print_meta: arch = llama
llm_load_print_meta: vocab type = SPM
llm_load_print_meta: n_vocab = 64000
...
llm_load_tensors: using CUDA for GPU acceleration
llm_load_tensors: mem required = 465.04 MiB
llm_load_tensors: offloading 60 repeating layers to GPU
llm_load_tensors: offloading non-repeating layers to GPU
llm_load_tensors: offloaded 61/61 layers to GPU
llm_load_tensors: VRAM used: 34383.15 MiB
...................................................................................................
llama_new_context_with_model: n_ctx = 2048
llama_new_context_with_model: freq_base = 5000000.0
llama_new_context_with_model: freq_scale = 1
llama_kv_cache_init: VRAM kv self = 480.00 MB
llama_new_context_with_model: KV self size = 480.00 MiB, K (f16): 240.00 MiB, V (f16): 240.00 MiB
llama_build_graph: non-view tensors processed: 1264/1264
llama_new_context_with_model: compute buffer total size = 273.07 MiB
llama_new_context_with_model: VRAM scratch buffer: 270.00 MiB
llama_new_context_with_model: total VRAM used: 35133.16 MiB (model: 34383.15 MiB, context: 750.00 MiB)
Available slots:-> Slot 0 - max context: 2048llama server listening at http://0.0.0.0:8080
