結構體:?
? ? ? ?C語言中,我們之前使用的都是C語言中內置的類型,比如整形(int)、字符型(char)、單精度浮點型(float)等。但是我們知道,我們現實世界中,還有很多其他類型。比如書,水杯,人等各種類型。
結構體的使用:?
? ? ? ?在使用結構體之前,我們先來看看結構體的基本使用語法:

? ? ? ?當內置類型無法滿足我們的我們的需求(像定義一本書),此時就會用到結構體了,它就可以自定義一個類型。比如書就是一種類型,組成它的元素就是木頭,墨水,膠水等,這些就是組成書的基本元素。而在編程語言中,我們定義一本書,它的基本元素就可以理解為C語言的內置類型,由這些內置類型組合而成。
struct Book
{//書由一下屬性(元素)組成char Book_Name[20];//書的名字char Writer_Name[20];//作者姓名int edition;//版本號
};//此時變量列表為空? ? ? ?此時我們就自定義了一種書的類型,這時就可以定義多個書的變量。書是類,那么具體的一本書就是一個書變量(也可以理解為對象),此時我們第一定義一個書的變量,并打印。注:變量列表可以為空
struct Book
{//書由一下屬性(元素)組成char Book_Name[20];//書的名字char Writer_Name[20];//作者姓名int edition;//版本號
};int main()
{struct Book Book1 = { "大話數據結構", "張三", 20 };printf("書名是:%s\n", Book1.Book_Name);printf("作者是:%s\n", Book1.Writer_Name);printf("版本是:%d\n", Book1.edition);return 0;
}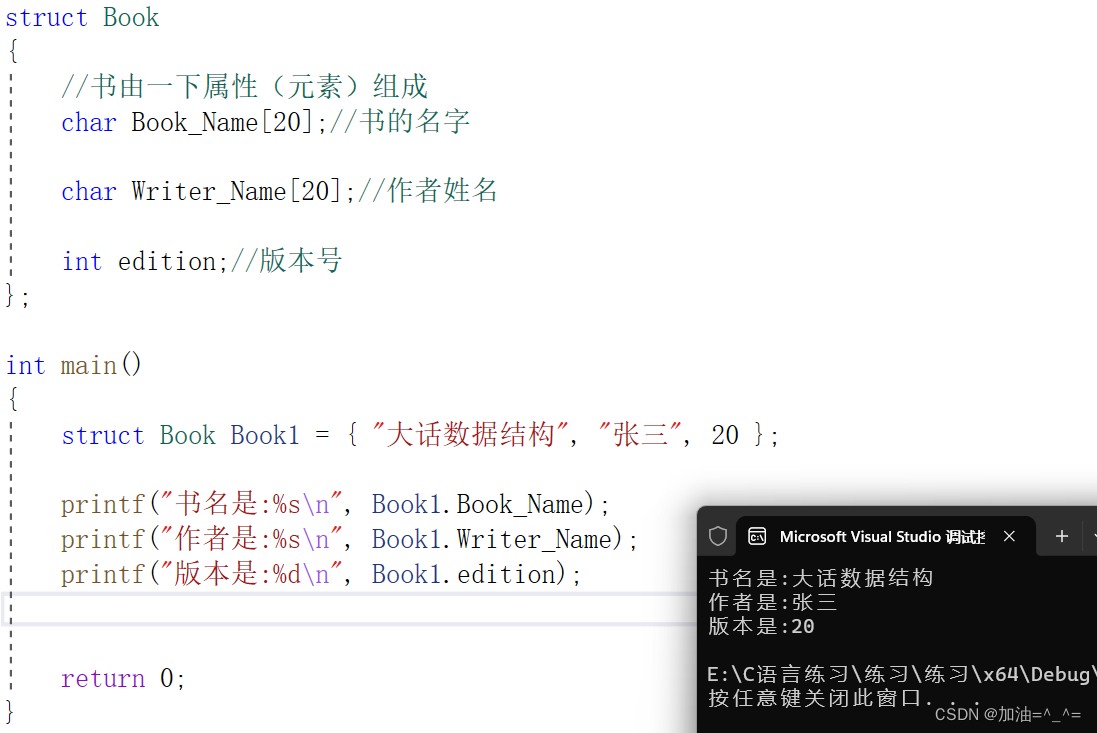 ? ? ? ?我們用 . 來訪問變量中的每一個成員(這不是使用指針的情況)。要按照順序來定義每一個變量,. 就是一個操作符,意思可以理解為“的”。
? ? ? ?我們用 . 來訪問變量中的每一個成員(這不是使用指針的情況)。要按照順序來定義每一個變量,. 就是一個操作符,意思可以理解為“的”。
? ? ? ?每一種類型都有對應的指針,所以結構體也有指針,就是結構體指針。我們用指針訪問結構體變量時就需要用到 -> 來指定訪問變量的哪一個具體成員屬性。
struct Book* p = &Book1;//定義結構體指針指向變量Book1
//因為其他類型只需要解引用,但是結構體有多個成員
//用指針找到結構體變量的每一個成員需要用到 ->
printf("書名是:%s\n", p->Book_Name);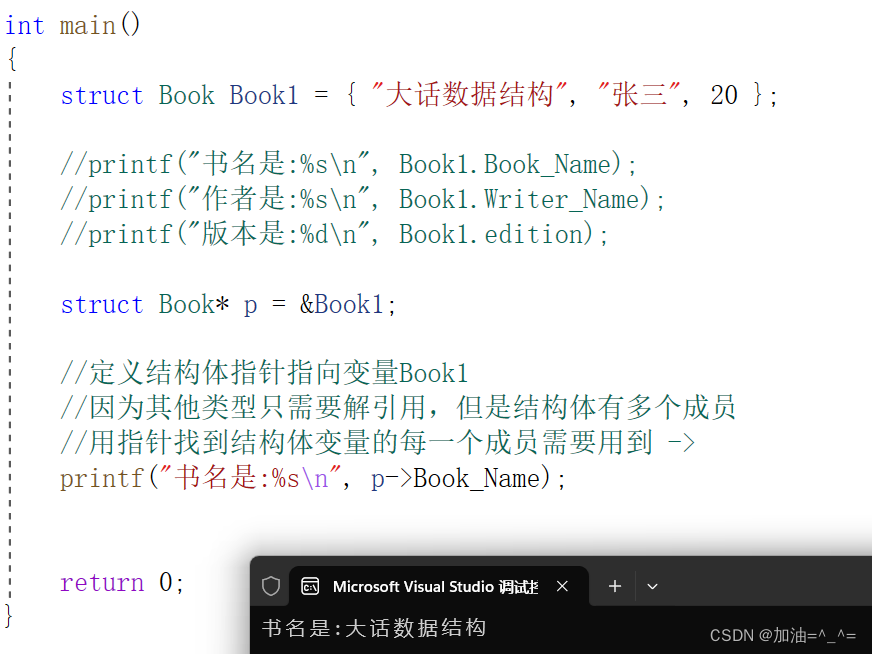 ? ? ? ???當然也可以對其解引用之后再使用 . 操作符訪問具體成員屬性。
? ? ? ???當然也可以對其解引用之后再使用 . 操作符訪問具體成員屬性。
//通過解引用再使用 . 來訪問具體屬性
printf("書名是:%s\n", (*p).Book_Name);
? ? ? ?現在我們來舉例成員列表的使用。比如此時我們使用成員列表,聲明多個成員:
