
為優化淘寶帶寬成本,我們在網關 SDK(Java)統一使用 ZSTD 替代 GZIP 壓縮以獲取更高的壓縮比,從而得到更小的響應包。具體實現采用官方推薦的?zstd-jni 庫。zstd-jni 會調用 zstd 的 c++ 庫。

背景
在性能壓測和優化過程中,遇到了以下三個問題:
GC 次數不變,但耗時翻倍
進程內存泄漏,極限情況下會出現 OOM Killer 殺掉進程的情況
Netty 堆外內存泄漏(在優化問題 1 時引入)
下面我會從這三個問題展開,分享排查、解決問題的思路和過程。

GC 優化
???【GC 耗時翻倍問題】現象
在我們預期中,使用 ZSTD 壓縮,在大包場景下(20KB 以上),不僅能夠獲得比 GZIP 更高的壓縮比;同時壓縮性能也應有一定優化,具體優化程度取決于業務特征,但至少不會有性能劣化。
但實際性能壓測發現相比于同級別的 Netty GZIP,ZSTD 壓縮下,GC 次數不變,但耗時幾乎翻倍,導致最終應用表現為幾乎無任何性能優化,甚至影響 RT(CMS 下)。
???【GC 耗時翻倍問題】分析
我們的 ZSTD 壓縮是通過 JNI 實現,流程是將堆內數據拷貝到堆外壓縮,再將拷回堆內。
使用 JNI 會在一定程度上影響 GC 的效率,這是我們已知的,但是耗時翻倍超出了我們的預期。因此我們嘗試分析壓縮的執行流程。
JDK 22 中通過在 G1 中實現 region pinning 來減少延遲,以在 JNI 執行期間無需禁用 GC,詳見 JEP?423:?Region?Pinning?for?G1(地址:https://openjdk.org/jeps/423)
相比 GZIP,ZSTD 在單次壓縮過程中,多了內存占用:
壓縮后數據占用的堆內內存
a.ZSTD 壓縮原始數據和壓縮后數據分開保存,占用兩份內存。而 GZIP 會將壓縮后的數據寫回到壓縮前的 byte 數組,只占用一份內存。
b.除此之外,尤其是在流式 ZSTD 場景下,多個響應復用同一個 OutputStream 以達到最優壓縮比,但 OutputStream 里的 buffer 會占用額外的堆內空間。
堆外壓縮需要的內存,保存 ZSTD 壓縮上下文(保存字典)。
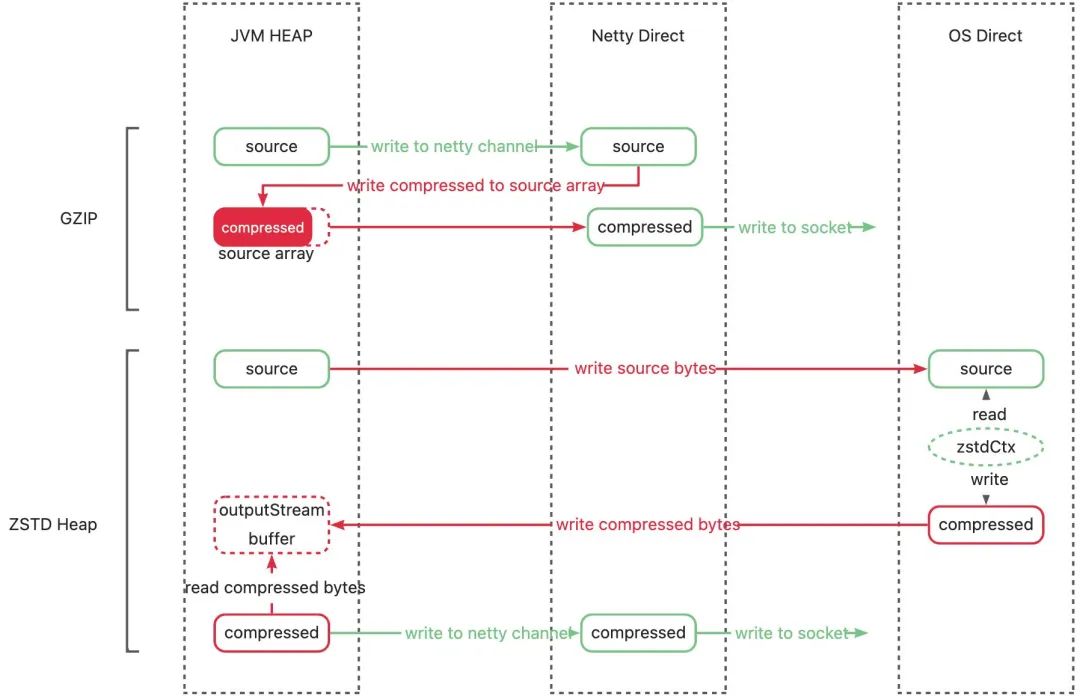
據圖分析,可能存在兩個問題導致 GC 耗時變長:
不必要的堆內內存占用
不必要的堆內外數據拷貝
???【GC 耗時翻倍問題】解決
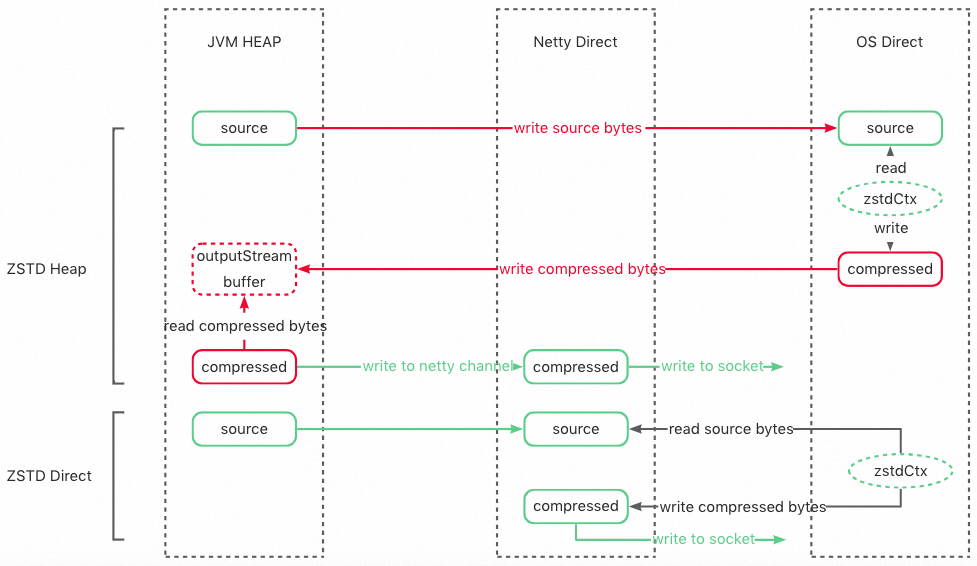
思路:為了能夠解決以上兩個問題,我們希望能夠將原始數據在堆外壓縮后直接寫出,一方面盡早釋放原始數據占用的堆內內存,另一方面減少不必要的堆內外拷貝。