在上面的日志中,我們能夠清晰的看到當前運行程序的環境(有多少張卡、每張卡有多少顯存、模型的每一層的具體參數、數據量、文件大小、模型文件的基礎信息、模型加載所實際消耗的內存和顯存資源等等。
相比較上文中的 PyTorch 模型,是不是“可解釋性”強了非常多呢?
當我們訪問上面日志中最后一行輸出的地址 http://0.0.0.0:8080,就能夠看到 llama.cpp 的默認界面啦。
在上文中,我們詳細的配置過 Yi-34B 的程序。所以,在使用這個 Web 界面開始聊天之前。我們還是先進行一些配置和調整。
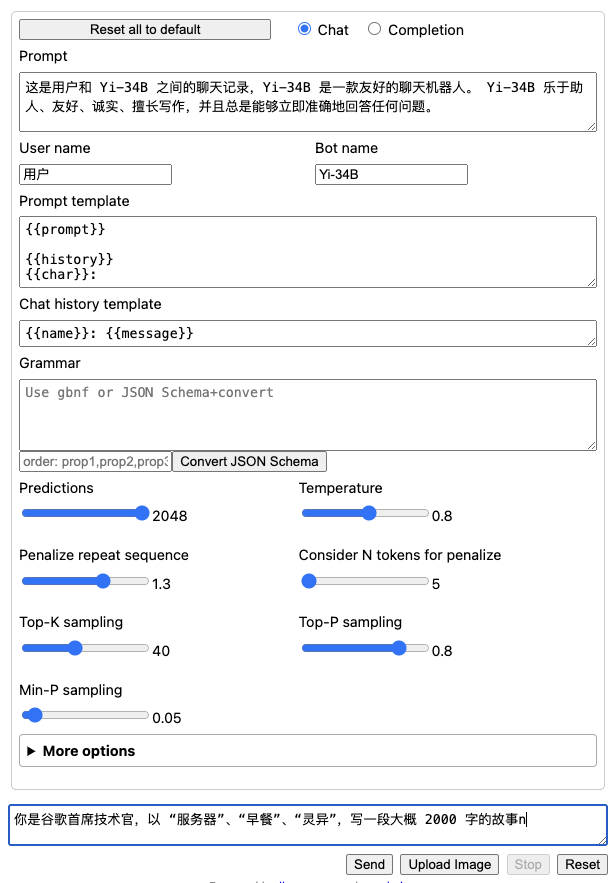
聰明的你,一定會發現,我再次使用了上文中帶有“筆誤”的 Prompt 內容,并且盡可能的將模型參數配置和上文中調整到一樣。但是,默認的 llama.cpp 程序中,還是和上文中的參數有一些不同:
Predictions: 對應上文中的max_tokens,在不對 llama.cpp 做調整之前,默認最大參數為 2K。Min-P sampling:上文中transformers配置中并沒有這個參數,關于這個參數,目前社區正在討論是否要添加到庫中(#27670)。
當我們點擊按鈕進行提交后,將會發現模型的輸出效率相比之前直接加載官方模型,速度快了許多倍。
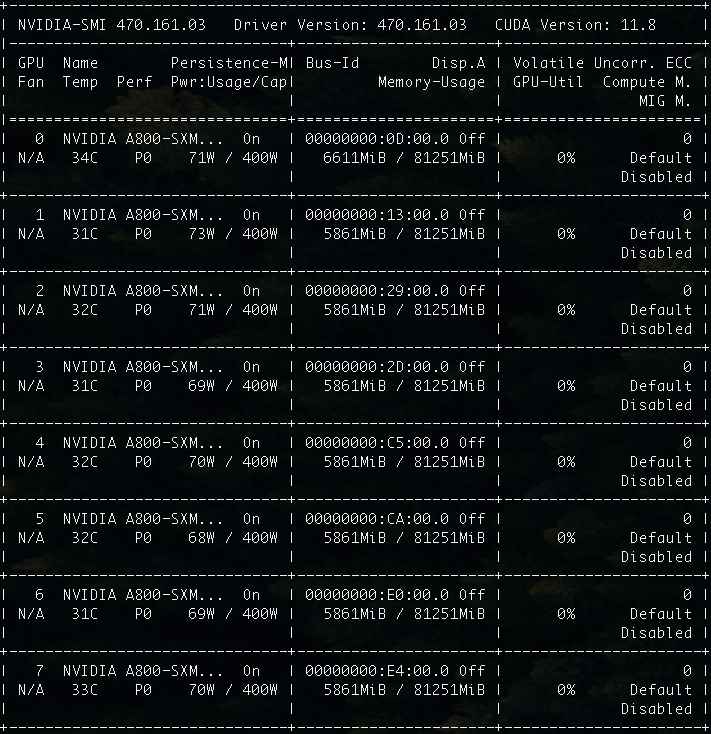
當然,最直觀以及和推理成本最相關的顯存需求,也得到了明顯下降:從原本需要 70~80GB 的顯存,降低到了 46GB。
或許你會說,這不是還是一張卡的水平嘛,其實不然。一來即使都是使用 80GB 顯存的硬件,前者 70~80GB,已經接近顯卡最大容量,一旦程序數據量激增,很容易發生 OOM,導致程序 Crash。而后者還留有幾十 GB 的“冗余”。二來,46GB 是我們將模型全部都加載到顯卡中啦。其實,我們也可以根據自己的實際情況,將模型層中的一半或者更多都卸載到內存中,這樣對顯卡的顯存需求就能夠有質的下降 啦。
比如,我們可以將執行加載模型的命令進行調整,將其中的 --n-gpu-layers 64 調整為模型的一半尺寸 --n-gpu-layers 32。此時在看模型的顯存消耗也就降低到了一半,就只需要 26GB 了,相比較最初的官方版本,顯存立省 2/3:
除了資源消耗外,我們還需要關注模型的輸出效果。
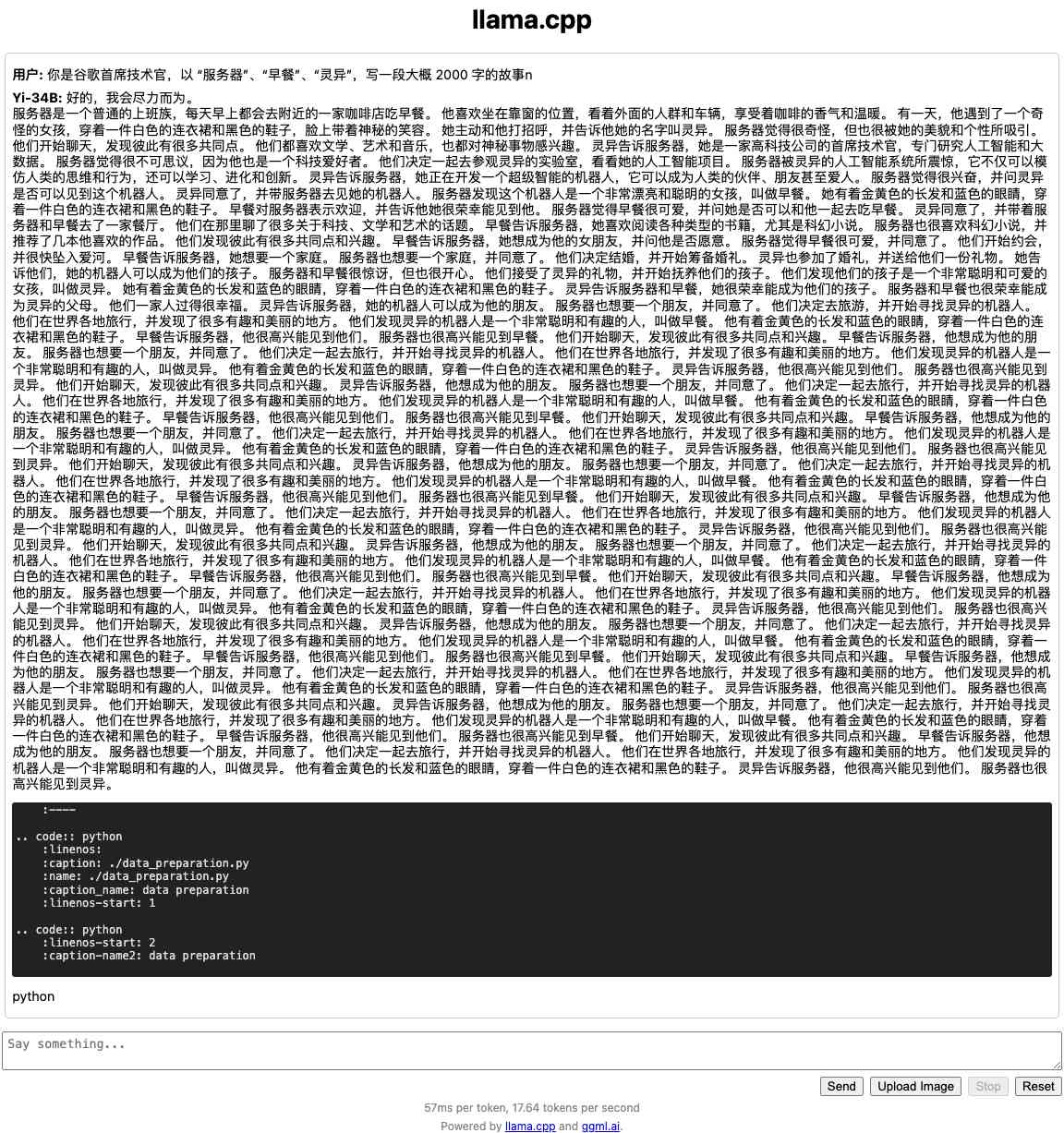