struct Book
{//書由一下屬性(元素)組成char Book_Name[20];//書的名字char Writer_Name[20];//作者姓名int edition;//版本號
}Book1, Book2, Book3;//這3個相當于全局結構體變量int main()
{struct Book Book4;//局部變量return 0;
}? ? ? ?就相當于全局變量。但是C語言并不支持直接在主函數中直接對全局結構體變量進行賦值。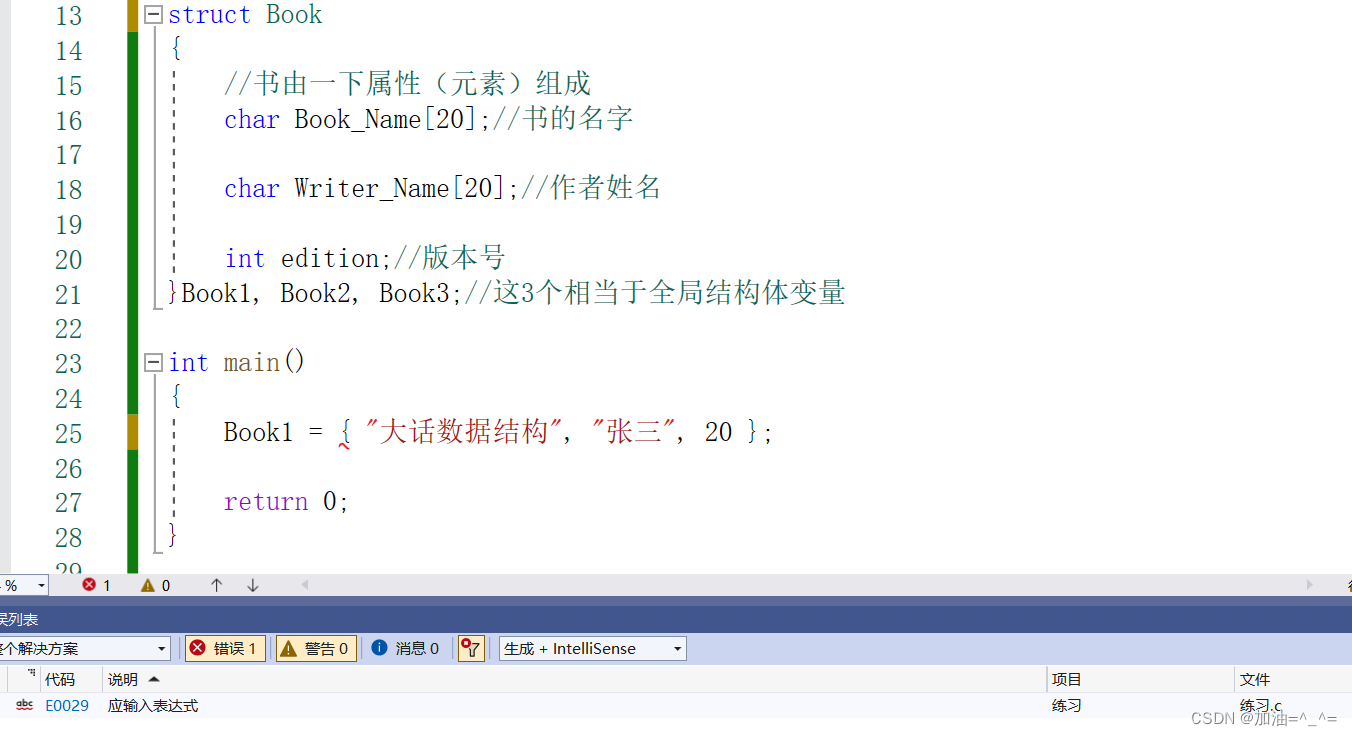
? ? ? ?此時對賦值屬性的字符串賦值也不能使用以下方法賦值:
Book1.Book_Name = "大話數據結構";
? ? ? ?我們只能使用strcpy函數賦值;但對于整數屬性的賦值可以直接賦值:
strcpy(Book1.Book_Name, "大話數據結構");
printf("書名是:%s\n", Book1.Book_Name);
Book1.edition = 20;
printf("版本是:%d\n", Book1.edition);
? ? ? ?之后有人就經常和typedef搞混,因為用法相似:
typedef struct Book
{//書由一下屬性(元素)組成char Book_Name[20];//書的名字char Writer_Name[20];//作者姓名int edition;//版本號
}book;? ? ? ?此時我們相當于將struct Book重命名了(重命名具體用法可先查看其他文章),之后定義該結構體變量不需要使用struct Book,而直接使用book聲明該變量的類型即可:
book Book1 = { "大話數據結構", "張三", 20 };? ? ? ??這里相當于定義了一本書,由于使用了typedef函數,可以省略struct關鍵字,寫出結構體名稱,創建變量即可,這里創建了2個變量,之后打印變量名.成員。
//兩種形式都可以使用
book Book1 = { "大話數據結構", "張三", 20 };struct Book Book2 = { "C語言", "我", 1 };
printf("書名是:%s\n", Book1.Book_Name);
printf("書名是:%s\n", Book2.Book_Name);
? ? ? ?結構體成員可以是結構體,要用大括號來說明結構體中另外的結構體。
struct s
{int a;char c;char arr[20];double d;
};
struct t
{char ch[10];struct s s;//結構體成員可以是結構體char* pc;
};
int main()
{char arr[] = "holle bit";struct t t1 = { "hehe",{3,'u',"holle world",3.14},arr };printf("%s\n", t1.ch);//heheprintf("%s\n", t1.s.arr);//holle worldprintf("%d\n", t1.s.a);//3printf("%lf\n", t1.s.d);//3.140000printf("%s\n", t1.pc);//holle bitreturn 0;