實現:使用 zstd-jni 提供的堆外壓縮接口,直接原始數據拷貝到堆外進行壓縮,并通過 Netty 直接在堆外寫出(流程為上圖的 ZSTD Direct)。
???【Finalizer 問題】現象
但是,轉堆外壓縮后,再次進行壓測,發現 GC 并沒有如期下降,反而更加頻繁,堆內存使用更高。
于是 GC 后 dump 查看堆布局,分析 JVM 堆內存,發現整體堆使用大小 915M/4G,這很不正常,我們的測試應用沒有長壽命對象,預期 GC 后,堆大小應該只有幾十 M。
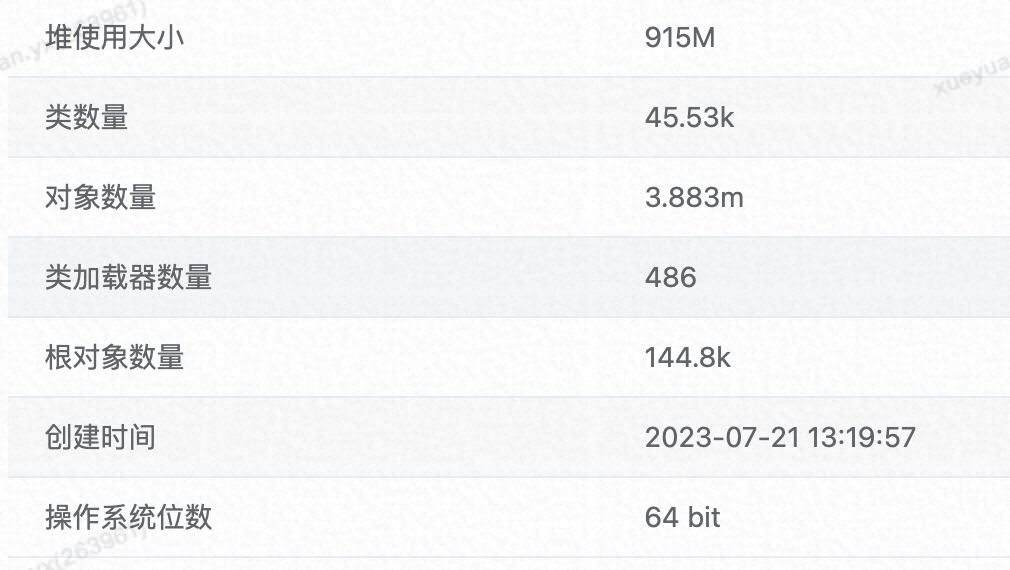
進一步查看堆內對象,發現有大量新增可疑對象:
Finalizer
ZstdJNIDirectByteBufCompressor(壓縮實例,JNI 調用入口。)
DefaultInvocation(請求上下文,包含請求和響應的全部信息,為應用大對象。)
他們的引用關系為:
Finalizer -> ZstdJNIDirectByteBufCompressor <-> DefaultInvocation。
其中 ZstdJNIDirectByteBufCompressor 和 DefaultInvocation 有高達 1604 個,占用內存超 704M,占已使用堆內存的 77%,但之前并沒有這些對象。

???【Finalizer 問題】分析
哪來這么多 Finalizer 對象,和 GC 耗時增長有什么關系?
要想知道 Finalizer 對象是什么,我們首先需要了解 JVM 的 finalize() 方法:
finalize() 方法定義在 Object 類中,對于實現了 finalize() 的對象,當垃圾回收器確定該對象沒有任何引用時,就會調用其 finalize()。
筆者建議大家盡量避免使用它,因為它并不能等同于 C 和 C++ 語言中的析構函數,而是 Java 剛誕生時為了使傳統 C、C++ 程序員更容易接受 Java 所做出的一項妥協。它的運行代價高昂,不確定性大,無法保證各個對象的調用順序,如今已被官方明確聲明為不推薦使用的語法。有些教材中描述它適合做“關閉外部資源”之類的清理性工作,這完全是對 finalize() 方法用途的一種自我安慰。finalize() 能做的所有工作,使用 try-finally 或者其他方式都可以做得更好、 更及時,所以筆者建議大家完全可以忘掉 Java 語言里面的這個方法。
--《深入理解 JVM》
多數同學對 finalize 方法的了解,可能都來自于以上這段話,知道其 “運行代價高昂”,“不推薦使用” ,那它到底會對我們應用產生什么影響?
JVM 是如何執行 finalize() 的?