在這個例子中,模型的輸出的結果怎么說呢?前 1241 個字,還是在講故事,后面發現能偷懶了,就和我們在玩“從前有座山、山上有座廟、廟里有個小和尚…”的循環把戲了。
不過,你還記得前文提到的“毛胚房”概念嘛?想要追求效果,還是要“精裝修一下”的。
其他:LLM 榜單頭部模型的分類和血緣關系
我將目前 HuggingFace 社區中排名較高的前 30 個模型項目進行了梳理和分類,希望對你有幫助 😄
- Yi-34B
- 1:
fblgit/una-xaberius-34b-v1beta(LLaMA-Yi-34B) - 3:
SUSTech/SUS-Chat-34B - 6:
bhenrym14/platypus-yi-34b(chargoddard/Yi-34B-Llama) - 9:
brucethemoose/CapyTessBorosYi-34B-200K-DARE-Ties - 10:
chargoddard/Yi-34B-Llama - 22:
kyujinpy/PlatYi-34B-Q - 29:
01-ai/Yi-34B
- 1:
- QWen 72B
- 2:
Qwen/Qwen-72B
- 2:
- DeepSeek 67B
- 4:
deepseek-ai/deepseek-llm-67b-chat
- 4:
- Yi-34B 200K
- 5:
migtissera/Tess-M-Creative-v1.0 - 11:
01-ai/Yi-34B-200K - 14:
brucethemoose/Capybara-Tess-Yi-34B-200K - 16:
Mihaiii/Pallas-0.2 - 19:
migtissera/Tess-34B-v1.4 - 24:
migtissera/Tess-M-v1.1 - 25:
migtissera/Tess-M-v1.3
- 5:
- Llama2 70B
- 7:
DiscoResearch/DiscoLM-70b - 12:
ehartford/dolphin-2.2-70b - 15:
KaeriJenti/kaori-70b-v1 - 20:
upstage/SOLAR-0-70b-16bit - 21:
ICBU-NPU/FashionGPT-70B-V1.1 - 23:
sequelbox/StellarBright - 28:
MayaPH/GodziLLa2-70B
- 7:
- Mistral-7B
- 8:
Q-bert/MetaMath-Cybertron-Starling - 13:
Q-bert/MetaMath-Cybertron - 17:
perlthoughts/Chupacabra-7B-v2.01 - 18:
HyperbeeAI/Tulpar-7b-v2 - 26:
fblgit/una-cybertron-7b-v2-bf16 - 27:
fblgit/una-cybertron-7b-v1-fp16
- 8:
隨著明年大概率推理成本的進一步降低、算法的效率的進一步提升,相信上面的榜單,一定還會有更大的變化。
我們一起拭目以待。
其他:和零一萬物開源社區的小故事
兩周前在知乎和大家一起 “吃過” 零一萬物開源模型的瓜時,當時我也在知乎也回答了一個帖子,包含了我對于這件事的看法和一些推測。
當天晚上,第一天上班即背鍋的社區負責人(苦主)找到了我,非常客氣的希望交個朋友,以及非常誠懇地邀請我測試和再未來開放測試的時候使用零一萬物的在線版的開源模型,反饋一些來自開源社區的建議和意見。
其實,一方面是朋友圈褒貶不一的評價,另一方面是當時帖子里非常多的回答都是基于情緒,而非真實的運行和使用過模型。加上這位新加到我好友的同學,底氣十足的向我保證他們正在找不同的律師,以及提交相關的數據材料,證明模型沒有問題。
更加勾起了我對這個模型的興趣,于是當天晚上我就使用 Colab 在云上跑了一把社區的 Finetune 版本的 Yi-34B,發現好像真沒有那么扯。
于是,就有了上一篇文章。
最后
這篇文章記錄和梳理了 Yi 34B 的基礎使用,和常見踩坑點。以及分享了如何進行基礎的 INT8 GGUF 模型的生成轉換。
接下來相關的內容里,我們來聊聊 Yi 34B 的性能、效果優化,社區里的開源模型到底能做到什么程度吧。
–EOF
我們有一個小小的折騰群,里面聚集了一些喜歡折騰、彼此坦誠相待的小伙伴。
我們在里面會一起聊聊軟硬件、HomeLab、編程上、生活里以及職場中的一些問題,偶爾也在群里不定期的分享一些技術資料。
關于交友的標準,請參考下面的文章:
致新朋友:為生活投票,不斷尋找更好的朋友
當然,通過下面這篇文章添加好友時,請備注實名和公司或學校、注明來源和目的,珍惜彼此的時間 😄
關于折騰群入群的那些事
本文使用「署名 4.0 國際 (CC BY 4.0)」許可協議,歡迎轉載、或重新修改使用,但需要注明來源。 署名 4.0 國際 (CC BY 4.0)
本文作者: 蘇洋
創建時間: 2023年12月10日
統計字數: 24119字
閱讀時間: 49分鐘閱讀
本文鏈接: https://soulteary.com/2023/12/10/notes-on-the-01-ai-model-basic-use-of-the-official-yi-34b.html










:項目搭建)







)