}? ? ? ?這里結構體成員中有指針,我們創建一個數組,把數組名放進去。?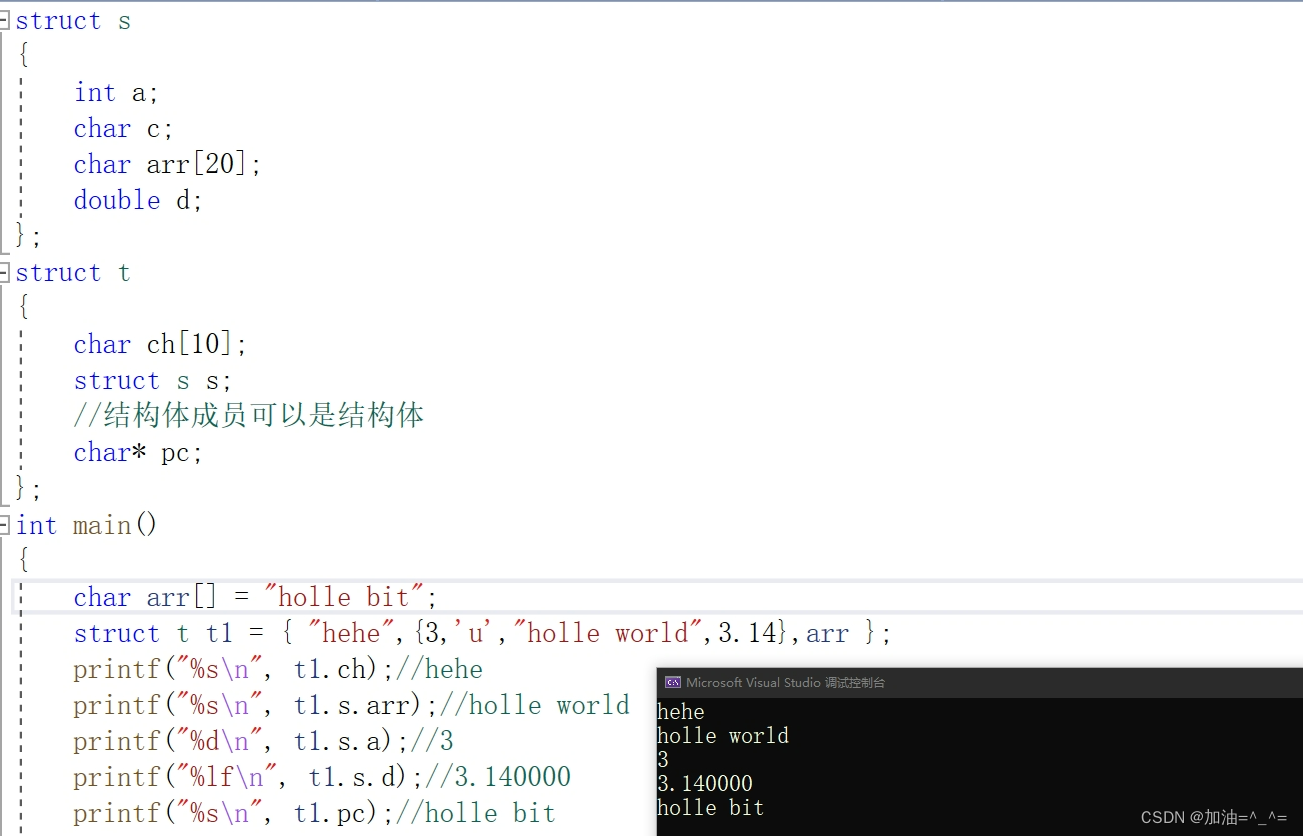
結構體的傳參:?
? ? ? ?我們知道,形參是實參的一份臨時拷貝,我們對結構體進行傳參時,如果是傳值,就是函數中把這個結構體變量臨時復制一份,這樣無疑會浪費很多空間。
? ? ? ?所以我們一般進行傳址調用,就是傳入結構體的指針:
typedef struct stu
{char name[20];short age;char tele[12];char sex[5];
}stu;
void print1(stu s)
{printf("%s\n", s.name);//張三printf("%d\n", s.age);//40printf("%s\n", s.tele);//15568886688printf("%s\n", s.sex);//男//不是指針就用"."
}
void print2(stu* p)
{printf("%s\n", p->name);printf("%d\n", p->age);printf("%s\n", p->tele);printf("%s\n", p->sex);//指針就用箭頭
}
int main()
{stu s = { "張三",40,"15568886688","男" };print1(s);//用這個不太好print2(&s);//用這個函數比較好return 0;
}
? ? ? ?函數傳參時,參數是需要壓棧的。如果傳遞一個結構體對象的時候,結構體過大,參數壓棧系統開銷比較大,所以會導致性能的下降。結論:結構體傳參的時候,要傳結構體的地址。?
匿名結構體:?
? ? ? ?匿名結構體,顧名思義,就是沒有名字的結構體,意味著沒有標簽,但有一個成員變量。
struct
{//匿名結構體類型int a;char c;
}sa;
struct
{//匿名結構體類型int a;char c;
}*psa;//匿名結構體指針類型
int main()
{psa = &sa;//編譯器會認為這是兩種不同的類型return 0;
}? ? ? ??一般最好不要使用,使用一次以后就最好不要使用了。
結構體的自引用:
? ? ? ?結構體可以自信用,并不是遞歸。結構體類型中可以有一個同類型的結構體指針,結構體自引用牽扯到數據結構,先大致了解。
//結構體的自引用
//數據結構:鏈表
//在內存中,每個數據是隨機分布的,為了讓他們有規律的連接起來,就要用到鏈表
//
struct Node
{int data;struct Node *next;
};
int main()
{return 0;
} ? ? ? ?因為typedef可以定義數據類型的名字,所以可以:
? ? ? ?因為typedef可以定義數據類型的名字,所以可以:
typedef struct Node
{int data;struct Node* next;
}Node;
int main()
{struct Node n1;Node n2;return 0;
}結構體的大小:?