JVM 在加載類的時候,會去識別該類是否實現了 finalize() ;若是,則標記出該類為“ finalize class”。
在創建 “finalize Class” 對象時,會調用 Finalizer#register(),在該方法中創建一個 Finalizer 對象,Finalizer 對象會引用原始對象,然后將其注冊到名為 unfinalized 的全局隊列中(保證 Finalizer 對象及其引用的原始對象一直可達,以確保在被 GC 前,其 finalize() 能被執行)。
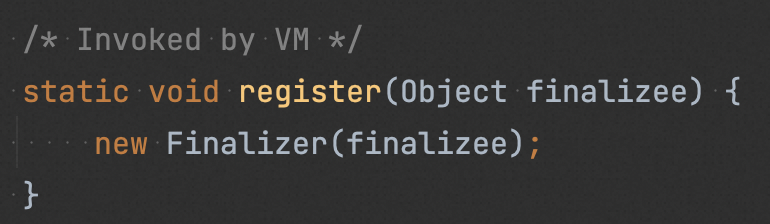
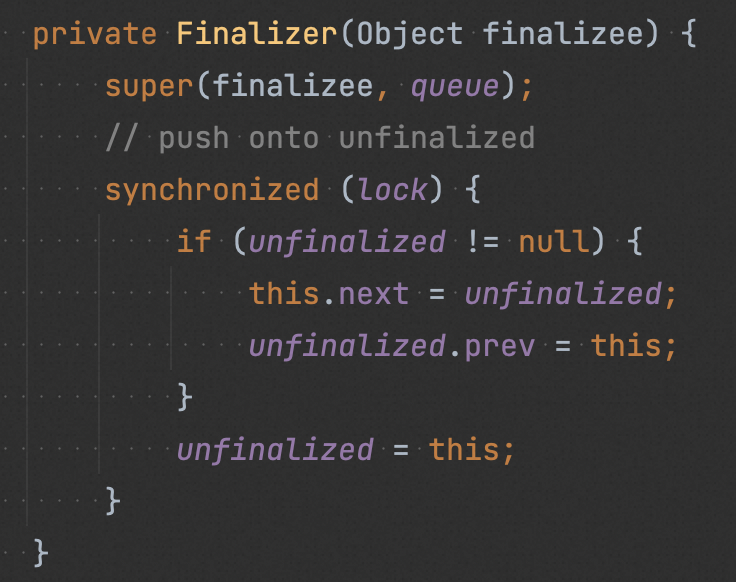
在一次 GC時,JVM 判斷原始對象除了 Finalizer 對象引用之外沒有其他對象引用之后,就把 Finalizer 對象從 “unfinalized” 隊列中取出,加入到 “Finalizer queue” 中。
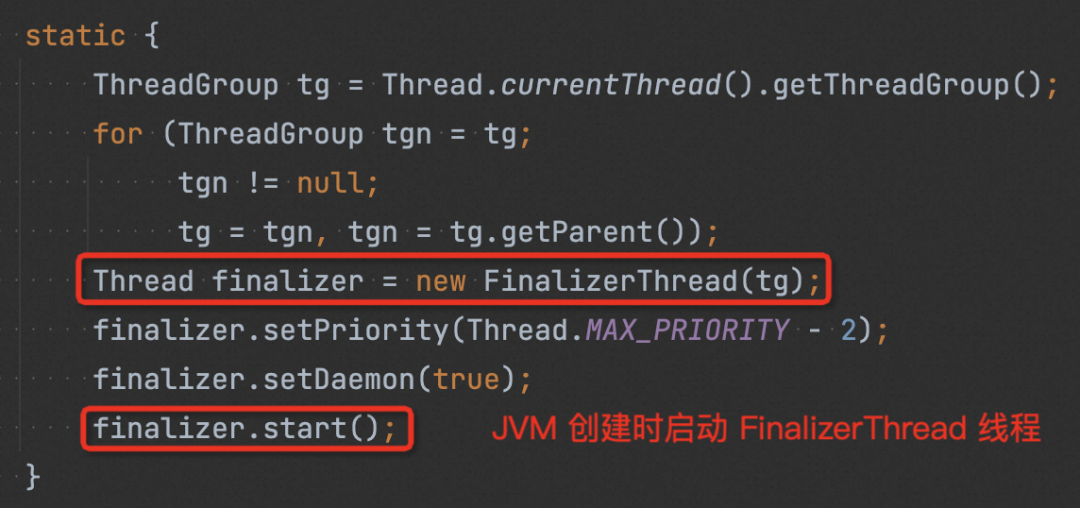
JVM 在啟動時,會啟動一個“finalize”線程,該線程會一直從“Finalizer queue”中取出對象,然后執行原始對象中的 finalize()。
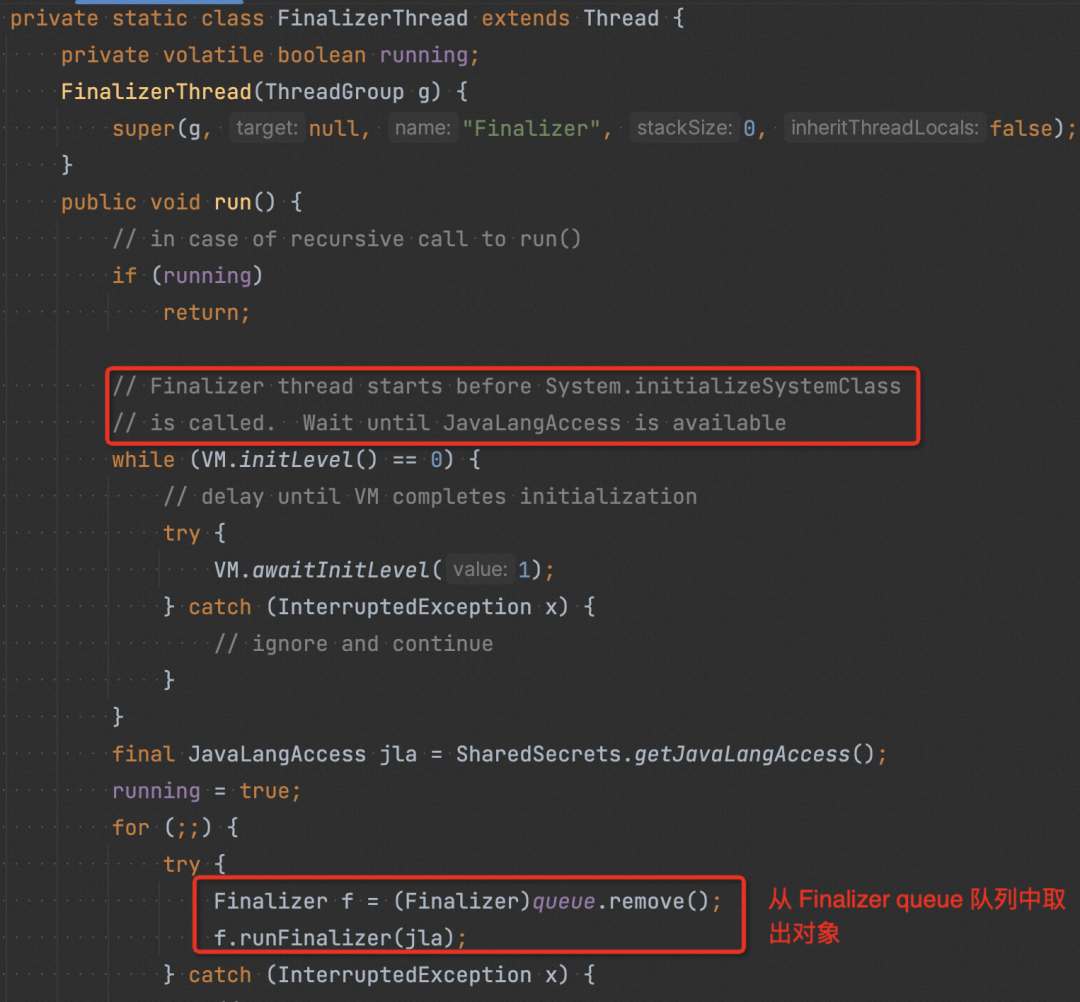
在完成步驟 4 后,Finalizer 對象以及其引用的原始對象,再無其他引用,屬于不可達對象,再次 GC 的時候他們將會被回收掉。(如果在 finalize() 使該對象重新可達,再次 GC 該對象不會被回收,即 finalize() 方法是對象逃脫死亡 (GC) 命運的最后一次機會)。
使用 finalize() 帶來哪些影響?
創建一個實現 finalize() 的對象時,需要額外創建其 Finalizer 對象并且注冊到隊列中,因此需要額外的內存空間,且創建時間長于普通對象創建。
相比普通對象,實現 finalize() 的對象生存周期更長,至少需要兩次 GC 才可被回收。
在 GC 時需要對實現 finalize() 的對象做特殊處理(比如 Finalizer 對象的出隊入隊操作等), GC 耗時更長。
因為 finalize 線程優先級比較低,若 CPU 繁忙,可能會導致 “ Finalizer queue” 有積壓,在經歷多次 YGC 之后原始對象及其 Finalizer 對象就會進入 old 區域,那么這些對象只能等待 FGC 才能被 GC。
總的來說,使用 finalize() 方法本身會加重系統負擔、嚴重影響 GC 并且無法保證 finalize 的調用時機,其應用場景也僅僅是防止資源泄漏,finalize() 能做的所有工作,使用 try-finally 或者其他方式都可以做得更好、 更及時,所以我們還是忘記它的存在吧。
???【Finalizer 問題】解決
最佳實踐:
盡可能避免使用 finalize 機制。若實在無法避免,也應盡量避免其引用大對象。
JDK 18 中已經棄用 finalize 機制以在未來版本中刪除。詳見:Deprecate?Finalization?for?Removal(地址:https://openjdk.org/jeps/421)
在我們的 ZSTD 場景下,由于 zstd-jni 將 finalize() 作為堆外資源的兜底清理手段,因此我們斷開其對應用大對象的引用后,耗時翻倍的問題被成功解決。
我們的測試應用單機極限 QPS 較低(300),Finalizer 只要不引用大對象,對 GC 的影響不大;但在更高 QPS 場景下,Finalizer 對 GC 的影響會更加凸顯。
我們在另一線上應用使用 ZSTD 壓縮,在單機 QPS 1000 時,比起使用 NoFinalizer 的 Zstd Compressor,使用 Finalizer 的 Zstd Compressor GC 耗時漲了近 10 倍。
因此,我們最終決定直接使用 NoFinalizer 的 Zstd Compressor。

Netty ByteBuf 內存泄漏
???現象
為了優化 GC,我們通過 Netty 的 DirectByteBuf 操作堆外內存,直接在堆外壓縮并響應。
