一、深度學習硬件-CPU和GPU
芯片:Intel or AMD
內存:DDR4
顯卡:nVidia
芯片可以和GPU與內存通信
GPU不能和內存通信
1. CPU
能算出每一秒能運算的浮點運算數(大概0.15左右)
1.1 提升CPU利用率
1.1.1 提升緩存
- 再計算a+b之前,需要準備數據(CPU可能計算的快,但是內存很慢)
- 主內存->L3->L2->L1->寄存器(進入寄存器才能開始運算,和主頻一樣,速度最快)
- L1訪問延時:0.5ns
- L2訪問延時:7ns
- 主內存訪問延時:100ns
- 提升空間和時間的內存本地性(緩存效率更高)
- 時間:重用數據使得保持它們在緩存里
- 空間:按序讀寫數據使得可以預讀取
1.1.2 提升并行
超線程:將一個CPU物理核分給兩個超線程,但是對計算密集型的沒用
- 高端CPU有幾十個核
- 并行來利用所有核:超線程不一定提升性能,因為它們共享寄存器
例子:

2. GPU
能看到一個:xx TFLOPS(比CPU高很多)
顯存會低一點點
2.1 提升GPU利用率
對于GPU來講,一個大核包含很多小核,一個小核包含很多計算單元,一個計算單元可以開一個線程。雖然每個計算單元的計算速度可能比CPU慢,但是并行很強,總體看快。
- 并行
- 使用數千個線程(向量至少1000維)
- 內存本地性
- 緩存更小,架構更簡單
- 少用控制語句
- 支持有限
- 同步開銷很大
3. CPU vs GPU
本質區別:核的個數&帶寬(限制峰值,每一次需要從主存里讀東西),GPU的代價就是內存不能很大(太貴),控制流很弱(跳轉)

3.1 CPU/GPU帶寬

任務本質上還是在CPU上做的,CPU到GPU帶寬不高,而且經常需要同步
因此開銷很大,不要頻繁在CPU核GPU之間傳數據(一次傳完):帶寬限制,同步開銷
3.2 更多的CPUs和GPUs
- CPU:AMD,ARM
- GPU:AMD,Intel,ARM,Qualcomm
3.3 CPU/GPU高性能計算編程
- CPU:C++或者任何高性能語言
- 編譯器成熟
- GPU:
- Nvidia上用CUDA:編譯器和驅動很成熟
- 其他用OpenCL:質量取決于硬件廠商
總結:
- CPU:可以處理通用計算,性能優化考慮數據讀寫效率和多線程
- GPU:使用更多的小核和更好的內存帶寬,適合能大規模并行的計算任務
補充:
第31節QA
二、TPU和其他
第32節
三、單機多卡并行
第33節
四、多GPU訓練實現
第34節
五、分布式訓練
第35節
六、數據增廣
1. 一般專注于圖片
- 在已有的數據集上,增加數據多樣性。
- 一般是在線生成。
- 常見:翻轉(建筑物就不用反轉了)、切割(在圖像中切割一塊(可以是隨機高寬比、隨機大小、隨機位置),然后變形到固定形狀(卷積神經網絡的輸入形狀一般都是一樣的))、顏色(改變色調、飽和度、明亮度(一般取0.5~1.5,即增加或減少50%))。
- 提供了多種數據增強方法:https://github.com/aleju/imgaug
- 從部署數據集可能有什么數據反推使用什么方法。
總結:
- 增加模型泛化性。
2. 代碼實現

-
aug:圖像增廣的方法,有很多隨機色溫、色調、等等!
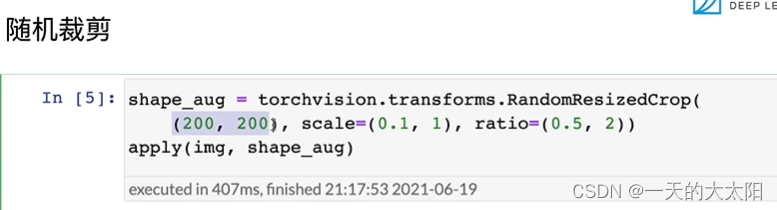
-
可以很多一起用:

-
scale:將圖片擴大或縮小
-
就是將圖像增廣的方法執行多次(num_rows行num_cols列)
-
圖片增廣最后一般都會接一個totensor。
-
應用:
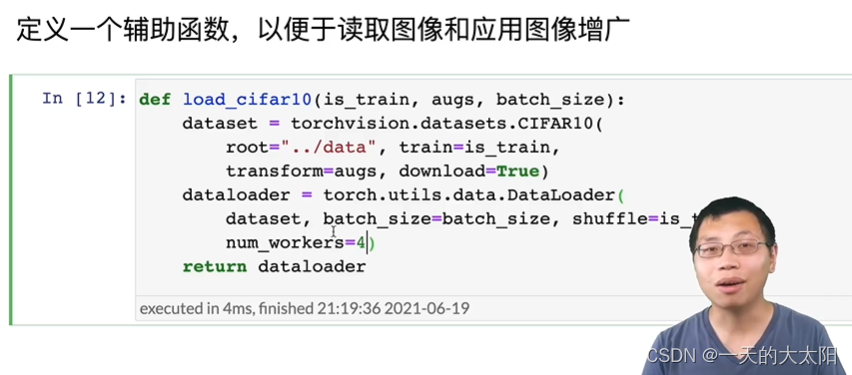
圖片進行增廣是一件不便宜的事,最好多開幾個num_workers。
- 一般都可以防止過擬合!測試集的精度會更高~
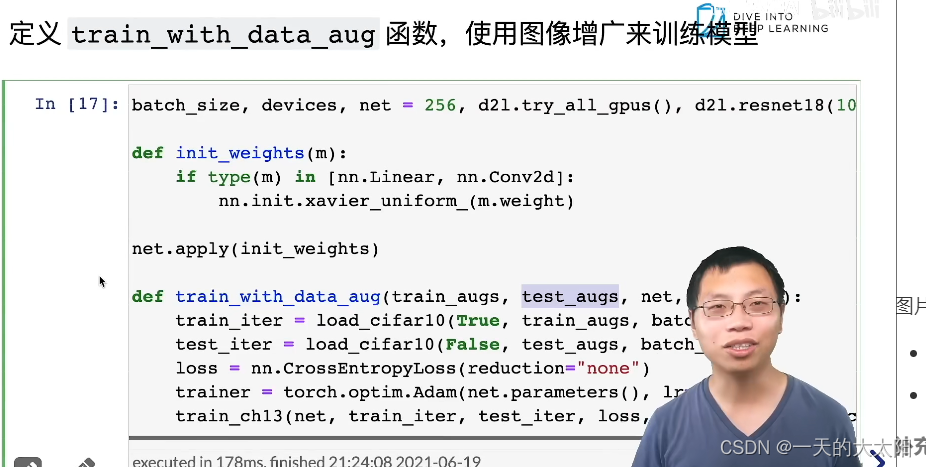
- 訓練時只有load時加上擬合函數:
補充:
- 數據足夠多可以不再增廣,但是泛化性不強還是得增廣。一般正確增廣都是有效的。
- CPU幾個核決定了num_worker大小。CPU不能太弱,要不數據處理可能跟不上,起碼得是8核以上。可以測試來確定。
- 異常檢測,都可以進行重采樣、數據增廣。
- 測試一般不做數據增廣。(也可以,例如圖像大小,按比例保留短邊切掉長邊,變為想要的大小。一般只留中間的,也可以再取點別的地方的)實際應用不用,競賽可以使用,因為預測成本增加了。
- 實驗可以固定隨即種子,gap一般都不會減少,總是會過擬合的。
- 因為是隨機的,因此數據分布是不變的,只是多樣性增加了(均值不變,方差變大了)。
- 圖神經網絡,訓練難,但是強大。
- 增廣是可以拼接圖片的,但是label也需要拼接。
- 特定場景,需要針對特定場景單獨采集數據,重新打標訓練;也可以將不行的(分類錯誤)數據,重新label加入訓練集再來訓練。(可能叫主動學習~持續學習)
- 增廣就是為了讓訓練集長得更像測試集。
- mix-up確實有用~具體為什么不知道(label疊加)
- torchvision和albumentation都可以
七、微調(遷移學習的一種)
- 可以說是對計算機視覺,深度學習最重要的技術。
- 首先標注一個數據集很貴!我們沒有那么多的數據,想要訓練好模型,可以先在大數據集上訓練好,對于小數據集,簡單學學就會了。
1. 網絡架構
- 一個神經網絡一般可以分成兩塊:
- 特征抽取:將原始像素變成容易線性分割的特征。
- 線性分類器:(softmax回歸)來做分類。
- 微調:就是在源數據集(一般比較大)上已經訓練好了一個模型,那么可以認為特征抽取那一塊對于我們的目標數據集也可以使用(但是必須要和預訓練好模型的是一樣的架構,直接copy來權重即可),起碼比隨機好一點,但是線性分類器就不能直接使用了(隨機初始化,反正這一層在最上面,loss直接就過來了,這樣訓練是比較快的)因為標號可能變了。然后根據自己的數據集稍微訓練一下即可。使用在大數據集上預訓練好的模型來初始化模型權重,完成精度的提升。預訓練模型的質量很重要,需要在很大的模型上訓練過。通常數度更快,精度更高。
2. 訓練
-
是一個目標數據集上的正常訓練任務,但是使用更強的正則化:
- 因為我們通常會使用更小的學習率(已經和最優解比較接近了,不需要特別長的學習率。微調對學習率不敏感,直接使用一個比較小的學習率就行了)。
- 使用更少的數據迭代(需要訓練的epoch沒有那么多了,訓練太過很可能over fit)。
-
源數據集遠復雜于目標數據(類別、數量、樣本個數要百倍大于目標數據集),通常微調效果更好。沒有特別優于目標數據集的不如自己從頭開始訓練。
3. 重用分類器權重
- 源數據集可能也有目標數據集中的部分標號。
- 這樣線性分類器就可以使用預訓練好的模型分類器中對應標號對應的向量(也可以重用其中的好幾個類,還能再加上自己新建的類,但是只有重復的類能重用,而且只能手動提取權重。其余的無關標號的權重直接刪除!)來做初始化。(實際用的不多)
- 沒有的標號只能隨機。
4. 固定一些層
- 神經網絡通常學習有層次的特征表示:
- 低層次的特征更加通用(與底層細節相關,理解數據,我們認為這是通用的)
- 高層次的特征則更跟數據及相關(更加語義化一些,與標號更相關)
- 可以固定底部一些層的參數,不參與更新(這樣模型復雜度降低),可以認為是一種更強的正則。對于數據集很小時很有用。但是怎么樣最好是需要調的,最極端的是其余固定住,只訓練最后一個全連接層,另一個極端就是全部的層一起動。
5. 代碼實現
(訓練集測試集)進行了數據增廣,注意如果預訓練模型做了norm,微調前也需要做同樣的norm。模型輸入大小要一樣。要是有數據增強也是需要一樣的。
-
下模型:(下載時,下列參數為true,說明不僅下模型定義下下來,還有訓練好的parameter也一起拿下來)下一行代碼是拿出最后一層。