? ? ? ?這是結構體最重要的部分,因為我們一定要知道每個類型在內存中的占據規則。結構體在內存中的占據規則是很復雜的。
結構體內存占據規則:
? ? ? ?結構體占據內存遵循地址對齊。第一個成員在與結構體變量偏移量為0的地址處對齊。所有成員都會遵循字節對齊,且第一個成員總是在與結構體變量偏移量為0的地址處對齊。其實結構體是先在內存中找到能被第一個類型整除的地址。
? ? ? ?結構體每個成員都遵循地址對齊,對齊數是根據系統對齊數和當前成員大小對齊的。
? ? ? ?對齊數 = 編譯器默認的對齊數 與 改成員大小的較小值
? ? ? ?vs編譯器默認對齊數為8。
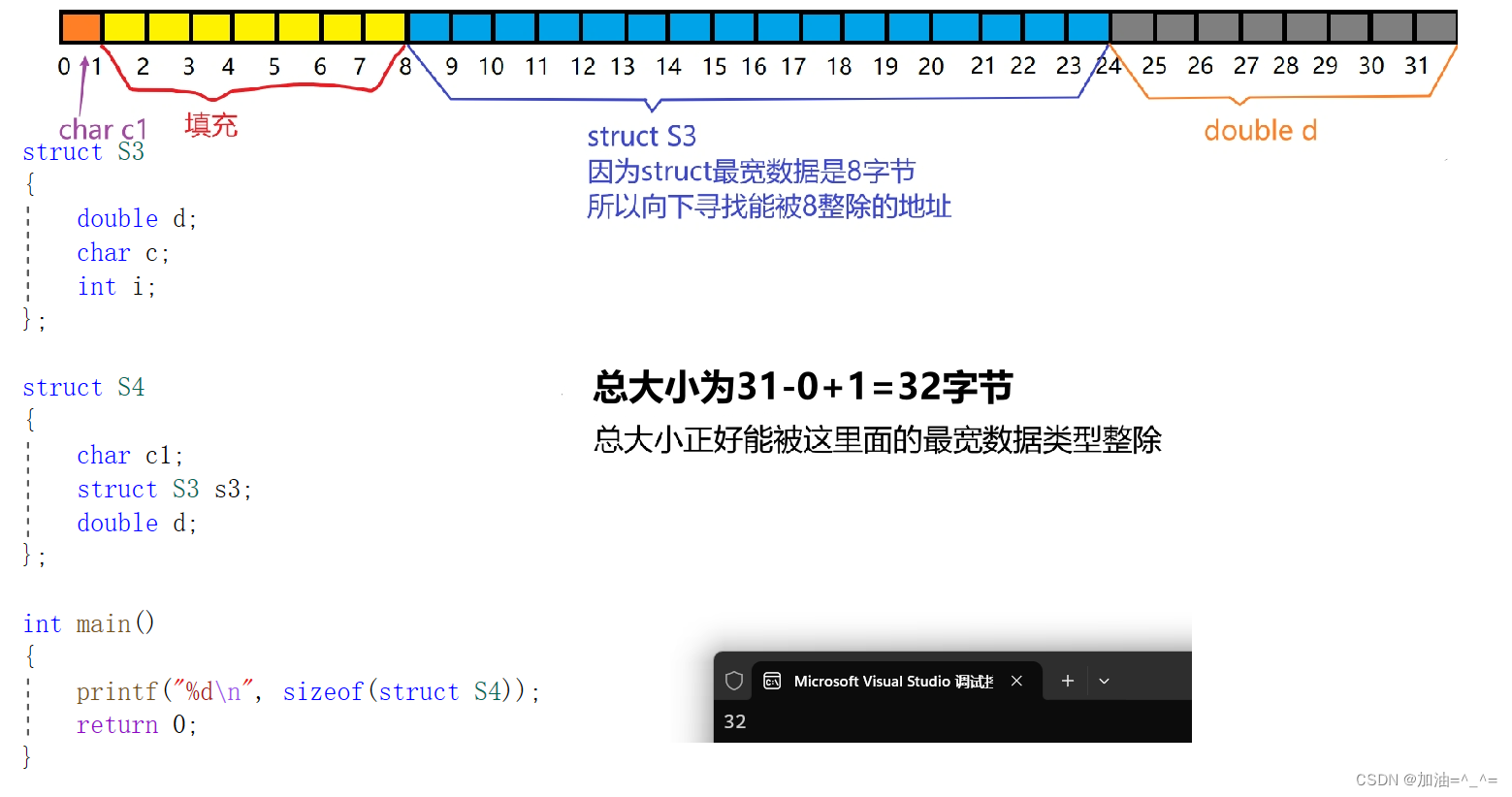
struct S3
{double d;char c;int i;
};? ? ? ?先看第一個成員,占據8個字節,所以先在內存中找到能被8整除的地址,偏移量為0(我們一會再解釋),所以先占據8個字節,之后又找能被下一個成員內存(較小的對齊數是1)整除的地址,最后又找能被4整除的地址,最后整體結構體大小必須是當前最大成員屬性大小的整數倍。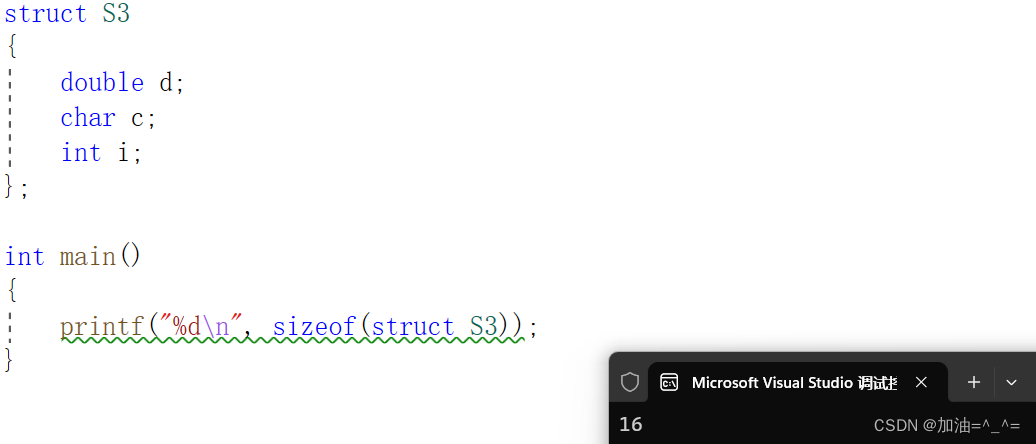
 ? ? ? ? ?即使VS默認對齊數是8,但是結構體大小是根據自己本身成員屬性最大整數倍對齊的。
? ? ? ? ?即使VS默認對齊數是8,但是結構體大小是根據自己本身成員屬性最大整數倍對齊的。
結構體嵌套:
? ? ? ?結構體可是可以嵌套的。
struct S3
{double d;char c;int i;
};
struct s4
{char c1;struct S3 s3;double d;
};
使用pragma來指定對齊數:?