但在性能壓測時,通過 Netty 的內存泄漏檢測工具,發現在極限情況下會產生內存泄漏,經過觀察,會伴隨著以下幾種現象:
施壓 QPS 達到單機極限,持續有 FGC 產生;
客戶端超時主動斷連,繼續往被關閉的 channel 里寫入內容失敗,會出現連接已關閉的報錯;
Netty 堆外內存滿;
???分析
Step 1 泄漏堆棧顯示泄漏對象為響應內容的 DirectByteBuf
Step 2 通過增加埋點追溯業務代碼中可能的泄漏點,發現在寫給 netty ChannelOutboundHandler pipeline 之前,是沒有泄漏的。
Step 3 排查聚焦在 netty 的 ChannelOutboundHandler pipeline,排查我們自己實現的 ChannelOutboundHandler 內部也并未有泄漏。
Step 4 進一步分析 netty 內存泄漏檢測的堆棧,發現泄漏內存的最后訪問點有 netty 框架內部代碼,所以猜測泄漏可能是框架執行過程中產生。
Step 5 進一步分析 netty 寫出響應的代碼。
我們調用 netty 的 AbstractChannel#writeAndFlush(java.lang.Object) 寫出內容,會從 pipeline 的最后一個節點執行,最終進入到 next.invokeWriteAndFlush(m, promise)。
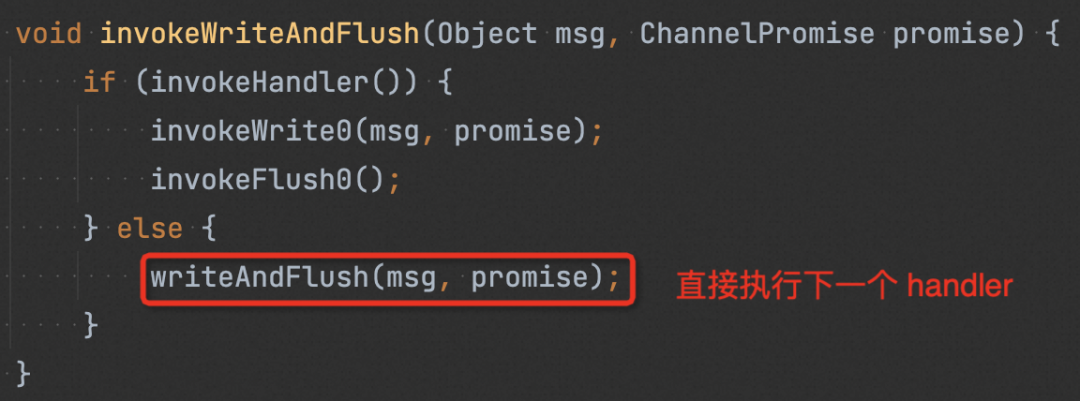
invokeHandler() 會檢查 handler 的狀態(如下圖),確認其是否可被執行。若 handler 被認為不可執行,則會直接嘗試執行下一個 handler (如 1 中圖)。
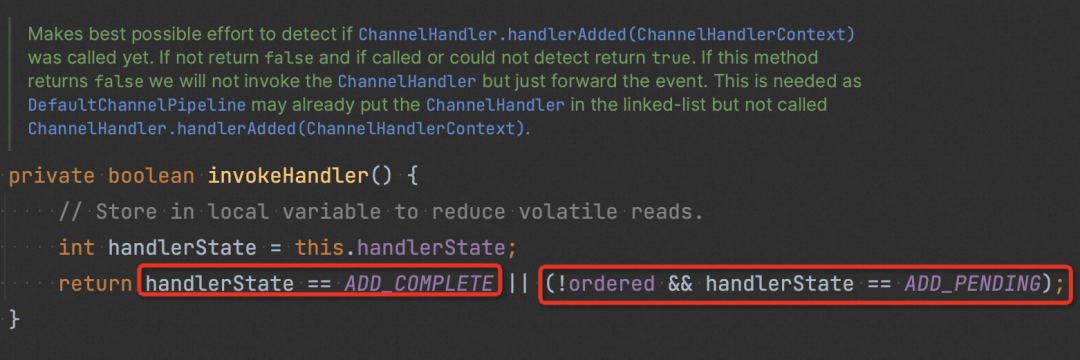
嘗試追溯 handlerState 的更新。發現當 channel 被 deregister 后(連接關閉), pipeline 所有中間 handler 的狀態都會被置為 REMOVE_COMPLETE,即不可執行,這樣后續再寫入的消息都不會再進入到這些 handler 里了。(泄漏就是從這里開始)
setRemoved:911, AbstractChannelHandlerContext (io.netty.channel)
callHandlerRemoved:950, AbstractChannelHandlerContext (io.netty.channel)
callHandlerRemoved0:637, DefaultChannelPipeline (io.netty.channel)
destroyDown:876, DefaultChannelPipeline (io.netty.channel)
destroyUp:844, DefaultChannelPipeline (io.netty.channel)
destroy:836, DefaultChannelPipeline (io.netty.channel)
access$700:46, DefaultChannelPipeline (io.netty.channel)
channelUnregistered:1392, DefaultChannelPipeline$HeadContext (io.netty.channel)
invokeChannelUnregistered:198, AbstractChannelHandlerContext (io.netty.channel)
invokeChannelUnregistered:184, AbstractChannelHandlerContext (io.netty.channel)
fireChannelUnregistered:821, DefaultChannelPipeline (io.netty.channel)
run:839, AbstractChannel$AbstractUnsafe$8 (io.netty.channel)
safeExecute$$$capture:164, AbstractEventExecutor (io.netty.util.concurrent)