-
更改輸出層:并對最后一層的weight隨機初始化

-
如果param_group為true:將非最后一層的參數取出,其他層lr小,fc層lr大。

-
不適用預訓練:從零開始訓練。

補充:
- 數據不平衡(也可以理解成標號不平衡)問題對特征提取的影響相對較小,對越往上層的影響越大,尤其是分類器。
- 要找預訓練模型在和所使用的數據集相似的源數據集(可以更大,種類更多,但是要相似,當然不是源數據集必須包含目標數據集哦)上訓練的,要不相差太大可能還不如從頭開始訓練。
- 標號要找對應的字符串(label的名稱字符串,還要注意語義匹配不同,數據集上叫的名字可能不同),因為標號肯定是按照順序來的,沒什么意義。
- 微調中的歸一化很重要,可以認為是網絡中的一塊,是可以換成batchnoralize就不需要這個了,但是我們copy時是沒有copy這一塊的,因此需要我們手動弄過去,但是如果預訓練模型中有,那就不需要我們代碼中自己搞的normalize了(源數據集的訓練結構也做了歸一化)。
- normalize參數是從源數據集上算出來的,finetune需要更改normalization的參數為自己數據集的均值和方差。
- auto-gluon會加入微調的(使用微調一般不會讓模型變差,可能不會變好,但是一般不會變差)。
- 常用的CV預訓練模型有imagenet上預訓練的resnet系列。
- 微調是需要重新搞一下label和對應標號關系的,可以看課后習題有講解。
- 自己預訓練一個分類模型是有用的,因為可以用到其他圖像技術上,反正都需要抽取特征的。
八、競賽-樹葉分類結果
第38節,略
九、實戰-圖像分類kaggle比賽
o-gluon會加入微調的(使用微調一般不會讓模型變差,可能不會變好,但是一般不會變差)。
- 常用的CV預訓練模型有imagenet上預訓練的resnet系列。
- 微調是需要重新搞一下label和對應標號關系的,可以看課后習題有講解。
- 自己預訓練一個分類模型是有用的,因為可以用到其他圖像技術上,反正都需要抽取特征的。
八、競賽-樹葉分類結果
第38節,略
九、實戰-圖像分類kaggle比賽
第39節40節,略
——目標跟蹤)
)
)
)

)

。Javaee項目,springboot項目。)

)
)
)



———HTTP 緩存機制)



之燈光和陰影(源碼))