? ? ? ?我們可以自己設置默認對齊數,提高空間利用效率,因為對齊數總是等于較小值。先設置默認對齊數為2幾次方。要加入預處理指令#pragma pack(設置的默認對齊數)
#pragma pack(1)//設置默認對齊數為4
struct S
{char c1;//1double d;//8
};
#pragma pack()//取消設置的默認對齊數
int main()
{struct S s;printf("%d\n", sizeof(s));return 0;
}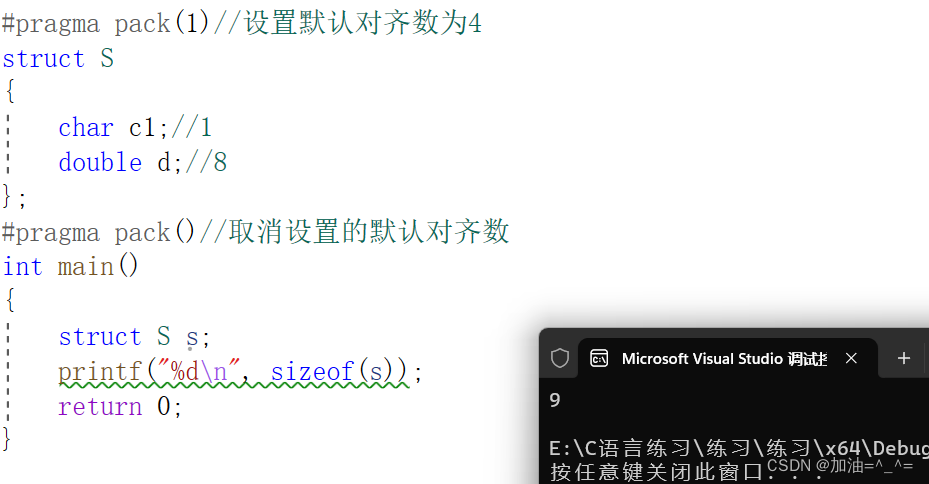
? ? ? ?此時最小默認對齊數為1,所以所有屬性都找到能被1整除的地址即可。結構在對齊方式不合適的時候,我蠻可以自己更改默認對齊數。一般是2幾次方。?
相對偏移函數offsetof:
? ? ? ?我們可以求出它相對于結構體偏移了幾個字節。要引入頭文件stddef.h。
#include<stddef.h>//offsetof的頭文件
struct S1
{char c1;char c2;int i;
};int main()
{printf("%zd\n", offsetof(struct S1, c1));printf("%zd\n", offsetof(struct S1, c2));printf("%zd\n", offsetof(struct S1, i));return 0;
}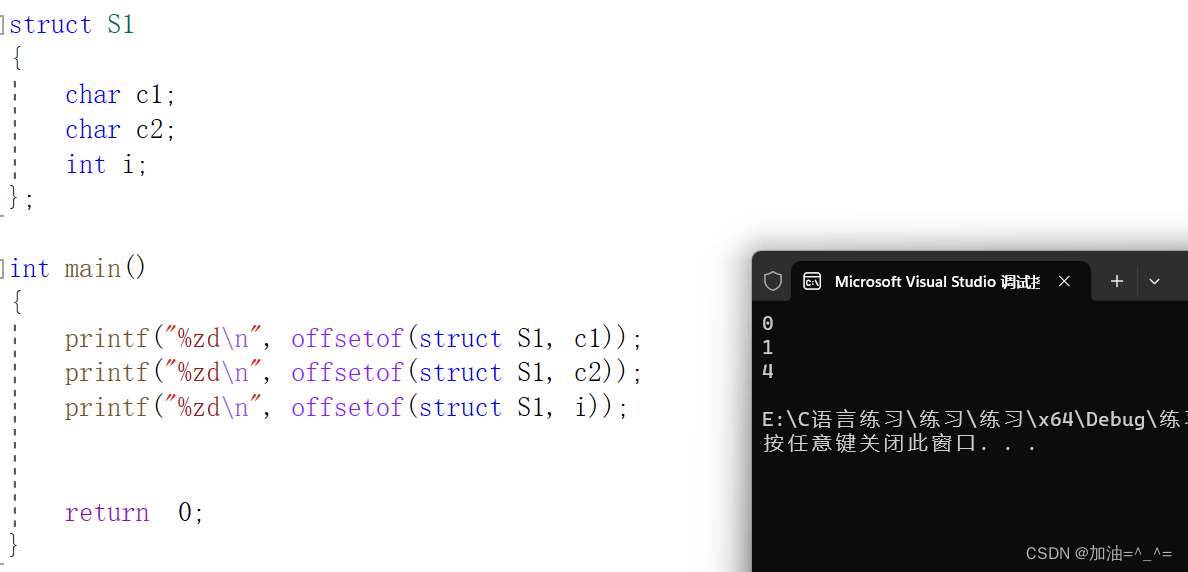
? ? ? ?相對起始位置的偏移量。
內存對齊的意義:?