safeExecute:-1, AbstractEventExecutor (io.netty.util.concurrent)- Async stack trace
addTask:-1, SingleThreadEventExecutor (io.netty.util.concurrent)
execute:825, SingleThreadEventExecutor (io.netty.util.concurrent)
execute:815, SingleThreadEventExecutor (io.netty.util.concurrent)
invokeLater:1042, AbstractChannel$AbstractUnsafe (io.netty.channel)
deregister:822, AbstractChannel$AbstractUnsafe (io.netty.channel)
fireChannelInactiveAndDeregister:782, AbstractChannel$AbstractUnsafe (io.netty.channel)
close:765, AbstractChannel$AbstractUnsafe (io.netty.channel)
close:620, AbstractChannel$AbstractUnsafe (io.netty.channel)
close:1352, DefaultChannelPipeline$HeadContext (io.netty.channel)
invokeClose:622, AbstractChannelHandlerContext (io.netty.channel)
close:606, AbstractChannelHandlerContext (io.netty.channel)
close:472, AbstractChannelHandlerContext (io.netty.channel)
close:957, DefaultChannelPipeline (io.netty.channel)
close:244, AbstractChannel (io.netty.channel)
close:92, DefaultHttpStream (com.alibaba.xxx.xxx.xxx.inbound.http)
onRequestReceived:111, DefaultHttpStreamTest$getHttpServerRequestListener$1 (com.alibaba.xxx.xxx.xxx.inbound.http)
onHttpRequestReceived:53, HttpServerStreamHandler (com.alibaba.xxx.xxx.xxx.inbound.http.server)
channelRead:44, HttpServerStreamHandler (com.alibaba.xxx.xxx.xxx.inbound.http.server)
invokeChannelRead:379, AbstractChannelHandlerContext (io.netty.channel)
invokeChannelRead:365, AbstractChannelHandlerContext (io.netty.channel)
fireChannelRead:357, AbstractChannelHandlerContext (io.netty.channel)
channelRead:286, IdleStateHandler (io.netty.handler.timeout)
invokeChannelRead:379, AbstractChannelHandlerContext (io.netty.channel)
invokeChannelRead:365, AbstractChannelHandlerContext (io.netty.channel)
fireChannelRead:357, AbstractChannelHandlerContext (io.netty.channel)