- 平臺原因(移植原因):不是所有的硬件平臺都能訪問任意地址上的數據的,某些硬件只能在某某些地址處去某些特定類型的數據,否則拋出異常。
- 性能原因:對于未對齊的內存,處理器需要兩次內存訪問;而對齊的的內存訪問僅需要一次。假設一個處理器總是從內存中取8個字節,則地址必須是8的倍數,如果我們能保證將所有的doubl類型數據的地址都對齊成8的倍數,就可以用一個內存操作來讀取或者寫值了,否則,我們可能需要執行兩次內存訪問,因為對象可能分放在兩個8字節內存中。
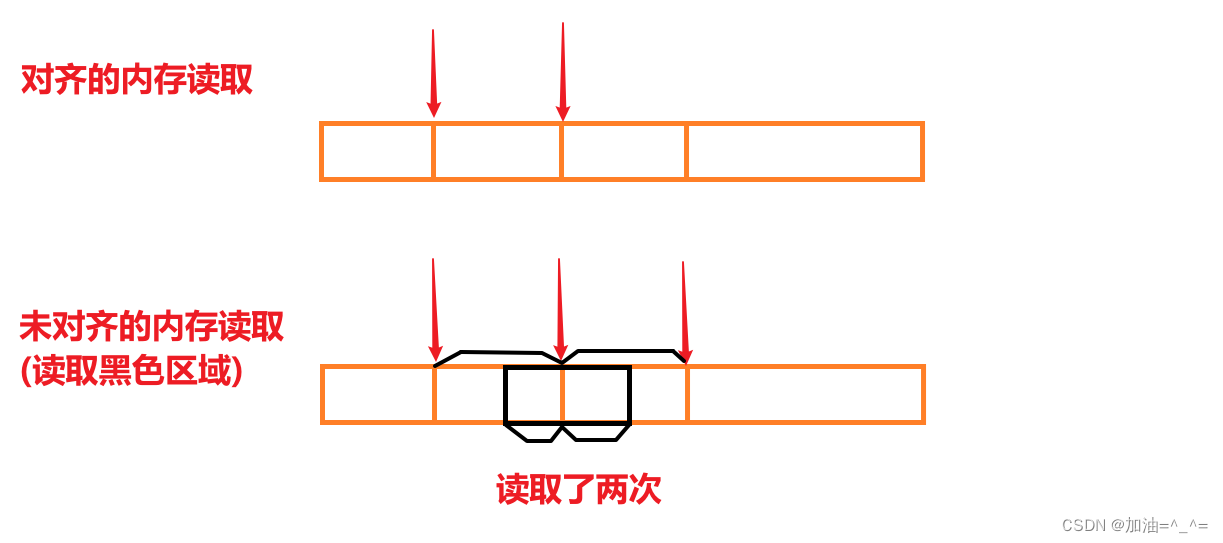
? ? ? ?總體來說,結構體的內存對齊是拿空間來換時間的做法。我們在設計結構體是,既要滿足對齊,又要節省空間,所以我們讓占用空間小的成員盡量集中在一起。?
位段:?
位段是什么?
? ? ? ?位段的出現就是為了節省空間,因為結構體遵循內存對齊,有時候會造成空間浪費,于是衍生出來了位段。位段的聲明和結構體是類似的,有兩個不同:
-
位段成員必須是int、 unsigned int 、signed int或者char等類型。
-
位段的成員名后面有一個冒號和一個數字。
位段的使用和大小:?
? ? ? ?位段的使用是類似于結構體的。
//1.位段的成員必須是int、unsigned int、signed int
//2.位段的成員名后有一個冒號和數字
//位段 - 二進制位
struct A
{int a : 2;//2//冒號后面的數字表示a只需要兩個比特位就夠了int b : 5;//5int c : 10;int d : 30;
};
//47bit - 6個字節*8 = 48bit
//因為位段有自己的對齊方式
int main()
{struct A s;printf("%d\n", sizeof(s));//8個字節return 0;
}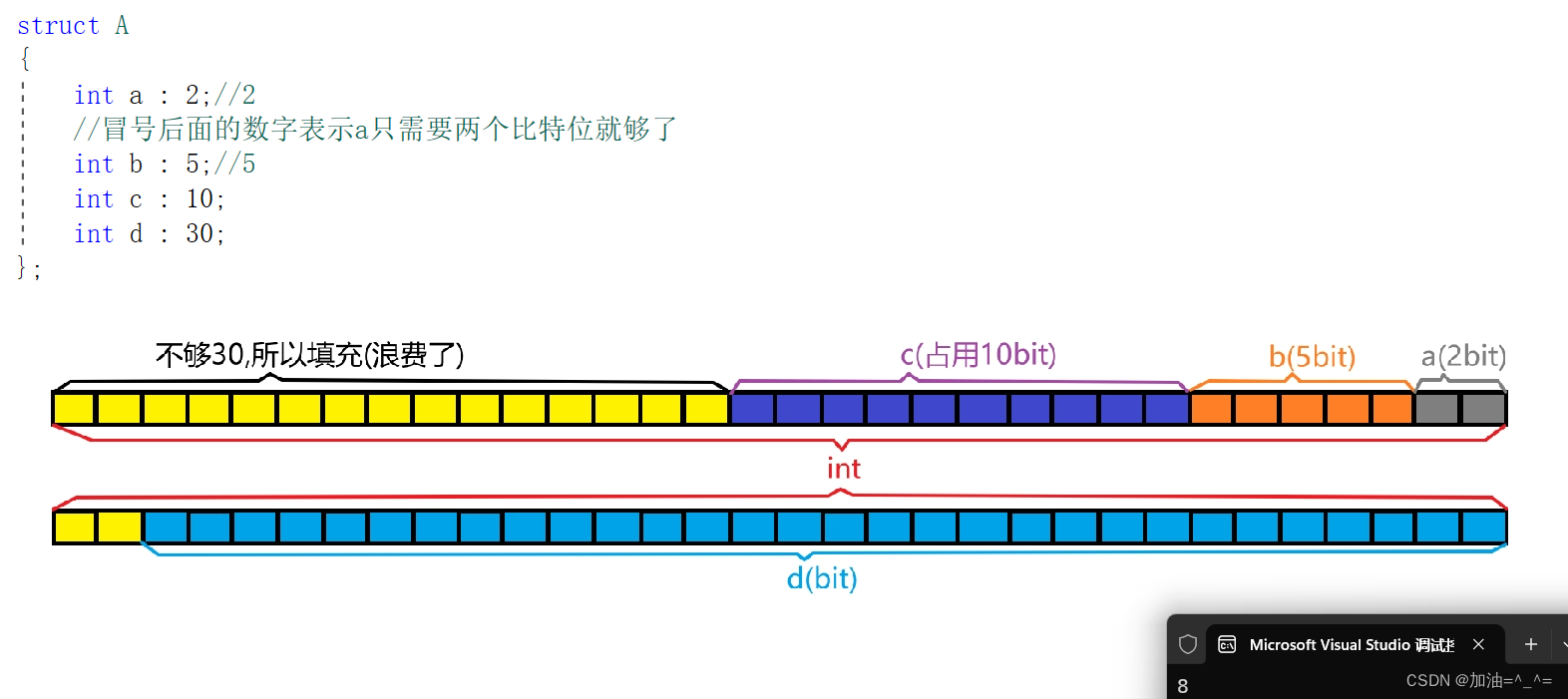
? ? ? ?上圖中A就是一個位段類型。A的大小是8個字節。?
? ? ? ?位段涉及很多不確定因素,位段是不跨平臺的,注重可移植的程序應該避免使用位段。
struct S
{char a : 3;char b : 4;char c : 5;char d : 4;
};
int main()
{struct S s={0};s.a = 10;s.b = 20;s.c = 3;s.d = 4;return 0;
}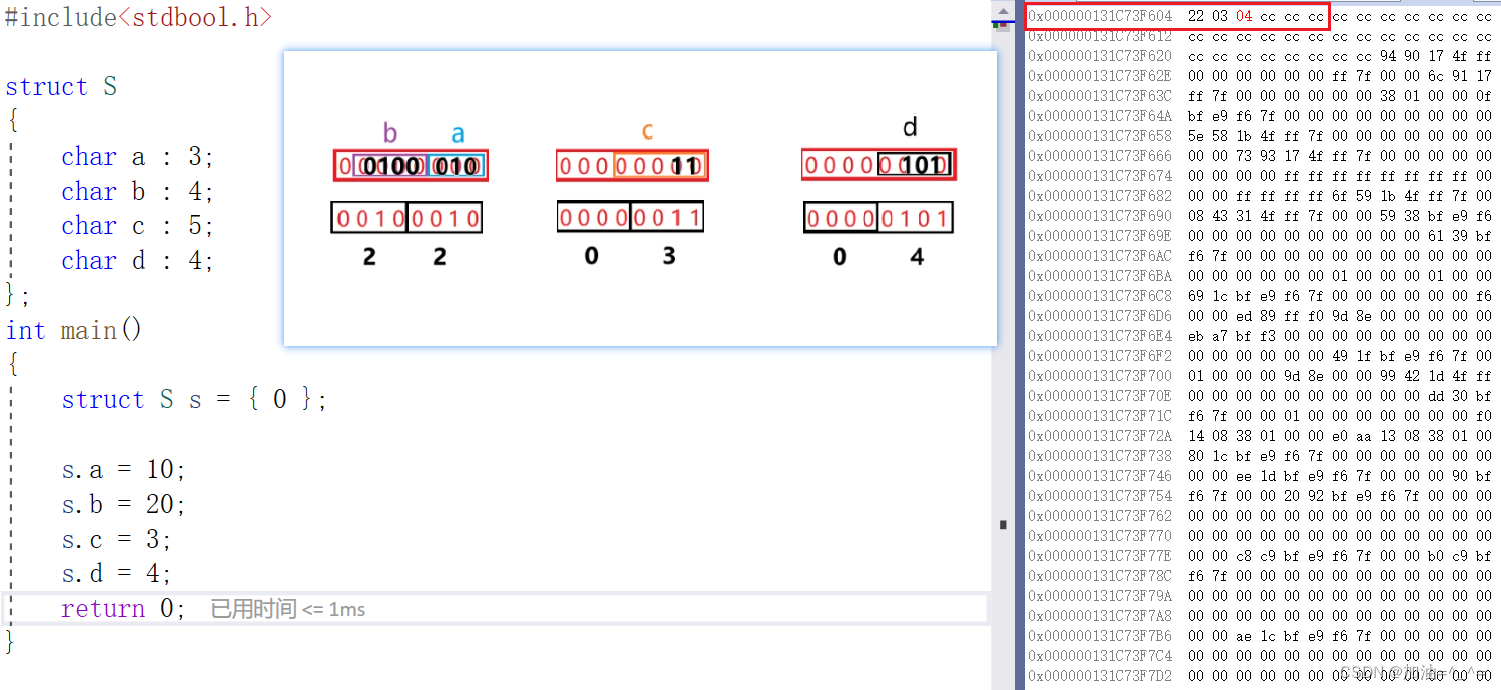
? ? ? ?上面的代碼就是相當于先創建一個位段類型,之后聲明每個成員占多少個bit,之后有給成員賦值,但很明顯,給a賦值10所占據的比特位已經超過了3個bit,于是只將10的二進制前后3個為給成員a。如果不夠,高位補0。之后以此類推。?
位段成員的賦值:?
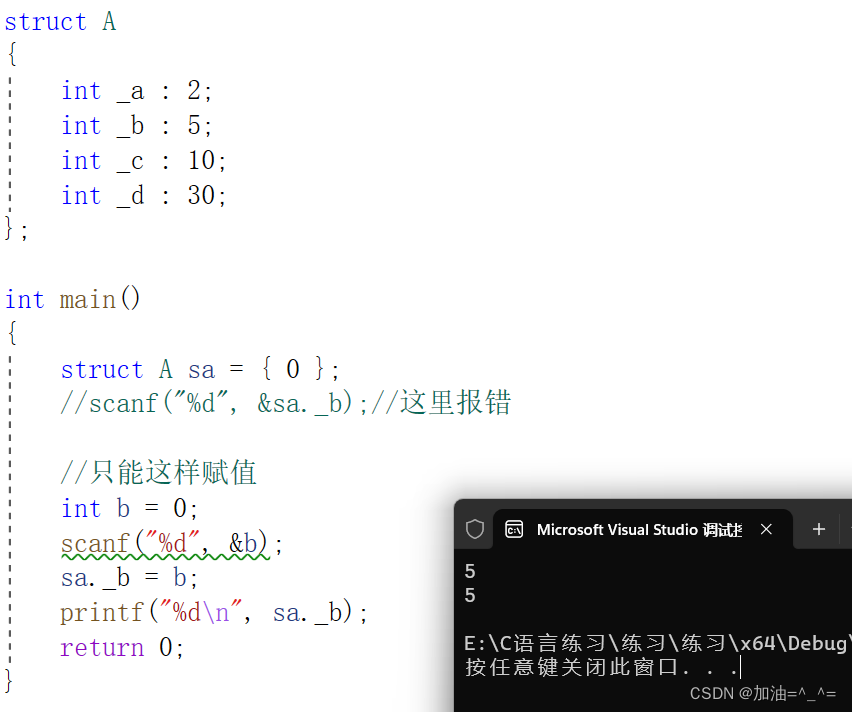
? ? ? ?位段的幾個成員共有一個字節,這樣有些成員的起始位置并不是某個字節的起始位置,那么這些位置處是沒有地址的。
? ? ? ?內存中每個字節分配一個地址,一個字節內部的bit位是沒有地址的,所以不能對位段成員使用&操作,這樣就不能使用scanf直接給位段的成員輸入值,只能是先輸入放在一個變量中,然后賦值給位段的成員。
struct A
{int _a : 2;int _b : 5;int _c : 10;int _d : 30;
};int main()
{struct A sa = { 0 };//scanf("%d", &sa._b);//這里報錯//只能這樣賦值int b = 0;scanf("%d", &b);sa._b = b;printf("%d\n", sa._b);return 0;
}
位段存在的意義:?