channelRead:103, MessageToMessageDecoder (io.netty.handler.codec)
invokeChannelRead:379, AbstractChannelHandlerContext (io.netty.channel)
invokeChannelRead:365, AbstractChannelHandlerContext (io.netty.channel)
fireChannelRead:357, AbstractChannelHandlerContext (io.netty.channel)
channelRead:103, MessageToMessageDecoder (io.netty.handler.codec)
channelRead:111, MessageToMessageCodec (io.netty.handler.codec)
invokeChannelRead:379, AbstractChannelHandlerContext (io.netty.channel)
invokeChannelRead:365, AbstractChannelHandlerContext (io.netty.channel)
fireChannelRead:357, AbstractChannelHandlerContext (io.netty.channel)
channelRead:103, MessageToMessageDecoder (io.netty.handler.codec)
invokeChannelRead:379, AbstractChannelHandlerContext (io.netty.channel)
invokeChannelRead:365, AbstractChannelHandlerContext (io.netty.channel)
fireChannelRead:357, AbstractChannelHandlerContext (io.netty.channel)
fireChannelRead:324, ByteToMessageDecoder (io.netty.handler.codec)
channelRead:296, ByteToMessageDecoder (io.netty.handler.codec)
invokeChannelRead:379, AbstractChannelHandlerContext (io.netty.channel)
invokeChannelRead:365, AbstractChannelHandlerContext (io.netty.channel)
fireChannelRead:357, AbstractChannelHandlerContext (io.netty.channel)
channelRead:1410, DefaultChannelPipeline$HeadContext (io.netty.channel)
invokeChannelRead:379, AbstractChannelHandlerContext (io.netty.channel)
invokeChannelRead:365, AbstractChannelHandlerContext (io.netty.channel)
fireChannelRead:919, DefaultChannelPipeline (io.netty.channel)
read:166, AbstractNioByteChannel$NioByteUnsafe (io.netty.channel.nio)
processSelectedKey:719, NioEventLoop (io.netty.channel.nio)
processSelectedKeysOptimized:655, NioEventLoop (io.netty.channel.nio)
processSelectedKeys:581, NioEventLoop (io.netty.channel.nio)