? ? ? ?學過網絡的都知道,我們的數據都是封裝成幀發送的,我們一般采用IP數據報的形式發送,我們觀察IP數據報的格式: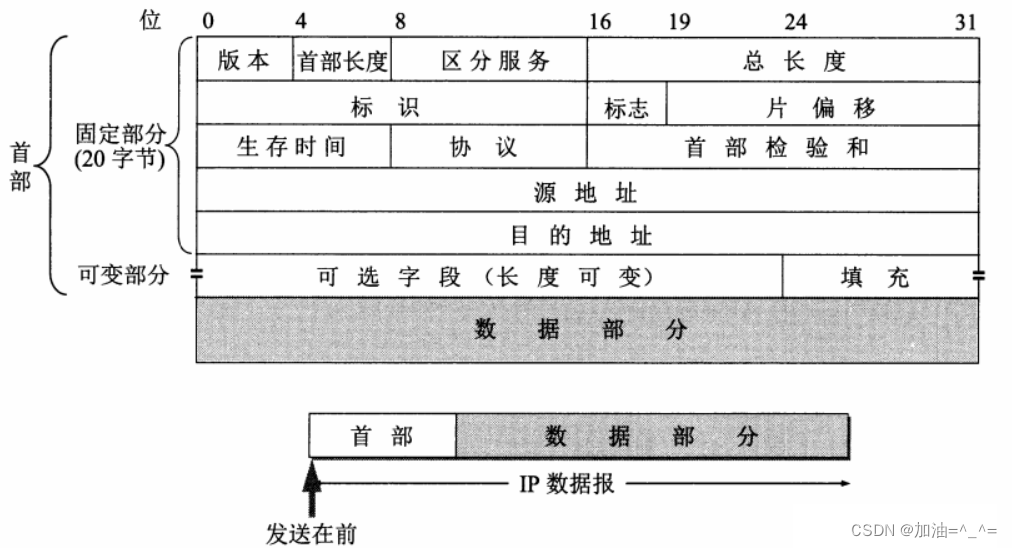
? ? ? ?因為地址最小的的地址編號是字節,1個字節8個bit位,若使用結構體,必然會造成空間的浪費,位段的出現使我們將每一個bit位都合理的使用,但有人會問?既然現在硬件內存都那么大了,還有必要限制內存嗎?
? ? ? ?我們可以將網絡通道想象成一條高速公路,如果都是大型文件,就像是都是大卡車,這樣勢必會造成交通擁擠;但是如果都是小文件,就是小客車,即使會用交通擁擠也會比都是大卡車的路況好。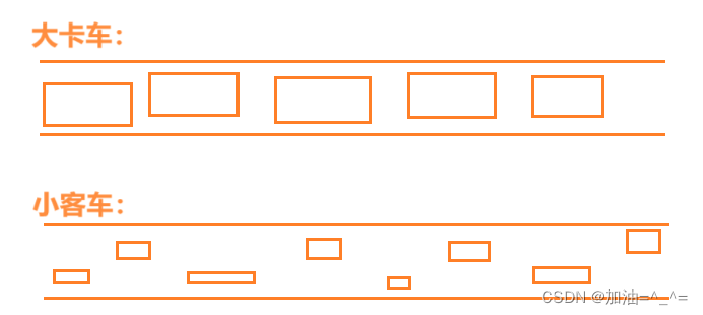 ?
?
位段的跨平臺問題:
- int位段被當做有符號數還是無符號數是不確定的。
-
位段中最大位的數目不確定。(16位機器int是2個字節,寫成27會出問題)。
-
位段中的成員在內存中從左向右分配,還是從右向左分配標準尚未定義。
-
當一個結構包括兩個位段,第二位段成員比較大,無法容納于第一個位段剩余的位時,是舍棄剩余的位還是利用,這個是不確定的。
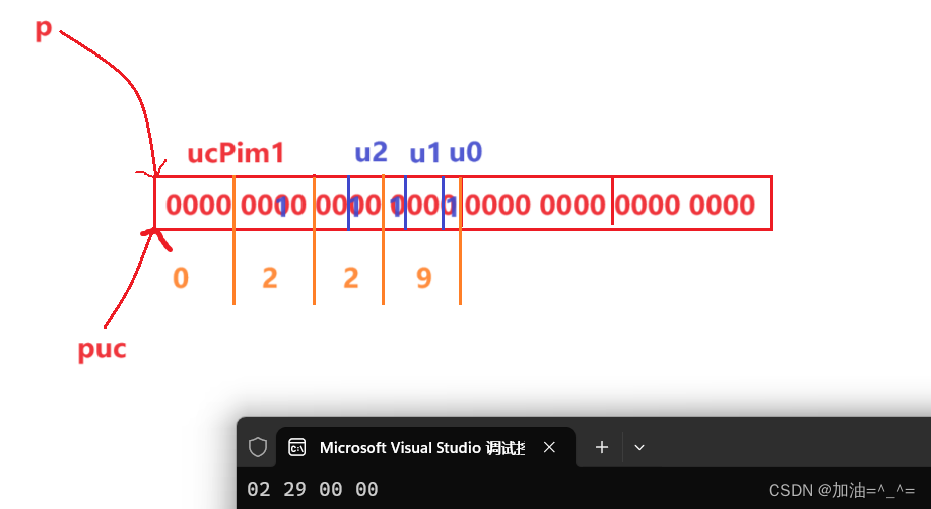
? ? ? ?最后我們來看一道關于位段的練習題:
int main()
{unsigned char puc[4];struct tagPIM{unsigned char ucPim1;unsigned char u0 : 1;unsigned char u1 : 2;unsigned char u2 : 3;}*p;p = (struct tagPIM*)puc;memset(puc, 0, 4);//設置4個字節,每個內容為0p->ucPim1 = 2;p->u0 = 3;p->u1 = 4;p->u2 = 5;printf("%02x %02x %02x %02x\n", puc[0], puc[1], puc[2], puc[3]);//%02x打印出兩個16進制的數return 0;
}
???????


 的 Menu控件)
)






兩數之和(代碼詳解))




)


)
![[足式機器人]Part2 Dr. CAN學習筆記-自動控制原理Ch1-1開環系統與閉環系統Open/Closed Loop System](http://pic.xiahunao.cn/[足式機器人]Part2 Dr. CAN學習筆記-自動控制原理Ch1-1開環系統與閉環系統Open/Closed Loop System)