run:493, NioEventLoop (io.netty.channel.nio)
run:986, SingleThreadEventExecutor$4 (io.netty.util.concurrent)
run:74, ThreadExecutorMap$2 (io.netty.util.internal)
run:748, Thread (java.lang)可以看到 pipeline 中間 handler 被跳過了,其中也包括我們自己實現的 handler。分析下圖代碼,我們寫給 netty pipeline 的 msg 實際是我們自己包裝的 HttpObject,是在我們自己實現的 handler 里才轉成 netty 的 ReferenceCounted 對象的,由于 handler 被跳過導致該對象并沒有被轉換成 ReferenceCounted,所以即使 netty 有兜底的 release ,實際并沒有產生作用,HttpObject 內部的 ByteBuf 并未真正被釋放,此時產生泄漏。
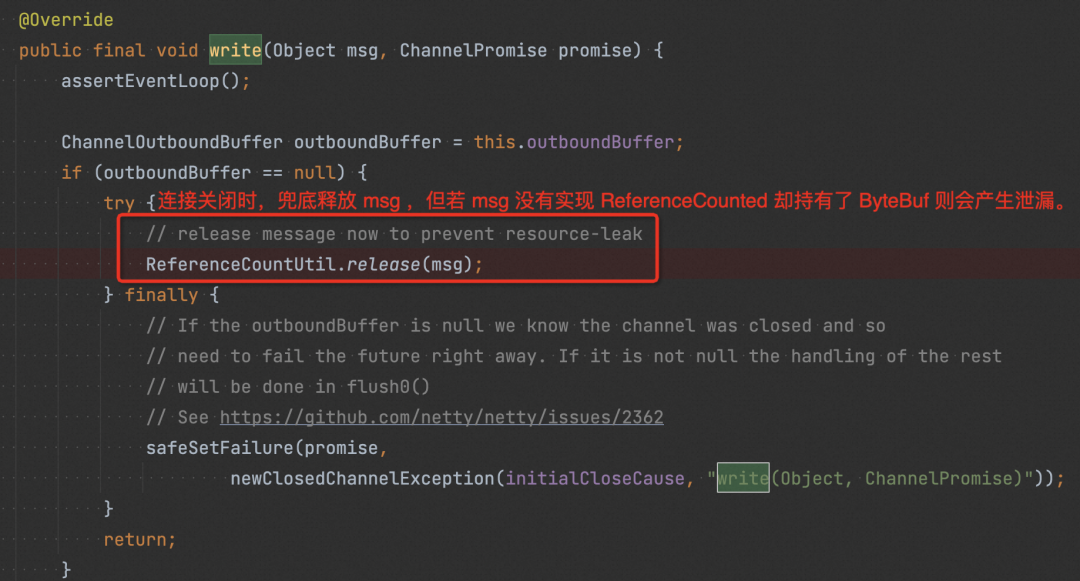
???解決
【最佳實踐】在寫入 channel 之前,一定要先判斷 channel 是否 active 。
【最佳實踐】我們寫給 netty 的內容,最好是實現了 ReferenceCounted 接口的對象,這樣即使 netty 內部出現不預期情況,我們也可以利用 netty 的兜底 release 來釋放資源。
控制 ByteBuf 的使用范圍。在我們的場景里,可以將壓縮的實現下移到 netty 層,但上述 1、2 也同樣必須改進才能確保不出問題。
好處:對 ByteBuf 的操作可以收口在傳輸層,應用層編程難度大大降低。
壞處:考慮到可能存在多個 傳輸層 (http server) 的實現,壓縮邏輯可能需要根據堆內堆外做兩份實現,每個 http server 都需要對接。

堆外內存
???現象
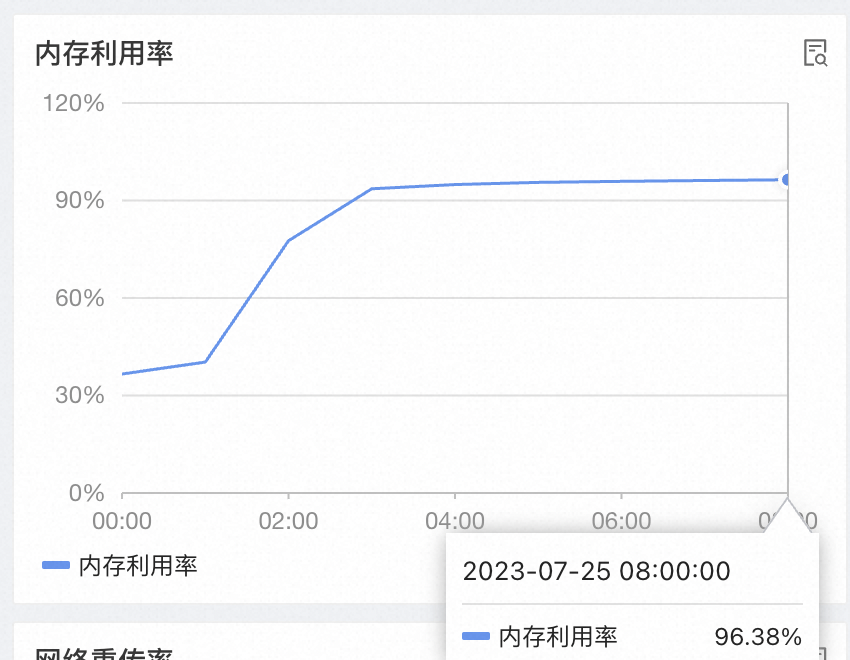
開啟 zstd 壓縮時:
QPS 增加會導致操作系統內存持續增加,直到 OOM Killer。
在 QPS 調零數十小時后,內存也幾乎不會降低。
因此懷疑存在堆外內存泄漏。
???分析
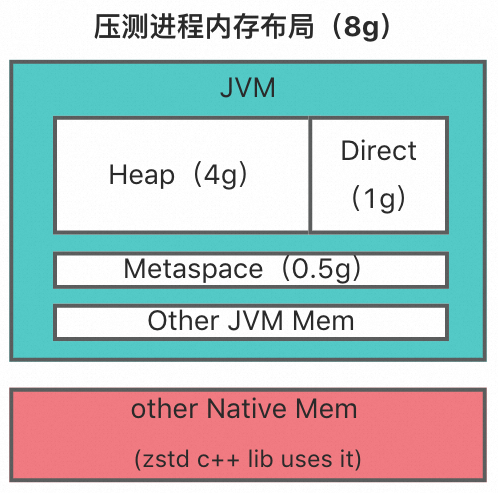
首先,整個應用進程用到的堆外內存分兩塊:
JVM 堆外內存:在我們的測試應用里,JVM 的堆外內存最大值均為 1g,主要是 netty 使用,即 25%。
zstd 庫使用的原生內存:
壓縮流程使用原生內存的過程可以簡單描述為:創建 zstd ctx 準備壓縮 -> 調用 malloc 分配操作系統內存 -> 執行壓縮 -> 調用 free 釋放內存 -> 釋放 zstd ctx。
首先分析源碼:
Java 代碼:在我們的應用里 zstd ctx 的生命周期為請求級別,且我們通過 Java 埋點確認了請求結束后一定會正確釋放。
zstd c++ 代碼:zstd 沒有額外的內存管理,直接使用 stdlib 的 malloc 和 free 操作內存。在 zstd ctx 創建的時候分配對應的內存塊,銷毀實例時釋放對應的內存塊。
理論上不會存在 zstd 相關的內存泄漏
其次,通過對比實驗分析:
在未開啟 zstd 壓縮時,不會出現堆外內存疑似泄漏的問題。而開啟 zstd 壓縮時,內存會漲到 95%+,遠超過 JVM 占用的最大內存。
因此,基本排除 1 的泄漏可能。
接著,分析進程實際內存使用:
使用 jemalloc 對壓測到 95% 內存的進程進行內存分析,發現堆外內存主要由 zstd 庫持有(其實這個 case 進程內存最終降下來了,但當時未查明原因。)
使用 jemalloc 內存泄漏檢測工具,未檢測到 zstd 庫代碼的內存泄漏。
因此,我們認為 zstd 庫對內存的操作大概率沒有泄漏。
直到最后,我們嘗試升級 JDK 版本,重新壓測發現 QPS 調零后,內存能夠降下來了。而 JDK 版本升級前后的區別在于使用的內存分配器不同:glibc 默認的 ptmalloc vs jemalloc。因此我們懷疑內存泄漏和內存分配器有關。
內存分配器是什么?
內存分配器是用來為應用分配和管理操作系統內存的,分配器從操作系統獲取內存再自行管理,具體分配、管理、回收策略取決于內存分配器的具體實現。
我們通常使用的內存分配器,即 malloc/free 函數,由 C 標準庫 (libc) 提供的,也被稱為動態內存分配器,不同的內存分配器對函數有不同的實現。
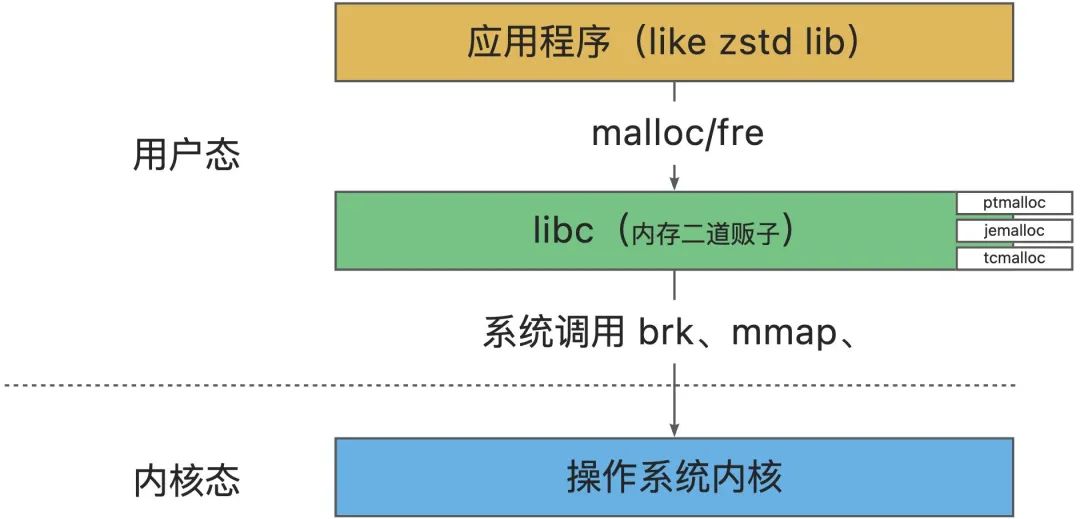
內存分配器的核心思想?
內存分配器的核心是 平衡內存分配的性能和內存使用的效率。前者保證響應快、時間短,后者保證有足夠內存可用、不浪費。
內存分配器百家爭鳴,但是核心思想都是相似的,只是差在具體的算法和元數據的存儲上。內存分配器的核心思想概括起來三條:
內存分配及管理:將內存分為多種固定大小的內存塊(Chunk),通過內存塊管理和元信息存儲策略,使對每個 size class 或大內存區域的訪問的性能最優。
內存回收及預測:當用戶釋放內存時,要能夠合并小內存為大內存,根據一些條件,該保留的就保留起來,在下次使用時可以快速的響應。不需要保留時,則釋放回系統,避免長期占用。
多線程內存分配:比如通過線程獨占內存區間(TLS Thread Local Storage)以降低鎖競爭對性能的影響。
幾種常見的應用層內存分配器對比
內存分配及管理 | 內存回收及預測 |
鏈表維護空閑內存塊,每次分配時從鏈首遍歷嘗試尋找大小合適(但不相等,因此容易產生內存碎片)的空閑內存塊,若無,則嘗試繼續向 OS 申請新內存塊(內存擴張,64 位系統下每次申請 64M,Linux 64M 內存塊問題就來源于此) |
|
內存管理分為線程 Cache 和中央堆兩部分。 為每個線程分配一份線程 Cache,小內存分配從線程 Cache 獲取,大內存從中央堆分配。 在需要時從中央堆獲取內存補充線程 Cache。 |
|
使用多級大小來優化小塊內存的分配;
使用分配區(arena)來維護內存,每個分配區都維護了一系列分頁,來提供 small 和 large 的內存分配請求; 每個線程有線程 Cache,且固定選擇一個分配區,small 和 large 對象優先從 tcache 分配,其次從線程固定的 arena 分配。 | 從一個分配區分配出去的內存塊,在釋放的時候一定會回到該分配區。 有兩個層面的回收:
|
總的來說,不同的內存分配器有不同的策略,需要根據場景選擇:
PTMalloc:是 glibc 默認的內存分配器;存在內存浪費、內存碎片、以及加鎖導致的性能問題。
TCMalloc:適合線程的數量、創建,銷毀等是動態的場景;在一些內存需求較大的服務(如推薦系統),小內存上限過低,當請求量上來,鎖沖突嚴重,CPU 使用率將指數暴增。
JEMalloc:適合線程的數量、創建、銷毀等是靜態的(比如線程池)的場景。當 JEMalloc 為了容納更多的線程時,它會去申請新的 Cache,這會導致出現瞬間的性能劇烈抖動。
???解決
由于測試應用使用的 JDK 版本較低,底層 malloc 實現為 glibc 默認的 ptmalloc,存在內存碎片問題,底層使用 jemalloc 即可解決內存碎片問題。

總結與感想
時刻關注代碼對應用性能的影響。比如一些容易被忽略的點,堆內外拷貝操作、長時間引用大對象等。
最好不要用 Finalizer,避免降低 GC 回收效率。
堆外內存使用得當,一定程度上能夠優化性能,但要注意由此引發的泄漏風險。
盡量控制堆外內存的使用范圍,降低業務層編碼難度。
在使用堆外內存時可以需要通過顯式約定來盡量降低內存泄漏的風險,比如在代碼中明確說明 ByteBuf 的使用原則:
a.誰消費誰釋放,如果 A 組件將 ByteBuf 傳遞給 B 組件,則通常交由 B 組件決定是否釋放。
b.如果不希望使用者釋放,在傳給使用者之前,調用一次 .retain() 方法。
寫給 netty 的內容,最好是實現了 ReferenceCounted 接口的對象,這樣即使 netty 內部出現不預期情況,我們也可以利用 netty 的兜底 release 來釋放資源。
¤?拓展閱讀?¤
3DXR技術?|?終端技術?|?音視頻技術
服務端技術?|?技術質量?|?數據算法



)


)



覆蓋優化 - 附代碼)






![[Linux] 用LNMP網站框架搭建論壇](http://pic.xiahunao.cn/[Linux] 用LNMP網站框架搭建論壇)

